


In 2018, Google released BERT. Once it was released, it defeated the State-of-the-art (Sota) results of 11 NLP tasks in one fell swoop, becoming a new milestone in the NLP world;The structure of BERT is shown in the figure below , The left side is the BERT model pre-training process, and the right side is the fine-tuning process for specific tasks. Among them, the fine-tuning stage is for fine-tuning when it is subsequently used in some downstream tasks, such as: text classification, part-of-speech tagging, question and answer system, etc. BERT can be fine-tuned on different tasks without adjusting the structure. Through the task design of "pre-training language model and downstream task fine-tuning", it has brought powerful model effects. Since then, "pre-training language model and downstream task fine-tuning" has become the mainstream training paradigm in the field of NLP.
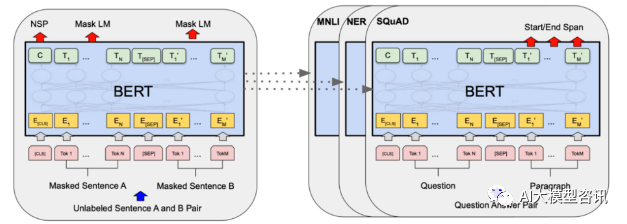 BERT structure diagram, the left side is the pre-training process, and the right side is the specific task fine-tuning process
BERT structure diagram, the left side is the pre-training process, and the right side is the specific task fine-tuning process
However, with the emergence of large-scale architectures represented by GPT3, As the parameter size of large-scale language models (LLM) increases, full fine-tuning on consumer-grade hardware becomes unfeasible. The following table shows the CPU/GPU memory consumption of full model fine-tuning and parameter efficient fine-tuning on an A100 GPU (80G video memory) and hardware with a CPU memory of 64GB or more
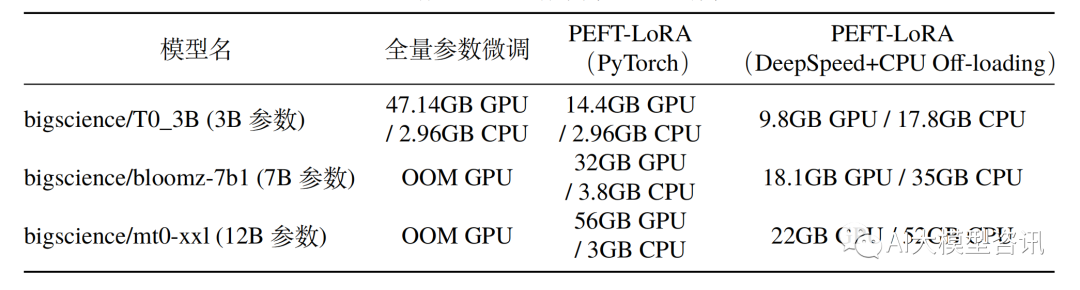 Full Comparison of memory usage between parameter fine-tuning and parameter efficient fine-tuning
Full Comparison of memory usage between parameter fine-tuning and parameter efficient fine-tuning
In addition, comprehensive fine-tuning of the model will also lead to the loss of diversity and serious forgetting problems. Therefore, how to efficiently perform model fine-tuning has become the focus of industry research, which also provides research space for the rapid development of efficient parameter fine-tuning technology
Efficient parameter fine-tuning refers to fine-tuning a small amount or additional model parameters, with a fixed large Partially pre-trained model (LLM) parameters, thereby greatly reducing computing and storage costs, while also achieving performance comparable to full parameter fine-tuning. The parameter efficient fine-tuning method is even better than full fine-tuning in some cases, and can be better generalized to out-of-domain scenarios.
Efficient fine-tuning technology can be roughly divided into the following three categories, as shown in the figure below: adding additional parameters (A), selecting a part of parameters to update (S), and introducing heavy parameterization (R). Among the methods of adding additional parameters, they are mainly divided into two subcategories: Adapter-like methods and Soft prompts.
Common parameter efficient fine-tuning technologies include BitFit, Prefix Tuning, Prompt Tuning, P-Tuning, Adapter Tuning, LoRA, etc. The following chapters will explain in detail some mainstream efficient parameter fine-tuning methods
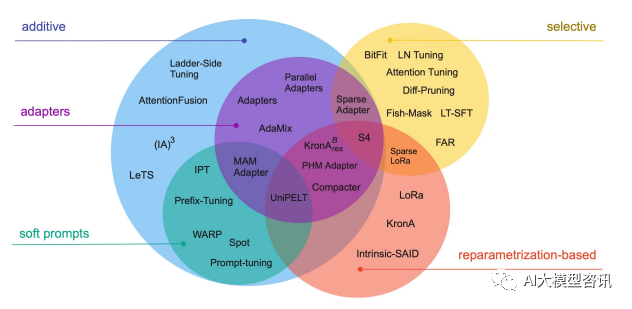 Common parameter efficient fine-tuning technologies and methods
Common parameter efficient fine-tuning technologies and methods
Although full fine-tuning for each task is very effective, it will also generate a Uniquely large models, which make it difficult to infer what changes occurred during fine-tuning, are also difficult to deploy, and especially difficult to maintain as the number of tasks increases.
