


With the rapid development and application of large-scale models, the importance of Embedding, which is the core basic component of large-scale models, has become more and more prominent. The open source commercially available Chinese-English semantic vector model BGE (BAAI General Embedding) released by Zhiyuan Company a month ago has attracted widespread attention in the community, and has been downloaded hundreds of thousands of times on the Hugging Face platform. Currently, BGE has rapidly iteratively launched version 1.5 and announced multiple updates. Among them, BGE has open sourced 300 million pieces of large-scale training data for the first time, providing the community with help in training similar models and promoting the development of technology in this field
The first open source semantic vector in the industry The model training data reaches 300 million pieces of Chinese and English data
BGE’s outstanding capabilities largely stem from its large-scale and diverse training data. Previously, industry peers had rarely released similar data sets. In this update, Zhiyuan opens BGE training data to the community for the first time, laying the foundation for further development of this type of technology.
The data set MTP released this time consists of a total of 300 million Chinese and English related text pairs. Among them, there are 100 million records in Chinese and 200 million records in English. The sources of data include Wudao Corpora, Pile, DuReader, Sentence Transformer and other corpora. After necessary sampling, extraction and cleaning,
is obtained. For details, please refer to Data Hub: https://data.baai.ac.cn
MTP is the largest open source Chinese-English related text pair data set to date, providing an important foundation for training Chinese and English semantic vector models.
Based on community feedback, BGE has been further optimized based on its version 1.0, making Its performance is more stable and outstanding. The specific upgrade content is as follows:
It is worth mentioning that recently, Zhiyuan and Hugging Face released a technical report, which proposed using C-Pack to enhance the Chinese universal semantic vector model.
《C-Pack: Packaged Resources To Advance General Chinese Embedding》
Link: https://arxiv.org/pdf/2309.07597 .pdf
##Gaining high popularity in the developer communityLangchain official, LangChain co-founder and CEO Official Harrison Chase, Deep trading founder Yam Peleg and other community influencers expressed concern about BGE.
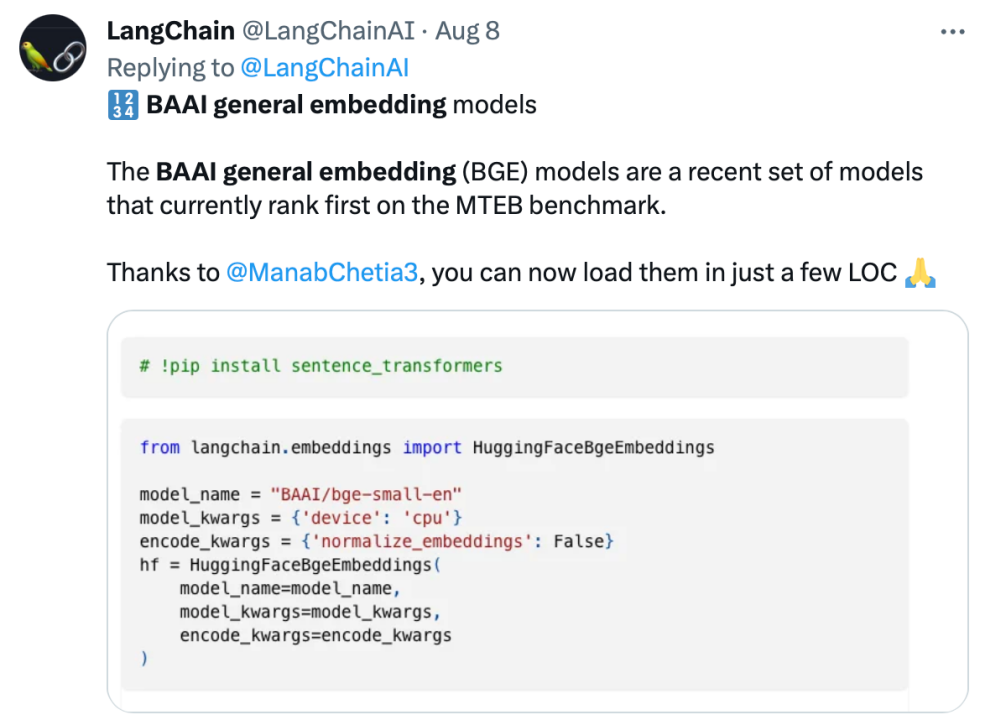
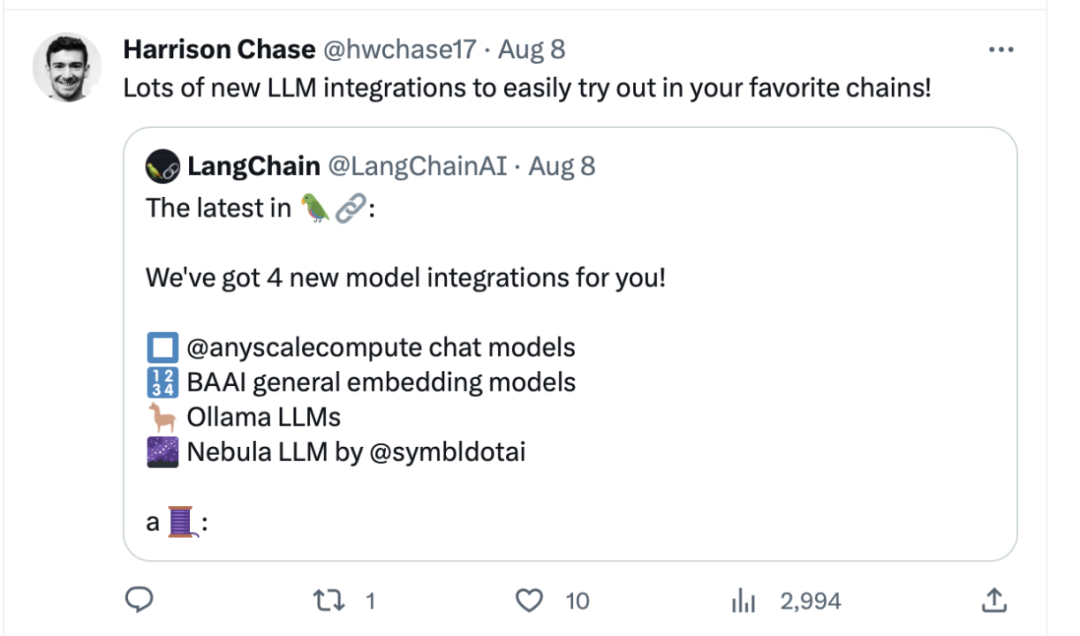
Adhere to open source and promote collaborative innovation, Zhiyuan large model technology development system FlagOpen BGE has added a new FlagEmbedding section, focusing on Embedding technology and models. BGE is one of the high-profile open source projects. FlagOpen is committed to building artificial intelligence technology infrastructure in the era of large models, and will continue to open more complete large model full-stack technologies to academia and industry in the future
The above is the detailed content of Zhiyuan has opened 300 million semantic vector model training data, and the BGE model continues to be iteratively updated.. For more information, please follow other related articles on the PHP Chinese website!





























![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



