


The Alpaca model is an LLM (Large Language Model, big language) open source model developed by Stanford University. It is a fine-tuned model on 52K instructions from the LLaMA 7B (7B open source by Meta Company) , with 7 billion model parameters (the larger the model parameters, the stronger the model’s reasoning ability, and of course the higher the cost of training the model).
LoRA, the full English name is Low-Rank Adaptation of Large Language Models, literally translated as low-level adaptation of large language models. This is a technology developed by Microsoft researchers to solve the fine-tuning of large language models. If you want a pre-trained large language model to be able to perform tasks in a specific field, you generally need to do fine-tuning. However, the current parameter dimensions of large language models with good inference effects are very, very large, and some are even hundreds of billions of dimensions. If you directly Performing fine-tuning on a large language model will require a very large amount of calculations and a very high cost.
'LoRA's approach is to freeze the pre-trained model parameters, and then inject trainable layers into each Transformer block. Since there is no need to recalculate the gradient of the model parameters, it will greatly reduce the calculation. quantity.
As shown in the figure below, the core idea is to add a bypass to the original pre-trained model and perform a dimensionality reduction and then dimensionality operation. During training, the parameters of the pre-trained model are fixed, and only the dimensionality reduction matrix A and the dimensionality enhancement matrix B are trained. The input and output dimensions of the model remain unchanged, and the BA and the parameters of the pre-trained language model are superimposed on the output.
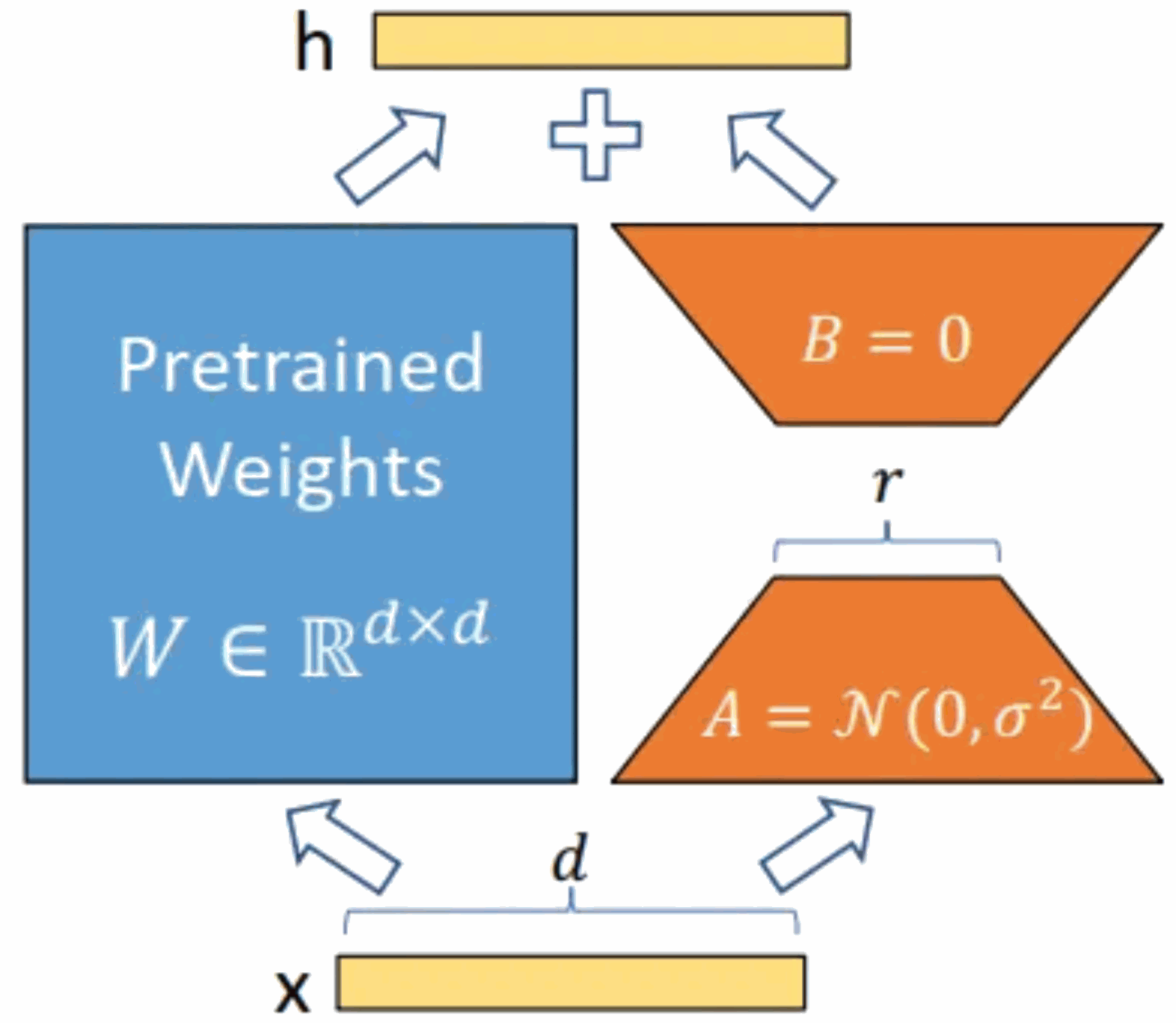
Initialize A with a random Gaussian distribution and initialize B with a 0 matrix. This ensures that the new bypass BA=0 during training, thus having no impact on the model results. During reasoning, the results of the left and right parts are added together, that is, h=Wx BAx=(W BA)x. Therefore, just add the matrix product BA after training and the original weight matrix W as the new weight parameter replacement. The W of the original pre-trained language model is enough, and no additional computing resources will be added. The biggest advantage of LoRA is that it trains faster and uses less memory.
The Alpaca-lora model used for localized deployment practice in this article is a low-order adaptation version of the Alpaca model. This article will practice the localization deployment, fine-tuning and inference process of the Alpaca-lora model and describe the relevant steps.
