


Kini terdapat juga dokumen resolusi tinggi berbilang modal yang besar!
Teknologi ini bukan sahaja boleh mengenal pasti maklumat dalam imej dengan tepat, tetapi juga memanggil pangkalan pengetahuannya sendiri untuk menjawab soalan mengikut keperluan pengguna
Sebagai contoh, apabila anda melihat antara muka Mario dalam gambar, anda boleh terus menjawab bahawa ia adalah dari Nintendo bekerja.

Model ini telah dikaji bersama oleh ByteDance dan Universiti Sains dan Teknologi China, dan dimuat naik ke arXiv pada 24 November 2023
Dalam penyelidikan ini, pasukan pengarang mencadangkan DocPedia, sebuah resolusi tinggi bersatu Dokumen multimodal model besar DocPedia.

Digabungkan dengan maklumat teks dalam imej, DocPedia juga boleh menggunakan keupayaan penaakulan model yang besar untuk menganalisis masalah berdasarkan konteks. 
Selepas membaca maklumat imej, DocPedia juga akan menjawab kandungan lanjutan yang tidak ditunjukkan dalam imej berdasarkan asas pengetahuan dunianya yang kaya
Jadual berikut secara kuantitatif membandingkan beberapa model besar berbilang mod sedia ada dan kunci DocPedia pengekstrakan maklumat (KIE) dan keupayaan menjawab soalan visual (VQA). 
Jadi, bagaimanakah DocPedia mencapai kesan sedemikian? 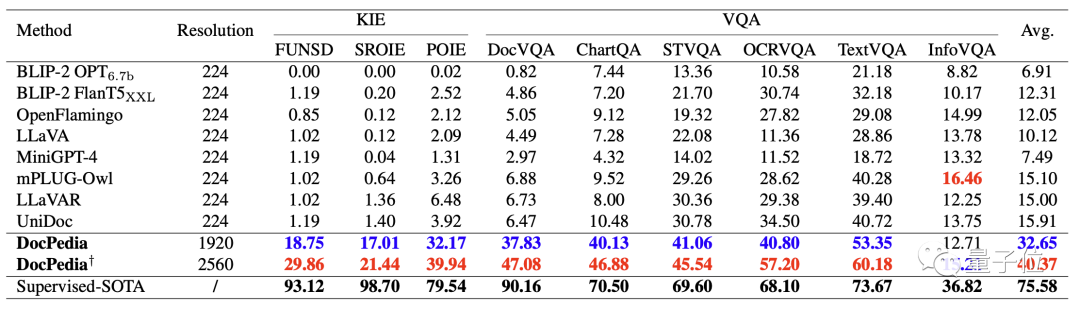
Dari segi strategi untuk isu penyelesaian, berbeza dengan kaedah sedia ada, DocPedia menyelesaikannya dari perspektif 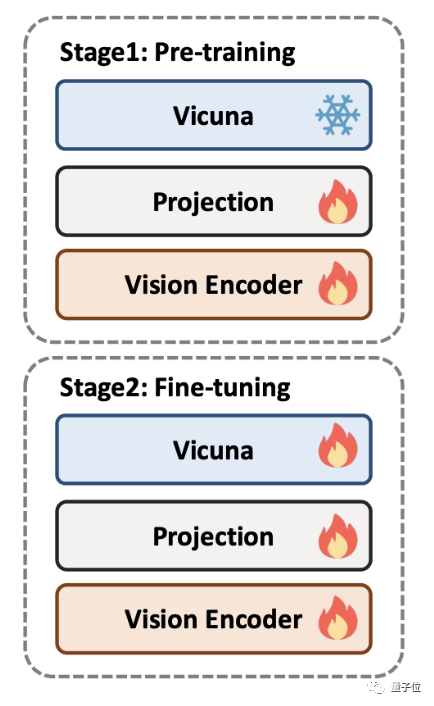 domain frekuensi
domain frekuensi
Apabila memproses imej dokumen resolusi tinggi, DocPedia mula-mula mengekstrak matriks pekali DCTnya. Matriks ini boleh menurunkan sampel resolusi spatial 8 kali tanpa kehilangan maklumat teks imej asal
Selepas langkah ini, kami akan menggunakan penyesuai domain frekuensi bertingkat (Penyesuai Frekuensi) untuk menghantar isyarat input Kepada Pengekod Penglihatan untuk pemampatan resolusi yang lebih mendalam dan pengekstrakan ciriDengan kaedah ini, imej 2560×2560 boleh diwakili oleh 1600 token.
Berbanding dengan memasukkan terus imej asal ke dalam pengekod visual (seperti Swin Transformer), kaedah ini mengurangkan bilangan token sebanyak 4 kali ganda.
Akhir sekali, token ini digabungkan dengan token yang ditukar daripada arahan dalam dimensi jujukan dan dimasukkan ke dalam model besar untuk jawapan.
Hasil eksperimen ablasi menunjukkan bahawa meningkatkan resolusi dan melakukan penalaan kefahaman persepsi bersama adalah dua faktor penting untuk meningkatkan prestasi DocPedia
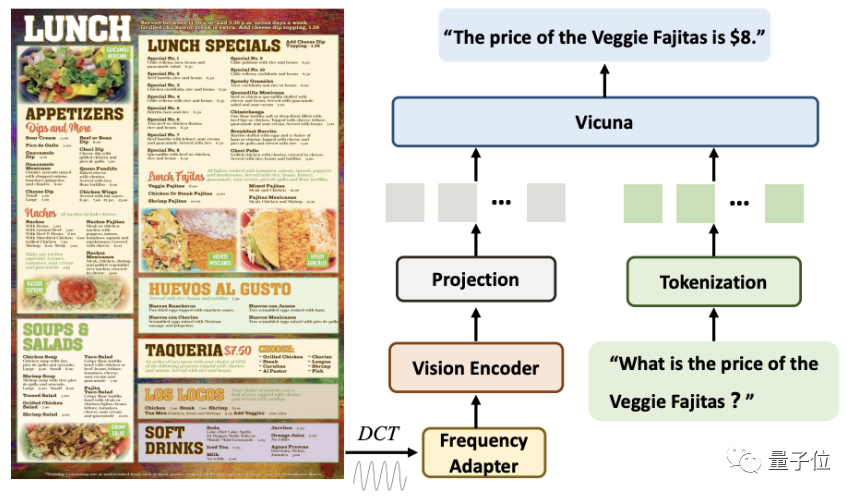
Angka berikut membandingkan prestasi DocPedia bagi imej kertas dan yang sama arahan pada input yang berbeza Jawapan pada skala. Ia boleh dilihat bahawa DocPedia menjawab dengan betul jika dan hanya jika resolusi ditingkatkan kepada 2560 × 2560.

