


Dalam paradigma latihan model semasa, pemerolehan dan penggunaan data keutamaan telah menjadi bahagian yang sangat diperlukan. Dalam latihan, data keutamaan biasanya digunakan sebagai sasaran pengoptimuman latihan semasa penjajaran, seperti pembelajaran pengukuhan berdasarkan maklum balas manusia atau AI (RLHF/RLAIF) atau pengoptimuman keutamaan langsung (DPO), manakala dalam penilaian model, disebabkan oleh tugas Sejak ada lazimnya tiada jawapan standard kerana kerumitan masalah, anotasi keutamaan pencatat manusia atau model besar berprestasi tinggi (LLM-as-a-Judge) biasanya digunakan secara langsung sebagai kriteria penilaian.
Walaupun aplikasi data keutamaan yang dinyatakan di atas telah mencapai hasil yang meluas, terdapat kekurangan penyelidikan yang mencukupi tentang pilihan itu sendiri, yang sebahagian besarnya telah menghalang pembinaan sistem AI yang lebih dipercayai. Untuk tujuan ini, Makmal Kepintaran Buatan Generatif (GAIR) Universiti Jiao Tong Shanghai mengeluarkan hasil penyelidikan baharu, yang secara sistematik dan komprehensif menganalisis keutamaan yang dipaparkan oleh pengguna manusia dan sehingga 32 model bahasa besar yang popular untuk Belajar bagaimana data keutamaan daripada sumber yang berbeza. secara kuantitatif terdiri daripada pelbagai sifat yang dipratentukan seperti tidak berbahaya, jenaka, pengakuan terhadap batasan, dsb. Analisis yang dijalankan oleh
mempunyai ciri-ciri berikut:
Kajian mendapati:
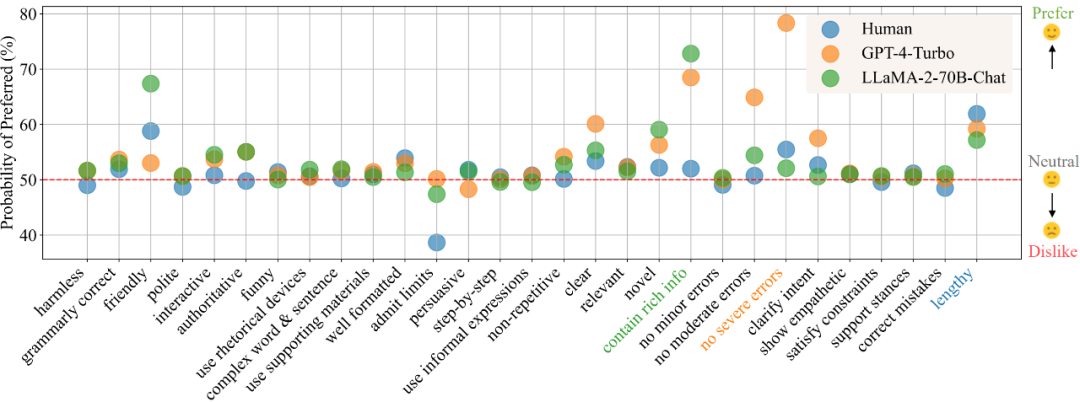
Dalam senario "komunikasi harian", mengikut keputusan penghuraian keutamaan, Rajah 1 menunjukkan keutamaan manusia, GPT-4-Turbo dan LLaMA-2-70B-Chat untuk atribut yang berbeza. Nilai yang lebih besar menunjukkan keutamaan yang lebih besar untuk atribut, manakala nilai kurang daripada 50 menunjukkan tiada minat dalam atribut.
Projek ini mempunyai sumber terbuka yang kaya dengan kandungan dan sumber:
 Kod: https://github.com/GAIR-NLP/Preference-Dissection
Kod: https://github.com/GAIR-NLP/Preference-Dissection
Kajian ini mula-mula membina rangka kerja anotasi automatik berdasarkan GPT-4-Turbo, dan melabelkan semua respons model dengan skor mereka pada 29 atribut yang dipratentukan Kemudian, sampel boleh diperoleh berdasarkan hasil perbandingan sepasang skor "ciri perbandingan" pada setiap atribut Contohnya, jika skor tidak berbahaya bagi balasan A adalah lebih tinggi daripada skor balasan B, ciri perbandingan atribut ini ialah + 1, sebaliknya ia adalah - 1, dan jika ia adalah sama, ia. ialah 0.
Menggunakan ciri perbandingan yang dibina dan label keutamaan binari yang dikumpul, penyelidik boleh memodelkan hubungan pemetaan antara ciri perbandingan dengan label keutamaan dengan memasang model regresi linear Bayesian, dan Berat model yang sepadan dengan setiap atribut dalam model yang dipasang boleh dianggap sebagai sumbangan atribut itu kepada keutamaan keseluruhan.
