


Selepas kemunculan model besar seperti GPT, kaedah model bahasa Transformer + autoregressive, yang merupakan tugas pra-latihan untuk meramal token seterusnya, telah mencapai kejayaan besar. Jadi, bolehkah kaedah pemodelan autoregresif ini mencapai hasil yang lebih baik dalam model visual? Artikel yang diperkenalkan hari ini ialah artikel yang diterbitkan oleh Apple baru-baru ini tentang melatih model visual berdasarkan latihan pra-latihan Transformer+autoregressive Izinkan saya memperkenalkan karya ini kepada anda. . . com/apple/ml-aim
2. Struktur model Struktur model adalah berdasarkan Transformer, dan menggunakan ramalan token seterusnya dalam model bahasa sebagai matlamat pengoptimuman. Pengubahsuaian utama adalah dalam tiga aspek. Pertama sekali, tidak seperti ViT, artikel ini menggunakan perhatian sehala GPT, iaitu elemen pada setiap kedudukan hanya mengira perhatian dengan elemen sebelumnya. Kedua, kami memperkenalkan lebih banyak maklumat kontekstual untuk meningkatkan keupayaan pemahaman bahasa model. Akhir sekali, kami mengoptimumkan tetapan parameter model untuk meningkatkan lagi prestasi. Dengan penambahbaikan ini, model kami mencapai peningkatan prestasi yang ketara pada tugas bahasa.
Struktur model adalah berdasarkan Transformer, dan menggunakan ramalan token seterusnya dalam model bahasa sebagai matlamat pengoptimuman. Pengubahsuaian utama adalah dalam tiga aspek. Pertama sekali, tidak seperti ViT, artikel ini menggunakan perhatian sehala GPT, iaitu elemen pada setiap kedudukan hanya mengira perhatian dengan elemen sebelumnya. Kedua, kami memperkenalkan lebih banyak maklumat kontekstual untuk meningkatkan keupayaan pemahaman bahasa model. Akhir sekali, kami mengoptimumkan tetapan parameter model untuk meningkatkan lagi prestasi. Dengan penambahbaikan ini, model kami mencapai peningkatan prestasi yang ketara pada tugas bahasa.
Dalam model Transformer, mekanisme baharu diperkenalkan, iaitu, berbilang token awalan ditambah di hadapan jujukan input. Token ini menggunakan mekanisme perhatian dua hala. Tujuan utama perubahan ini adalah untuk meningkatkan konsistensi antara aplikasi pra-latihan dan hiliran. Dalam tugas hiliran, kaedah perhatian dua hala yang serupa dengan ViT digunakan secara meluas. Dengan memperkenalkan perhatian dwiarah awalan dalam proses pra-latihan, model boleh menyesuaikan diri dengan lebih baik kepada keperluan pelbagai tugas hiliran. Penambahbaikan sedemikian boleh meningkatkan prestasi dan keupayaan generalisasi model.
Gambar
 Dari segi mengoptimumkan lapisan MLP keluaran akhir model, kaedah pra-latihan asal biasanya membuang lapisan MLP dan menggunakan MLP serba baharu dalam tugas hiliran. Ini adalah untuk mengelakkan MLP pra-latihan daripada terlalu berat sebelah terhadap tugas pra-latihan, mengakibatkan penurunan keberkesanan tugas hiliran. Walau bagaimanapun, dalam kertas ini, penulis mencadangkan pendekatan baru. Mereka menggunakan MLP bebas untuk setiap patch, dan juga menggunakan gabungan perwakilan dan perhatian setiap patch untuk menggantikan operasi pengumpulan tradisional. Dengan cara ini, kebolehgunaan ketua MLP yang telah terlatih dalam tugas hiliran dipertingkatkan. Melalui kaedah ini, penulis dapat mengekalkan maklumat imej keseluruhan dengan lebih baik dan mengelakkan masalah terlalu bergantung kepada tugasan pra-latihan. Ini sangat membantu untuk meningkatkan keupayaan generalisasi dan kebolehsuaian model. Berkenaan matlamat pengoptimuman, artikel itu mencuba dua kaedah Yang pertama adalah untuk menyesuaikan secara langsung piksel tampalan dan menggunakan MSE untuk ramalan. Yang kedua ialah tokenize tampalan imej terlebih dahulu, menukarnya menjadi tugas klasifikasi, dan menggunakan kehilangan entropi silang. Walau bagaimanapun, dalam eksperimen ablasi seterusnya dalam artikel, didapati bahawa walaupun kaedah kedua juga boleh membenarkan model dilatih secara normal, kesannya tidak sebaik yang berdasarkan kebutiran piksel MSE.
