


This article mainly introduces python to realize the automatic reservation function of library study room in detail. It has certain reference value. Interested friends can refer to it.
This article shares the python implementation with everyone. The specific code for automatic reservation of the library study room is for your reference. The specific content is as follows
Introduction
Many schools now provide students with a very good learning environment. Usually This is reflected in the facilities and equipment of the self-study classrooms. What I have to mention about this is the library of our school. With the construction of the new library, multiple functional areas have been set up in the library. Each floor is divided into four areas: A, B, C, and D, connected by the north and south. The corridors are connected, and a spiral staircase runs through the first to fifth floors. Area A is a self-study area; Areas B and C are social science and natural science bookstores that integrate collection and reading; Area D is a special functional area, including a film and television hall, a digital media maker experience center, a smart training classroom, and a cloud desktop electronic reading room. etc.; there are twelve large and small study rooms in the east-west corridors of Areas B and C; there are leisure reading areas in the north-south corridors.
I copied the above paragraph from the library’s official website, but I really have to give a thumbs up to the school library. Returning to the topic of this article, the school provides comfortable, high-quality and well-equipped study rooms for teachers and students free of charge. However, these study rooms require online reservations before they can be used. Reservations for the next day start at 00:00 every day. Therefore, if you want to make an appointment for a study room in a time period (3 hours), you have to burn the midnight oil. Of course, having fast hands will be a huge advantage in this process. If you go to bed early at night and your hand speed is not fast, you will basically not be able to make an appointment in the study room. I just happened to learn a little python crawler recently, and I plan to use the crawler to help me complete this arduous task. Ha ha ha ha! (ps: To prevent malicious access, all links will not be released)
Python implementation ideas
The idea is quite simple when you think about it. It is nothing more than logging in to the account and searching Room, submit reservation. Then let us try it:
Login account
First open the login interface for our study room reservation, the link is: U2FsdGVkX19NdfJkghN54Msvy1zl7AucRur/ct0nz4orPI7uLkSDsvuFMgr0fGcO
rn9Z/f8h3bds9w==
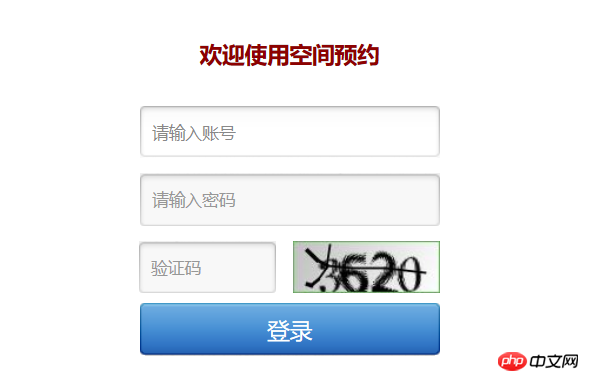
Okay, this first step of logging in to your account is a great test for me as a newbie, but I can’t be timid. By referring to the method used by some other big guys, it is to open firebug of firefox (ctrl shift e) to check the network situation, and perform a normal login in this case.

You can see that we have a post here, and then you can use the requests.post method in python.
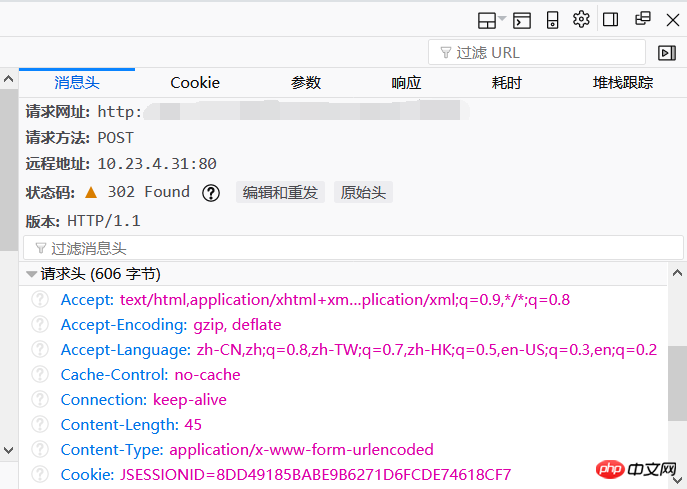
In order to log in successfully, you need to hide your identity as a crawler. In the message header, you can see our request header. Just copy all the parameters to form Own headers = {…} to trick the server.
