


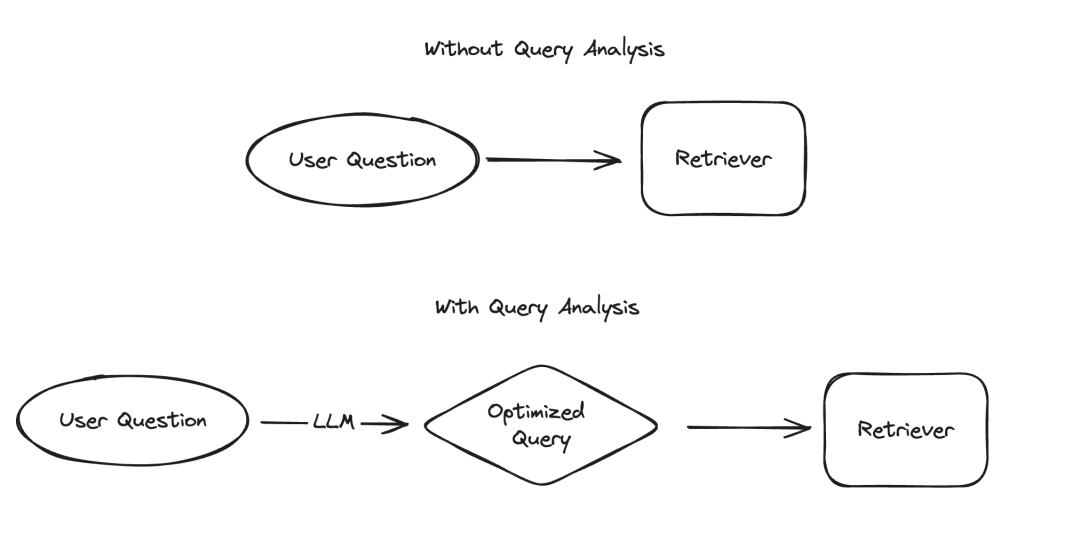
Dalam aplikasi model bahasa besar (LLM), terdapat beberapa senario yang memerlukan data dipersembahkan dalam cara berstruktur, yang mana pengekstrakan maklumat dan analisis pertanyaan adalah dua contoh biasa. Kami baru-baru ini menekankan kepentingan pengekstrakan maklumat dengan dokumentasi yang dikemas kini dan repositori kod khusus. Untuk analisis pertanyaan, kami juga telah mengemas kini dokumentasi yang berkaitan. Dalam senario ini, medan data mungkin termasuk rentetan, nilai Boolean, integer, dsb. Antara jenis ini, menangani nilai kategori kardinaliti tinggi (iaitu jenis penghitungan) adalah yang paling mencabar.
 Gambar
Gambar
Apa yang dipanggil "nilai kumpulan kardinaliti tinggi" merujuk kepada nilai yang mesti dipilih daripada pilihan terhad Nilai ini tidak boleh ditentukan sesuka hati, tetapi mesti datang daripada set yang telah ditetapkan. Dalam set sedemikian, kadangkala akan terdapat sejumlah besar nilai sah, yang kami panggil "nilai kardinaliti tinggi". Sebab mengapa berurusan dengan nilai-nilai sedemikian sukar ialah LLM sendiri tidak tahu apakah nilai-nilai yang boleh dilaksanakan ini. Oleh itu, kami perlu memberikan LLM maklumat tentang nilai yang boleh dilaksanakan ini. Walaupun mengabaikan kes di mana terdapat hanya beberapa nilai yang boleh dilaksanakan, kami masih boleh menyelesaikan masalah ini dengan menyenaraikan nilai yang mungkin ini secara eksplisit dalam petunjuk. Walau bagaimanapun, masalah menjadi rumit kerana terdapat begitu banyak nilai yang mungkin.
