

自Ilya Sutskever官宣離職OpenAI後,他的下一步動作成了大家關注焦點。
甚至有人密切注意著他的一舉一動。
這不,Ilya前腳剛剛點讚❤️了一篇新論文——
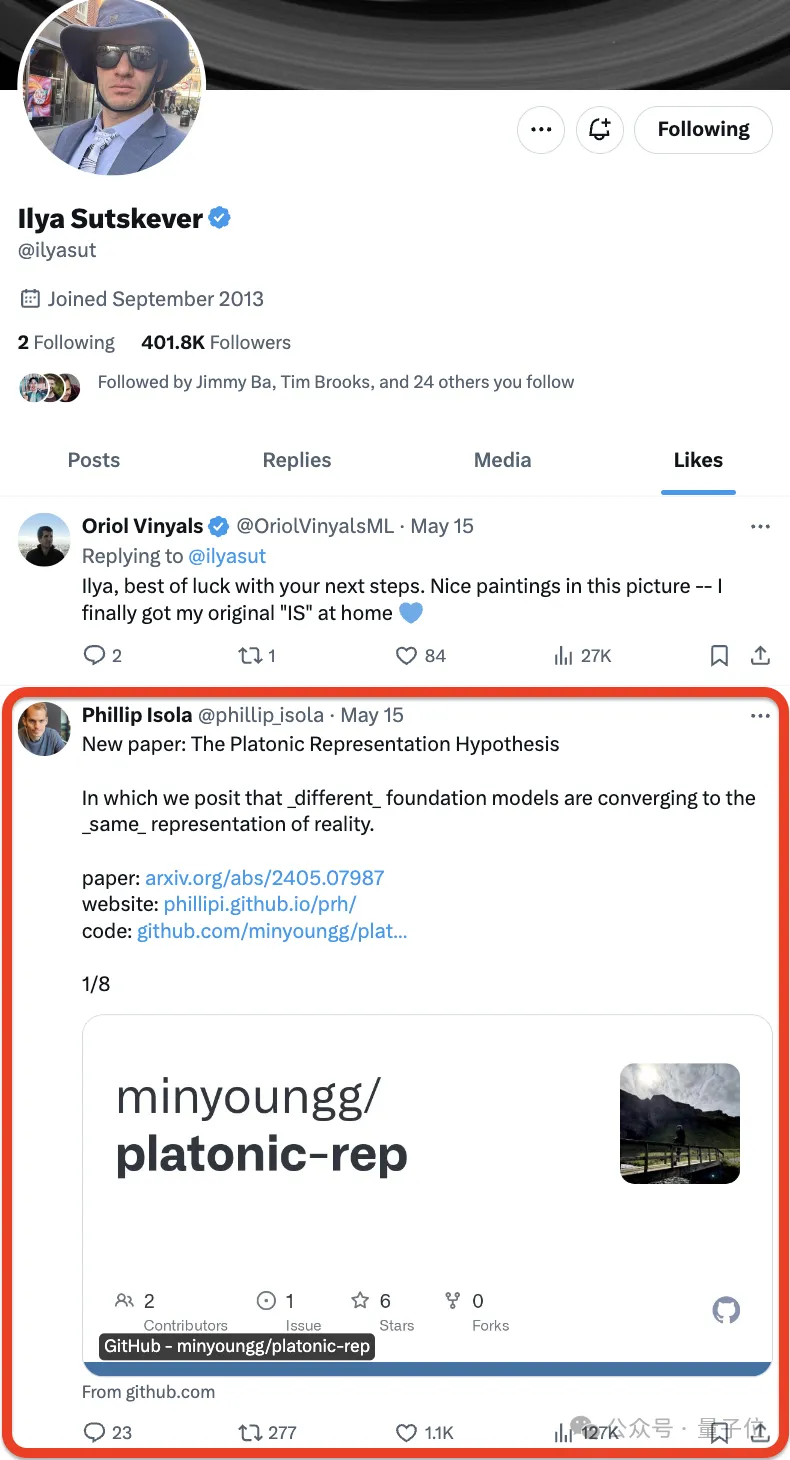
-網友們後腳就搶著都看上了:

#論文來自MIT,作者提出了一個假說,用一句話總結是這樣嬸兒的:
神經網路在不同的資料和模態上以不同目標進行訓練,正趨向於在其表示空間中形成一個共享的現實世界統計模型。

