


Dengan kejayaan model bahasa besar seperti LLaMA dan Mistral, banyak syarikat telah mula mencipta model bahasa besar mereka sendiri. Walau bagaimanapun, melatih model baharu dari awal adalah mahal dan mungkin mempunyai keupayaan yang berlebihan.
Baru-baru ini, penyelidik dari Universiti Sun Yat-sen dan Tencent AI Lab mencadangkan FuseLLM, yang digunakan untuk "menggabungkan berbilang model besar heterogen."
Berbeza daripada kaedah penyepaduan model tradisional dan penggabungan berat, FuseLLM menyediakan cara baharu untuk menggabungkan pengetahuan pelbagai model bahasa besar yang heterogen. Daripada menggunakan berbilang model bahasa besar pada masa yang sama atau memerlukan penggabungan hasil model, FuseLLM menggunakan kaedah latihan berterusan yang ringan untuk memindahkan pengetahuan dan keupayaan model individu ke dalam model bahasa besar yang digabungkan. Apa yang unik tentang pendekatan ini ialah keupayaannya untuk menggunakan pelbagai model bahasa besar yang heterogen pada masa inferens dan mengeksternalkan pengetahuan mereka ke dalam model bercantum. Dengan cara ini, FuseLLM meningkatkan prestasi dan kecekapan model dengan berkesan.
Makalah ini baru sahaja diterbitkan di arXiv dan telah menarik perhatian dan kiriman daripada netizen.

Seseorang fikir ia menarik untuk melatih model dalam bahasa lain dan saya telah memikirkannya.
Pada masa ini kertas kerja ini telah diterima oleh ICLR 2024.