Apabila bilangan nilai yang mungkin meningkat, kesukaran LLM memilih nilai juga meningkat. Di satu pihak, jika terdapat terlalu banyak nilai yang mungkin, nilai tersebut mungkin tidak sesuai dalam tetingkap konteks LLM. Sebaliknya, walaupun semua nilai yang mungkin boleh dimuatkan ke dalam konteks, termasuk kesemuanya menghasilkan pemprosesan yang lebih perlahan, peningkatan kos dan keupayaan penaakulan LLM yang dikurangkan apabila menangani sejumlah besar konteks. `Apabila bilangan nilai yang mungkin meningkat, kesukaran LLM memilih nilai meningkat. Di satu pihak, jika terdapat terlalu banyak nilai yang mungkin, nilai tersebut mungkin tidak sesuai dalam tetingkap konteks LLM. Sebaliknya, walaupun semua nilai yang mungkin boleh dimuatkan ke dalam konteks, termasuk kesemuanya menghasilkan pemprosesan yang lebih perlahan, peningkatan kos dan keupayaan penaakulan LLM yang dikurangkan apabila menangani sejumlah besar konteks. ` (Nota: Teks asal nampaknya dikodkan URL. Saya telah membetulkan pengekodan dan menyediakan teks yang ditulis semula.)
Baru-baru ini, kami telah menjalankan kajian mendalam tentang analisis pertanyaan dan apabila menyemak semula dokumentasi yang berkaitan, kami telah secara khusus menambah bahagian tentang cara menanganinya Halaman dengan nilai kardinaliti tinggi. Dalam blog ini, kami akan menyelami beberapa pendekatan percubaan dan memberikan hasil penanda aras prestasi mereka.
Gambaran keseluruhan keputusan boleh dilihat di LangSmith https://smith.langchain.com/public/8c0a4c25-426d-4582-96fc-d7def170be76/d?ref=blog.langchain.dev. Seterusnya, kami akan memperkenalkan secara terperinci:
 Pictures
Pictures
Dataset terperinci boleh dilihat di sini https://smith.langchain.com/public/8c0a4c25-5826c25-426df /d?ref=blog.langchain.dev.
Untuk mensimulasikan masalah ini, kami menganggap senario: kami ingin mencari buku tentang makhluk asing oleh pengarang tertentu. Dalam senario ini, medan penulis ialah pembolehubah kategori kardinaliti tinggi - terdapat banyak nilai yang mungkin, tetapi ia mestilah nama penulis yang sah khusus. Untuk menguji ini, kami mencipta set data yang mengandungi nama pengarang dan alias biasa. Contohnya, "Harry Chase" mungkin merupakan alias untuk "Harrison Chase." Kami mahu sistem pintar dapat mengendalikan jenis aliasing ini. Dalam set data ini, kami menghasilkan set data yang mengandungi senarai nama dan alias penulis. Ambil perhatian bahawa 10,000 nama rawak tidak terlalu banyak - untuk sistem peringkat perusahaan, anda mungkin perlu berurusan dengan kardinaliti dalam berjuta-juta.
Menggunakan set data ini, kami bertanya soalan: "Apakah buku Harry Chase tentang makhluk asing?" Dalam contoh ini, output yang dijangkakan ialah {"topic": "aliens", "author": "Harrison Chase"}. Kami menjangkakan sistem menyedari bahawa tiada pengarang bernama Harry Chase, tetapi Harrison Chase mungkin yang dimaksudkan oleh pengguna.
Dengan persediaan ini, kami boleh menguji terhadap set data alias yang kami buat untuk menyemak sama ada ia dipetakan dengan betul kepada nama sebenar. Pada masa yang sama, kami juga merekodkan kependaman dan kos pertanyaan. Sistem analisis pertanyaan jenis ini biasanya digunakan untuk carian, jadi kami sangat mengambil berat tentang kedua-dua penunjuk ini. Atas sebab ini, kami juga mengehadkan semua kaedah kepada hanya satu panggilan LLM. Kami mungkin menanda aras kaedah menggunakan berbilang panggilan LLM dalam artikel akan datang.