他們將這種推測起名為柏拉圖表示假說,參考了柏拉圖的洞穴寓言以及其關於理想現實本質的觀念。

Ilya甄選還是有保障的,有網友看過後稱之為是今年看到的最好的論文:

還有網友真的有才,看完後化用《安娜·卡列尼娜》開篇的一句話來總結:所有幸福的語言模型都是相似的,每個不幸的語言模型都有自己的不幸。

化用懷特海名言:所有機器學習都是柏拉圖的註腳。

俺們也來看了一下,大概內容是:
#作者分析了AI系統的表徵收斂
# (Representational Convergence),即不同神經網路模型中的資料點表徵方式正變得越來越相似,這種相似性跨不同的模型架構、訓練目標甚至資料模態。 是什麼推動了這種收斂?這種趨勢會持續下去嗎?它的最終歸宿在哪裡?
經過一系列分析和實驗,研究人員推測這種收斂確實有一個終點,並且有一個驅動原則:不同模型都在努力達到對現實的準確表徵
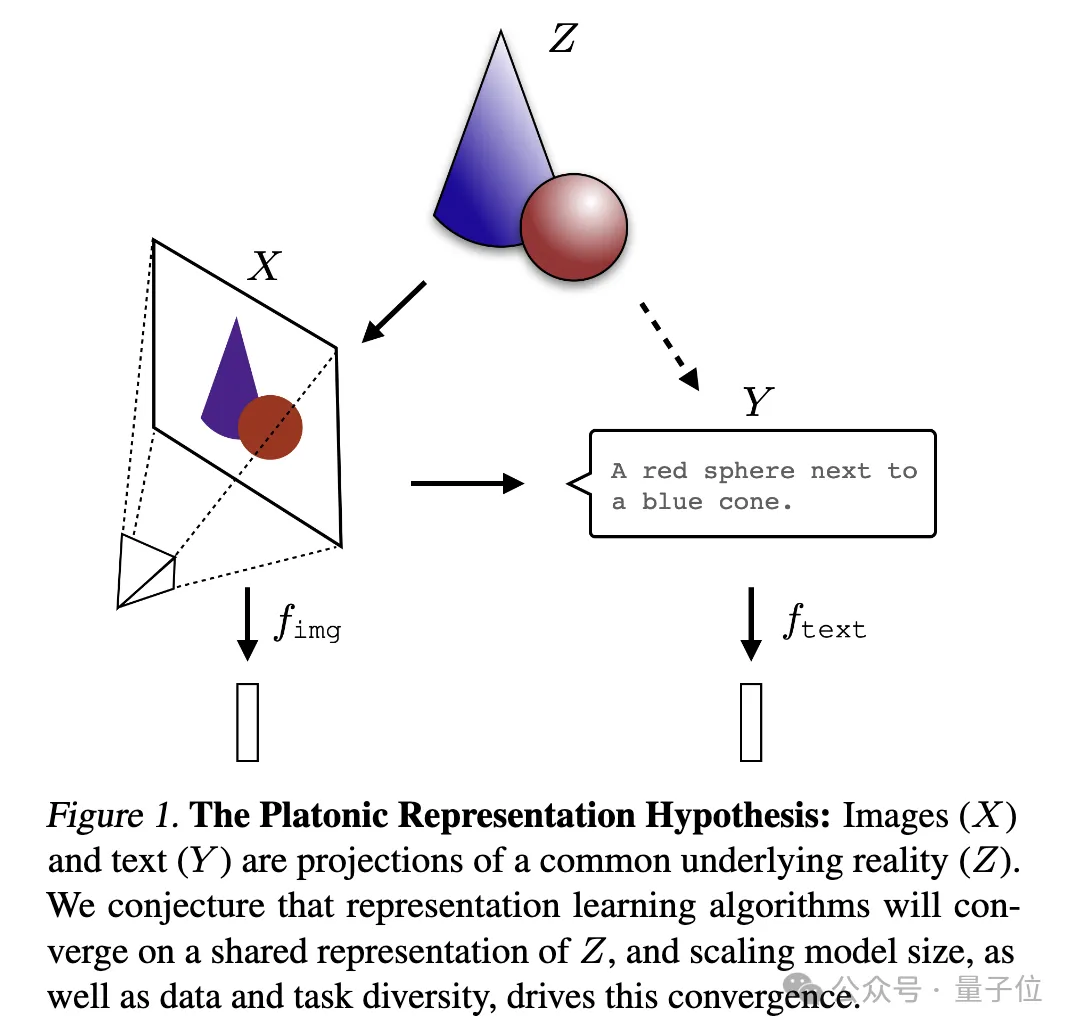
。 一張圖來解釋:
一張圖來解釋:
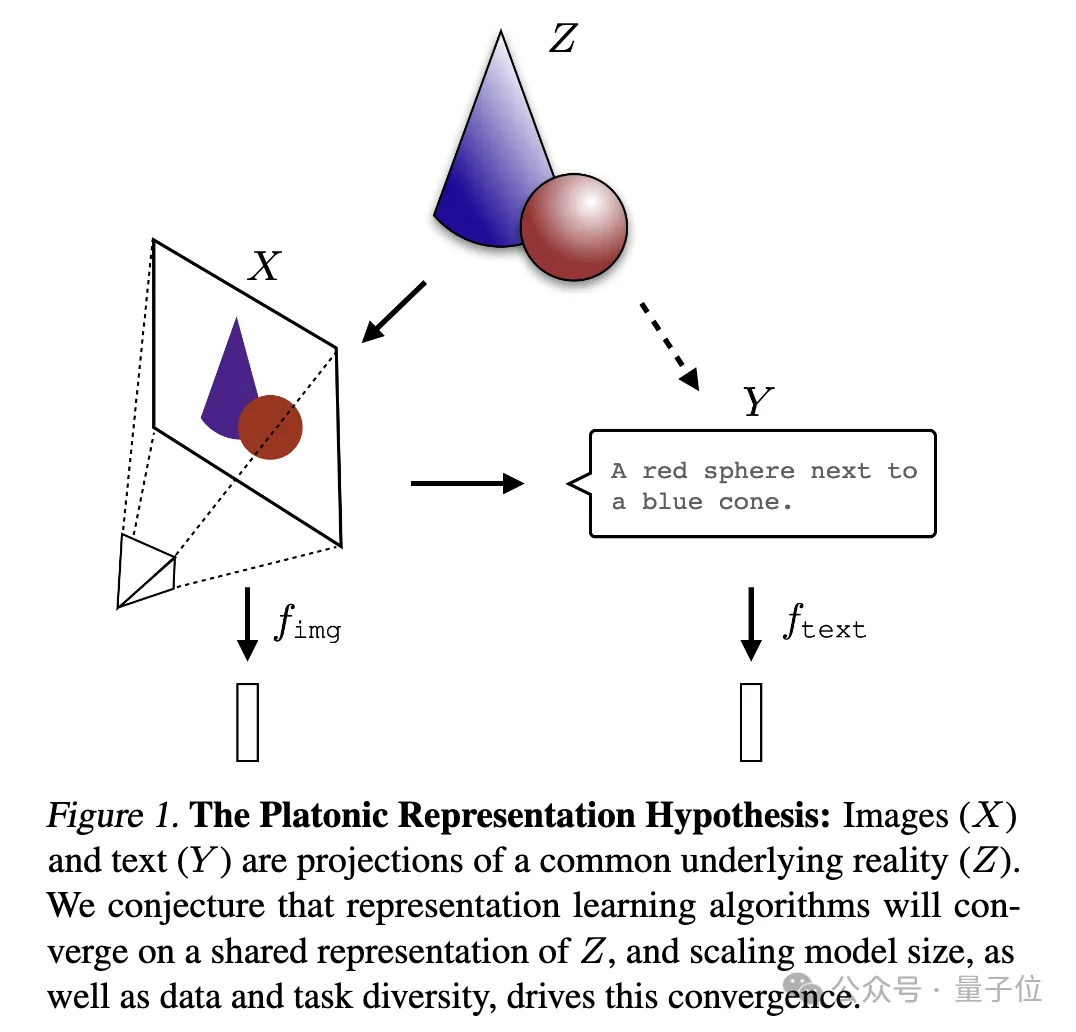
(X)和文字(Y)
是共同底層現實###(Z)###的不同投影。研究人員推測,表徵學習演算法將收斂到對Z的統一表徵上,而模型規模的增加、數據和任務的多樣性是推動這種收斂的關鍵因素。 ######只能說,不愧是Ilya感興趣的問題,太深奧了,俺們也不太懂,下面請AI幫忙解讀了一下給大家分享~########## #####表格被收斂的證據######首先,作者分析了大量先前的相關研究,同時也自己上手做了實驗,拿出了一系列表格和收斂的證據,展示了不同模型的收斂、規模與性能、跨模態的收斂。 #########Ps:本研究重點關注向量嵌入表徵,即資料被轉化成向量形式,透過核函數描述資料點之間的相似性或距離。文中「表徵對齊」概念,即如果兩種不同的表徵方法揭示了類似的資料結構,那麼這兩種表徵被視為是對齊的。 ######1、不同模型的收斂,不同架構和目標的模型在底層表示上趨於一致。
