Found a total of 3040 related content
Efficient parameter fine-tuning of large-scale language models--BitFit/Prefix/Prompt fine-tuning series
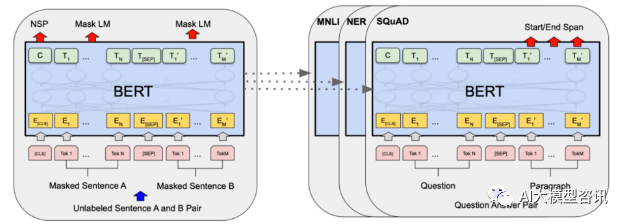
Article Introduction:In 2018, Google released BERT. Once it was released, it defeated the State-of-the-art (Sota) results of 11 NLP tasks in one fell swoop, becoming a new milestone in the NLP world. The structure of BERT is shown in the figure below. On the left is the BERT model preset. The training process, on the right is the fine-tuning process for specific tasks. Among them, the fine-tuning stage is for fine-tuning when it is subsequently used in some downstream tasks, such as text classification, part-of-speech tagging, question and answer systems, etc. BERT can be fine-tuned on different tasks without adjusting the structure. Through the task design of "pre-trained language model + downstream task fine-tuning", it brings powerful model effects. Since then, "pre-training language model + downstream task fine-tuning" has become the mainstream training in the NLP field.
2023-10-07
comment 0
909

Sentiment analysis using model fine-tuning
Article Introduction:Fine-tuning refers to making slight adjustments to a pre-trained model on a specific task to improve performance. In sentiment analysis, pre-trained natural language processing models (such as BERT, RoBERTa, ALBERT) can be used as the basic model and fine-tuned in combination with specific sentiment analysis data sets to achieve more accurate sentiment analysis results. Through fine-tuning, the model can be adapted according to the needs of specific tasks and improve the performance of the model on specific tasks. The purpose of fine-tuning the model is to fine-tune the general natural language processing model to improve its recognition ability and prediction accuracy in sentiment analysis tasks. Through fine-tuning, we can transfer the learning capabilities of the model to specific areas, making it better suited to specific task requirements. Such fine-tuning
2024-01-22
comment 0
745

ReFT (Representation Fine-tuning): a new large language model fine-tuning technology that is better than PeFT
Article Introduction:ReFT (Representation Finetuning) is a breakthrough method that promises to redefine the way we fine-tune large language models. According to a recent (April) paper published on arxiv by researchers at Stanford University, ReFT is significantly different from traditional weight-based fine-tuning methods, providing a more efficient and effective way to adapt to these large-scale models to Adapt to new tasks and areas! Before introducing this paper, let's take a look at PeFT. Parameter Efficient Fine-Tuning PeFTParameterEfficientFine-Tuning (PEFT) is an efficient fine-tuning method for fine-tuning a small number or additional model parameters. Fine-tuning with traditional predictive networks
2024-04-15
comment
812
OpenAI releases new AI fine-tuning tool: 'The vast majority of organizations will develop custom models'
Article Introduction:OpenAI has announced major enhancements to its fine-tuning API, as well as an expansion of its custom model routine. These updates will give developers unprecedented control to fine-tune AI models and provide new ways to build customized models for specific business needs. Since its launch in August 2023, GPT-3.5’s fine-tuning API has become a turning point in combining refined AI models to perform specific tasks. Fine-tuning tools play a vital role in the development of AI models. They allow developers to optimize model performance based on specific data sets and application scenarios. In April 2022, OpenAI released a series of improvements to its fine-tuning API. These improvements not only improve the flexibility and accuracy of the model, but also provide developers with more
2024-04-07
comment
844

For the first time: Microsoft uses GPT-4 to fine-tune large model instructions, and the zero-sample performance of new tasks is further improved.
Article Introduction:We know that large language models (LLMs), from Google T5 models to the OpenAI GPT series of large models, have demonstrated impressive generalization capabilities, such as context learning and thought chain reasoning. At the same time, in order to make LLMs follow natural language instructions and complete real-world tasks, researchers have been exploring instruction fine-tuning methods for LLMs. This is done in two ways: using human-annotated prompts and feedback to fine-tune models on a wide range of tasks, or using public benchmarks and datasets augmented with manually or automatically generated instructions to supervise fine-tuning. Among these methods, Self-Instruct fine-tuning is a simple and effective method that fine-tunes teachers from SOTA instructions
2023-04-10
comment 0
1200

