


Sebuah "model besar berbilang modal pertama orang muda" yang dipanggil Vary-toy ada di sini!
Saiz model kurang daripada 2B, ia boleh dilatih pada kad grafik gred pengguna, dan ia boleh berjalan dengan mudah pada kad grafik lama GTX1080ti 8G.
Ingin menukar imej dokumen kepada format Markdown? Pada masa lalu, berbilang langkah seperti pengecaman teks, pengesanan dan pengisihan reka letak, pemprosesan jadual formula dan pembersihan teks diperlukan.
Kini anda hanya memerlukan satu arahan:
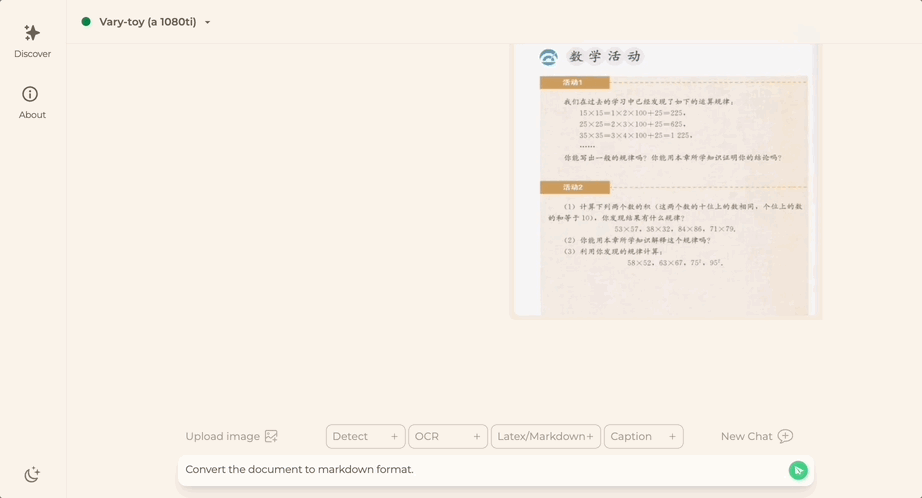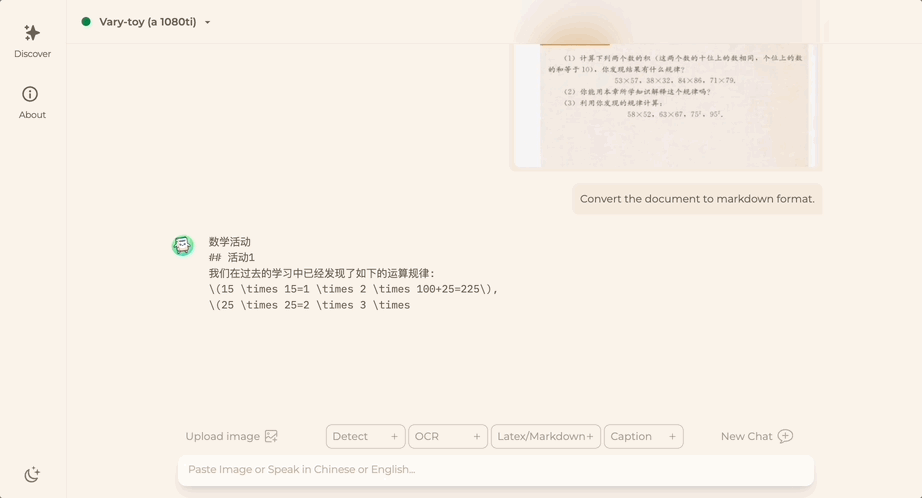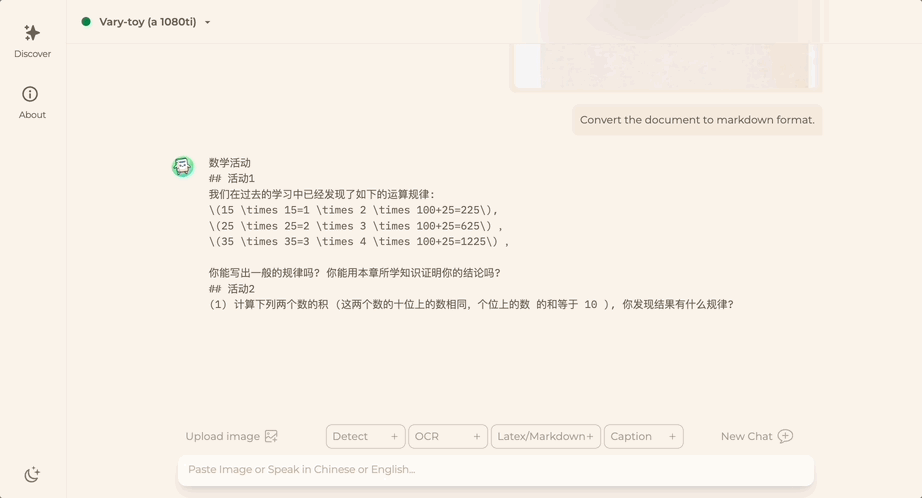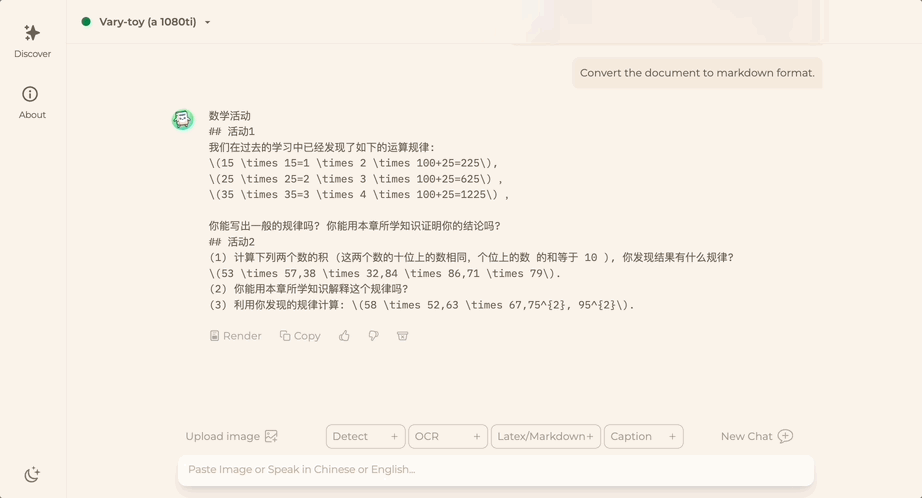
Tidak kira Bahasa Cina atau Inggeris, teks besar dalam gambar boleh diekstrak dalam beberapa minit:

Pengesanan objek pada gambar tertentu masih boleh memberi koordinat:

Kajian ini dicadangkan bersama oleh penyelidik dari Megvii, Universiti Sains dan Teknologi Kebangsaan, dan Universiti Huazhong.
