

圖檢索增強生成(Graph RAG)正逐漸流行起來,成為傳統向量搜尋方法的強大補充。這種方法利用圖資料庫的結構化特性,將資料以節點和關係的形式組織起來,從而增強檢索資訊的深度和上下文關聯性。圖在表示和儲存多樣化且相互關聯的資訊方面具有天然優勢,能夠輕鬆捕捉不同資料類型間的複雜關係和屬性。而向量資料庫則處理這類結構化資訊時則顯得力不從心,它們更專注於處理高維度向量表示的非結構化資料。在 RAG 應用中,結合結構化的圖資料和非結構化的文字向量搜索,可以讓我們同時享受兩者的優勢,這也是本文將要探討的內容。
建立知識圖譜通常是利用圖資料表示的強大功能中最困難的一步。它需要收集和整理數據,這需要對領域知識和圖建模有深刻的理解。為了簡化這個過程,可以參考現有的項目或利用LLM來建立知識圖譜,進而可以把重點放在檢索召回上,以提高LLM的生成階段。下面來進行相關程式碼的實踐。
為了儲存知識圖譜數據,首先需要建構一個 Neo4j 實例。最簡單的方法是在 Neo4j Aura 上啟動一個免費實例,它提供了 Neo4j 資料庫的雲端版本。當然,也可以透過 Docker 本地啟動一個,然後將圖譜資料匯入 Neo4j 資料庫。
以下是本機啟動docker的運作範例:
docker run -d \--restart always \--publish=7474:7474 --publish=7687:7687 \--env NEO4J_AUTH=neo4j/000000 \--volume=/yourdockerVolume/neo4j:/data \neo4j:5.19.0
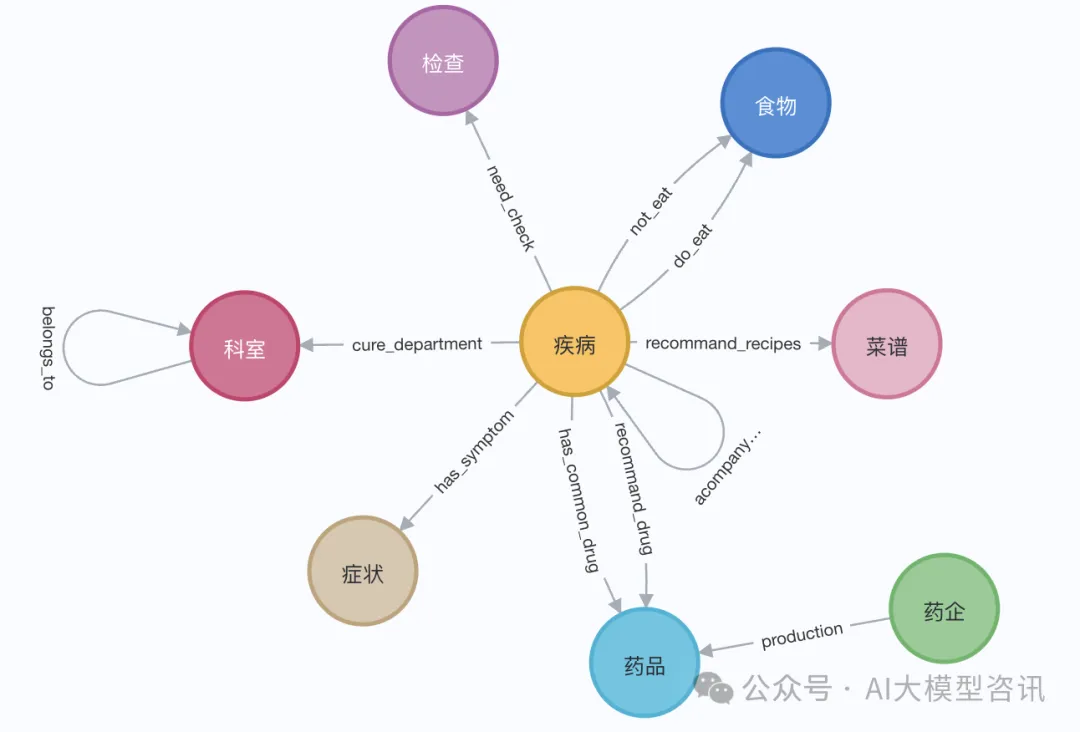 #圖片
#圖片
# 读取维基百科文章raw_documents = WikipediaLoader(query="Elizabeth I").load()# 定义分块策略text_splitter = TokenTextSplitter(chunk_size=512, chunk_overlap=24)documents = text_splitter.split_documents(raw_documents[:3])llm=ChatOpenAI(temperature=0, model_name="gpt-4-0125-preview")llm_transformer = LLMGraphTransformer(llm=llm)# 提取图数据graph_documents = llm_transformer.convert_to_graph_documents(documents)# 存储到 neo4jgraph.add_graph_documents(graph_documents, baseEntityLabel=True, include_source=True)
class GraphRag(object):def __init__(self):"""Any embedding function implementing `langchain.embeddings.base.Embeddings` interface."""self._database = 'neo4j'self.label = 'Med'self._driver = neo4j.GraphDatabase.driver(uri=os.environ["NEO4J_URI"],auth=(os.environ["NEO4J_USERNAME"],os.environ["NEO4J_PASSWORD"]))self.embeddings_zh = HuggingFaceEmbeddings(model_name=os.environ["EMBEDDING_MODEL"])self.vectstore = Neo4jVector(embedding=self.embeddings_zh, username=os.environ["NEO4J_USERNAME"], password=os.environ["NEO4J_PASSWORD"], url=os.environ["NEO4J_URI"], node_label=self.label, index_name="vector" )def query(self, query: str, params: dict = {}) -> List[Dict[str, Any]]:"""Query Neo4j database."""from neo4j.exceptions import CypherSyntaxErrorwith self._driver.session(database=self._database) as session:try:data = session.run(query, params)return [r.data() for r in data]except CypherSyntaxError as e:raise ValueError(f"Generated Cypher Statement is not valid\n{e}")def add_embeddings(self):"""Add embeddings to Neo4j database."""# 查询图中所有节点,并且根据节点的描述和名字生成embedding,添加到该节点上query = """MATCH (n) WHERE not (n:{}) RETURN ID(n) AS id, labels(n) as labels, n""".format(self.label)print("qurey node...")data = self.query(query)ids, texts, embeddings, metas = [], [], [], []for row in tqdm(data,desc="parsing node"):ids.append(row['id'])text = row['n'].get('name','') + row['n'].get('desc','')texts.append(text)metas.append({"label": row['labels'], "context": text})self.embeddings_zh.multi_process = Falseprint("node embeddings...")embeddings = self.embeddings_zh.embed_documents(texts)print("adding node embeddings...")ids_ret = self.vectstore.add_embeddings(ids=ids,texts=texts,embeddings=embeddings,metadatas=metas)return ids_ret# Fulltext index querydef structured_retriever(self, query, limit=3, simlarity=0.9) -> str:"""Collects the neighborhood of entities mentioned in the question"""# step1 从图谱中检索与查询相关的实体。