OpenAI partners with Scale AI to improve fine-tuning of enterprise GPT models
Article Introduction:OpenAI recently announced an in-depth cooperation with ScaleAI, aiming to improve the performance of GPT-3.5 Turbo and GPT-4 large-scale language models in enterprise environments. OpenAI stated that through in-depth cooperation with enterprises, OpenAI's large-scale language models can be customized to meet the needs of enterprises. personalized needs and better serve enterprises. At the same time, officials emphasized that all data sent through the fine-tuning API belongs to the customer's property and will not be used by OpenAI or any other entity to train other models. OpenAI announced that it has designated ScaleAI as the "preferred partner" for GPT-3.5 fine-tuning, which indicates that both parties We will give full play to our respective advantages and jointly create a better and more comprehensive A for enterprises.
2023-09-18
comment 0
243

RAG or fine-tuning? Microsoft has released a guide to the construction process of large model applications in specific fields
Article Introduction:Retrieval-augmented generation (RAG) and fine-tuning are two common methods to improve the performance of large language models. So which method is better? Which is more efficient when building applications in a specific domain? This paper from Microsoft is for your reference when choosing. When building large language model applications, two approaches are often used to incorporate proprietary and domain-specific data: retrieval enhancement generation and fine-tuning. Retrieval-enhanced generation enhances the model's generation capabilities by introducing external data, while fine-tuning incorporates additional knowledge into the model itself. However, our understanding of the advantages and disadvantages of these two approaches is insufficient. This article introduces a new focus proposed by Microsoft researchers to create context-specific and adaptive response capabilities for the agricultural industry.
2024-02-16
comment 0
910

The strongest API calling model is here! Based on LLaMA fine-tuning, the performance exceeds GPT-4
Article Introduction:After the alpaca, there is another model named after an animal, this time it is the gorilla. Although LLM is currently in the limelight, making a lot of progress, and its performance in various tasks is also remarkable, the potential of these models to effectively use tools through API calls still needs to be explored. Even for today's state-of-the-art LLMs, such as GPT-4, API calls are a challenging task, mainly due to their inability to generate accurate input parameters and LLMs' tendency to hallucinate incorrect usage of API calls. No, the researchers created Gorilla, a fine-tuned LLaMA-based model that even surpasses GPT-4 in writing API calls. And when combined with a document retriever
2023-06-10
comment 0
1334
RoSA: A new method for efficient fine-tuning of large model parameters
Article Introduction:As language models scale to unprecedented scale, comprehensive fine-tuning for downstream tasks becomes prohibitively expensive. In order to solve this problem, researchers began to pay attention to and adopt the PEFT method. The main idea of the PEFT method is to limit the scope of fine-tuning to a small set of parameters to reduce computational costs while still achieving state-of-the-art performance on natural language understanding tasks. In this way, researchers can save computing resources while maintaining high performance, bringing new research hotspots to the field of natural language processing. RoSA is a new PEFT technique that, through experiments on a set of benchmarks, is found to outperform previous low-rank adaptive (LoRA) and pure sparse fine-tuning methods using the same parameter budget. This article will go into depth
2024-01-18
comment 0
147

OpenAI partners with Scale AI to improve enterprise GPT model fine-tuning capabilities
Article Introduction:IT House reported on August 26 that OpenAI recently issued a press release announcing an in-depth cooperation with ScaleAI to enhance GPT-3.5 Turbo and GPT-4 language models in the enterprise environment. OpenAI said that through in-depth cooperation between the two parties, it can help enterprises customize OpenAI's large language model to meet the individual needs of enterprises. OpenAI once again emphasized in the content that all data sent through the fine-tuning API belongs to the customer's property and will not be used by OpenAI or any other entity to train other models. ScaleAI has unique advantages in data labeling and AI solutions, and OpenAI lists them as As a "preferred partner". OpenAI recently published a blog post,
2023-09-04
comment 0
1032
Comprehensive analysis of large model parameters and efficient fine-tuning, Tsinghua research published in Nature sub-journal
Article Introduction:In recent years, Sun Maosong's team from the Department of Computer Science at Tsinghua University has in-depth explored the mechanism and characteristics of efficient fine-tuning methods for large language model parameters, and collaborated with other relevant teams in the school to complete the research result "Efficient Parameter Fine-tuning for Large-scale Pre-trained Language Models" (Parameter- Efficient Fine-tuning of Large-scale Pre-trained Language Models) was published in "Nature Machine Intelligence" on March 2. The research results were contributed by Sun Maosong, Li Juanzi, Tang Jie, Liu Yang, Chen Jianfei, Liu Zhiyuan from the Department of Computer Science and Zheng Haitao from the Shenzhen International Graduate School.
2023-04-11
comment 0
1034