Dari segi mengoptimumkan lapisan MLP keluaran akhir model, kaedah pra-latihan asal biasanya membuang lapisan MLP dan menggunakan MLP serba baharu dalam tugas hiliran. Ini adalah untuk mengelakkan MLP pra-latihan daripada terlalu berat sebelah terhadap tugas pra-latihan, mengakibatkan penurunan keberkesanan tugas hiliran. Walau bagaimanapun, dalam kertas ini, penulis mencadangkan pendekatan baru. Mereka menggunakan MLP bebas untuk setiap patch, dan juga menggunakan gabungan perwakilan dan perhatian setiap patch untuk menggantikan operasi pengumpulan tradisional. Dengan cara ini, kebolehgunaan ketua MLP yang telah terlatih dalam tugas hiliran dipertingkatkan. Melalui kaedah ini, penulis dapat mengekalkan maklumat imej keseluruhan dengan lebih baik dan mengelakkan masalah terlalu bergantung kepada tugasan pra-latihan. Ini sangat membantu untuk meningkatkan keupayaan generalisasi dan kebolehsuaian model. Berkenaan matlamat pengoptimuman, artikel itu mencuba dua kaedah Yang pertama adalah untuk menyesuaikan secara langsung piksel tampalan dan menggunakan MSE untuk ramalan. Yang kedua ialah tokenize tampalan imej terlebih dahulu, menukarnya