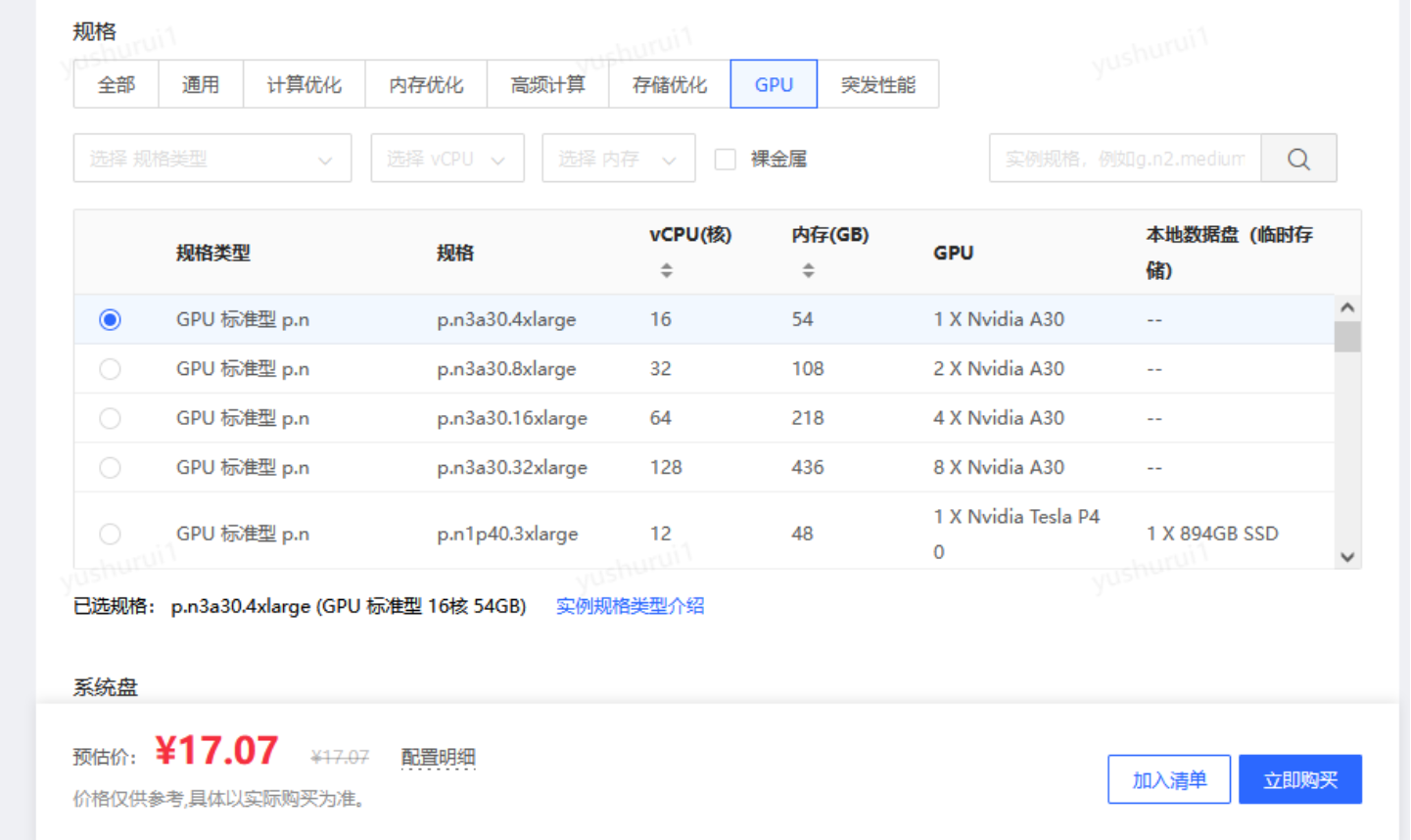
The GPU server deployed in this article has 4 independent GPUs, the model is P40, and the computing power of a single P40 is equivalent to 60 The computing power of a CPU with the same main frequency.

#If you just feel that the physical card is too expensive for testing, you can also use the "replacement version" - GPU cloud server. Compared with physical cards, using GPU cloud servers to build not only ensures flexible high-performance computing, but also has these benefits -
Jingdong Cloud’s GPU cloud host is currently doing 618 activities, which is very cost-effective
//m.sbmmt.com/link/5d3145e1226fd39ee3b3039bfa90c95d
When we get the GPU server, we first install the graphics card driver and CUDA driver (which is a computing platform launched by graphics card manufacturer NVIDIA. CUDA is a general parallel computing architecture launched by NVIDIA, which enables GPU Ability to solve complex computational problems).
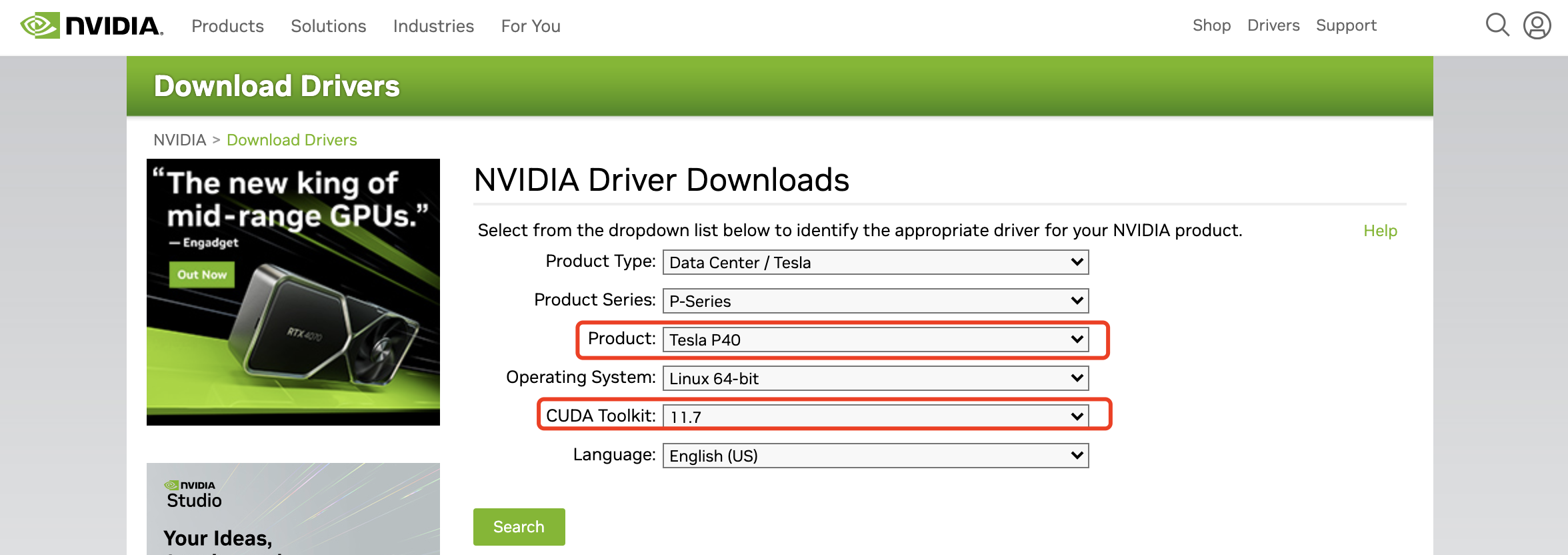
The graphics card driver needs to go to NVIDIA's official website to find the corresponding graphics card model and adapted CUDA version. Download address:
https://www.nvidia.com/Download/index.aspx, select You can download the driver file for the corresponding graphics card and CUDA version.