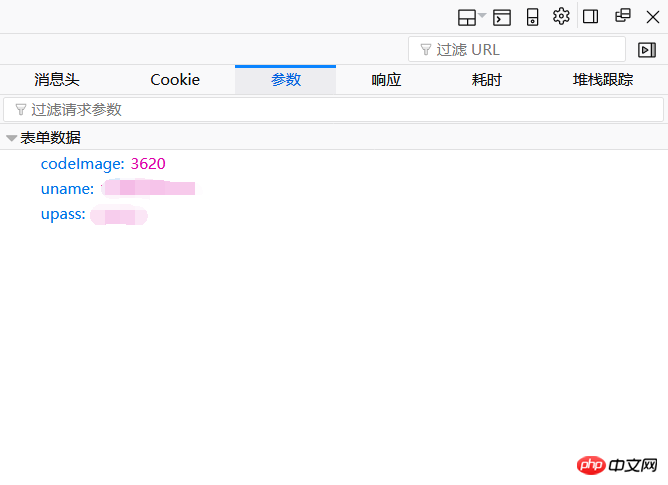
#Look at the parameters page. There are only three form data here, corresponding to the verification code, account number and password. Copy the parameters here to form our data = {…}. What needs our attention is this verification code. Whether it can be recognized manually or automatically by a machine, the verification code needs to be saved as a local file. As a result, there is a problem. Every time the server is accessed, the verification code will change. Now let's think about it. First we have to get the verification code and save it locally, which requires a visit to the server. Finally, we have to submit our parameters to log in. This time we visit the server again, this time for verification. The verification code and the verification code we obtained are no longer the same verification code. In the first attempt, I couldn't log in to the server anyway, because the two verification codes did not match. How to make the verification code obtained for the first time consistent with the verification code when submitted?
The same cookie is needed here. In the several pictures above, we can all see that there is a cookie value. To ensure synchronization, we need to make sure that the cookie value when we obtain the verification code is consistent with the cookie value when submitting the account password. Therefore, in my program, the first step I do is to obtain a cookie value, and then use this cookie value as a parameter in the headers. This is the idea of logging in. I would like to add that I manually identified the verification code here >﹏<.
Find a room
This step is actually a useless step. Why is there this step? According to human reservation habits, what kind of step will we produce? However, if you use a crawler, you can directly submit the reservation form after successfully logging in. Of course, if you want to make the automatic reservation program more intelligent, you can add this step to check which rooms can still be reserved, and add some customized rules here. I just skipped it. . .
Submit an appointment
Same as logging in, we also submit it manually to check the network situation, and then we can use python to simulate this process. I won’t explain it here with pictures. The requests.post method is also used for submission here. However, one thing to note is that the headers here are different from the headers when logging in, so I would like to remind you that if you use other similar reservation programs, you can pay attention to see whether the headers when posting different content are consistent. I was fooled here for a while.
#!/usr/bin/env python
# _*_ coding:utf-8 _*_
#
# @Version : 1.0
# @Time : 2018/4/10
# @Author : 圈圈烃
# @File : reservation_4.py
import requests
import re
import json
import datetime
import time
def get_cookies():
"""获得cookies"""
url = 'http://**************'
s = requests.session()
s.get(url)
ck_dict = requests.utils.dict_from_cookiejar(s.cookies) # 将jar格式转化为dict
ck = 'JSESSIONID=' + ck_dict['JSESSIONID'] # 重组cookies
"""获得二维码"""
path = './code.png'
get_cookies_headers = {
'user-anget': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:59.0) Gecko/20100101 Firefox/59.0',
'Cookie': ck}
get_cookies_url = 'http://**************'
code_image = requests.get(get_cookies_url, headers=get_cookies_headers)
with open(path, 'wb') as fn:
fn.write(code_image.content)
fn.close()
print('验证码保存成功')
return ck
def login(cookies, hour, minute):
login_headers = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Encoding': 'gzip, deflate',
'Accept-Language': 'zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2',
'Cache-Control': 'no-cache',
'Connection': 'keep-alive',
'Content-Length': '45',
'Content-Type': 'application/x-www-form-urlencoded',
'Cookie': cookies,
