Found a total of 161 related content

强化学习中的算法选择问题
Article Introduction:强化学习中的算法选择问题,需要具体代码示例强化学习是一种通过智能体与环境的交互学习最优策略的机器学习领域。在强化学习中,选择适合的算法对于学习效果至关重要。在本文中,我们将探讨强化学习中的算法选择问题,并提供具体代码示例。在强化学习中有许多算法可以选择,如Q-Learning、DeepQNetwork(DQN)、Actor-Critic等。选择合适的算法
2023-10-08
comment 0
778

如何使用PHP构建强化学习算法
Article Introduction:如何使用PHP构建强化学习算法引言:强化学习是一种机器学习方法,通过与环境进行交互来学习如何做出最优决策。在本文中,我们将介绍如何使用PHP编程语言构建强化学习算法,并且提供代码示例以帮助读者更好地理解。一、什么是强化学习算法强化学习算法是一种通过观察环境的反馈来学习如何做出决策的机器学习方法。与其他机器学习算法不同的是,强化学习算法不仅仅是根据已有数据进行
2023-07-31
comment 0
376

Python中的强化学习算法有哪些?
Article Introduction:随着人工智能技术的发展,强化学习作为一种重要的人工智能技术,已经被广泛应用于许多领域,例如控制系统、游戏等。Python作为一种流行的编程语言,也提供了许多强化学习算法的实现。本文将介绍Python中常用的强化学习算法及其特点。Q-learningQ-learning是一种基于值函数的强化学习算法,它通过学习一个值函数来指导行为策略,使得智能体能够在环境中选
2023-06-04
comment 0
719

强化学习的定义、分类和算法框架
Article Introduction:强化学习(RL)是一种介于有监督学习和无监督学习之间的机器学习算法。它通过不断试错和学习来解决问题。在训练过程中,强化学习会采取一系列决策,并根据执行的操作获得奖励或惩罚。其目标是最大化总奖励。强化学习具有自主学习和适应能力,能够在动态环境下做出优化决策。与传统的监督学习相比,强化学习更适用于没有明确标签的问题,并且可以在长期决策问题中取得良好的效果。强化学习的核心是根据代理执行的操作来强制执行行为,代理根据行动对总体目标的积极影响来获得奖励。强化学习算法主要有两种类型:基于模型与无模型学习算法基于模型的
2024-01-24
comment
260
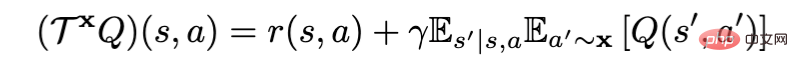
离线强化学习新范式!京东科技&清华提出解耦式学习算法
Article Introduction:离线强化学习算法 (Offline RL) 是当前强化学习最火的子方向之一。离线强化学习不与环境交互,旨在从以往记录的数据中学习目标策略。在面临数据收集昂贵或危险等问题,但是可能存在大量数据领域(例如,机器人、工业控制、自动驾驶),离线强化学习对比到在线强化学习(Online RL)尤其具有吸引力。在利用贝尔曼策略评估算子进行策略评估时,根据 X 的不同可以把当前的离线强化学习算法分为 RL-based (x=π)和 Imitation-based (x=μ), 其中π为目标策略,μ为行为策略
2023-04-11
comment 0
601

强化学习之策略梯度算法
Article Introduction:策略梯度算法是一种重要的强化学习算法,其核心思想是通过直接优化策略函数来搜索最佳策略。与间接优化价值函数的方法相比,策略梯度算法具有更好的收敛性和稳定性,并且能够处理连续动作空间问题,因此被广泛应用。这种算法的优势在于它可以直接学习策略参数,而不需要估计值函数。这使得策略梯度算法能够应对高维状态空间和连续动作空间的复杂问题。此外,策略梯度算法还可以通过采样来近似计算梯度,从而提高计算效率。总之,策略梯度算法是一种强大而灵活的方法,为在策略梯度算法中,我们需要定义一个策略函数\pi(a|s),它给
2024-01-22
comment 0
800

Golang在强化学习中的机器学习应用
Article Introduction:Golang在强化学习中的机器学习应用简介强化学习是一种机器学习方法,通过与环境互动并根据奖励反馈学习最优行为。Go语言具有并行、并发和内存安全等特性,使其在强化学习中具有优势。实战案例:围棋强化学习在本教程中,我们将使用Go语言和AlphaZero算法实现一个围棋强化学习模型。
2024-05-08
comment
249