#The file I downloaded is
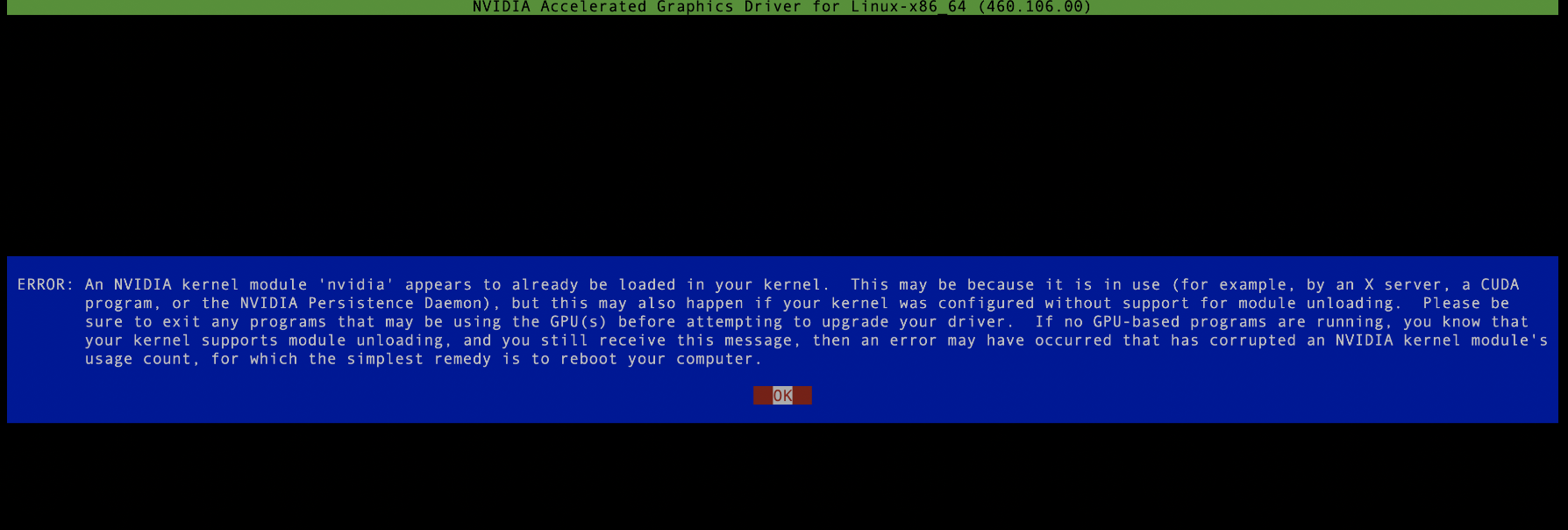
NVIDIA-Linux-x86_64-515.105.01.run, this is an executable file, which can be executed with root permissions. Note that there cannot be running nvidia processes during the driver installation process. If necessary, kill them all, otherwise it will The installation failed, as shown in the figure below:
Then proceed all the way to next. If no error is reported, the installation is successful. In order to check the graphics card resources later, it is best to install another graphics card monitoring tool, such as nvitop, just use pip install nvitop. Note here that since the python versions of different servers are different, it is best to install anaconda to deploy your own private python space to prevent Various strange errors occur when running. The specific steps are as follows:
1. Install anaconda. Download method: wget
https://repo.anaconda.com/archive/Anaconda3-5.3.0-Linux-x86_64 .sh. Installation command: sh Anaconda3-5.3.0-Linux-x86_64.sh Enter "yes" for each installation step, and finally complete the installation after conda init, so that every time you enter the installation user's session, you will directly enter your own python environment. If you choose no in the last step of installation, that is, conda init is not performed, you can later enter the private python environment through source /home/jd_ad_sfxn/anaconda3/bin/activate.
2. Install setuptools Next, you need to install the packaging and distribution tool setuptools. Download address: wget
https://files.pythonhosted.org/packages/26/e5/9897eee1100b166a61f91b68528cb692e8887300d9cbdaa1a349f6304b79/setuptools-40.5.0 .zip installation command: unzip setuptools-40.5.0.zip cd setuptools-40.5.0/ python setup.py install
3. Install pip download address: wget
https://files.pythonhosted. org/packages/45/ae/8a0ad77defb7cc903f09e551d88b443304a9bd6e6f124e75c0fbbf6de8f7/pip-18.1.tar.gz Installation command: tar -xzf pip-18.1.tar.gz cd pip-18.1 python setup.py install
So far, it’s been a long time installation The process has finally come to an end. We now create a private python space, execute
conda create -n alpaca pythnotallow=3.9conda activate alpaca
and verify it. As shown in the figure below, it indicates that it has been created successfully.

The basic environment of the GPU server has been installed above, and now we are about to start the exciting model training (exciting ing ), before training we first need to download the model file, download address:
https://github.com/tloen/alpaca-lora, the entire model is open source, which is great! First, download the model file locally and execute git clone https://github.com/tloen/alpaca-lora.git.
There will be a folder alpaca-lora locally, and then cd alpaca-lora to execute inside the folder
pip install -r requirements.txt
This process may be slow and requires downloading a large number of dependency packages from the Internet. Various package conflicts and missing dependencies may also be reported. In this area, you can only try to find out what is missing. (Resolving package dependencies and version conflicts is indeed a headache. However, if this step is not done well, the model will also run. can't get up, so I can only solve it patiently bit by bit). I won't go into details about the painful process here, because different machines may encounter different problems, so the reference significance is not very great.
If the installation process is completed, no error message is reported, and the prompt Successful completed, then congratulations, the long march of thousands of miles has been completed, and you are very close to success. Just hold on a little longer. It's very likely to succeed :).
Since our goal is to fine-tuning the model, we have to have a fine-tuning goal. Since the original model does not support Chinese well, our goal is to use the Chinese corpus To make the model better support Chinese, this community has also prepared it for me. We can just download the Chinese corpus directly and execute wget
https://github.com/LC1332/Chinese-alpaca-lora/ locally. blob/main/data/trans_chinese_alpaca_data.json?raw=true, download the corpus used for later model training to the root directory of alpaca-lora (for convenience later).
The content of the corpus is a lot of triples (instruction, input, output, as shown in the figure below). Instruction is the instruction to let the model do something, input is the input, and output is the output of the model. According to the instruction and input, what information should be output by the training model so that the model can better adapt to Chinese.