menjadi tugas klasifikasi, dan menggunakan kehilangan entropi silang. Walau bagaimanapun, dalam eksperimen ablasi seterusnya dalam artikel, didapati bahawa walaupun kaedah kedua juga boleh membenarkan model dilatih secara normal, kesannya tidak sebaik yang berdasarkan kebutiran piksel MSE.
3. Keputusan eksperimen
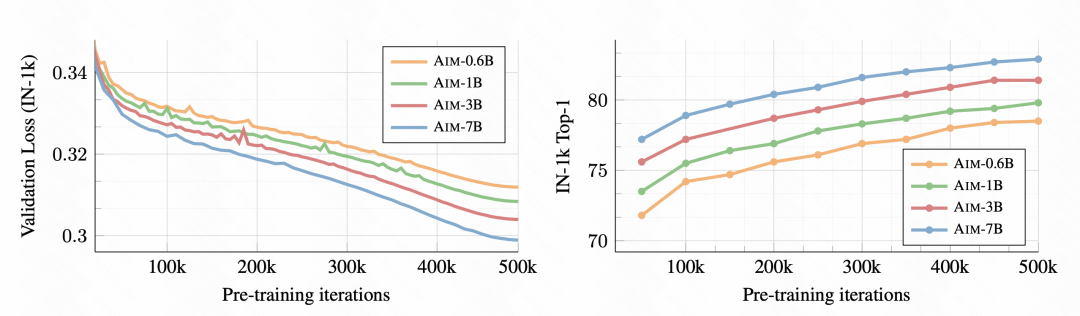
Bahagian percubaan artikel menganalisis secara terperinci kesan model imej berasaskan autoregresif ini dan kesan setiap bahagian terhadap kesan. 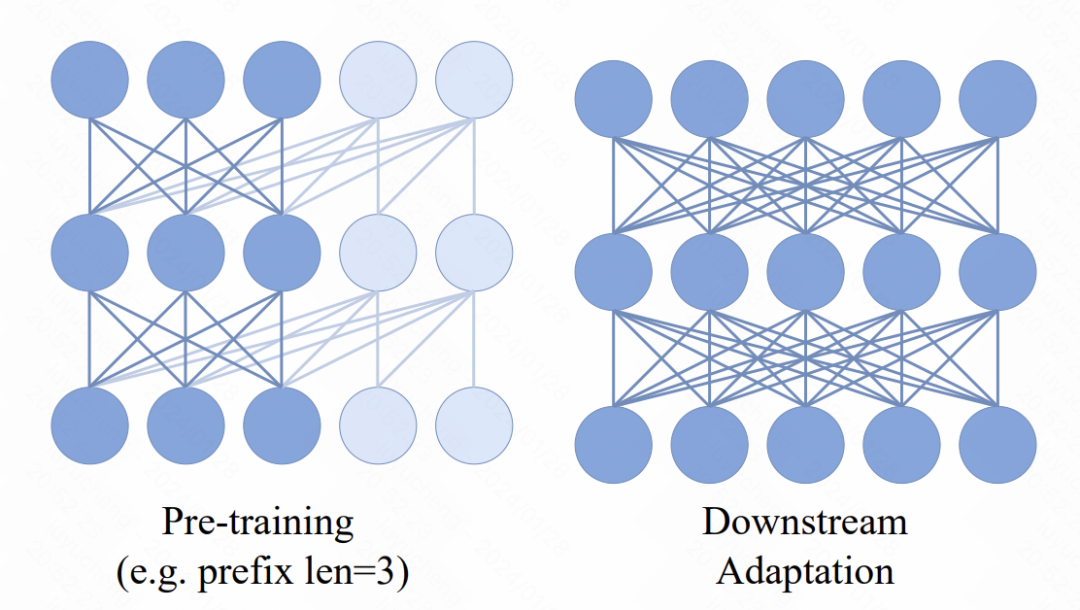 Pertama sekali, semasa latihan berlangsung, tugas klasifikasi imej hiliran menjadi lebih baik dan lebih baik, menunjukkan bahawa kaedah pra-latihan ini sememangnya boleh mempelajari maklumat perwakilan imej yang baik.
Pertama sekali, semasa latihan berlangsung, tugas klasifikasi imej hiliran menjadi lebih baik dan lebih baik, menunjukkan bahawa kaedah pra-latihan ini sememangnya boleh mempelajari maklumat perwakilan imej yang baik.
Gambar
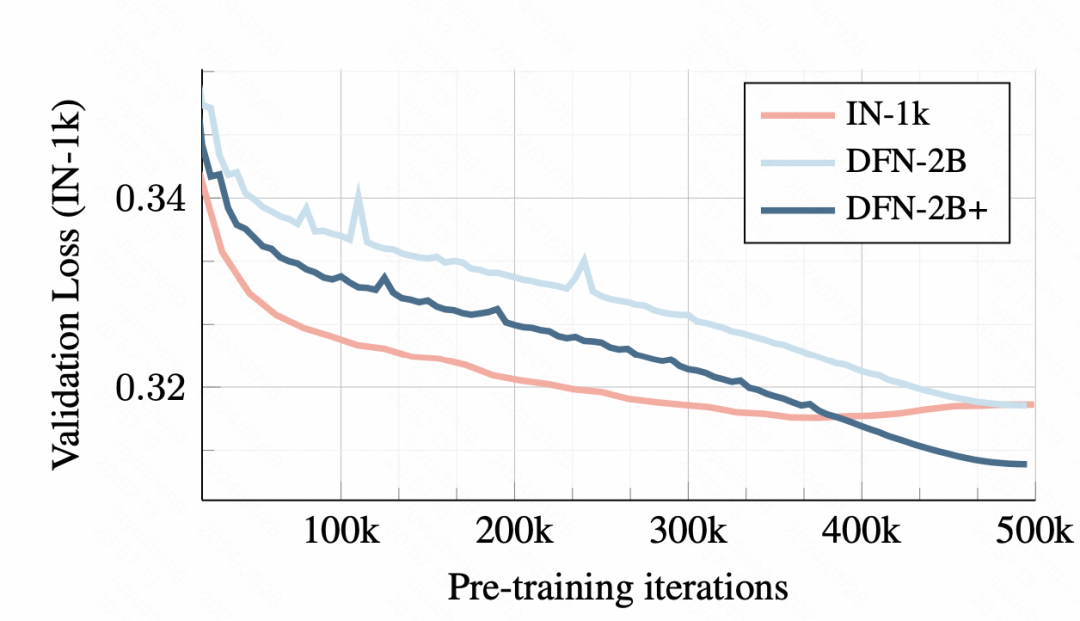
 Mengenai reka bentuk setiap modul model, artikel itu juga menjalankan analisis eksperimen ablasi terperinci.
