

下面小編就為大家帶來一篇模擬HTTP請求實現網頁自動操作及資料收集的方法。小編覺得蠻不錯的,現在就分享給大家,也給大家做個參考。一起跟隨小編過來看看吧
前言
網頁可分為資訊提供和業務操作類,資訊提供如新聞、股票行情之類的網站。業務操作如網路營業廳、OA之類的。當然,也有很多網站同時具有這兩種性質,像微博、豆瓣、淘寶這類網站,既提供訊息,也實現某些業務。
普通上網方式一般都是手動操作(這個不需要解釋:D)。但有時候人工手動操作的方式可能就無法勝任了,如爬取網路上大量數據,即時監測某個頁面的變化,批量操作業務(如批量發微博,批量淘寶購物)、刷單等。由於操作量大,而且都是重複的操作,人工操作效率低下,且易出錯。這時候就可以使用軟體來自動操作了。
本人開發過多個這類軟體,有網路爬蟲、自動大量操作業務這類的。其中使用到的一個核心功能就是模擬HTTP請求。當然,有時會使用HTTPS協議,而且網站一般需要登陸後才能進一步操作,還有最重要的一點就是弄清楚網站的業務流程,即知道為了實現某個操作該在什麼時候向哪個頁面以什麼方式提交什麼數據,最後,要擷取數據或知道操作結果,就還需要解析HTML。本文將一一闡述。
本文使用C#語言來展示程式碼,當然也可以用其它語言實現,原理是一樣的。以登陸京東為實例。
模擬HTTP請求
#C#模擬HTTP請求需要使用如下類別:
•WebRequest
•HttpWebRequest
•HttpWebResponse
•Stream
先建立一個請求物件(HttpWebRequest),設定相關的Headers資訊後發送請求(如果是POST,還要把表單資料寫入網絡流),如果目標位址可訪問,會得到一個回應物件(HttpWebResponse),從對應物件的網路流中就可讀出傳回結果。
範例程式碼如下:
String contentType = "application/x-www-form-urlencoded";
String accept = "image/gif, image/x-xbitmap, image/jpeg, image/pjpeg, application/x-shockwave-flash, application/x-silverlight,
application/vnd.ms-excel, application/vnd.ms-powerpoint, application/msword, application/x-ms-application, application/x-ms-xbap,
application/vnd.ms-xpsdocument, application/xaml+xml, application/x-silverlight-2-b1, */*";
String userAgent = "Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/34.0.1847.116 Safari/537.36";
public String Get(String url, String encode = DEFAULT_ENCODE)
{
HttpWebRequest request = WebRequest.Create(url) as HttpWebRequest;
InitHttpWebRequestHeaders(request);
request.Method = "GET";
var html = ReadHtml(request, encode);
return html;
}
public String Post(String url, String param, String encode = DEFAULT_ENCODE)
{
Encoding encoding = System.Text.Encoding.UTF8;
byte[] data = encoding.GetBytes(param);
HttpWebRequest request = WebRequest.Create(url) as HttpWebRequest;
InitHttpWebRequestHeaders(request);
request.Method = "POST";
request.ContentLength = data.Length;
var outstream = request.GetRequestStream();
outstream.Write(data, 0, data.Length);
var html = ReadHtml(request, encode);
return html;
}
private void InitHttpWebRequestHeaders(HttpWebRequest request)
{
request.ContentType = contentType;
request.Accept = accept;
request.UserAgent = userAgent;
}
private String ReadHtml(HttpWebRequest request, String encode)
{
HttpWebResponse response = request.GetResponse() as HttpWebResponse;
Stream stream = response.GetResponseStream();
StreamReader reader = new StreamReader(stream, Encoding.GetEncoding(encode));
String content = reader.ReadToEnd();
reader.Close();
stream.Close();
return content;
}可以看出,Get和Post方法的程式碼大部分都相似,所以程式碼進行了封裝,提取了相同程式碼作為新的函數。
HTTPS請求
當網站使用https協定時,以上程式碼就可能會出現以下錯誤:
The underlying connection was closed: Could not establish trust relationship for