好的,到现在为止,万里长征已经走完2/3了,别着急训练模型,我们现在验证一下GPU环境和CUDA版本信息,还记得之前我们安装的nvitop嘛,现在就用上了,在本地直接执行nvitop,我们就可以看到GPU环境和CUDA版本信息了,如下图:
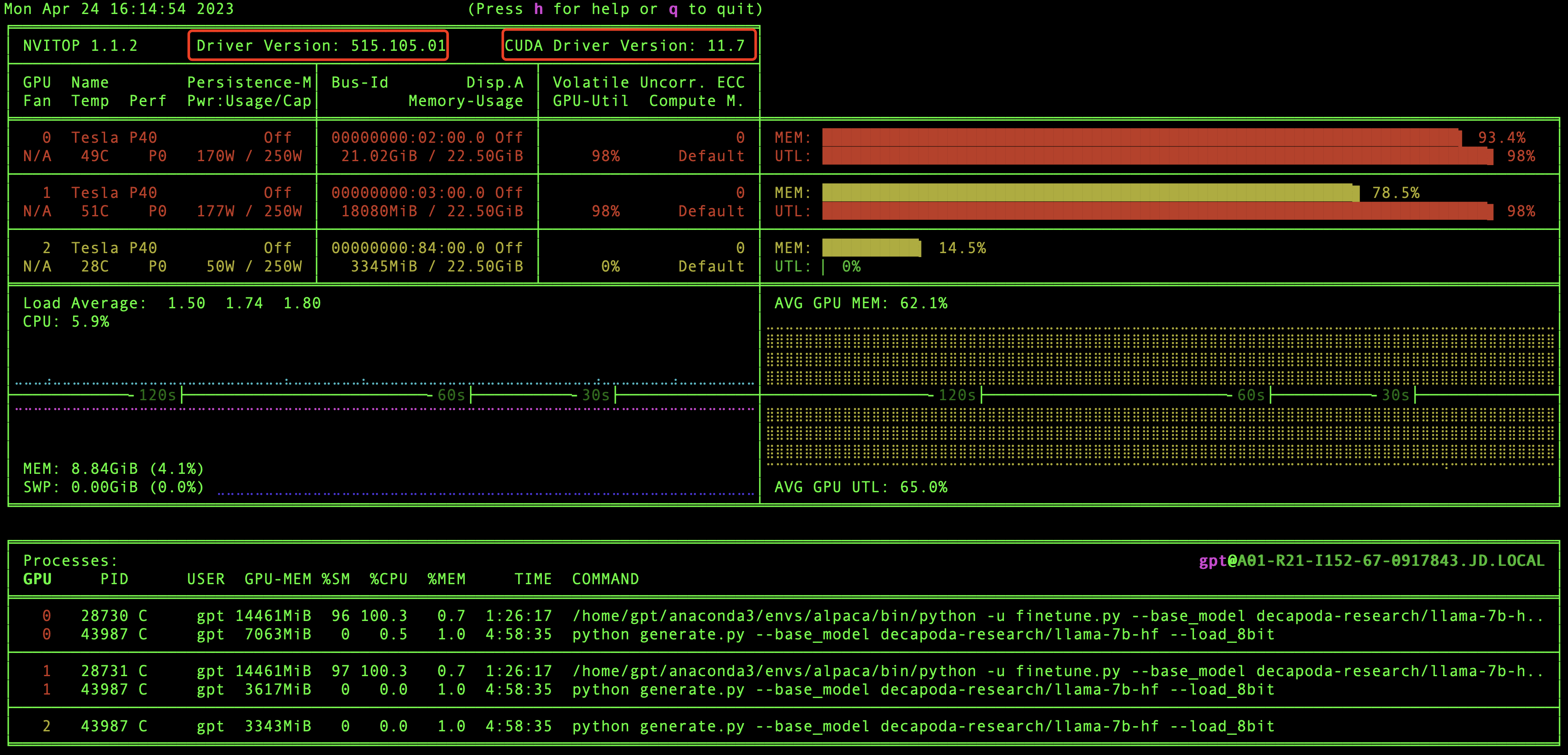
在这里我们能够看到有几块显卡,驱动版本和CUDA版本等信息,当然最重要的我们还能看到GPU资源的实时使用情况。
怎么还没到模型训练呢,别着急呀,这就来啦。
我们先到根目录下然后执行训练模型命令:
如果是单个GPU,那么执行命令即可:
python finetune.py \--base_model 'decapoda-research/llama-7b-hf' \--data_path 'trans_chinese_alpaca_data.json' \--output_dir './lora-alpaca-zh'
如果是多个GPU,则执行:
WORLD_SIZE=2 CUDA_VISIBLE_DEVICES=0,1 torchrun \--nproc_per_node=2 \--master_port=1234 \finetune.py \--base_model 'decapoda-research/llama-7b-hf' \--data_path 'trans_chinese_alpaca_data.json' \--output_dir './lora-alpaca-zh'
如果可以看到进度条在走,说明模型已经启动成功啦。
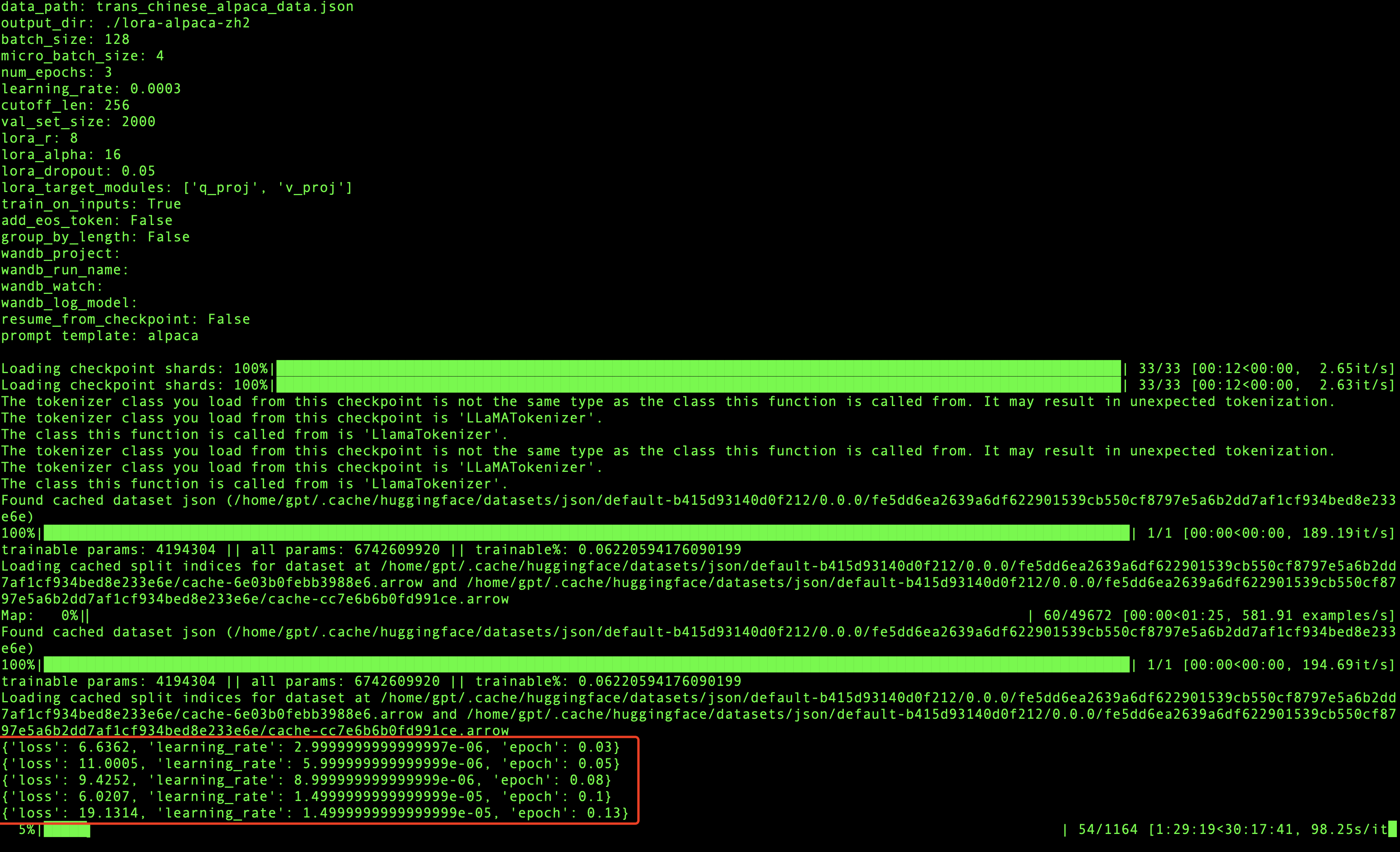
在模型训练过程中,每迭代一定数量的数据就会打印相关的信息,会输出损失率,学习率和代信息,如上图所示,当loss波动较小时,模型就会收敛,最终训练完成。
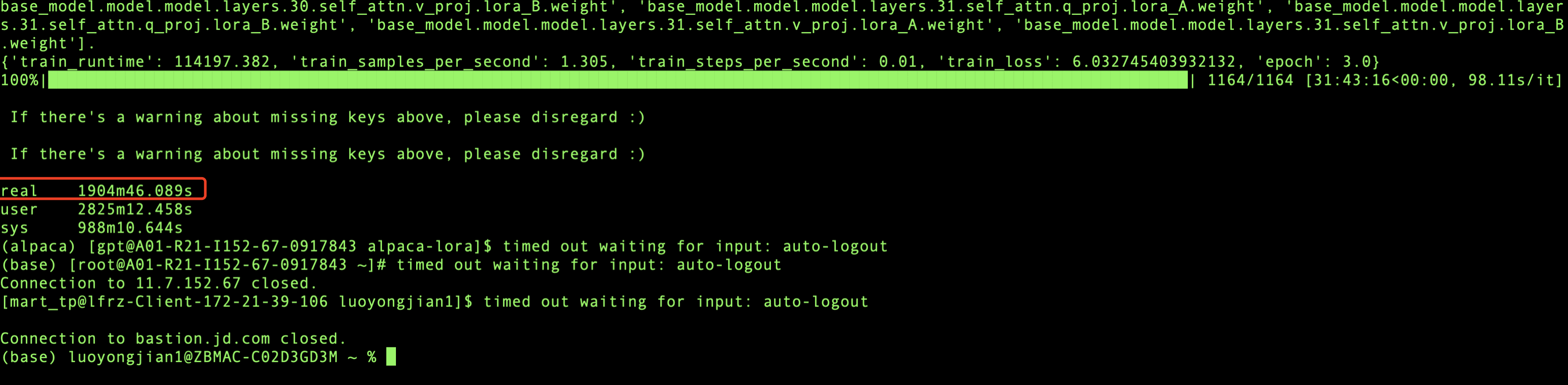
我用的是2块GPU显卡进行训练,总共训练了1904分钟,也就是31.73个小时,模型就收敛了,模型训练是个漫长的过程,所以在训练的时候我们可以适当的放松一下,做点其他的事情:)。
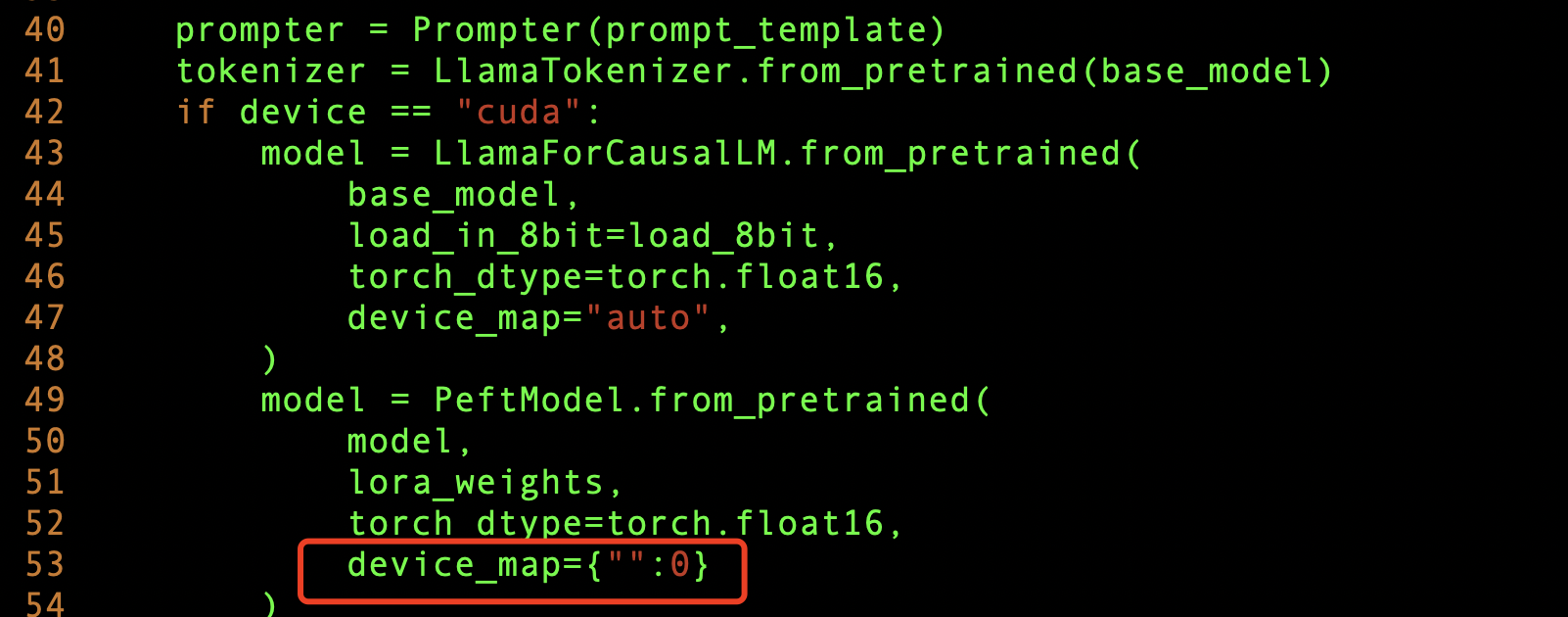
