Found a total of 10000 related content

The difference between large language models and word embedding models
Article Introduction:Large language models and word embedding models are two key concepts in natural language processing. They can both be applied to text analysis and generation, but the principles and application scenarios are different. Large-scale language models are mainly based on statistical and probabilistic models and are suitable for generating continuous text and semantic understanding. The word embedding model can capture the semantic relationship between words by mapping words to vector space, and is suitable for word meaning inference and text classification. 1. Word embedding model The word embedding model is a technology that processes text information by mapping words into a low-dimensional vector space. It converts words in a language into vector form so that computers can better understand and process text. Commonly used word embedding models include Word2Vec and GloVe. These models are widely used in natural language processing tasks
2024-01-23comment965

Linguistics in Artificial Intelligence: Language Models in Python Natural Language Processing
Article Introduction:Natural language processing (NLP) is a field of computer science that focuses on enabling computers to communicate effectively using natural language. Language models play a crucial role in NLP. They can learn probability distributions in language to perform various processing tasks on text, such as text generation, machine translation, and sentiment analysis. Types of Language Models There are two main types of language models: n-gram language model: considers the previous n words to predict the probability of the next word, n is called the order. Neural Language Model: Use neural networks to learn complex relationships in language. Language model in Python There are many libraries in Python that can implement language models, including: nltk.lm: provides the implementation of n-gram language model. ge
2024-03-21comment994

Autoregressive properties of language models
Article Introduction:Autoregressive language model is a natural language processing model based on statistical probability. It generates continuous text sequences by leveraging previous word sequences to predict the probability distribution of the next word. This model is very useful in natural language processing and is widely used in language generation, machine translation, speech recognition and other fields. By analyzing historical data, autoregressive language models are able to understand the laws and structure of language to generate text with coherence and semantic accuracy. It can not only be used to generate text, but also to predict the next word, providing useful information for subsequent text processing tasks. Therefore, autoregressive language models are an important and practical technique in natural language processing. 1. The concept of autoregressive model. The autoregressive model is a model that uses previous observations to
2024-01-22comment 0324

Meta launches AI language model LLaMA, a large-scale language model with 65 billion parameters
Article Introduction:According to news on February 25, Meta announced on Friday local time that it will launch a new large-scale language model based on artificial intelligence (AI) for the research community, joining Microsoft, Google and other companies stimulated by ChatGPT to join artificial intelligence. Intelligent competition. Meta's LLaMA is the abbreviation of "Large Language Model MetaAI" (LargeLanguageModelMetaAI), which is available under a non-commercial license to researchers and entities in government, community, and academia. The company will make the underlying code available to users, so they can tweak the model themselves and use it for research-related use cases. Meta stated that the model’s requirements for computing power
2023-04-14comment 01313

Six pitfalls to avoid with large language models
Article Introduction:From security and privacy concerns to misinformation and bias, large language models come with risks and rewards. There have been incredible advances in artificial intelligence (AI) recently, largely due to advances in developing large language models. These are at the core of text and code generation tools such as ChatGPT, Bard, and GitHub’s Copilot. These models are being adopted across all sectors. But how they are created and used, and how they can be misused, remains a source of concern. Some countries have decided to take a drastic approach and temporarily ban specific large language models until appropriate regulations are in place. Here’s a look at some of the real-world adverse effects of large language model-based tools, and some strategies to mitigate them.
2023-05-12comment 0867

Introduction to the memory model of Go language
Article Introduction:The memory model of Go language details the condition that "reading a variable in one goroutine can detect writing operations to the variable in other goroutine". This article introduces the memory model of Go language to everyone. I hope it will be useful to everyone. There is some help.
2020-01-10comment 01789