目前基於預訓練基礎模型所建構的系統數量逐漸增加,一些模型正成為多任務的標準核心架構。這種在多種應用上的廣泛適用性體現了它們在資料表徵方式上具有一定通用性。
雖然這個趨勢顯示AI系統正朝著一組較小的基礎模型集合收斂,但並不能證明不同的基礎模型會形成相同的表徵。
不過,最近一些與模型拼接(model stitching)相關的研究發現,即使在不同資料集上訓練,影像分類模型的中間層表徵也可以很好地對齊。
例如有研究發現,在ImageNet和Places365資料集上訓練的捲積網路的早期層可以互換,表明它們學習到了相似的初始視覺表徵。也發現了大量「羅塞塔神經元」(Rosetta Neurons),即在不同視覺模型中被活化的模式高度相似的神經元…
# 2.模型規模和性能越大,表徵對齊程度越高。
研究人員在Places-365資料集上使用相互最近鄰方法衡量了78個模型的對齊情況,並評估了它們在視覺任務適應基準VTAB的下游任務表現。
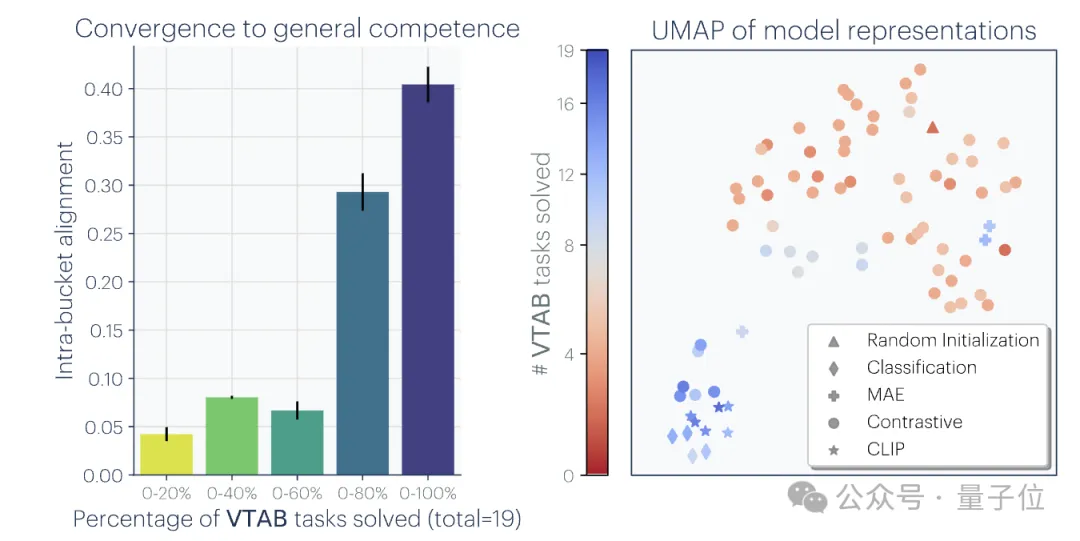
結果發現,泛化能力較強的模型群集之間的表徵對齊度明顯較高。
之前還有研究觀察到,較大模型之間的CKA內核對齊度較高。在理論上也有研究證明了輸出表現相似的模型內部活化也必然相似。
3、不同模態的模型表被收斂。
研究人員在維基百科影像資料集WIT上使用相互最近鄰方法來測量對齊度。
結果揭示了語言-視覺對齊度與語言建模分數之間存在線性關係,一般趨勢是能力更強的語言模型與能力更強的視覺模型對齊得更好。