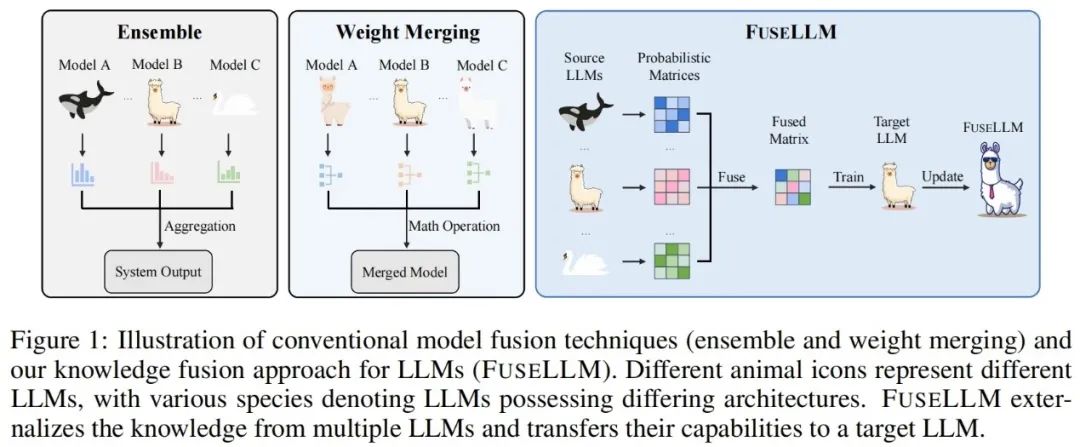
Untuk menggabungkan pengetahuan kolektif berbilang model bahasa besar sambil mengekalkan kelebihan masing-masing, strategi untuk perwakilan yang dijana model gabungan perlu direka dengan teliti. Secara khususnya, FuseLLM menilai sejauh mana model bahasa besar yang berbeza memahami teks ini dengan mengira entropi silang antara perwakilan yang dijana dan teks label, dan kemudian memperkenalkan dua fungsi gabungan berasaskan entropi silang:
Hasil eksperimen
Pengarang menilai FuseLLM dalam senario seperti penaakulan umum, penaakulan akal, penjanaan kod, penjanaan teks dan arahan yang mengikuti, dan mendapati ia mencapai peningkatan prestasi yang ketara berbanding semua model sumber dan model garis dasar latihan yang berterusan. . peningkatan purata sebanyak 1.86% telah dicapai pada setiap tugas, manakala FuseLLM telah mencapai peningkatan 5.16% berbanding Llama-2, yang jauh lebih baik daripada Llama-2 CLM, menunjukkan bahawa FuseLLM boleh menggabungkan kelebihan berbilang model bahasa besar untuk mencapai penambahbaikan prestasi. Pada Penanda Aras Common Sense, yang menguji keupayaan penaakulan akal, FuseLLM mengatasi semua model sumber dan model asas, mencapai prestasi terbaik pada semua tugas. . 6.36%. Sebab mengapa FuseLLM tidak mengatasi MPT dan OpenLLaMA mungkin disebabkan oleh penggunaan Llama-2 sebagai model bahasa besar sasaran, yang mempunyai keupayaan penjanaan kod yang lemah dan bahagian data kod yang rendah dalam korpus latihan berterusan, menyumbang hanya kira-kira 7.59%. Pada tanda aras penjanaan berbilang teks yang mengukur jawapan soalan pengetahuan (TrivialQA), pemahaman bacaan (DROP), analisis kandungan (LAMBADA), terjemahan mesin (IWSLT2017) dan aplikasi teorem (SciBench), FuseLLM juga mengatasi semua tugas mengatasi semua sumber model dan mengatasi prestasi Llama-2 CLM dalam 80% tugasan.
Oleh kerana FuseLLM hanya perlu mengekstrak perwakilan model berbilang sumber untuk gabungan, dan kemudian terus melatih model sasaran yang besar, ia juga boleh digunakan secara berterusan untuk memperhalusi model bahasa dengan arahan. Pada Penanda Aras Vicuna, yang menilai keupayaan mengikut arahan, FuseLLM juga mencapai prestasi cemerlang, mengatasi semua model sumber dan CLM. FuseLLM lwn. Penyulingan Pengetahuan & integrasi model & penggabungan berat
Memandangkan penyulingan pengetahuan juga merupakan satu kaedah untuk mempertingkatkan penyulingan pengetahuan untuk mempertingkatkan penggunaan bahasa LLM. dan Llama- 2 13B suling Llama-2 KD dibandingkan. Keputusan menunjukkan bahawa FuseLLM mengatasi penyulingan daripada model 13B tunggal dengan menggabungkan tiga model 7B dengan seni bina yang berbeza. Untuk membandingkan FuseLLM dengan kaedah gabungan sedia ada (seperti model ensembel dan penggabungan berat), penulis mensimulasikan senario di mana pelbagai model sumber datang daripada model asas struktur yang sama, tetapi dilatih secara berterusan pada korpora yang berbeza , dan menguji kebingungan pelbagai kaedah pada penanda aras ujian yang berbeza. Ia boleh dilihat bahawa walaupun semua teknik gabungan boleh menggabungkan kelebihan model berbilang sumber, FuseLLM boleh mencapai kebingungan purata terendah, menunjukkan bahawa FuseLLM mempunyai potensi untuk menggabungkan pengetahuan kolektif model sumber dengan lebih berkesan daripada kaedah ensembel model dan penggabungan berat. Akhirnya, walaupun masyarakat kini memberi perhatian kepada gabungan model besar, pendekatan semasa kebanyakannya berdasarkan penggabungan berat dan tidak boleh diperluaskan kepada model senario gabungan struktur dan saiz yang berbeza. Walaupun FuseLLM hanyalah penyelidikan awal mengenai gabungan model heterogen, memandangkan pada masa ini terdapat sebilangan besar model besar bahasa, visual, audio dan pelbagai mod struktur dan saiz yang berbeza dalam komuniti teknikal, apakah gabungan model heterogen ini. meletus pada masa hadapan? Mari tunggu dan lihat! 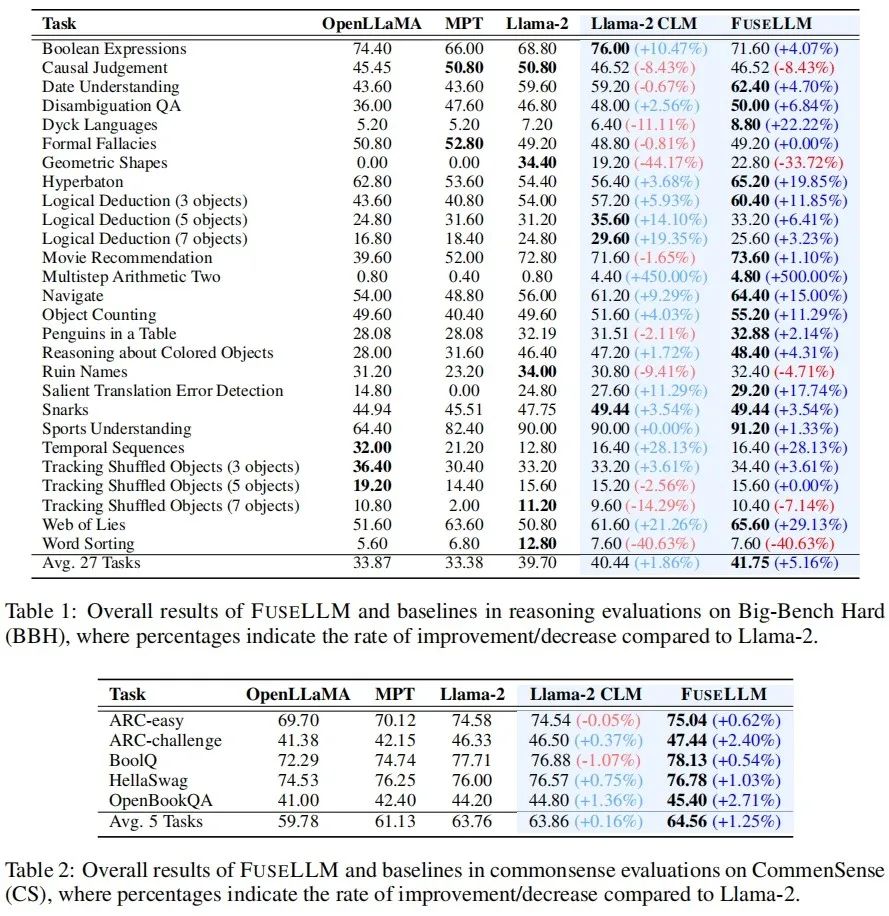


Atas ialah kandungan terperinci Gabungan pelbagai model besar heterogen membawa hasil yang menakjubkan. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
 Kaedah pengesanan pautan mati laman web
Kaedah pengesanan pautan mati laman web
 Penggunaan asas pernyataan sisipan
Penggunaan asas pernyataan sisipan
 Penggunaan fungsi ppf dalam Python
Penggunaan fungsi ppf dalam Python
 pertukaran mata wang
pertukaran mata wang
 Penyelesaian untuk kehilangan xlive.dll
Penyelesaian untuk kehilangan xlive.dll
 Bagaimana untuk menyelesaikan masalah bahawa pengurus peranti tidak boleh dibuka
Bagaimana untuk menyelesaikan masalah bahawa pengurus peranti tidak boleh dibuka
 tutorial pemasangan pycharm
tutorial pemasangan pycharm
 Bagaimana untuk mendapatkan data dalam html
Bagaimana untuk mendapatkan data dalam html








![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