Menurut laporan, walaupun Vary-toy kecil, ia merangkumi hampir semua keupayaan dalam penyelidikan arus perdana semasa LVLM(Model Bahasa Visual Skala Besar): pengecaman OCR dokumen(OCR Dokumen), kedudukan visual(Visual Pembumian) , Kapsyen Imej, Menjawab Soalan Visual (VQA) .


GTX1080 lama, dan mood mereka seperti:

, tetapi ramai orang tidak dapat menjalankannya kerana sumber yang terhad.
Memandangkan terdapat sedikit VLM "kecil" yang mempunyai sumber terbuka yang baik dan mempunyai prestasi yang sangat baik, pasukan itu baru mengeluarkan Vary-toy, yang dikenali sebagai "model besar berbilang mod pertama orang muda". Berbanding dengan Vary, Vary-toy bukan sahaja lebih kecil, tetapi juga melatihperbendaharaan kata visual yang lebih kuat Perbendaharaan kata baharu tidak lagi mengehadkan model kepada OCR peringkat dokumen, tetapi memberikan perbendaharaan kata visual yang lebih sejagat dan komprehensif. yang bukan sahaja boleh melakukan OCR peringkat dokumen, tetapi juga pengesanan sasaran visual umum. Jadi bagaimana ini dilakukan?
Struktur model dan proses latihan Vary-toy ditunjukkan dalam rajah di bawah Secara umumnya, latihan dibahagikan kepada dua peringkat.