Introduction to mathematical models in Java language
Article Introduction:The Java language is a high-level programming language that is well suited for the construction and analysis of mathematical models. Mathematical models are the application of mathematical concepts in the real world. They are often used to solve practical problems, such as predicting future trends, optimizing production and manufacturing, etc. This article will introduce common mathematical models and their applications in the Java language. Linear programming Linear programming is an optimization method that is widely used in solving problems such as optimal corporate decision-making, resource allocation, and production planning. In Java language, you can use Apache Commons
2023-06-10comment 01014
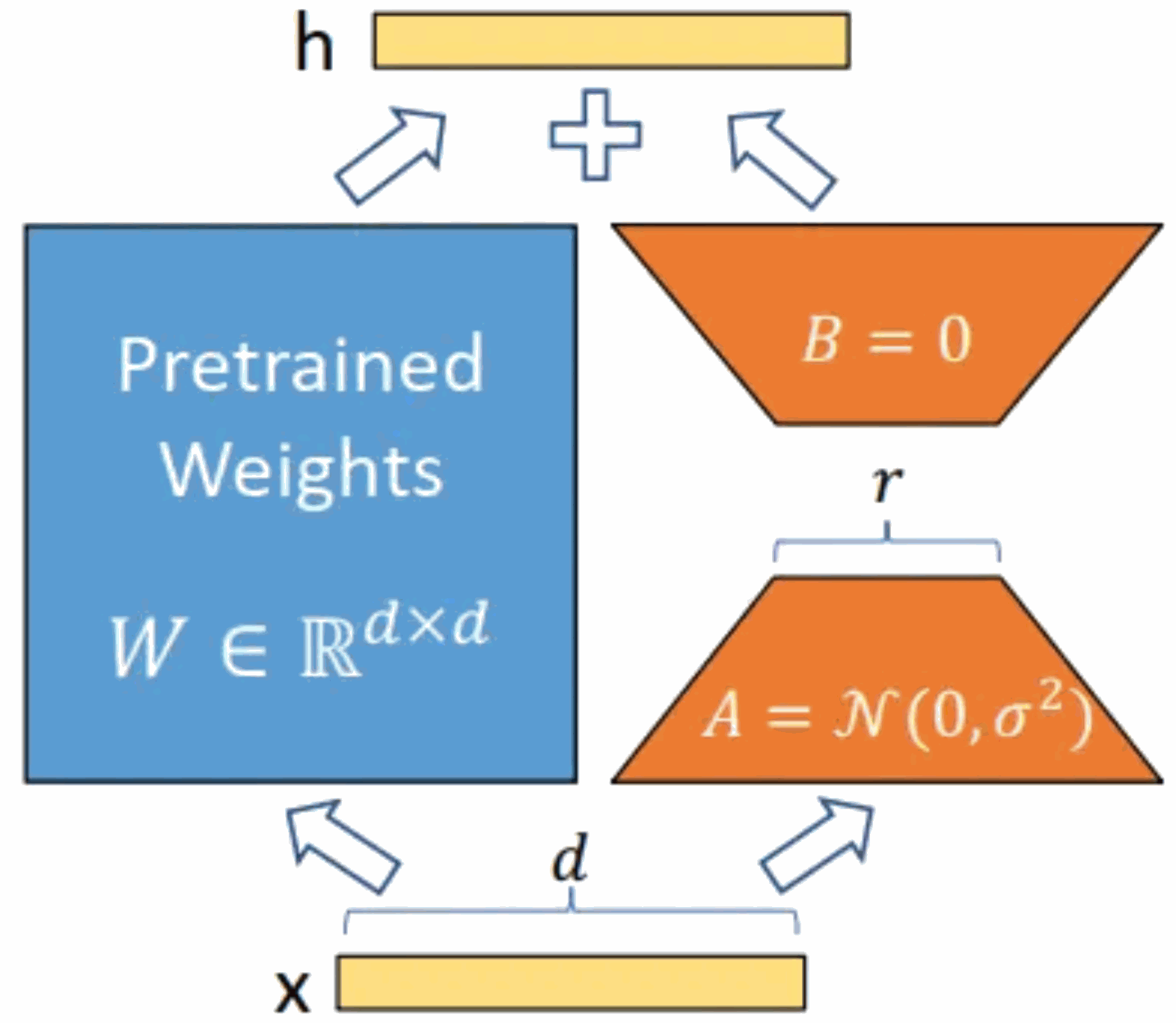
GPT large language model Alpaca-lora localization deployment practice
Article Introduction:Model introduction: The Alpaca model is an LLM (Large Language Model, large language) open source model developed by Stanford University. It is fine-tuned from the LLaMA7B (7B open source by Meta company) model on 52K instructions. It has 7 billion model parameters (the larger the model parameters, the larger the model parameters). , the stronger the model's reasoning ability, of course, the higher the