Mengenai reka bentuk setiap modul model, artikel itu juga menjalankan analisis eksperimen ablasi terperinci.
Gambar
 Dalam perbandingan kesan akhir, AIM telah mencapai keputusan yang sangat baik, yang juga mengesahkan bahawa kaedah pra-latihan autoregresif ini juga tersedia pada imej, dan mungkin menjadi kaedah pra-latihan untuk skala besar berikutnya model imej Salah satu cara utama latihan.
Dalam perbandingan kesan akhir, AIM telah mencapai keputusan yang sangat baik, yang juga mengesahkan bahawa kaedah pra-latihan autoregresif ini juga tersedia pada imej, dan mungkin menjadi kaedah pra-latihan untuk skala besar berikutnya model imej Salah satu cara utama latihan. 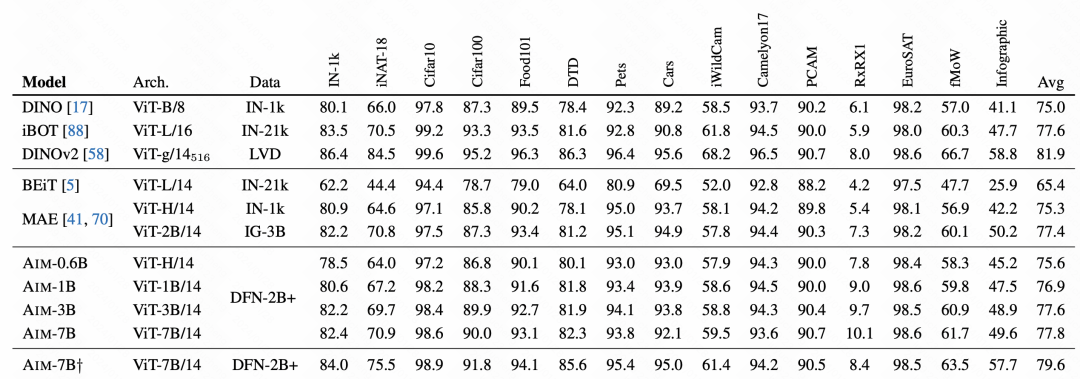 Gambar
Gambar
Atas ialah kandungan terperinci Apple menggunakan model bahasa autoregresif untuk pra-melatih model imej. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
 Bagaimana untuk kembali ke halaman utama dari subhalaman html
Bagaimana untuk kembali ke halaman utama dari subhalaman html
 Peranan pycharm
Peranan pycharm
 Bagaimana untuk menyelesaikan ralat1
Bagaimana untuk menyelesaikan ralat1
 Pengenalan kepada kekunci pintasan untuk meminimumkan tingkap tingkap
Pengenalan kepada kekunci pintasan untuk meminimumkan tingkap tingkap
 Penjelasan terperinci tentang penggunaan fungsi substr oracle
Penjelasan terperinci tentang penggunaan fungsi substr oracle
 Apakah platform Kuai Tuan Tuan?
Apakah platform Kuai Tuan Tuan?
 WiFi disambungkan tetapi terdapat tanda seru
WiFi disambungkan tetapi terdapat tanda seru
 Bagaimana untuk membuka fail mdf
Bagaimana untuk membuka fail mdf








![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