模型训练好后,我们就可以测试一下模型的训练效果了,由于我们是多个GPU显卡,所以想把模型参数加载到多个GPU上,这样会使模型推理的更快,需要修改
generate.py 文件,添加下面这样即可。
然后我们把服务启起来,看看效果,根目录执行:
python generate.py --base_model "decapoda-research/llama-7b-hf" \--lora_weights './lora-alpaca-zh' \--load_8bit
其中./lora-alpaca-zh目录下的文件,就是我们刚刚fine tuning模型训练的参数所在位置,启动服务的时候把它加载到内存(这个内存指的是GPU内存)里面。
如果成功,那么最终会输出相应的IP和Port信息,如下图所示:

我们可以用浏览器访问一下看看,如果能看到页面,就说明服务已经启动成功啦。
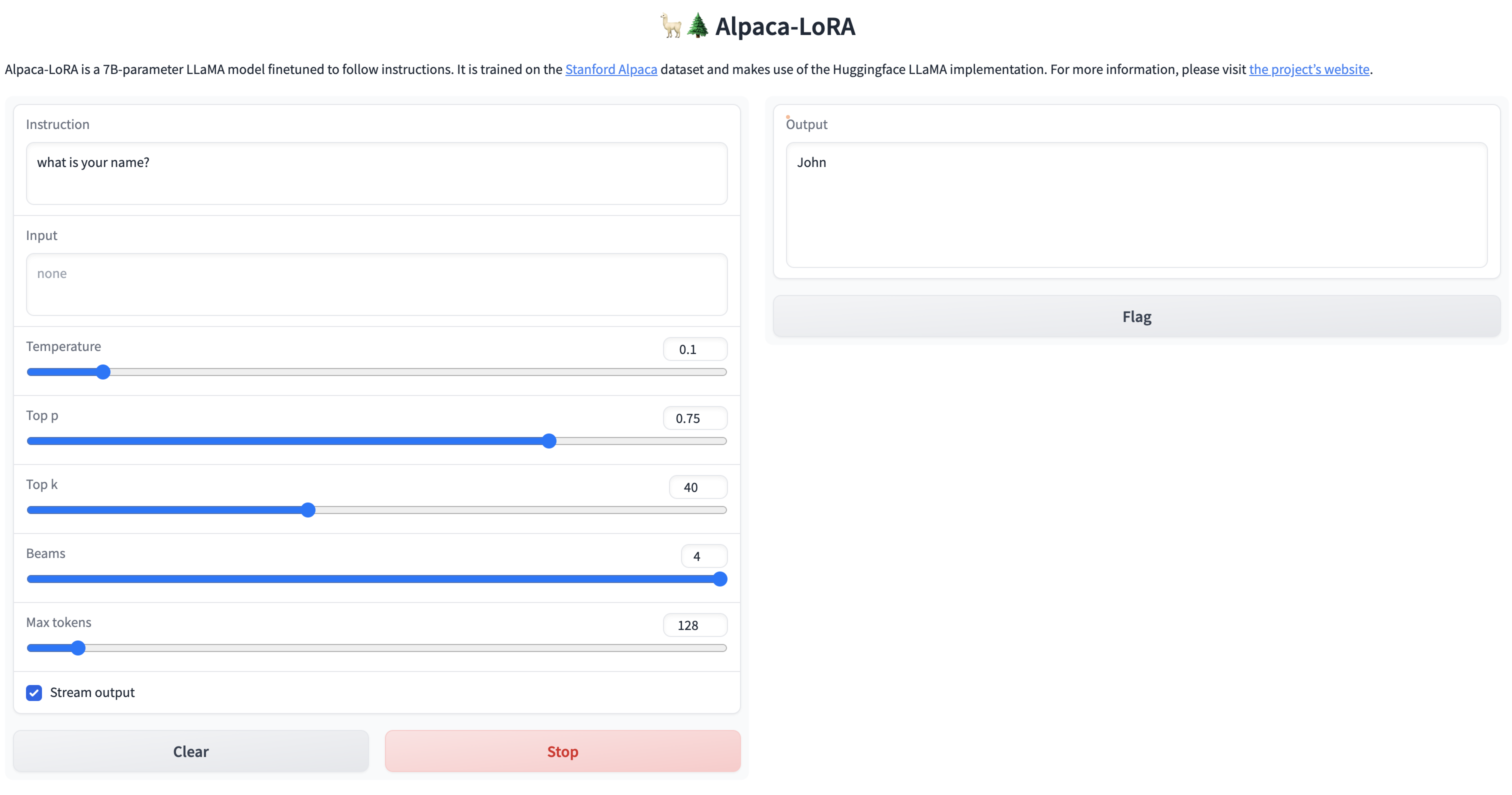
激动ing,费了九牛二虎之力,终于成功啦!!
因为我们目标是让模型说中文,所以我们测试一下对中文的理解,看看效果怎么样?