Gambar di bawah membandingkan respons model DocPedia kepada imej teks adegan yang sama dan arahan yang sama di bawah strategi penalaan halus yang berbeza.
Dapat dilihat daripada contoh ini bahawa model yang telah diperhalusi melalui pemahaman-persepsi boleh melakukan pengecaman teks dan soal jawab semantik dengan tepat

Sila klik pautan berikut untuk melihat kertas kerja: https: //arxiv.org/abs/ 2311.11810
Atas ialah kandungan terperinci Menerobos had resolusi: Byte dan Universiti Sains dan Teknologi China mendedahkan model dokumen berbilang modal yang besar. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
 Bagaimana untuk mengikat data dalam senarai lungsur
Bagaimana untuk mengikat data dalam senarai lungsur
 Bagaimana untuk memecahkan penyulitan fail zip
Bagaimana untuk memecahkan penyulitan fail zip
 Mengapa pencetak tidak mencetak?
Mengapa pencetak tidak mencetak?
 Apakah sistem pengendalian mudah alih?
Apakah sistem pengendalian mudah alih?
 Perisian pengoptimuman kata kunci Baidu
Perisian pengoptimuman kata kunci Baidu
 Apakah kelekitan pengguna
Apakah kelekitan pengguna
 bagaimana untuk menyembunyikan alamat ip
bagaimana untuk menyembunyikan alamat ip
 Platform dagangan mata wang digital rasmi
Platform dagangan mata wang digital rasmi








![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



