Found a total of 2489 related content

What models are bom and dom?
Article Introduction:BOM is the browser object model, and DOM is the document object model. BOM is a model used to describe browser windows and various objects provided by the browser. It is the core component of the browser. BOM can access and operate objects such as browser windows and frames. DOM provides a set of APIs that enable developers to access and manipulate elements and attributes in documents through scripting languages. Its core concepts include nodes, elements, attributes, text, etc. The root node of the DOM tree is the document object, through which Access the entire document's content.
2023-11-13
comment 0
514

A brief introduction to the DOM document object model
Article Introduction:This article brings you relevant knowledge about JavaScript, which mainly introduces issues related to the DOM document model. DOM is designed by the W3C organization as a platform-independent and language-independent API through which programs or scripts can dynamically access, Modify the content, style, and structure of the document. Let’s take a look at it. I hope it will be helpful to everyone.
2022-08-05
comment 0
1209

Is the javascript document object model a tree type?
Article Introduction:The JavaScript document object model is a tree. Document Object Model (DOM) is a standard programming interface for processing extensible markup languages recommended by the W3C organization. It is a tree-based API document.
2021-11-08
comment 0
2102

What types of crawler modules are there in php?
Article Introduction:PHP crawler module types include cURL, Simple HTML DOM, Goutte, PhantomJS, Selenium, etc. Detailed introduction: 1. cURL, which can simulate browser behavior to easily obtain web page content; 2. Simple HTML DOM, which can locate and extract HTML elements through CSS selectors or XPath expressions, and easily extract the required data from web pages. ;3. Goutte can send HTTP requests, process cookies, process forms, etc.
2023-09-01
comment 0
1291

字节跳动正式发布“豆包大模型”家族,含通用模型、角色扮演模型、声音复刻模型、语音识别模型、文生图模型等
Article Introduction:本站5月15日消息,今天上午,字节跳动在2024春季火山引擎Force原动力大会上正式宣布自家豆包大模型正式开启对外服务。据介绍,豆包大模型包含豆包通用模型Pro、豆包通用模型liti、豆包・角色扮演模型、豆包・语音合成模型、豆包・声音复刻模型、豆包・语音识别模型、豆包・文生图模型、豆包・FunctionCall模型。官方表示,此次大会共分为“AI增长焕新机、AI应用新范式、AI算力强护航”三个篇章。除发布字节跳动自研大模型外,字节跳动还宣布火山引擎大模型服务平台——火山方舟也将迎来重大升级。同时,字节跳
2024-05-15
comment
837

Knowledge compression: model distillation and model pruning
Article Introduction:Model distillation and pruning are neural network model compression technologies that effectively reduce parameters and computational complexity, and improve operating efficiency and performance. Model distillation improves performance by training a smaller model on a larger model, transferring knowledge. Pruning reduces model size by removing redundant connections and parameters. These two techniques are very useful for model compression and optimization. Model Distillation Model distillation is a technique that replicates the predictive power of a large model by training a smaller model. The large model is called the "teacher model" and the small model is called the "student model". Teacher models typically have more parameters and complexity and are therefore better able to fit the training and test data. In model distillation, the student model is trained to imitate the predicted behavior of the teacher model to achieve better performance on a smaller model.
2024-01-23
comment
299