Seterusnya, kami akan memperkenalkan beberapa kaedah berbeza dan prestasinya.
 Pictures
Pictures
Hasil lengkap boleh dilihat dalam LangSmith, dan kod untuk menghasilkan semula keputusan ini boleh didapati di sini.
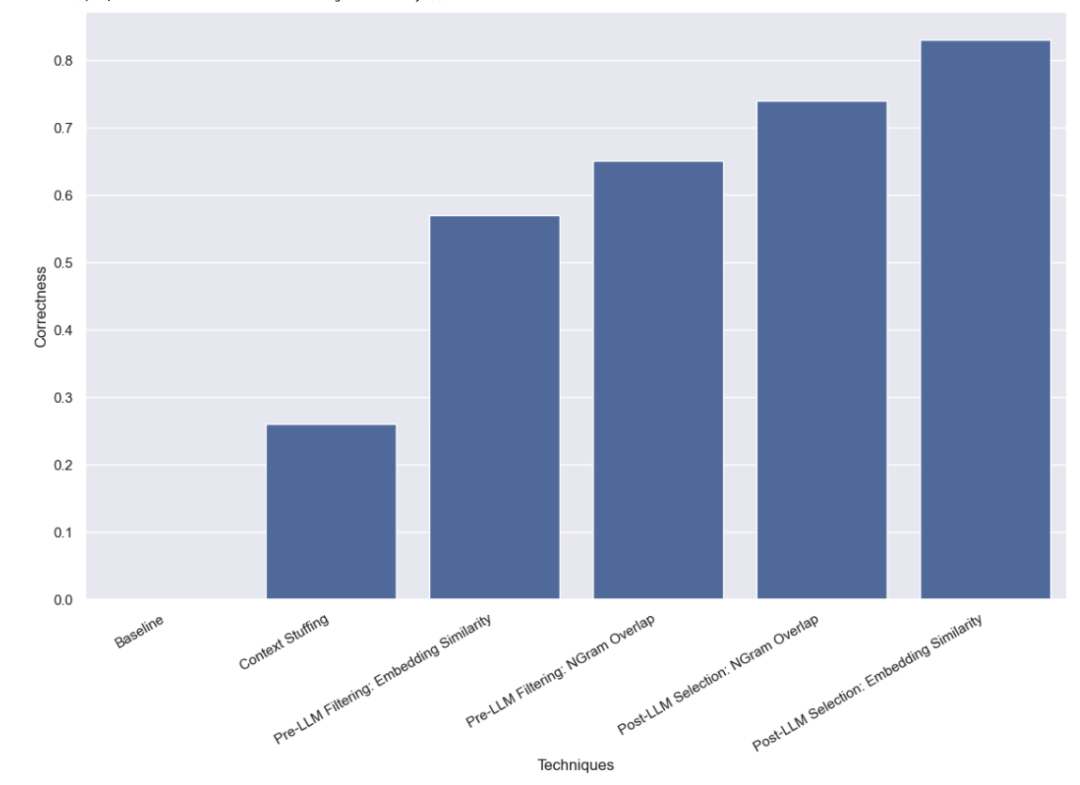
Pertama, kami menjalankan ujian garis dasar pada LLM, iaitu, secara langsung meminta LLM melakukan analisis pertanyaan tanpa memberikan sebarang maklumat nama yang sah. Seperti yang dijangka, tiada satu soalan pun dijawab dengan betul. Ini kerana kami sengaja membina set data yang memerlukan pengarang pertanyaan dengan alias.
Dalam kaedah ini, kami meletakkan kesemua 10,000 nama pengarang sah ke dalam gesaan dan meminta LLM mengingati bahawa ini adalah nama pengarang sah semasa melakukan analisis pertanyaan. Sesetengah model (seperti GPT-3.5) tidak dapat melaksanakan tugas ini kerana had tetingkap konteks. Untuk model lain dengan tetingkap konteks yang lebih panjang, mereka juga menghadapi kesukaran memilih nama yang betul dengan tepat. GPT-4 hanya memilih nama yang betul dalam 26% kes. Ralat yang paling biasa ialah mengekstrak nama tetapi tidak membetulkannya. Kaedah ini bukan sahaja lambat, ia juga mahal, mengambil purata 5 saat untuk disiapkan dan menelan belanja sebanyak $8.44.