4、模型與大腦表徵也顯示出一定程度的一致性,可能由於面臨相似的數據和任務限制。
2014年就有研究發現,神經網路的中間層活化與大腦視覺區的活化模式高度相關,可能是由於面臨相似的視覺任務和資料約束。
此後有研究進一步發現,使用不同訓練資料會影響大腦和模型表徵的對齊程度。心理學研究也發現人類感知視覺相似性的方式與神經網路模型高度一致。
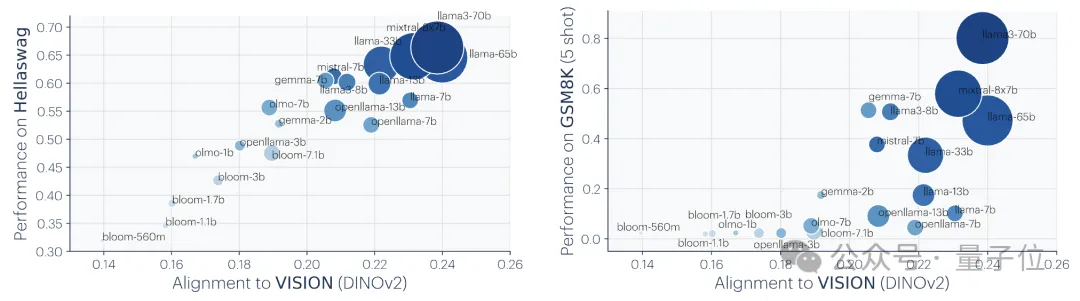
5、模型表徵的對齊程度與下游任務的表現呈正相關。
研究人員使用了兩個下游任務來評估模型的表現:Hellaswag(常識推理)和GSM8K(數學)。並使用DINOv2模型作為參考,來衡量其他語言模型與視覺模型的對齊程度。
實驗結果顯示,與視覺模型對齊程度較高的語言模型在Hellaswag和GSM8K任務上的表現也較好。視覺化結果顯示,對齊程度與下游任務表現之間有明顯的正相關。
之前的研究這裡就不展開說了,有興趣的家人們可查看原始論文。
接著,研究團隊透過理論分析和實驗觀察,提出了表格中收斂的潛在原因,並討論了這些因素如何共同作用,導致不同模型在表示現實世界時趨於一致。
機器學習領域,模型的訓練目標需減少在訓練資料上的預測誤差。為了防止模型過度擬合,通常會在訓練過程中加入正規化項。正則化可以是隱式,也可以是顯式。
研究人員在這部分闡述了這個最佳化過程中,下圖每個彩色部分如何可能在促進表和收斂中發揮作用。