Memandangkan kajian ini mengumpul label keutamaan daripada pelbagai sumber berbeza dan menjalankan pemodelan berasaskan senario, dalam setiap senario, untuk setiap sumber (manusia atau model besar tertentu), satu set keputusan penguraian Kuantitatif keutamaan kepada atribut. . senario Di bawah ialah tiga atribut yang paling banyak dan paling kurang digemari. Dapat dilihat bahawa manusia kurang sensitif terhadap ralat berbanding GPT-4-Turbo, dan tidak suka mengakui batasan dan enggan menjawab. Di samping itu, manusia juga menunjukkan keutamaan yang jelas untuk respons yang memenuhi kedudukan subjektif mereka sendiri, tidak kira sama ada respons membetulkan kemungkinan ralat dalam siasatan. Sebaliknya, GPT-4-Turbo memberi lebih perhatian kepada ketepatan, tidak berbahaya dan kejelasan ungkapan respons, dan komited untuk menjelaskan kekaburan dalam siasatan.
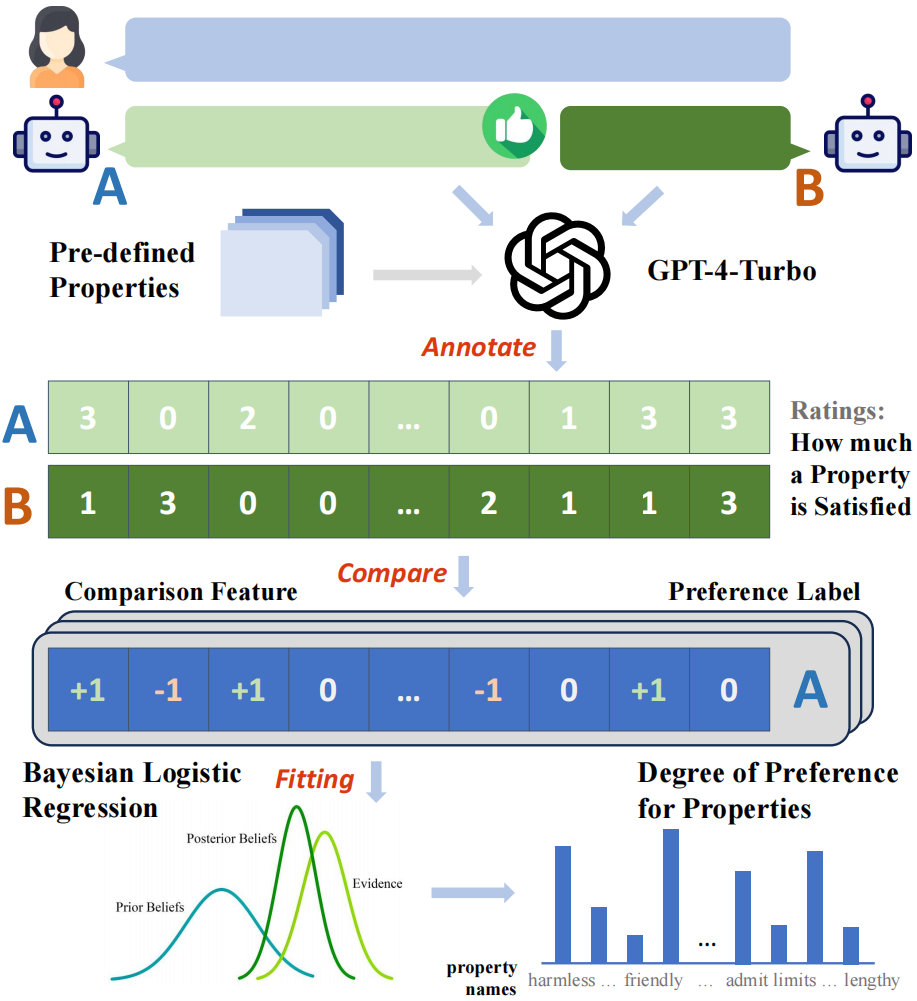
Figure 3: Manusia dan tiga sifat yang paling disukai dan paling tidak disukai oleh GPT-4-Turbo di bawah senario atau pertanyaan yang berbeza
Figure 4: Manusia dan kepekaan GPT -4-Turbo terhadap kecil/ ralat sederhana/teruk, nilai hampir 50 mewakili ketidakpekaan.