The difference between large language models and word embedding models
Article Introduction:Large language models and word embedding models are two key concepts in natural language processing. They can both be applied to text analysis and generation, but the principles and application scenarios are different. Large-scale language models are mainly based on statistical and probabilistic models and are suitable for generating continuous text and semantic understanding. The word embedding model can capture the semantic relationship between words by mapping words to vector space, and is suitable for word meaning inference and text classification. 1. Word embedding model The word embedding model is a technology that processes text information by mapping words into a low-dimensional vector space. It converts words in a language into vector form so that computers can better understand and process text. Commonly used word embedding models include Word2Vec and GloVe. These models are widely used in natural language processing tasks
2024-01-23
comment
965
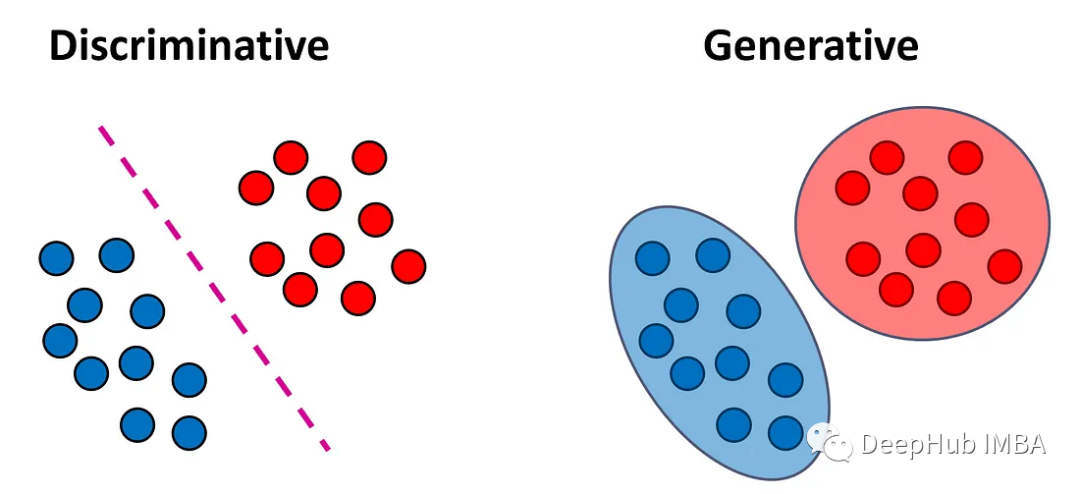
Generative and discriminative models
Article Introduction:Classification models can be divided into two categories: generative models and discriminative models. This article explains the differences between these two model types and discusses the pros and cons of each approach. Discriminative model A discriminative model is a model that can learn the relationship between input data and output labels. It predicts the output labels by learning the characteristics of the input data. In a classification problem, our goal is to assign each input vector x to a label y. Discriminative models attempt to directly learn a function f(x) that maps input vectors to labels. These models can be further divided into two subtypes: Classifiers try to find f(x) without using any probability distribution. These classifiers directly output a label for each sample without providing a probability estimate of the class. These classifiers are often called deterministic classifiers or
2023-05-19
comment 0
601