cost of training the model). LoRA, the full English name is Low-RankAdaptation of Large Language Models, literally translated as low-level adaptation of large language models. This is a technology developed by Microsoft researchers to solve the fine-tuning of large language models. If you want a pre-trained large language model to be able to perform a specific domain
2023-06-01comment 01234
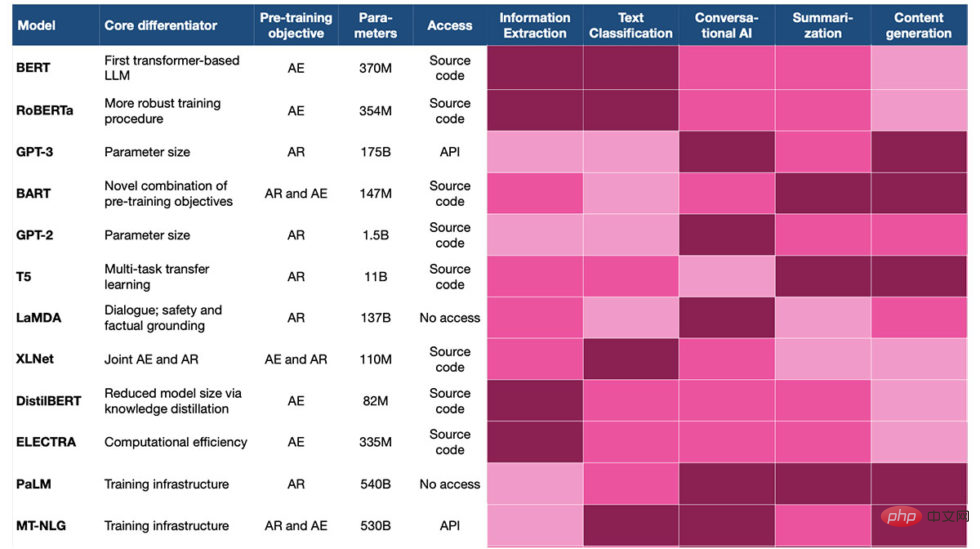
Choosing the right language model for NLP
Article Introduction:Translator | Reviewed by Cui Hao | Sun Shujuan 1. Opening Large language models (LLMs) are deep learning models trained to generate text. With impressive capabilities, LLMs have become the leader in modern natural language processing (NLP). Traditionally, they have been pre-trained by academic institutions and large technology companies such as OpenAI, Microsoft and Nvidia. Most of them are subsequently made available for public use. This plug-and-play approach is an important step towards large-scale AI applications - enterprises can now focus on fine-tuning existing LLM models for specific use cases, rather than spending significant resources to train models with general language capabilities. Model of knowledge. However, picking the right model for your application can still be tricky
2023-04-14comment 0746