1、任務通用性導致收斂#(Convergence via Task Generality)
隨著模型被訓練來解決更多任務,它們需要找到能夠滿足所有任務需求的表徵:
能夠勝任N個任務的表徵數量少於能夠勝任M個(M

先前也有過類似的原理被提出,圖解是這樣嬸兒的:

而且,容易的任務有多種解決方案,而困難的任務解決方案較少。因此,隨著任務難度的增加,模型的表徵趨於收斂到更優的、數量較少的解。
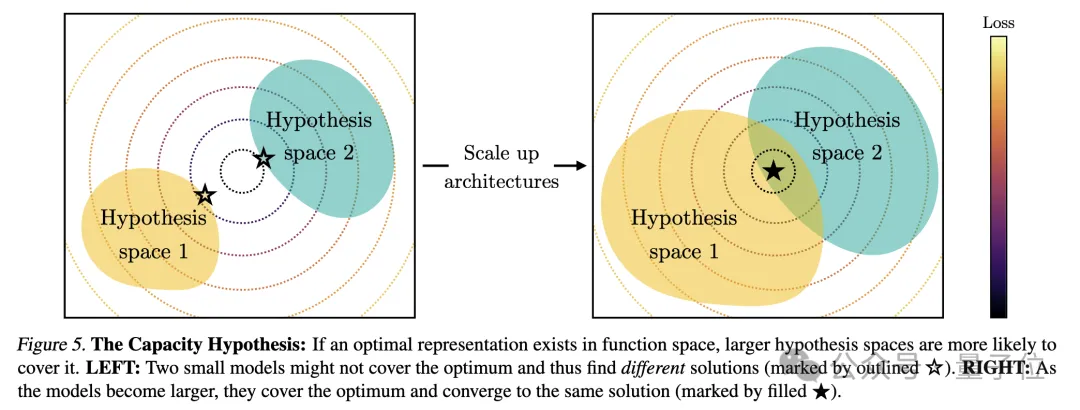
2、模型容量導致收斂(Convergence via Model Capacity)
研究人員指出了容量假設,如果存在一個全域最優的表徵,那麼在資料足夠的條件下,較大的模型更有可能逼近這個最優解。
因此,使用相同訓練目標的較大模型,無論其架構如何,都會趨向於此最優解的收斂。當不同的訓練目標有相似的最小值時,較大的模型更能有效地找到這些最小值,並在各訓練任務中趨於相似的解決方案。