It's not that large models cannot afford global fine-tuning, it's just that LoRA is more cost-effective and the tutorial is ready.
Article Introduction:This is the experience gained by the author Sebastian Raschka after hundreds of experiments, and it is worth reading. Increasing the amount of data and model parameters is recognized as the most direct way to improve the performance of neural networks. At present, the number of parameters of mainstream large models has expanded to hundreds of billions, and the trend of "large models" becoming larger and larger will become more and more intense. This trend has brought about various computing power challenges. If you want to fine-tune a large language model with hundreds of billions of parameters, it not only takes a long time to train, but also requires a lot of high-performance memory resources. In order to "bring down" the cost of fine-tuning large models, Microsoft researchers developed low-rank adaptive (LoRA) technology. The subtlety of LoRA is that it is equivalent to adding a detachable plug-in to the original large model.
2023-12-04
comment 0
196

Let large models no longer be 'big Mac'. This is the latest review of efficient fine-tuning of large model parameters.
Article Introduction:The AIxiv column is a column where this site publishes academic and technical content. In the past few years, the AIxiv column of this site has received more than 2,000 reports, covering top laboratories from major universities and companies around the world, effectively promoting academic exchanges and dissemination. If you have excellent work that you want to share, please feel free to contribute or contact us for reporting. Submission email: liyazhou@jiqizhixin.com; zhaoyunfeng@jiqizhixin.com. Recently, large-scale AI models such as large language models and Vincentian graph models have developed rapidly. Under this situation, how to adapt to rapidly changing needs and quickly adapt large models to various downstream tasks has become an important challenge. Limited by computing resources, traditional full-parameter micro
2024-04-28
comment
863

How to set WeChat to black mode?
Article Introduction:How to turn WeChat black: 1. Open the WeChat App and enter the homepage, click "Me" - "Settings"; 2. In the settings interface, click "General" - "Dark Mode" option; 3. Select the mode In the interface, check "Dark Mode" and click "Done" to turn WeChat into black.
2020-10-27
comment 0
461973
0 code fine-tuning of large models is popular, only 5 steps are needed, and the cost is as low as 150 yuan
Article Introduction:Fine-tuning a large model with 0 code costs less than $20 (approximately RMB 144 yuan)? The process is also very simple, only 5 steps. Popular open source generative models such as LLaMA, GPT, and StableLM can all be done. Picture This is MonsterAPI, the latest popular API platform. Some people think that this new work in the open source field can rewrite the game rules of AI development and accelerate the speed of AI applications. Some people excitedly asked in the picture, will it be connected to GPT-3/GPT-4 in the future? Picture So, how exactly is it implemented? Easy to understand in five steps and zero code, MonsterAPI is to make the fine-tuning steps as simple as possible, so that developers no longer need to manually perform a series of settings, and it also provides low-cost
2023-07-16
comment 0
1180