Methods and introduction to language model decoupling
Article Introduction:Language model is one of the basic tasks of natural language processing, and its main goal is to learn the probability distribution of language. Predict the probability of the next word given the previous text. To implement this model, neural networks such as Recurrent Neural Networks (RNN) or Transformers are often used. However, the training and application of language models are often affected by coupling issues. Coupling refers to the dependencies between parts of the model, so modifications to one part may have an impact on other parts. This coupling phenomenon complicates the optimization and improvement of the model, requiring the interaction between the various parts to be addressed while maintaining overall performance. The goal of decoupling is to reduce dependencies, enable model parts to be trained and optimized independently, and improve performance and scalability.
2024-01-23comment303
go语言模板类型有哪些
Article Introduction:Go语言模板系统提供了多种模板类型,包括:文本模板:用于生成纯文本,支持基本控制结构。HTML 模板:专用于生成 HTML 输出,提供自动 HTML 转义功能。自定义模板:可自行创建模板类型,扩展特定功能。
2024-07-27comment 0633

Common method: measuring the perplexity of a new language model
Article Introduction:There are many ways to evaluate new language models, some of which are based on evaluation by human experts, while others are based on automated evaluation. Each of these methods has advantages and disadvantages. This article will focus on perplexity methods based on automated evaluation. Perplexity is a metric used to evaluate the quality of language models. It measures the predictive power of a language model given a set of data. The smaller the value of confusion, the better the prediction ability of the model. This metric is often used to evaluate natural language processing models to measure the model's ability to predict the next word in a given text. Lower perplexity indicates better model performance. In natural language processing, the purpose of a language model is to predict the probability of the next word in a sequence. Given a sequence of words
2024-01-22comment827

Reverse thinking: MetaMath new mathematical reasoning language model trains large models
Article Introduction:Complex mathematical reasoning is an important indicator for evaluating the reasoning ability of large language models. Currently, the commonly used mathematical reasoning data sets have limited sample sizes and insufficient problem diversity, resulting in the phenomenon of "reversal curse" in large language models, that is, a person trained on "A is B" "The language model cannot be generalized to "B is A" [1]. The specific form of this phenomenon in mathematical reasoning tasks is: given a mathematical problem, the language model is good at using forward reasoning to solve the problem but lacks the ability to solve the problem with reverse reasoning. Reverse reasoning is very common in mathematical problems, as shown in the following two examples. 1. Classic question - Forward reasoning of chickens and rabbits in the same cage: There are 23 chickens and 12 rabbits in the cage. How many heads and how many feet are there in the cage? Reverse reasoning: There are several chickens and rabbits in the same cage. Counting from the top, there are 3
2023-10-11comment 0560

In-depth understanding of the coroutine and concurrency model of Go language
Article Introduction:Deeply understand the coroutine and concurrency model of Go language. Go language is a programming language that has risen rapidly in recent years. Its unique concurrency model and coroutine mechanism have become one of the main reasons for its popularity. The concurrency model of Go language and the characteristics of coroutines make concurrent programming simpler and more efficient. This article will delve into the coroutine and concurrency model of the Go language. First, we need to understand what coroutines are. Coroutines, also known as lightweight threads, are a very flexible concurrent programming model. Compared with traditional threads, coroutines are more portable and their creation and destruction
2023-11-30comment 0794

How to convey intent to language model using grammar
Article Introduction:Grammar is very important in natural language processing and language models, as it helps models understand the structure and relationships between language components. Grammar is a set of rules that describes the structure, order, and relationships of words and phrases in a language. These rules can be expressed in the form of formal grammars or natural language text. These rules can then be transformed into a computer-understandable form such as a context-free grammar (CFG) or a dependency grammar (DG). These formal grammar rules provide the basis for computer language processing, enabling computers to understand and process human language. By applying these rules, we can perform operations such as syntax analysis, syntax tree generation, and semantic parsing to achieve tasks such as natural language processing and machine translation. In natural language processing, grammar
2024-01-22comment 0750

Improving data annotation methods for large language models (LLM)
Article Introduction:Fine-tuning of large-scale language models (LLMs) involves retraining a pre-trained model using domain-specific data to adapt it to a specific task or domain. Data annotation plays a crucial role in the fine-tuning process and involves labeling data with specific information that the model needs to understand. 1. Principle of data annotation Data annotation is to help machine learning models better understand and process data by adding metadata, such as tags, tags, etc., to the data. For the fine-tuning of large language models, the principle of data annotation is to provide guiding information to help the model better understand the language and context of a specific domain. Common data annotation methods include entity recognition, sentiment analysis, and relationship extraction. 2. Methods of data annotation 2.1 Entity recognition Entity recognition is a kind of information extraction
2024-01-22comment 0591