How to perform model fusion and model compression in PHP?
Article Introduction:With the rapid development of artificial intelligence, the complexity of models is getting higher and higher, and the use of resources is also increasing. In PHP, how to perform model fusion and model compression has become a hot topic. Model fusion refers to fusing multiple single models together to improve overall accuracy and efficiency. Model compression reduces the size and computational complexity of the model to save model storage and computing resources. This article will introduce how to perform model fusion and model compression in PHP. 1. Model fusion In PHP, there are two commonly used model fusion methods:
2023-05-23
comment 0
950
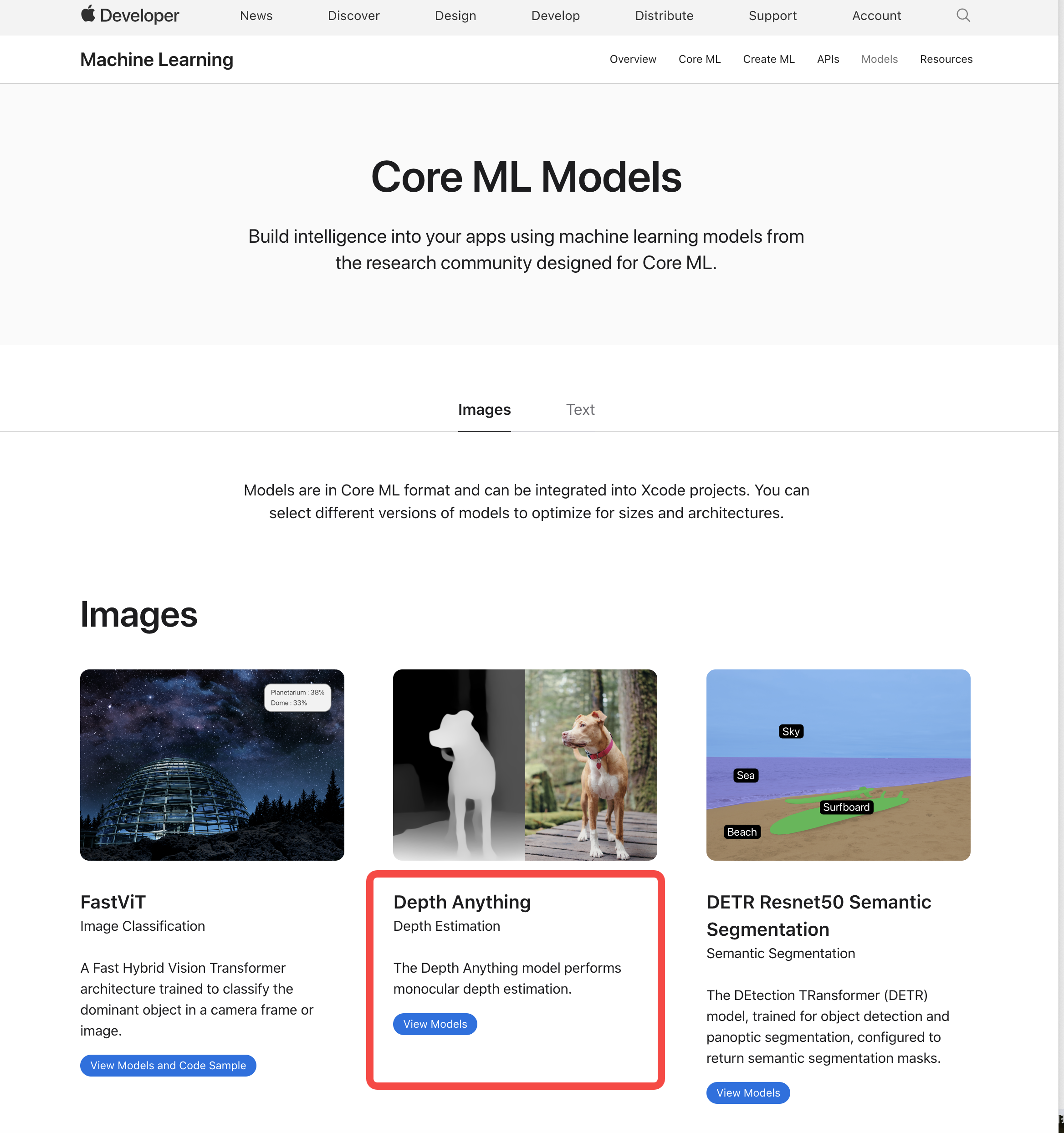
字节大模型团队Depth Anything V2模型入选苹果最新CoreML模型
Article Introduction:近日,苹果公司在HuggingFace上发布了20个新的CoreML模型和4个数据集,字节大模型团队的单目深度估计模型DepthAnythingV2入选其中。CoreML苹果公司的机器学习框架,用于将机器学习模型集成到iOS、MacOS等设备上高效运行。在无需互联网连接的情况下执行复杂的AI任务,增强用户隐私并减少延迟。苹果开发者可通过这些模型构建智能、安全的AI应用。DepthAnythingV2字节大模型团队开发的单目深度估计模型。V2版细节处理更精细,鲁棒性更强,速度显著提升。包含25M到
2024-06-29
comment 0
640

In-depth analysis of converting conceptual model into relational model
Article Introduction:Conceptual model and relational model are two models commonly used in database design. The conceptual model is used to describe the conceptual relationships between entities, while the relational model is used to describe the relationships between the data actually stored in the database. In database design, it is usually necessary to convert the conceptual model into a relational model, which is an important process. This process includes converting entities in the conceptual model into tables in the relational model, and converting relationships in the conceptual model into foreign key constraints in the relational model. Through this process, it is possible to ensure that the structure of the database is consistent with the relationship between the conceptual model, thereby achieving effective storage and query of data. The process of converting a conceptual model into a relational model mainly includes the following steps: 1. Identify entities and attributes. Entities in the conceptual model represent independently existing things, such as people.
2024-01-22
comment 0
325

一文带您了解数据模型:概念模型、逻辑模型和物理模型
Article Introduction:数据模型是组织数据管理的基石,是构建信息基础设施的关键组成部分。数据模型为组织提供了清晰的数据结构和逻辑框架,使得数据管理更加高效和可持续。在数字化时代,数据已成为企业最宝贵的资产之一,而数据模型的设计和实施,则决定了数据在企业运营和决策中的有效性和可信度。良好的数据模型不仅能够够简化复杂的数据景观,提高数据质量和一致性,还能够够优化数据库性能,支持数据分析和决策制定。因此,数据模型的意义在于为企业提供了数据驱动的决策支持,促进了业务的创新和竞争力的提升。在为企业提供了数据驱动的决策支持,促进了
2024-05-13
comment 0
200