Ideally, we hope to have an efficient fine-tuning method that meets the following conditions:
The above issues depend on the extent to which the fine-tuning process can guide the learning of new abilities and exposure to pre-training LM secondary schools ability. Although, the previous efficient fine-tuning methods Adapter-Tuning and Diff-Pruning can also partially meet the above needs. BitFit, a sparse fine-tuning method with smaller parameters, can meet all the above needs.
BitFit is a sparse fine-tuning method that only updates the bias parameters or part of the bias parameters during training. For the Transformer model, most of the transformer-encoder parameters are frozen, and only the bias parameters and the classification layer parameters of the specific task are updated. The bias parameters involved include the bias involved in calculating query, key, value and merging multiple attention results in the attention module, the bias in the MLP layer, the bias parameter in the Layernormalization layer, and the bias parameters in the pre-training model as shown in the figure below. .
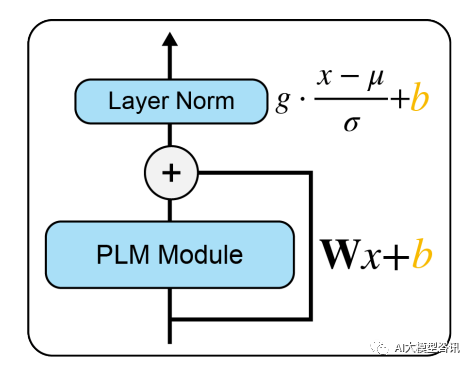 Picture
Picture
The PLM module represents a specific PLM sub-layer, such as attention or FFN. The orange block in the figure indicates the trainable Hint vector, blue blocks represent frozen pre-trained model parameters
In models such as Bert-Base/Bert-Large, the bias parameter only accounts for 0.08%~0.09% of the total parameters of the model. However, by comparing the effects of BitFit, Adapter and Diff-Pruning on the Bert-Large model based on the GLUE data set, it was found that BitFit has the same effect as Adapter and Diff-Pruning when the number of parameters is much smaller than that of Adapter and Diff-Pruning. , even slightly better than Adapter and Diff-Pruning in some tasks.
It can be seen from the experimental results that compared to the fine-tuning of all parameters, the BitFit fine-tuning results only updated a very small number of parameters, and achieved good results on multiple data sets. Although it is not as good as fine-tuning all parameters, it is far better than the Frozen method of fixing all model parameters. At the same time, by comparing the parameters before and after BitFit training, it was found that many bias parameters did not change much, such as the bias parameters related to calculating the key. It is found that the bias parameters of the FFN layer that calculates the query and enlarges the feature dimension from N to 4N have the most obvious changes. Only updating these two types of bias parameters can also achieve good results. On the contrary, if any one of them is fixed, the effect of the model will be greatly lost.
The work before Prefix Tuning was mainly to manually design discrete templates or automatically search for discrete templates. For manually designed templates, changes in the template are particularly sensitive to the final performance of the model. Adding a word, missing a word, or changing the position will cause relatively large changes. For automated search templates, the cost is relatively high; at the same time, the results of previous discrete token searches may not be optimal. In addition, the traditional fine-tuning paradigm uses pre-trained models to fine-tune different downstream tasks, and a fine-tuned model weight must be saved for each task. On the one hand, fine-tuning the entire model takes a long time; on the other hand, it will also Takes up a lot of storage space. Based on the above two points, Prefix Tuning proposes a fixed pre-training LM, adding trainable, task-specific prefixes toLM, so that different prefixes can be saved for different tasks, and the fine-tuning cost is also small; at the same time, this kind of Prefix is actually Continuously differentiable Virtual Token (Soft Prompt/Continuous Prompt) is better optimized and has better effect than discrete Token.