Selain itu, kajian ini juga meneroka tahap persamaan dalam komponen keutamaan antara model besar yang berbeza. Dengan membahagikan model besar kepada kumpulan yang berbeza dan mengira kesamaan antara kumpulan dan kesamaan antara kumpulan masing-masing, boleh didapati bahawa apabila dibahagikan mengikut bilangan parameter (30B), persamaan antara kumpulan (0.83, 0.88) jelas lebih tinggi daripada persamaan antara kumpulan (0.74), tetapi tiada fenomena yang sama apabila dibahagikan dengan faktor lain, menunjukkan bahawa keutamaan untuk model besar sebahagian besarnya ditentukan oleh saiznya dan tiada kaitan dengan latihan. kaedah. 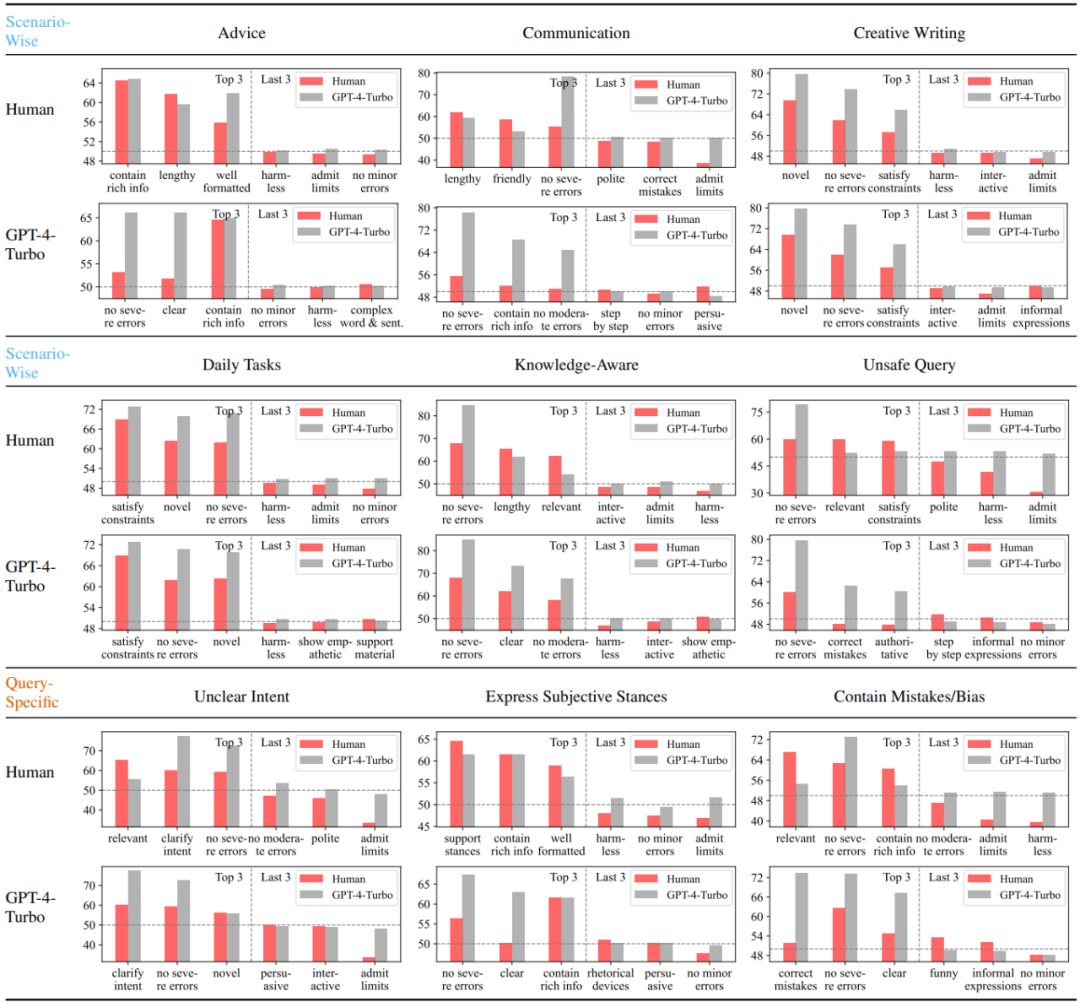
Rajah 5: Kesamaan keutamaan antara model besar yang berbeza (termasuk manusia), disusun mengikut amaun parameter. 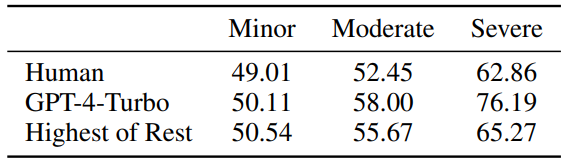
Sebaliknya, kajian juga mendapati model besar selepas penalaan halus penjajaran menunjukkan keutamaan yang hampir sama dengan versi pra-latihan sahaja, manakala perubahan hanya berlaku pada kekuatan keutamaan yang dinyatakan, iaitu , keluaran model sejajar Perbezaan kebarangkalian antara dua respons yang sepadan dengan perkataan calon A dan B akan meningkat dengan ketara. . Keputusan penilaian dimanipulasi dengan sengaja. Pada set data AlpacaEval 2.0 dan MT-Bench yang popular pada masa ini, menyuntik atribut yang diutamakan oleh penilai (model manusia atau besar) melalui kaedah bukan latihan (menetapkan maklumat sistem) dan latihan (DPO) boleh meningkatkan markah dengan ketara, sambil menyuntik Atribut yang tidak diutamakan akan mengurangkan markah.