圖解是這樣嬸兒的:
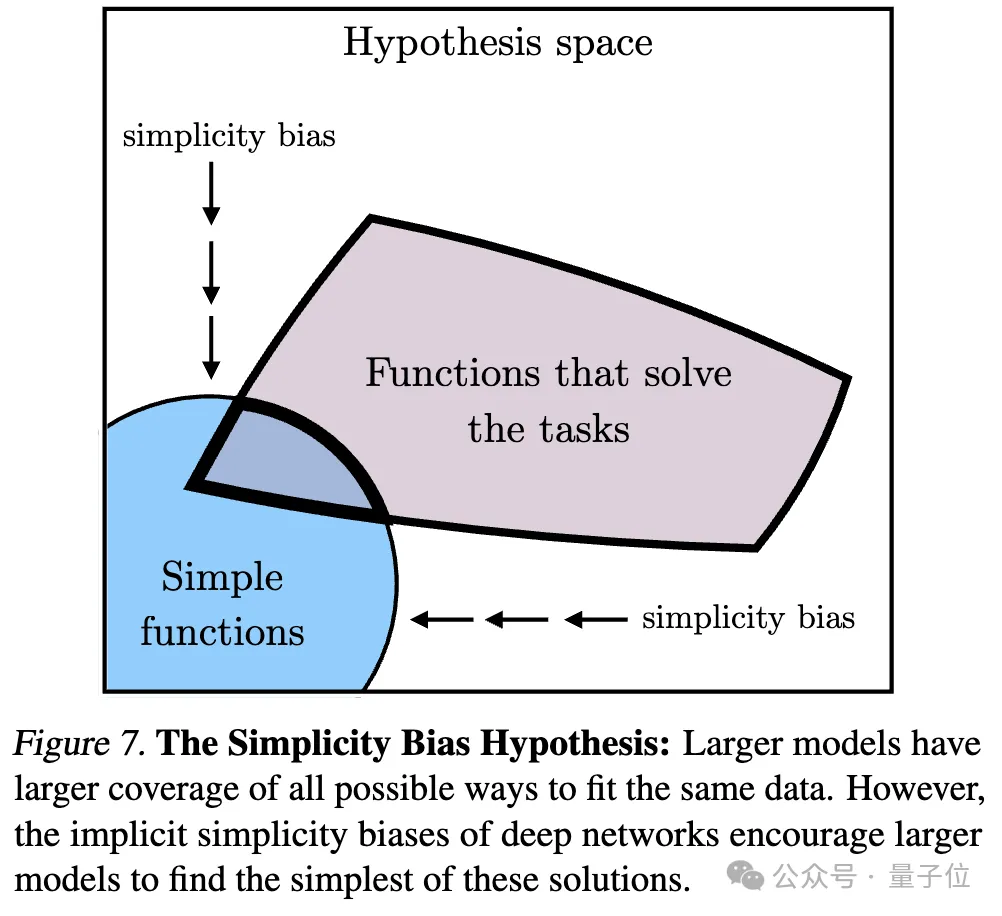
#3、簡單偏差導致收斂 (Convergence via Simplicity Bias)
關於收斂的原因,研究人員也提出了一個假設。深度網路傾向於尋找資料的簡單擬合,這種內在的簡單性偏差使得大模型在表示上趨於簡化,從而導致收斂。

