


Algoritma k-nerest neighbor ialah algoritma pembelajaran mesin berasaskan contoh atau berasaskan memori untuk pengelasan dan pengecaman. Prinsipnya adalah untuk mengelaskan dengan mencari data jiran terdekat bagi titik pertanyaan yang diberikan. Memandangkan algoritma sangat bergantung pada data latihan yang disimpan, ia boleh dilihat sebagai kaedah pembelajaran bukan parametrik.
k algoritma jiran terdekat sesuai untuk menangani masalah klasifikasi atau regresi. Untuk masalah klasifikasi ia berfungsi dengan nilai diskret manakala untuk masalah regresi ia berfungsi dengan nilai berterusan. Sebelum pengelasan, jarak mesti ditakrifkan, dan terdapat banyak pilihan untuk ukuran jarak biasa.
Ini ialah ukuran jarak yang biasa digunakan dan berfungsi untuk vektor bernilai sebenar. Formula mengukur jarak garis lurus antara titik pertanyaan dan titik lain.
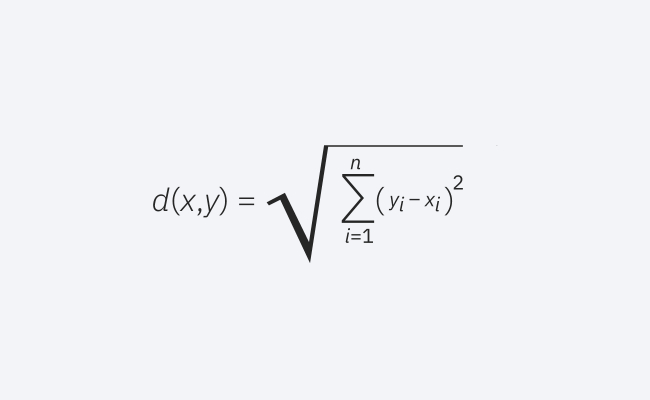
Formula Jarak Euclidean
Ini juga merupakan ukuran jarak popular yang mengukur nilai mutlak antara dua mata.

Formula jarak Manhattan
Ukuran jarak ini ialah bentuk umum bagi ukuran jarak Euclidean dan Manhattan.

Formula Jarak Minkowski
Teknik ini sering digunakan dengan vektor boolean atau rentetan untuk mengenal pasti titik di mana vektor tidak sepadan. Oleh itu, ia juga dipanggil ukuran pertindihan.

Formula jarak hamming
Untuk menentukan titik data yang paling hampir dengan titik pertanyaan tertentu, jarak antara titik pertanyaan dan titik data lain perlu dikira. Langkah-langkah jarak ini membantu membentuk sempadan keputusan yang membahagikan titik pertanyaan kepada kawasan yang berbeza.
Atas ialah kandungan terperinci Aplikasi kaedah pengukuran jarak yang biasa digunakan dalam algoritma jiran terdekat K. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
















![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