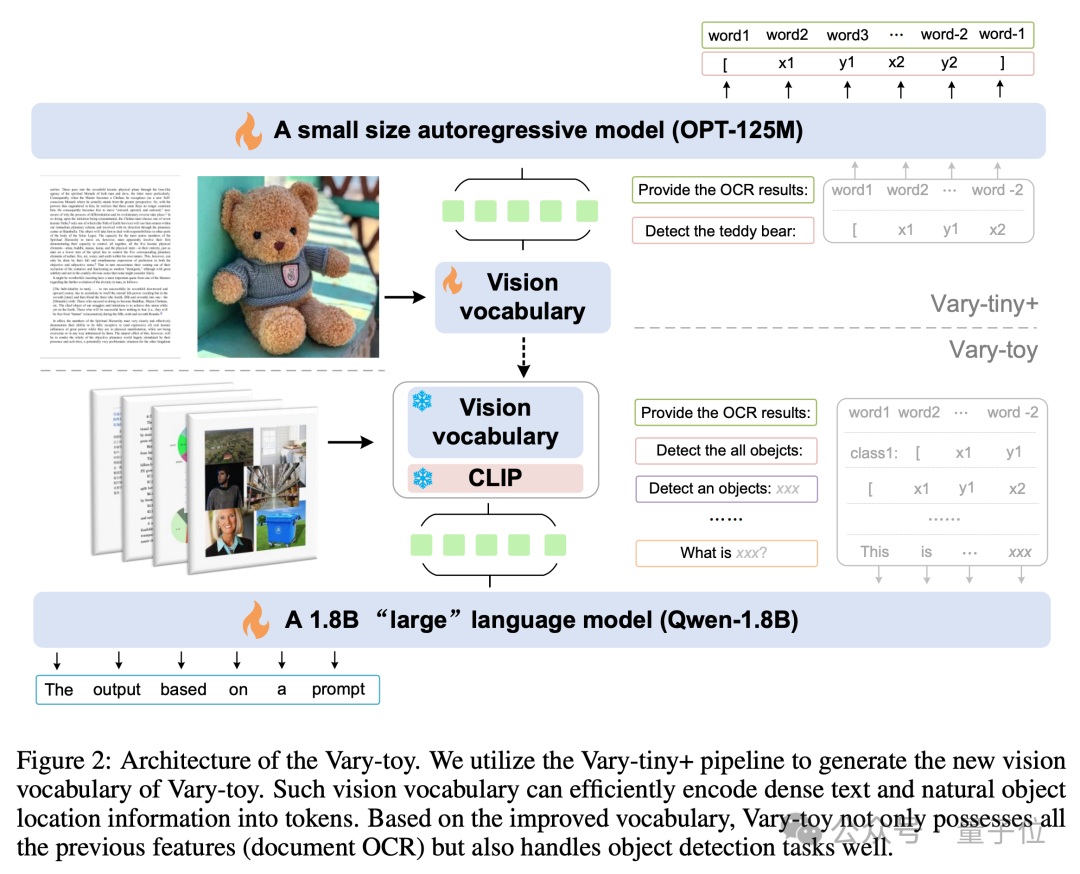 Pertama sekali, pada peringkat pertama, struktur Vary-tiny+ digunakan untuk pra-melatih perbendaharaan kata visual yang lebih baik daripada Vary asal Kosa kata visual baharu menyelesaikan masalah yang hanya digunakan oleh Vary asal untuk OCR peringkat dokumen Masalah pembaziran kapasiti dan masalah tidak menggunakan sepenuhnya kelebihan pra-latihan SAM.
Pertama sekali, pada peringkat pertama, struktur Vary-tiny+ digunakan untuk pra-melatih perbendaharaan kata visual yang lebih baik daripada Vary asal Kosa kata visual baharu menyelesaikan masalah yang hanya digunakan oleh Vary asal untuk OCR peringkat dokumen Masalah pembaziran kapasiti dan masalah tidak menggunakan sepenuhnya kelebihan pra-latihan SAM.
Kemudian pada peringkat kedua, perbendaharaan kata visual yang dilatih pada peringkat pertama digabungkan ke dalam struktur akhir untuk latihan pelbagai tugas/SFT.