docs_with_score = self.vectstore.similarity_search_with_score(query, k=topk)entities = [item[0].page_content for item in data if item[1] > simlarity] # scoreself.vectstore.query("CREATE FULLTEXT INDEX entity IF NOT EXISTS FOR (e:Med) ON EACH [e.context]")result = ""for entity in entities:qry = entity# step2 从全局索引中查出entity label,query1 =f"""CALL db.index.fulltext.queryNodes('entity', '{qry}') YIELD node, score return node.label as label,node.context as context, node.id as id, score LIMIT {limit}"""data1 = self.vectstore.query(query1)# step3 根据label在相应的节点中查询邻居节点路径for item in data1:node_type = item['label']node_type = item['label'] if type(node_type) == str else node_type[0]node_id = item['id']query2 = f"""match (node:{node_type})-[r]-(neighbor) where ID(node) = {node_id} RETURN type(r) as rel, node.name+' - '+type(r)+' - '+neighbor.name as output limit 50"""data2 = self.vectstore.query(query2)# step4 为了保持多样性,对关系进行筛选rel_dict = defaultdict(list)if len(data2) > 3*limit:for item1 in data2:rel_dict[item1['rel']].append(item1['output'])if rel_dict:rel_dict = {k:random.sample(v, 3) if len(v)>3 else v for k,v in rel_dict.items()}result += "\n".join(['\n'.join(el) for el in rel_dict.values()]) +'\n'else:result += "\n".join([el['output'] for el in data2]) +'\n'return resultfrom langchain import HuggingFacePipelinefrom transformers import pipeline, AutoTokenizer, AutoModelForCausalLMdef custom_model(model_name, branch_name=None, cache_dir=None, temperature=0, top_p=1, max_new_tokens=512, stream=False):tokenizer = AutoTokenizer.from_pretrained(model_name, revision=branch_name, cache_dir=cache_dir)model = AutoModelForCausalLM.from_pretrained(model_name,device_map='auto',torch_dtype=torch.float16,revision=branch_name,cache_dir=cache_dir)pipe = pipeline("text-generation",model = model,tokenizer = tokenizer,torch_dtype = torch.bfloat16,device_map = 'auto',max_new_tokens = max_new_tokens,do_sample = True)llm = HuggingFacePipeline(pipeline = pipe,model_kwargs = {"temperature":temperature, "top_p":top_p,"tokenizer":tokenizer, "model":model})return llmtongyi_model = "Qwen1.5-7B-Chat"llm_model = custom_model(model_name=tongyi_model)tokenizer = llm_model.model_kwargs['tokenizer']model = llm_model.model_kwargs['model']##步驟II:輸入檢索資料產生回應
final_data = self.get_retrieval_data(query)prompt = ("请结合以下信息,简洁和专业的来回答用户的问题,若信息与问题关联紧密,请尽量参考已知信息。\n""已知相关信息:\n{context} 请回答以下问题:{question}".format(cnotallow=final_data, questinotallow=query))messages = [{"role": "system", "content": "你是**开发的智能助手。"},{"role": "user", "content": prompt}]text = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)model_inputs = tokenizer([text], return_tensors="pt").to(self.device)generated_ids = model.generate(model_inputs.input_ids,max_new_tokens=512)generated_ids = [output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)]response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]print(response)以上是知識圖譜檢索增強的GraphRAG(基於Neo4j程式碼實作)的詳細內容。更多資訊請關注PHP中文網其他相關文章!


