OpenAI develops new tool to try to explain the behavior of language models
Article Introduction:Language modeling is an artificial intelligence technology that can generate natural language from given text. OpenAI's GPT series language models are one of the most advanced representatives at present, but IT House has noticed that they also have a problem: their behavior is difficult to understand and predict. To make language models more transparent and trustworthy, OpenAI is developing a new tool that can automatically identify which parts of a language model are responsible for its behavior and explain it in natural language. The principle of this tool is to use another language model (that is, OpenAI's latest GPT-4) to analyze the internal structure of other language models (such as OpenAI's own GPT-2). A language model is made up of many "neurons", each of which can observe something in the text.
2023-05-12comment 0903

Application of decoding strategies in large language models
Article Introduction:Large-scale language models are a key technology in the field of natural language processing, showing strong performance in various tasks. Decoding strategy is one of the important aspects of text generation by the model. This article will detail decoding strategies in large language models and discuss their advantages and disadvantages. 1. Overview of decoding strategies In large language models, decoding strategies are methods for generating text sequences. Common decoding strategies include greedy search, beam search, and random search. Greedy search is a simple and straightforward method that selects the word with the highest probability as the next word each time, but may ignore other possibilities. Beam search adds a width limit to greedy search, retaining only the candidate words with the highest probability, thereby increasing diversity. Random search randomly selects the next word, which can produce more diverse
2024-01-22comment 0884

LLM large language model and retrieval enhancement generation
Article Introduction:LLM large language models are usually trained using the Transformer architecture to improve the ability to understand and generate natural language through large amounts of text data. These models are widely used in chatbots, text summarization, machine translation and other fields. Some well-known LLM large language models include OpenAI's GPT series and Google's BERT. In the field of natural language processing, retrieval-enhanced generation is a technique that combines retrieval and generation. It generates text that meets requirements by retrieving relevant information from large-scale text corpora and using generative models to recombine and arrange this information. This technique has a wide range of applications, including text summarization, machine translation, dialogue generation, and other tasks. Retrieval enhancement by taking advantage of retrieval and generation
2024-01-23comment 0910
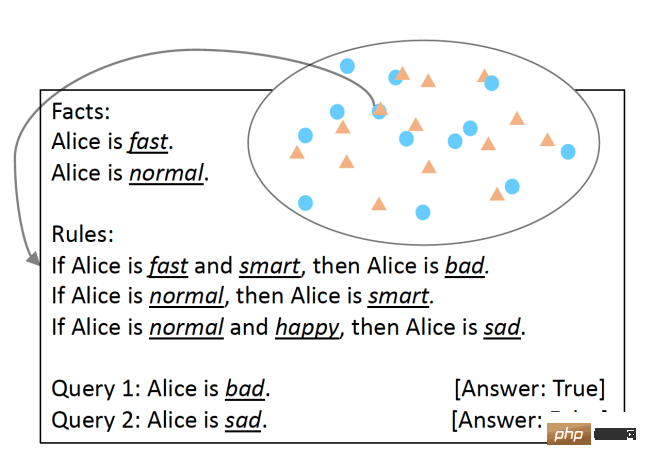
Study shows large language models have problems with logical reasoning
Article Introduction:Translator | Reviewed by Li Rui | Sun Shujuan Before chatbots with sentient capabilities became a hot topic, large language models (LLM) had already caused more excitement and concern. In recent years, large language models (LLMs), deep learning models trained on large amounts of text, have performed well on several benchmarks used to measure language understanding capabilities. Large language models such as GPT-3 and LaMDA manage to maintain coherence across longer texts. They seem knowledgeable about different topics and remain consistent throughout lengthy conversations. Large language models (LLMs) have become so convincing that some people associate them with personality and higher forms of intelligence. But large language models (LLMs) can behave like humans
2023-04-12comment 0688