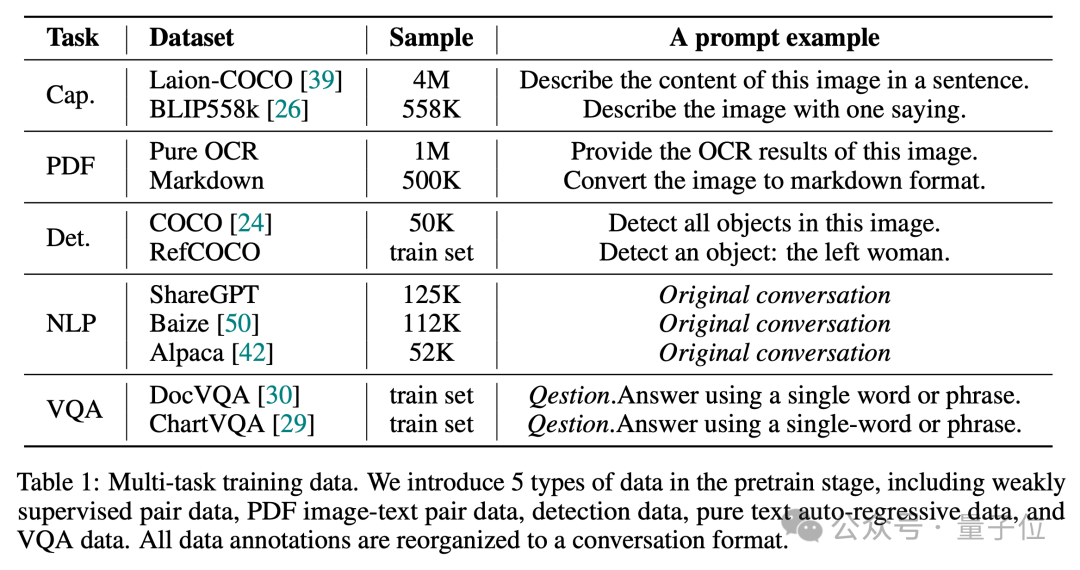
Seperti yang kita sedia maklum, nisbah data yang baik adalah penting untuk menjana VLM dengan keupayaan menyeluruh.
Jadi dalam peringkat pra-latihan, Vary-toy menggunakan data daripada 5 jenis tugasan untuk membina dialog Nisbah data dan gesaan sampel adalah seperti yang ditunjukkan dalam rajah di bawah:
 Dalam peringkat SFT, hanya LLaVA. -80K data telah digunakan. Untuk butiran lanjut teknikal, sila lihat laporan teknikal Vary-toy.
Dalam peringkat SFT, hanya LLaVA. -80K data telah digunakan. Untuk butiran lanjut teknikal, sila lihat laporan teknikal Vary-toy.
Keputusan ujian eksperimen
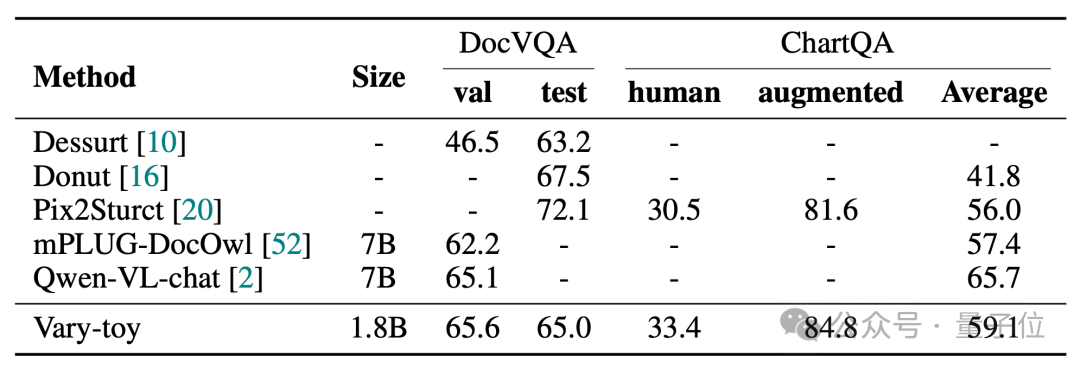
Vary-toy boleh mencapai 65.6% ANLS pada DocVQA, 59.1% ketepatan pada ChartQA, dan 88.1% ketepatan pada RefCOCO:
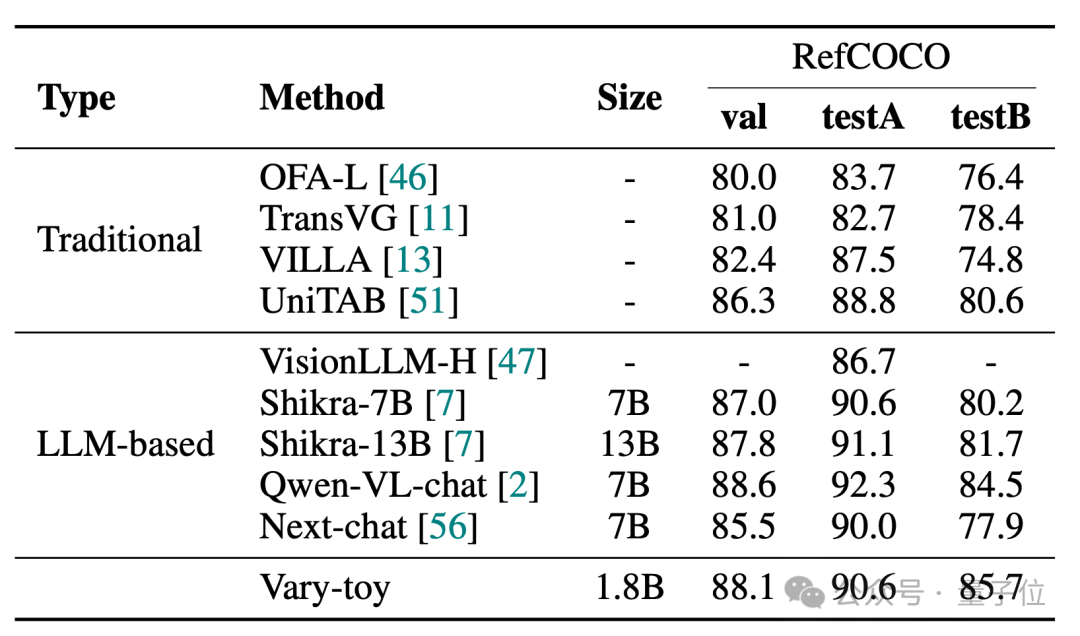
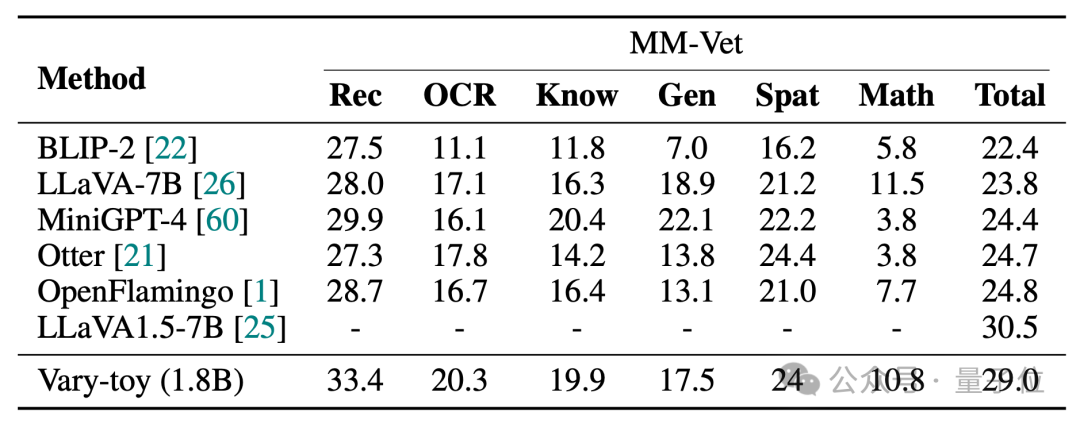
MMVet boleh mencapai ketepatan 29% daripada segi visual atau penanda aras , Vary-toy, yang kurang daripada 2B, malah boleh bersaing dengan prestasi beberapa model 7B yang popular.
Pautan projek:
[1]https://arxiv.org/abs/2401.12503
[3]https://varytoy.github.io/
Atas ialah kandungan terperinci Model besar berbilang modal disukai oleh golongan muda dalam talian dengan sumber terbuka: dengan mudah menjalankan 1080Ti. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
 Bagaimana untuk mengikat data dalam senarai lungsur
Bagaimana untuk mengikat data dalam senarai lungsur
 koleksi kod latar belakang css
koleksi kod latar belakang css
 Pelayan tidak boleh ditemui pada penyelesaian komputer
Pelayan tidak boleh ditemui pada penyelesaian komputer
 Bagaimana untuk memuat turun video dari Douyin
Bagaimana untuk memuat turun video dari Douyin
 Semak ruang cakera dalam linux
Semak ruang cakera dalam linux
 Bagaimana untuk mendapatkan nombor input dalam java
Bagaimana untuk mendapatkan nombor input dalam java
 Sebab utama mengapa komputer menggunakan binari
Sebab utama mengapa komputer menggunakan binari
 Bagaimana untuk membuka fail exe
Bagaimana untuk membuka fail exe








![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