机器学习:Github上排名前19个强化学习 (RL)项目
Article Introduction:强化学习(RL)是一种机器学习方法,它通过代理不断试错来学习。强化学习算法在多个领域得到应用,如游戏、机器人技术和金融领域。RL的目标是发现一种能够最大化预期长期回报的策略。强化学习算法通常被分为两类:基于模型和无模型。基于模型的算法利用环境模型来规划最佳行动路径。这种方法依赖于对环境的准确建模,然后通过模型来预测不同行动的结果。与之相对,无模型的算法则直接从与环境的交互中学习,不需要对环境进行显式建模。这种方法更适用于那些环境模型难以获取或者不准确的情况。在实际相比之下,无模型强化学习算法并不
2024-03-19
comment 0
579

AI模型训练:强化算法与进化算法
Article Introduction:强化学习算法(RL)和进化算法(EA)是机器学习领域中独具特色的两种算法,虽然它们都属于机器学习的范畴,但在问题解决的方式和理念上存在明显的差异。强化学习算法:强化学习是一种机器学习方法,其核心在于智能体与环境互动,通过尝试和错误来学习最佳行为策略,以最大化累积奖励。强化学习的关键在于智能体不断尝试各种行为,并根据奖励信号调整其策略。通过与环境的交互,智能体逐步优化其决策过程,以达到既定的目标。这种方法模仿了人类学习的方式,通过不断试错和调整来提高性能,使智能体能够在复强化学习中的主要组成部分包括环境、智
2024-03-25
comment
349
七个流行的强化学习算法及代码实现
Article Introduction:目前流行的强化学习算法包括 Q-learning、SARSA、DDPG、A2C、PPO、DQN 和 TRPO。这些算法已被用于在游戏、机器人和决策制定等各种应用中,并且这些流行的算法还在不断发展和改进,本文我们将对其做一个简单的介绍。1、Q-learningQ-learning:Q-learning 是一种无模型、非策略的强化学习算法。 它使用 Bellman 方程估计最佳动作值函数,该方程迭代地更新给定状态动作对的估计值。
2023-04-11
comment 0
1216

强化学习中的奖励设计问题
Article Introduction:强化学习中的奖励设计问题,需要具体代码示例强化学习是一种机器学习的方法,其目标是通过与环境的交互来学习如何做出能够最大化累积奖励的行动。在强化学习中,奖励起着至关重要的作用,它是代理人(Agent)学习过程中的信号,用于指导其行为。然而,奖励设计是一个具有挑战性的问题,合理的奖励设计可以极大地影响到强化学习算法的性能。在强化学习中,奖励可以被视为代理人与环境
2023-10-08
comment 0
772

再掀强化学习变革!DeepMind提出「算法蒸馏」:可探索的预训练强化学习Transformer
Article Introduction:在当下的序列建模任务上,Transformer可谓是最强大的神经网络架构,并且经过预训练的Transformer模型可以将prompt作为条件或上下文学习(in-context learning)适应不同的下游任务大型预训练Transformer模型的泛化能力已经在多个领域得到验证,如文本补全、语言理解、图像生成等等。从去年开始,已经有相关工作证明,通过将离线强化学习(offline RL)视为一个序列预测问题,那么模型就可以从离线数据中学习策略。但目前的方法要么是从不包含学习的数据中学习策略
2023-04-12
comment 0
1296

Python中的深度强化学习是什么?
Article Introduction:Python中的深度强化学习是什么?DeepReinforcementLearning(DRL)在近年来已成为人工智能领域的一个关键研究重点,尤其是在游戏、机器人、自然语言处理等方面的应用中。基于Python语言的强化学习与深度学习库,如TensorFlow、PyTorch、Keras等,使得我们可以更轻松地实现DRL的算法。深度强化学习的理论基础深度
2023-06-04
comment 0
1321