Kaedah yang kami uji seterusnya ialah menapis senarai nilai yang mungkin sebelum menghantarnya ke LLM. Kelebihan ini ialah ia hanya menghantar subset nama yang mungkin kepada LLM, jadi LLM mempunyai lebih sedikit nama untuk dipertimbangkan, semoga membolehkannya melengkapkan analisis pertanyaan dengan lebih cepat, lebih murah dan lebih tepat. Tetapi ini juga menambah mod potensi kegagalan baharu - bagaimana jika penapisan awal menjadi salah?
Kaedah penapisan yang kami gunakan pada mulanya ialah kaedah benam dan memilih 10 nama yang paling serupa dengan pertanyaan. Ambil perhatian bahawa kami sedang membandingkan keseluruhan pertanyaan dengan nama, yang bukan perbandingan yang ideal!
Kami mendapati bahawa menggunakan pendekatan ini, GPT-3.5 dapat mengendalikan 57% kes dengan betul. Kaedah ini jauh lebih pantas dan lebih murah daripada kaedah sebelumnya, mengambil masa purata hanya 0.76 saat untuk diselesaikan, dengan jumlah kos hanya $0.002.
Kaedah penapisan kedua yang kami gunakan ialah untuk TF-IDF mengvektorkan jujukan aksara 3-gram bagi semua nama yang sah, dan menggunakan nama sah yang divektorkan dengan yang divektorkan Persamaan kosinus antara input pengguna digunakan untuk memilih 10 nama sah yang paling berkaitan untuk ditambahkan pada gesaan model. Juga ambil perhatian bahawa kami sedang membandingkan keseluruhan pertanyaan dengan nama, yang bukan perbandingan yang ideal!
Kami mendapati bahawa menggunakan pendekatan ini, GPT-3.5 dapat mengendalikan 65% kes dengan betul. Kaedah ini juga jauh lebih pantas dan lebih murah daripada kaedah sebelumnya, mengambil purata hanya 0.57 saat untuk disiapkan, dan jumlah kos hanya $0.002.
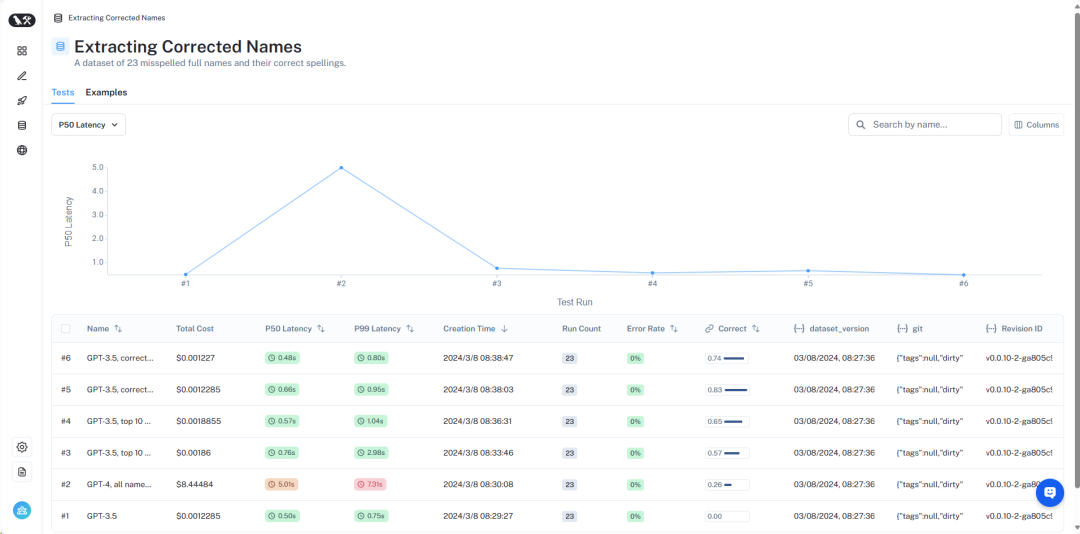
Kaedah terakhir yang kami uji ialah cuba membetulkan sebarang ralat selepas LLM menyelesaikan analisis pertanyaan awal. Kami mula-mula melakukan analisis pertanyaan pada input pengguna tanpa memberikan sebarang maklumat tentang nama pengarang yang sah dalam gesaan. Ini adalah ujian asas yang sama yang kami lakukan pada mulanya. Kami kemudian melakukan langkah seterusnya untuk mengambil nama dalam medan pengarang dan mencari nama sah yang paling serupa.