'Host': '**************',
'Pragma': 'no-cache',
'Referer': 'http://**************',
'Upgrade-Insecure-Requests': '1',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:59.0) Gecko/20100101 Firefox/59.0'
}
login_url = 'http://**************'
login_data = {
'codeImage': input('请输入验证码:'),
'uname': '**************',
'upass': '**************'
}
requests.post(login_url, data=login_data, headers=login_headers)
res = requests.get('http://**************', headers=login_headers)
reg_h = r'<option value=(.*?)>\d{4}-\d{2}-\d{2}' # 匹配可提供预约的hash
value_h = re.findall(reg_h, res.text)
"""定时"""
counter = 0
while (True):
now = datetime.datetime.now() # 获取当前系统时间
if now.hour == hour and now.minute == minute:
break
time.sleep(0.5)
# print(now)
counter = counter + 1
if counter == 240:
res = requests.get('http://**************', headers=login_headers)
reg_h = r'<option value=(.*?)>\d{4}-\d{2}-\d{2}' # 匹配可提供预约的hash
reg_t = r'(\d{4}-\d{2}-\d{2})' # 匹配可提供预约的日期
value_h = re.findall(reg_h, res.text)
value_t = re.findall(reg_t, res.text)
with open('./con_log.txt', 'a') as fjs:
fjs.write(eval(value_h[-1])+' '+value_t[-1]+' '+str(now)+' \n')
fjs.close()
print('保存成功')
counter = 0
return str(eval(value_h[-1]))
def reservation(day_hash, cookies, stime, etime):
reservation_data = {
'_etime': etime, # 结束时间11点,其值为11*60=660
'_roomid': '1285b3ca77594b3095c7b89d4922553c', # 房间Id
'_seatno': '',
'_stime': stime, # 开始时间8点,其值为8*60=480
'_subject': '学习', # 研讨主题
'_summary': '学习', # 研讨大纲
'ruleId': day_hash,
'usercount': 3, # 预约人数
'users': '**************', # 学号
'UUID': '**************'
}
reservation_headers = {
'Accept': 'application/json, text/javascript, */*; q=0.01',
'Accept-Encoding': 'gzip, deflate',
'Accept-Language': 'zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2',
'Cache-Control': 'no-cache',
'Connection': 'keep-alive',
'Content-Length': '239',
'Content-Type': 'application/json',
'Cookie': cookies,
'Host': '**************',
'Pragma': 'no-cache',
'Referer': 'http://**************',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:59.0) Gecko/20100101 Firefox/59.0'
}
reservation_js = json.dumps(reservation_data)
reservation_url = 'http://**************'
status = requests.post(reservation_url, data=reservation_js, headers=reservation_headers)
# print(stime, etime)
# print(status)
print(status.text)
def main():
"""预约策略一:11:20-20.40"""
full_stime = ['1060', '870', '680']
full_etime = ['1240', '1050', '860']
"""预约策略二:10:00-13:00;13:50-16:50;17:40-20:40"""
stime = ['1060', '830', '600']
etime = ['1240', '1010', '780']
cookies = get_cookies()
day_hash = login(cookies, 0, 0) # 设定定时时间
for i in range(0, 3):
reservation(day_hash, cookies, stime[i], etime[i])
if __name__ == '__main__':
main()Achieve the effect
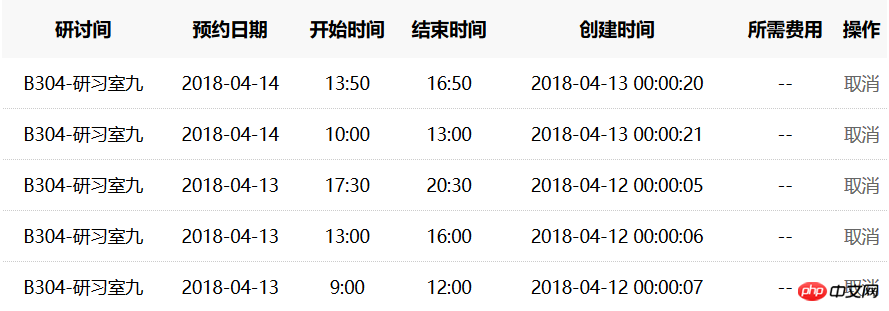
Since learning python, my mother no longer Don't worry I won't be able to grab a study room. After adding a few lines of timing procedures to the program, you can automatically reserve a study room for me at 00:00. Through testing, we found that it is possible to make an appointment to a large extent. For example, on the 4th to the 12th, it took 7 seconds to make an appointment for three time periods, but on the 4th to the 13th, it actually took 21 seconds, and it made During a period of time, I was asked out by other classmates. Of course, this program still needs further improvement to achieve a complete victory over "hand speed".
Make up for the last
If there are any shortcomings, welcome to communicate.
Related recommendations:
Python realizes automatic campus network login
The above is the detailed content of Python implements automatic reservation function of library study room. For more information, please follow other related articles on the PHP Chinese website!
















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