Adapting to large low-rank models
Article Introduction:Low-rank adaptation of large models is a method to reduce complexity by approximating the high-dimensional structure of a large model with a low-dimensional structure. The aim is to create a smaller, more manageable model representation that still maintains good performance. In many tasks, redundant or irrelevant information may exist in the high-dimensional structure of large models. By identifying and removing these redundancies, a more efficient model can be created while maintaining original performance, and can use fewer resources to train and deploy. Low-rank adaptation is a method that can speed up the training of large models while also reducing memory consumption. Its principle is to freeze the weights of the pre-trained model and introduce the trainable rank decomposition matrix into each layer of the Transformer architecture, thereby significantly reducing the trainability of downstream tasks.
2024-01-23
comment 0
315

Business model and data model design techniques in Java
Article Introduction:Java is a widely used programming language. When developing software, how to design the business model and data model is crucial. This article will introduce the design technology of business model and data model in Java. 1. Business model design A business model is a model that describes the relationships between business entities, business processes, business rules and business participants. In Java development, business models are usually designed using UML (Unified Modeling Language) modeling tools. Use case diagram design A use case diagram is a diagram that describes the functionality of a system.
2023-06-09
comment 0
1472

thinkphp model definition
Article Introduction:Mainly describes the rules of thinkphp model definition, model settings and the difference between model operations and database operations.
2020-05-28
comment 0
3014

NLP model integration: Fusing GPT with other models
Article Introduction:Ensemble methods are commonly used in machine learning and can combine multiple models to reduce variance and improve accuracy and robustness. In the field of NLP, ensemble methods can give full play to the advantages of different models and overcome their shortcomings. The integration of GPT, BERT, and RoBERTa can be leveraged to fully leverage their respective strengths and offset their weaknesses. By training ensemble models, the weights of each model output can be optimized to achieve state-of-the-art performance on a variety of NLP tasks. This method can comprehensively utilize the characteristics of different models to improve overall performance and achieve better results. GPT vs. other models Although GPT is a powerful and widely used NLP model, there are other models available such as BERT, RoBERTa, and XLNe
2024-01-23
comment 0
892

Several types of html box models
Article Introduction:There are two types of HTML box models, namely the standard box model (ContentBoxModel) and the IE box model (BorderBoxModel). The standard box model is stipulated by the W3C standard. In the standard box model, the width and height of an element only include the content area (content), excluding the border (border) and padding (padding). The total width or height of an element is equal to the width or height of the content area + the width or height of the border + the width of the padding or
2024-02-19
comment 0
174

How to use the navicat model
Article Introduction:Navicat Model is a database management tool used to graphically manage database models. Specific usage methods include: creating a new model; connecting to the database; designing the model (using entities, attributes, and relationships); editing the model; reverse engineering the model; generating scripts; and synchronizing the model and database. The main advantages of Navicat models are its intuitive interface, powerful design capabilities, reverse engineering support, script generation and synchronization capabilities.
2024-04-24
comment
458
Let's talk about the model fusion method of large models
Article Introduction:In previous practices, model fusion has been widely used, especially in discriminant models, where it is considered a method that can steadily improve performance. However, for generative language models, the way they operate is not as straightforward as for discriminative models because of the decoding process involved. In addition, due to the increase in the number of parameters of large models, in scenarios with larger parameter scales, the methods that can be considered by simple ensemble learning are more limited than low-parameter machine learning, such as classic stacking, boosting and other methods, because stacking models The parameter problem cannot be easily expanded. Therefore, ensemble learning for large models requires careful consideration. Below we explain five basic integration methods, namely model integration, probabilistic integration, grafting learning, crowdsourcing voting, and MOE
2024-03-11
comment
108

What are the js box models?
Article Introduction:js box models include standard box model, IE box model, CSS3 box model, etc. Detailed introduction: 1. The standard box model is a box model defined by the W3C specification and is also the most common box model. In the standard box model, the width and height of an element only include the content area, excluding borders, padding and margins. ; 2. The IE box model is a box model unique to the IE browser. In the IE box model, the width and height of an element include the content area, inner margins, and borders, but do not include the outer margins; 3. The CSS3 box model is A new box model introduced in CSS3 and more.
2023-10-12
comment 0
481