南洋理工发布量化交易大师TradeMaster,涵盖15种强化学习算法
Article Introduction:近日,量化平台大家庭迎来了一位新成员,基于强化学习的开源平台: TradeMaster— 交易大师。TradeMaster 由南洋理工大学开发,是一个涵盖四大金融市场,六大交易场景,15 种强化学习算法以及一系列可视化评价工具的统一的,端到端的,用户友好的量化交易平台!平台地址: https://github.com/TradeMaster-NTU/TradeMaster背景介绍近年来,人工智能技术在量化交易策略中正在占据越来越重要的地位。由于具有在复杂环境中突出的决策能力,将强化学习技术应用于
2023-04-11
comment 0
593

超强!深度学习Top10算法!
Article Introduction:自2006年深度学习概念被提出以来,20年快过去了,深度学习作为人工智能领域的一场革命,已经催生了许多具有影响力的算法。那么,你所认为深度学习的top10算法有哪些呢?以下是我心目中深度学习的顶尖算法,它们在创新性、应用价值和影响力方面都占据重要地位。1、深度神经网络(DNN)背景:深度神经网络(DNN)也叫多层感知机,是最普遍的深度学习算法,发明之初由于算力瓶颈而饱受质疑,直到近些年算力、数据的爆发才迎来突破。
2024-03-15
comment
344

Vue组件通讯的强化学习方法
Article Introduction:Vue组件通讯的强化学习方法在Vue开发中,组件通讯是一个非常重要的主题。它涉及到如何在多个组件之间共享数据、触发事件等。一种常见的做法是使用props和$emit方法进行父子组件之间的通讯。强化学习是一种通过试错和奖励机制来优化问题解决的算法。在组件通讯中,我
2023-07-17
comment 0
883

Java实现的自我学习算法与应用
Article Introduction:随着人工智能的发展,自我学习算法也越来越受到关注。相较于传统的人工智能算法,自我学习算法具有更高的智能化和适应性。在这篇文章中,我将重点讨论Java实现的自我学习算法及其应用。一、什么是自我学习算法?自我学习算法是一种强化学习算法,它能够根据其在执行任务时收到的反馈来改进自己的表现。简单来说,自我学习算法会学习如何去执行一个任务,并通过与环境的交互来提高其性
2023-06-18
comment 0
614
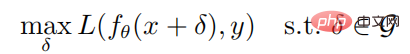
深度强化学习中的对抗攻击和防御
Article Introduction:01 前言该论文是关于深度强化学习对抗攻击的工作。在该论文中,作者从鲁棒优化的角度研究了深度强化学习策略对对抗攻击的鲁棒性。在鲁棒优化的框架下,通过最小化策略的预期回报来给出最优的对抗攻击,相应地,通过提高策略应对最坏情况的性能来实现良好的防御机制。考虑到攻击者通常无法 在训练环境中 攻击,作者提出了一种贪婪攻击算法,该算法试图在不与环境交互的情况下最小化策略的预期回报;另外作者还提出一种防御算法,该算法以最大-最小的博弈来对深度强化学习算法进行对抗训练
2023-04-08
comment 0
776

无模型元学习算法——MAML元学习算法
Article Introduction:元学习(Meta-learning)是指探索学习如何学习的过程,通过从多个任务中提取共同特征,以便快速适应新任务。与之相关的模型无关的元学习(Model-AgnosticMeta-Learning,MAML)是一种算法,其可以在没有先验知识的情况下,进行多任务元学习。MAML通过在多个相关任务上进行迭代优化来学习一个模型初始化参数,使得该模型能够快速适应新任务。MAML的核心思想是通过梯度下降来调整模型参数,以使得在新任务上的损失最小化。这种方法使得模型可以在少量样本的情况下快速学习,并且具有较
2024-01-22
comment 0
976

了解强化学习及其应用场景
Article Introduction:训练狗最佳方法是采用奖励机制,奖励它表现良好,惩罚它做错事。同样的策略可用于机器学习,称为强化学习。强化学习是机器学习的分支之一,通过决策训练模型来找到问题的最佳解决方案。为了提高模型准确性,可通过正奖励鼓励算法接近正确答案,同时给予负奖励以惩罚偏离目标的情况。只需要明确目标,再对数据进行建模,模型与数据开始交互,并自行提出解决方案,无需人工干预。强化学习实例我们还是以训练狗为例,我们提供诸如狗饼干之类的奖励来让狗执行各种动作。狗会按照一定的策略来追求奖励,因此它会听从命令并学习新的动作,如乞讨。狗喜欢四
2024-01-22
comment
960