微调真的能让LLM学到新东西吗:引入新知识可能让模型产生更多的幻觉
Article Introduction:大型语言模型(LLM)是在巨大的文本数据库上训练的,在那里它们获得了大量的实际知识。这些知识嵌入到它们的参数中,然后可以在需要时使用。这些模型的知识在训练结束时被“具体化”。在预训练结束时,模型实际上停止学习。对模型进行对齐或进行指令调优,让模型学习如何充分利用这些知识,以及如何更自然地响应用户的问题。但是有时模型知识是不够的,尽管模型可以通过RAG访问外部内容,但通过微调使用模型适应新的领域被认为是有益的。这种微调是使用人工标注者或其他llm创建的输入进行的,模型会遇到额外的实际知识并将其整合到参数中。
2024-05-30
comment
691
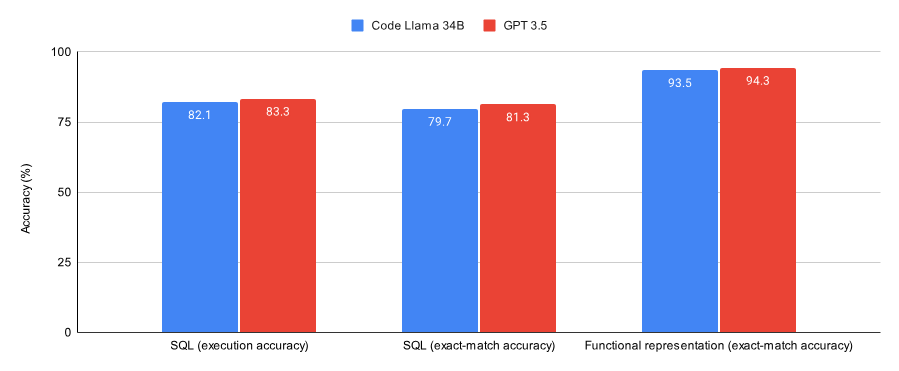
Choose GPT-3.5 or fine-tune open source models such as Llama 2? After comprehensive comparison, the answer is
Article Introduction:It is known that fine-tuning GPT-3.5 is very expensive. This paper uses experiments to verify whether the manually fine-tuned model can approach the performance of GPT-3.5 at a fraction of the cost. Interestingly, this article does exactly that. Comparing the results on the SQL task and the functional representation task, this article found that GPT-3.5 performed slightly better than CodeLlama34B, which was fine-tuned by Lora, on both data sets (a subset of the Spider data set and the Viggo functional representation data set). The training cost of GPT-3.5 is 4-6 times higher, and the deployment cost is also higher
2023-10-16
comment 0
557

美颜相机脸型怎么调整
Article Introduction:脸型调整步骤:1)选择脸型模板;2)调整脸型轮廓;3)微调脸型细节(下巴尖度、颧骨高度、额头宽度);4)保存调整。
2024-07-12
comment
598
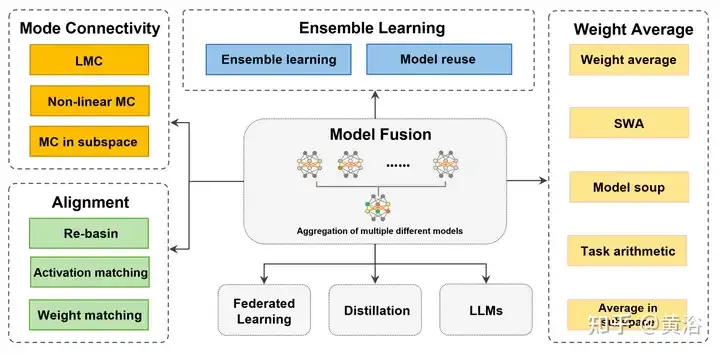
Review! Deep model fusion (LLM/basic model/federated learning/fine-tuning, etc.)
Article Introduction:In September 23, the paper "DeepModelFusion:ASurvey" was published by the National University of Defense Technology, JD.com and Beijing Institute of Technology. Deep model fusion/merging is an emerging technology that combines the parameters or predictions of multiple deep learning models into a single model. It combines the capabilities of different models to compensate for the biases and errors of individual models for better performance. Deep model fusion on large-scale deep learning models (such as LLM and basic models) faces some challenges, including high computational cost, high-dimensional parameter space, interference between different heterogeneous models, etc. This article divides existing deep model fusion methods into four categories: (1) "Pattern connection", which connects solutions in the weight space through a loss-reducing path to obtain a better initial model fusion
2024-04-18
comment
521

OpenAI offers new fine-tuning and customization options
Article Introduction:Fine-tuning plays a crucial role in building valuable AI tools. This process of refining pre-trained models using more targeted data sets allows users to greatly increase the model's understanding of professional connotations, allowing users to add ready-made knowledge to the model for specific tasks. While this process can take time, it's often three times more cost-effective than training a model from scratch. This value is reflected in OpenAI’s recent announcement of an expansion of its custom model program and various new features for its fine-tuning API. New features of self-service fine-tuning API OpenAI first announced the launch of a self-service fine-tuning API for GPT-3 in August 2023, and received an enthusiastic response from the AI community. According to an OpenAI report, thousands of
2024-04-19
comment 0
789