Mula-mula, kami melakukan semakan kesamaan menggunakan kaedah benam.
Kami mendapati bahawa menggunakan pendekatan ini, GPT-3.5 dapat mengendalikan 83% kes dengan betul. Kaedah ini jauh lebih pantas dan lebih murah daripada kaedah sebelumnya, mengambil purata hanya 0.66 saat untuk disiapkan, dan jumlah kos hanya $0.001.
Akhir sekali, kami cuba menggunakan vectorizer 3 gram untuk semakan persamaan.
Kami mendapati bahawa menggunakan pendekatan ini, GPT-3.5 dapat mengendalikan 74% kes dengan betul. Kaedah ini juga jauh lebih pantas dan lebih murah daripada kaedah sebelumnya, mengambil masa purata hanya 0.48 saat untuk disiapkan, dan jumlah kos hanya $0.001.
Kami menjalankan pelbagai penanda aras pada kaedah analisis pertanyaan untuk mengendalikan nilai kategori kardinaliti tinggi. Kami mengehadkan diri kami untuk membuat hanya satu panggilan LLM untuk mensimulasikan kekangan kependaman dunia sebenar. Kami mendapati bahawa membenamkan kaedah pemilihan berasaskan persamaan menunjukkan prestasi terbaik selepas menggunakan LLM.
Terdapat kaedah lain yang layak untuk diuji selanjutnya. Khususnya, terdapat banyak cara yang berbeza untuk mencari nilai kategori yang paling serupa sebelum atau selepas panggilan LLM. Selain itu, asas kategori dalam set data ini tidak setinggi yang dihadapi oleh kebanyakan sistem perusahaan. Set data ini mempunyai kira-kira 10,000 nilai, manakala banyak sistem dunia sebenar mungkin perlu mengendalikan kardinaliti dalam berjuta-juta. Oleh itu, penanda aras pada data kardinaliti yang lebih tinggi akan menjadi sangat berharga.
Atas ialah kandungan terperinci Amalan penilaian prestasi pertanyaan konteks ultra panjang LLM. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
 Bagaimanakah prestasi php8?
Bagaimanakah prestasi php8?
 Bagaimanakah prestasi thinkphp?
Bagaimanakah prestasi thinkphp?
 Bagaimana untuk membuat tatal gambar dalam ppt
Bagaimana untuk membuat tatal gambar dalam ppt
 Apakah arahan penutupan dan mulakan semula linux?
Apakah arahan penutupan dan mulakan semula linux?
 Mengapa video dalam ppt tidak boleh dimainkan?
Mengapa video dalam ppt tidak boleh dimainkan?
 Bagaimana untuk menukar perisian bahasa c ke bahasa Cina
Bagaimana untuk menukar perisian bahasa c ke bahasa Cina
 getelementbyid
getelementbyid
 Bagaimana untuk belajar pengaturcaraan python dari awal
Bagaimana untuk belajar pengaturcaraan python dari awal








![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