So, what needs to be rewritten is: So what is the meaning of prefix? The role of prefix is to guide the model to extract information related to x, so as to better generate y. For example, if we want to do a summary task, then after fine-tuning, prefix can understand that what we are currently doing is a "summarization form" task, and then guide the model to extract key information from x; if we want to do an emotion classification Task, prefix can guide the model to extract the semantic information related to emotion in x, and so on. This explanation may not be so rigorous, but you can roughly understand the role of prefix
Prefix Tuning is to construct a task-related virtual tokens as Prefix before inputting the token, and then only update the parameters of the Prefix part during training. , while other parameters in PLM are fixed. For different model structures, different Prefixes need to be constructed:
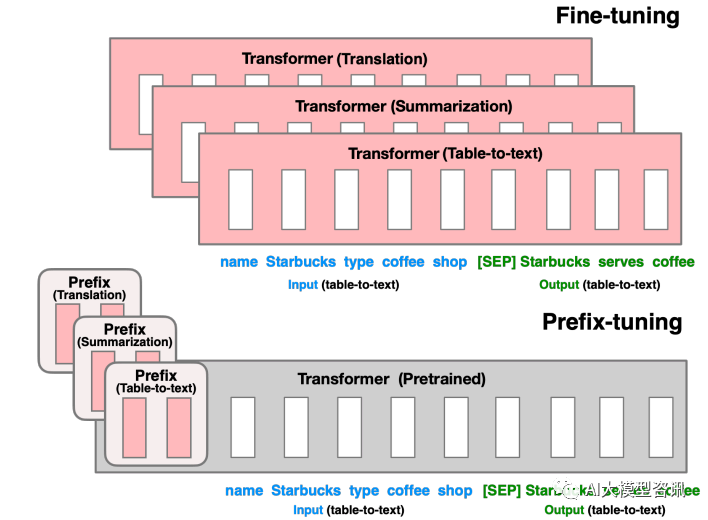 Picture
Picture
Rewrite the content without changing the original meaning, and rewrite it in Chinese: For the fine-tuning in the previous part, we update all Transformer parameters (red box) and need to store a complete copy of the model for each task. The prefix adjustment in the lower part will freeze the Transformer parameters and only optimize the prefix (red box)
This method is actually similar to constructing Prompt, except that Prompt is an artificially constructed "explicit" prompt. And the parameters cannot be updated, while Prefixis an "implicit" hint that can be learned. At the same time, in order to prevent the direct update of the parameters of Prefix from causing unstable training and performance degradation, an MLP structure is added in front of the Prefix layer. After training is completed, only the parameters of Prefix are retained. In addition, ablation experiments have proven that adjusting the embedding layer alone is not expressive enough, which will lead to a significant performance decline. Therefore, prompt parameters are added to each layer, which is a major change.
Although Prefix Tuning seems convenient, it also has the following two significant disadvantages:
Full fine-tuning of large models requires training a model for each task, which has relatively high overhead and deployment costs. At the same time, the discrete prompts (referring to manually designing prompts and adding prompts to the model) method is relatively expensive and the effect is not very good. Prompt Tuning learns prompts by backpropagating updated parameters instead of manually designing prompts; at the same time, it freezes the original weights of the model and only trains prompts parameters. After training, the same model can be used for multi-task inference.
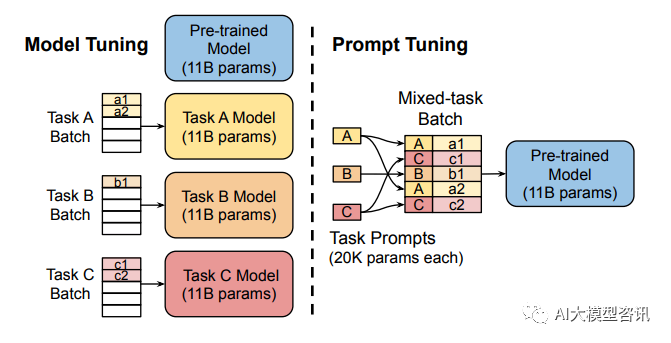 Picture
Picture
Model tuning requires making task-specific copies of the entire pre-trained model for each task. Downstream tasks and inference must be in separate batches . Prompt Tuning only requires storing a small task-specific prompt for each task and enables mixed-task inference using the original pre-trained model.
Prompt Tuning can be seen as a simplified version of Prefix Tuning. It defines its own prompt for each task, and then splices it into the data as input, but only adds prompt tokens to the input layer, and There is no need to add MLP for adjustment to solve difficult training problems.
It was found through experiments that as the number of parameters of the pre-trained model increases, the Prompt Tuning method will approach the results of full parameter fine-tuning. At the same time, Prompt Tuning also proposed Prompt Ensembling, which means training different prompts for the same task at the same time in a batch (that is, asking the same question in multiple different ways). This is equivalent to training different models. For example The cost of model integration is much smaller. In addition, the Prompt Tuning paper also discusses the impact of the initialization method and length of the Prompt token on model performance. Through ablation experiment results, it is found that Prompt Tuning uses class labels to initialize the model better than random initialization and initialization using sample vocabulary. However, as the model parameter scale increases, this gap will eventually disappear. When the length of Prompt token is around 20, the performance is already good (after exceeding 20, increasing the length of Prompt token will not significantly improve the performance of the model). Similarly, this gap will also decrease as the scale of model parameters increases ( That is, for very large-scale models, even if the Prompt token length is very short, it will not have much impact on performance).
The above is the detailed content of Efficient parameter fine-tuning of large-scale language models--BitFit/Prefix/Prompt fine-tuning series. For more information, please follow other related articles on the PHP Chinese website!
 mysql backup data method
mysql backup data method Ripple currency market trend
Ripple currency market trend How to solve the problem that pycharm cannot find the module
How to solve the problem that pycharm cannot find the module How to read macro control data in javascript
How to read macro control data in javascript Characteristics of the network
Characteristics of the network How to resume use of gas after payment
How to resume use of gas after payment The difference between windows hibernation and sleep
The difference between windows hibernation and sleep tim mobile online
tim mobile online




















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