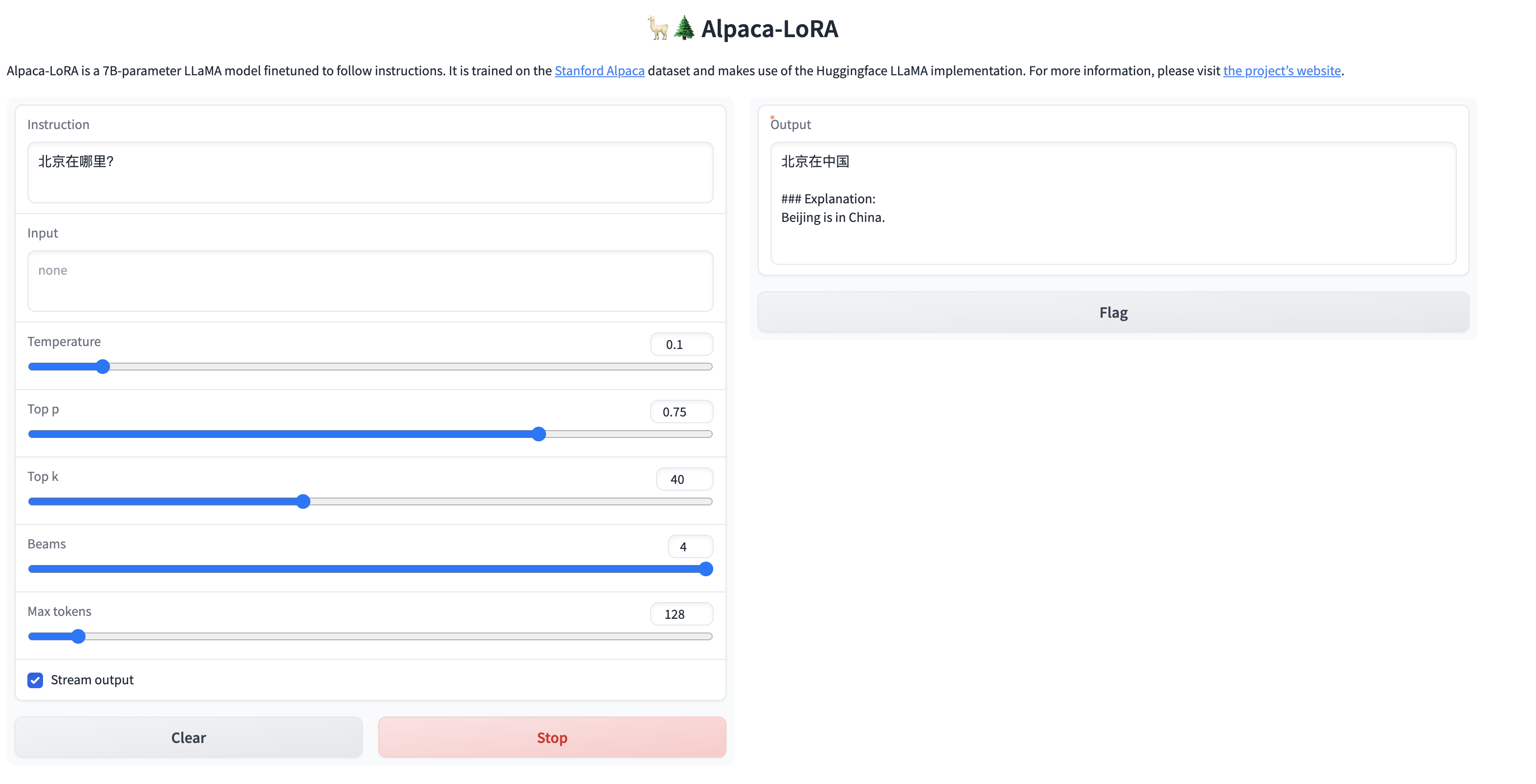
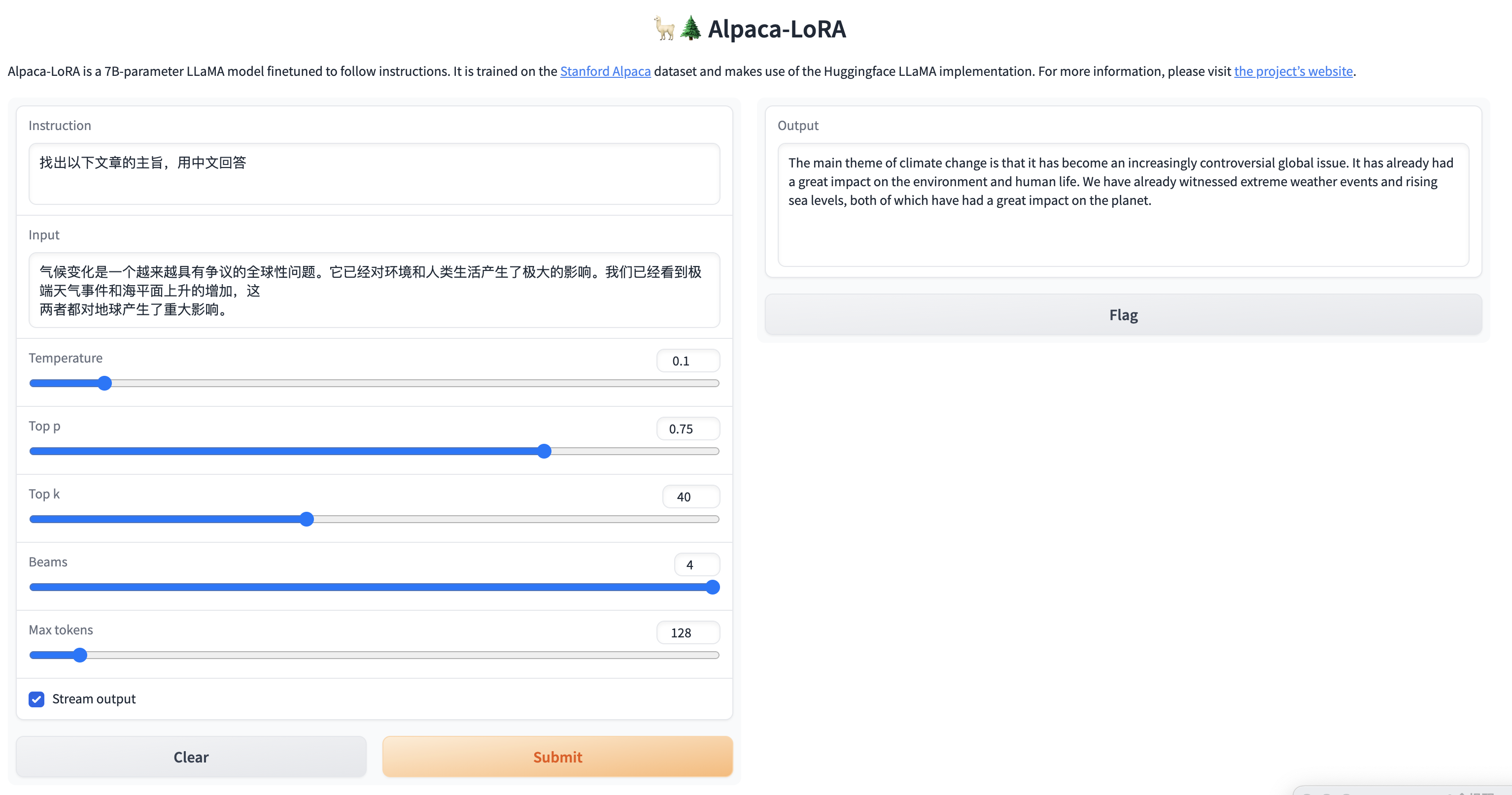
简单的问题,还是能给出答案的,但是针对稍微复杂一点的问题,虽然能够理解中文,但是并没有用中文进行回答,训练后的模型还是不太稳定啊。
在推理的时候我们也可以监控一下GPU的变化,可以看到GPU负载是比较高的,说明GPU在进行大量的计算来完成推理。
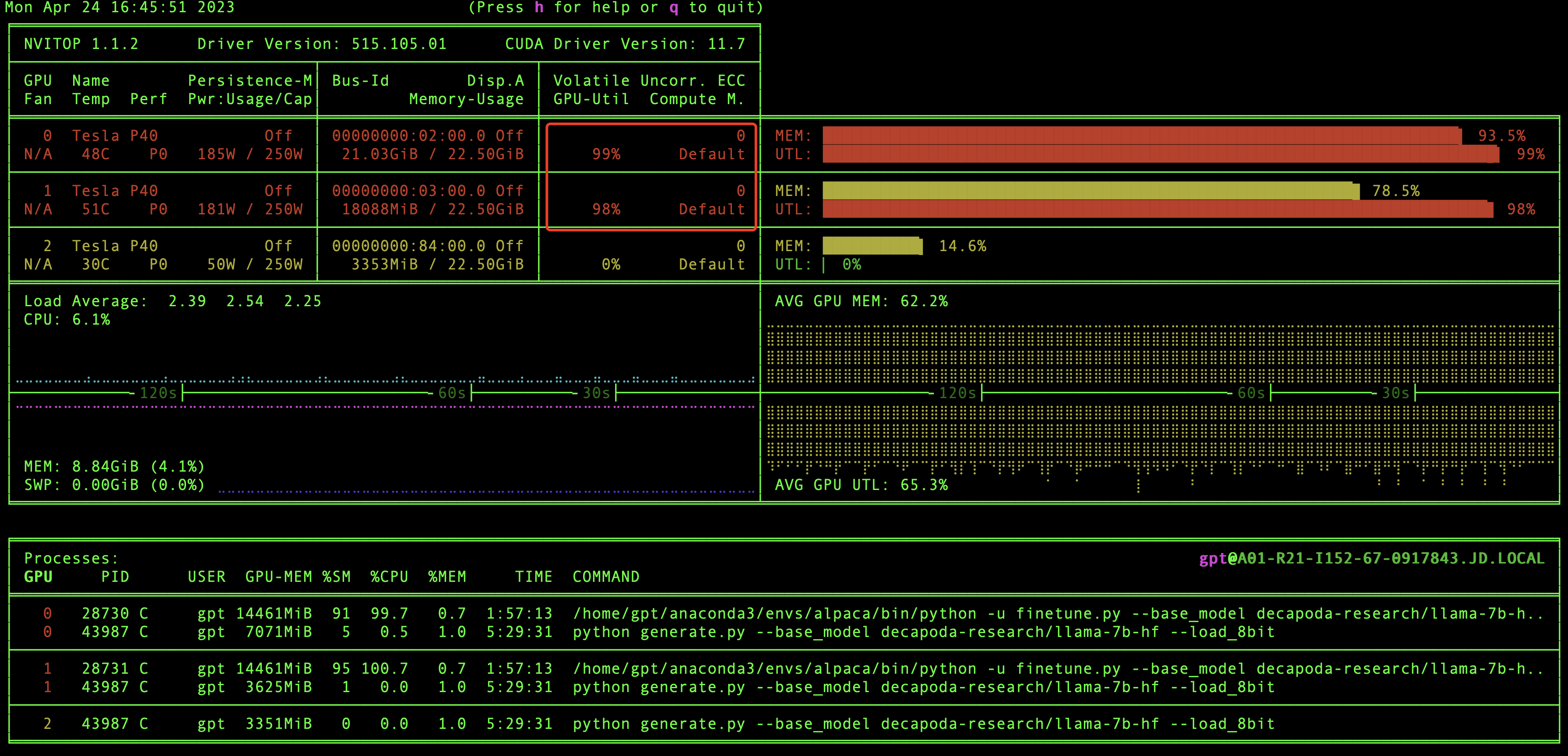
1.效果问题:由于语料库不够丰富,所以目前用社区提供的语料库训练的效果并不是很好,对中文的理解力有限,如果想训练出能够执行特定领域的任务,则需要大量的语料支持,同时训练时间也会更长;
2. Inference time problem: Since the currently deployed GPU server has 4 GPUs, 3 of them can be executed. Based on 3 GPUs, inference is still quite difficult. It takes about 30s-1min to execute an interaction. If it returns in real time like chatGPT, it will require a lot of computing power to support it. It can be inferred that the backend of chatGPT must be supported by a large cluster of computing power, so if you want to make it a service, cost investment is an issue that needs to be considered;
3. Chinese garbled code problem: When the input is Chinese, sometimes the returned results will be garbled. It is suspected to be related to word segmentation. Due to Chinese encoding problems, Chinese is not distinguished by spaces like English, so there may be certain errors. Garbled characters will occur, and this will also happen when calling open AI's API. We will see if the community has corresponding solutions later;
4. Model selection problem: Since the GPT community is currently relatively active, the generation and changes of models It is also changing with each passing day. Due to the rush of time, we have only investigated the localized deployment of the alpaca-lora model. There should be better and lower-cost implementation solutions for actual implementation in the future. We need to continue to follow the development of the community and choose the right one. open source solutions.
For details on the [ChatGLM language model] practice of JD Cloud P40 model GPU://m.sbmmt.com/link/f044bd02e4fe1aa3315ace7645f8597a
Author: JD Retail Luo Yongjian
Content source: JD Cloud Developer Community
The above is the detailed content of GPT large language model Alpaca-lora localization deployment practice. For more information, please follow other related articles on the PHP Chinese website!
 A memory that can exchange information directly with the CPU is a
A memory that can exchange information directly with the CPU is a ChatGPT registration
ChatGPT registration What are the windowing functions?
What are the windowing functions? MySQL's storage engine for modifying data tables
MySQL's storage engine for modifying data tables What are the marquee parameters?
What are the marquee parameters? Solutions to unknown software exception exceptions in computer applications
Solutions to unknown software exception exceptions in computer applications How to delete blank pages in word
How to delete blank pages in word what is vuex
what is vuex




















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