也就是說,較大的模型擁有更廣泛的覆蓋範圍,能夠以所有可能的方式擬合相同的資料。然而,深度網路的隱性簡單性偏好鼓勵較大的模型找到這些解決方案中最簡單的一個。
經過一系列分析與實驗,如開頭所述,研究人員提出了柏拉圖表示假說,推測了這種收斂的終點。
即不同的AI模型,儘管在不同的資料和目標上訓練,它們的表示空間正在收斂於一個共同的統計模型,這個模型代表了產生我們觀察到的資料的現實世界。
他們首先建構了一個理想化的離散事件世界模型。該世界包含一系列離散事件Z,每個事件都是從某個未知分佈P(Z)中取樣得到的。每個事件可以透過觀測函數obs以不同方式被觀測,如像素、聲音、文字等。
接下來,作者考慮了一類對比學習演算法,這類演算法試圖學習一個表徵fX,使得fX(xa)和fX(xb)的內積近似於xa和xb作為正樣本對(來自接近觀測)的對數odds與作為負樣本對(隨機取樣)的對數odds之比。

經過數學推導,作者發現如果資料夠平滑,這類演算法將收斂到一個核函數是xa和xb的點互資訊(PMI)核的表徵fX。

由於研究考慮的是一個理想化的離散世界,觀測函數obs是雙射的,因此xa和xb的PMI核等於對應事件za和zb的PMI核。

這就意味著,無論是從視覺資料X或語言資料Y中學習表徵,最終都會收斂到表示P(Z)的相同核函數,即事件對之間的PMI核。

研究者透過一個關於顏色的實證研究來驗證這個理論。無論是從圖像的像素共現統計中或從文本的詞語共現統計中學習顏色表徵,得到的顏色距離都與人類感知相似,並且隨著模型規模增大,這種相似性也越來越高。
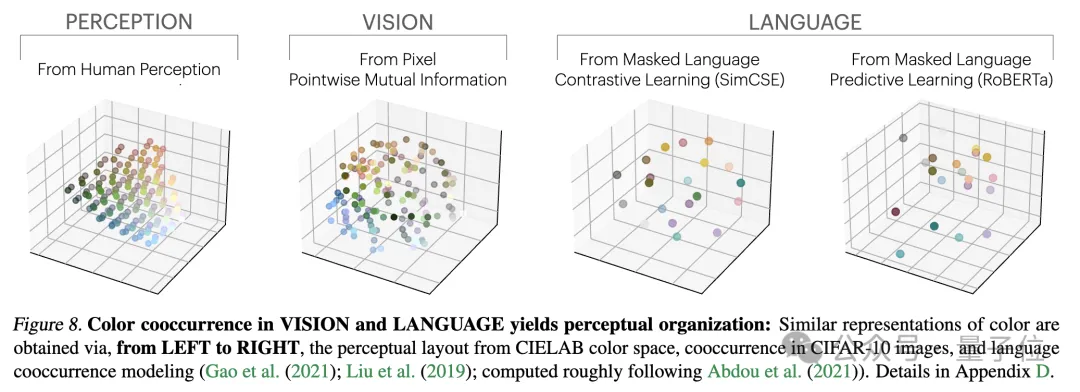
這符合了理論分析,即更大的模型能力可以更準確地建模觀測資料的統計量,進而得到更接近理想事件表徵的PMI核。
論文最後,作者總結了表徵斂對AI領域和未來研究方向的潛在影響,以及柏拉圖式表徵假設的潛在限制和例外情況。
他們指出,隨著模型規模的增加,表示的收斂可能會帶來的影響包括但不限於:
作者強調,上述影響的前提是,未來模型的訓練資料要足夠多元且無損,才能真正收斂到反映實際世界統計規律的表徵。
同時,作者也表示,不同模態的資料可能包含獨特的訊息,可能導致即使在模型規模增加的情況下,也難以實現完全的表示收斂。此外,目前並非所有表徵都在收斂,例如機器人領域還沒有標準化的狀態表徵方式。研究者和社區的偏好可能導致模型向人類表徵方式收斂,從而忽略了其他可能的智慧形式。
且專門設計用於特定任務的智慧系統,可能不會與通用智慧收斂到相同的表徵。
作者也強調了測量表示對齊的方法存在爭議,不同的度量方法可能會導致不同的結論。即使不同模型的表徵相似,但仍有差距有待解釋,目前無法確定這種差距是否重要。
更多細節及論證方法,給大噶把論文放這兒了~
論文連結:https://arxiv.org/abs/2405.07987
以上是Ilya離職後第一個動作:按讚了這篇論文,網友搶著傳看的詳細內容。更多資訊請關注PHP中文網其他相關文章!





