原因是憑證錯誤,用瀏覽器開啟會出現如下頁面:
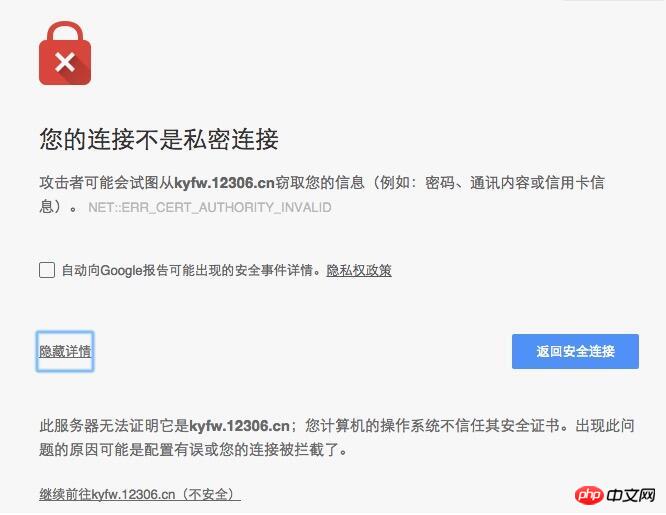
#當點擊繼續前往xxx.xx(不安全)時,就可繼續開啟網頁。在程式中,也只要模擬這一步驟就可以繼續了。 C#中只要設定ServicePointManager.ServerCertificateValidationCallback代理,在代理方法中直接回傳true就行了。
private HttpWebRequest CreateHttpWebRequest(String url)
{
HttpWebRequest request;
if (IsHttpsProtocol(url))
{
ServicePointManager.ServerCertificateValidationCallback = new RemoteCertificateValidationCallback(CheckValidationResult);
request = WebRequest.Create(url) as HttpWebRequest;
request.ProtocolVersion = HttpVersion.Version10;
}
else
{
request = WebRequest.Create(url) as HttpWebRequest;
}
return request;
}
private HttpWebRequest CreateHttpWebRequest(String url)
{
HttpWebRequest request;
if (IsHttpsProtocol(url))
{
ServicePointManager.ServerCertificateValidationCallback = new RemoteCertificateValidationCallback(CheckValidationResult);
request = WebRequest.Create(url) as HttpWebRequest;
request.ProtocolVersion = HttpVersion.Version10;
}
else
{
request = WebRequest.Create(url) as HttpWebRequest;
}
return request;
}這樣,就可正常造訪https網站了。
記錄Cookies實現身分認證
有些網站需要登入才能執行下一步操作,例如在京東購物需要先登入。網站伺服器使用session來記錄客戶端用戶,每個session對應一個用戶,而前面的程式碼每次創建一個請求都會重新建立一個session。即使登入成功,在執行下一步操作由於新建立了一個連接,登入也是無效的。這時就得想辦法讓伺服器認為這一系列的請求是來自同一個session。
客戶端只有Cookies,為了在下次請求的時候讓伺服器知道該客戶端對應哪個session,Cookies中會有一個記錄session ID的記錄。所以,只要Cookies相同,對伺服器來說就是同一個使用者。
這時需要使用到CookieContainer,顧名思義,這就是一個Cookies容器。 HttpWebRequest有一個CookieContainer屬性。只要把每次請求的Cookies都記錄在CookieContainer,下次請求時設定HttpWebRequest的CookieContainer屬性,由於Cookies相同,對於伺服器來說就是同一個使用者了。
public String Get(String url, String encode = DEFAULT_ENCODE)
{
HttpWebRequest request = WebRequest.Create(url) as HttpWebRequest;
InitHttpWebRequestHeaders(request);
request.Method = "GET";
request.CookieContainer = cookieContainer;
HttpWebResponse response = request.GetResponse() as HttpWebResponse;
foreach (Cookie c in response.Cookies)
{
cookieContainer.Add(c);
}
}分析偵錯網站
以上就實作了模擬HTTP請求,當然,最重要的還是分析站。一般的情況都是沒有文件、找不到網站開發人員,從一個黑盒子開始探索。分析工具有很多,推薦使用Chrome+外掛Advanced Rest Client,Chrome的開發者工具能讓我們知道開啟一個網頁時後台做了哪些操作與請求,Advanced Rest Client可模擬發送請求。
例如登入京東時,會提交以下資料:
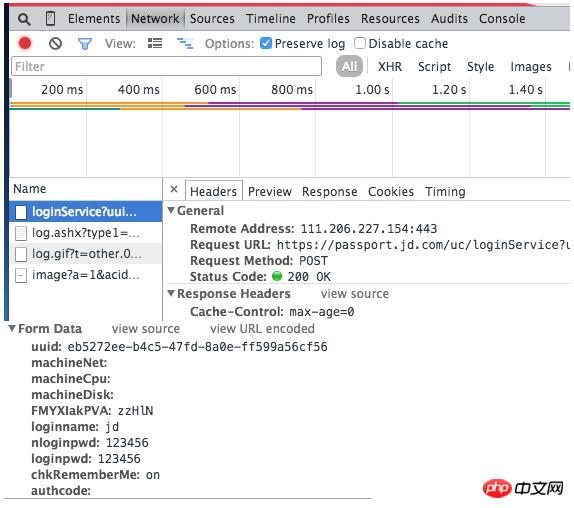
我們還能看到京東的密碼居然是明文傳輸,安全性很讓人擔心啊!
還能看到回傳的資料:

回傳的是JSON數據,不過\u8d26這些是什麼?其實這是Unicode編碼,使用Unicode編碼轉換工具,即可轉換成可讀的文字,例如這次回傳的結果是:帳戶名稱與密碼不匹配,請重新輸入。
解析HTML
HTTP請求所獲得的資料一般是HTML格式,有時也可能是Json或XML。需要解析才能提取有用資料。解析HTML的元件有:
•HTML Parser。多個平台可用,如Java/C#/Python。很久沒用了。
•HtmlAgilityPack。透過透過XPath來解析HMTL。一直使用。 關於XPath教程,可以看W3School的XPath教學。
結語
本文介紹了開發模擬自動網頁操作所需的技能,從模擬HTTP/HTTPS請求,到Cookies、分析網站、解析HTML。程式碼旨在說明使用方法,並非完整程式碼,可能無法直接運行。
以上是模擬HTTP請求實現網頁自動操作及資料收集的方法的詳細內容。更多資訊請關注PHP中文網其他相關文章!





