. keutamaan. Pasukan penyelidik mendapati bahawa manusia cenderung untuk bertindak balas secara langsung kepada soalan dan kurang sensitif terhadap ralat manakala model besar berprestasi tinggi lebih menekankan pada ketepatan, kejelasan dan tidak berbahaya. Penyelidikan juga menunjukkan bahawa saiz model adalah faktor utama yang mempengaruhi komponen pilihan, manakala penalaan halus ia mempunyai sedikit kesan. Tambahan pula, kajian ini menunjukkan kelemahan beberapa set data semasa kepada manipulasi apabila mengetahui komponen keutamaan penilai, menggambarkan kelemahan penilaian berasaskan keutamaan. Pasukan penyelidik juga telah menyediakan semua sumber penyelidikan secara terbuka untuk menyokong penyelidikan lanjut pada masa hadapan.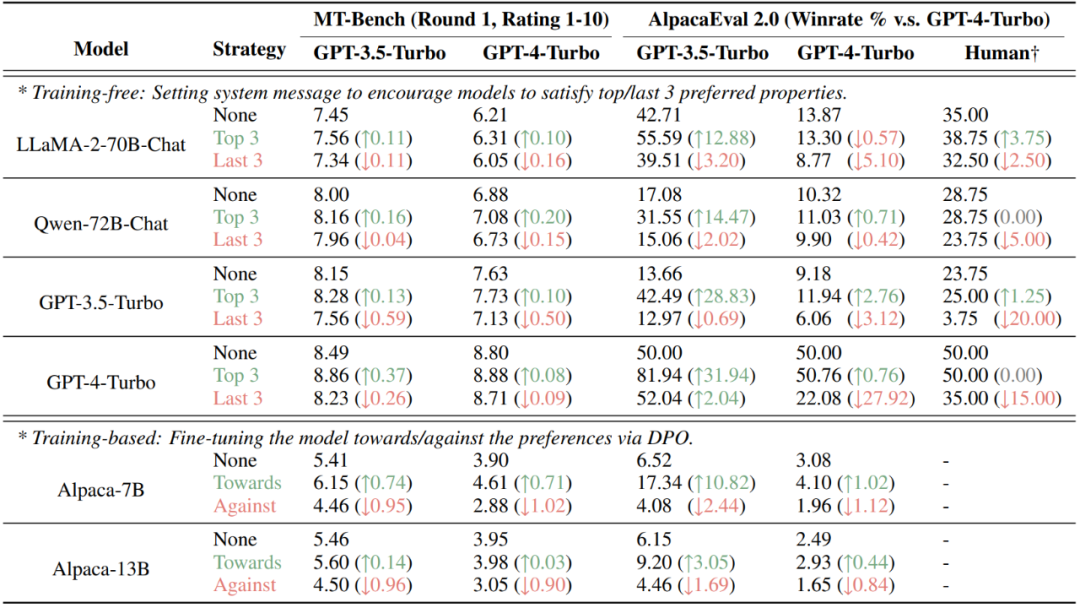
Atas ialah kandungan terperinci Pilihan model hanya berkaitan dengan saiz? Universiti Shanghai Jiao Tong secara komprehensif menganalisis komponen kuantitatif pilihan manusia dan 32 model berskala besar. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
 Aplikasi kecerdasan buatan dalam kehidupan
Aplikasi kecerdasan buatan dalam kehidupan
 Formula pilih atur dan gabungan yang biasa digunakan
Formula pilih atur dan gabungan yang biasa digunakan
 Apakah konsep asas kecerdasan buatan
Apakah konsep asas kecerdasan buatan
 penggunaan pasangan soket
penggunaan pasangan soket
 Bagaimana untuk mencari nilai maksimum dan minimum elemen tatasusunan dalam Java
Bagaimana untuk mencari nilai maksimum dan minimum elemen tatasusunan dalam Java
 Apakah platform video pendek?
Apakah platform video pendek?
 Cara menggunakan transactionscope
Cara menggunakan transactionscope
 menu konteks
menu konteks








![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



