


Untuk menangani masalah pengekstrakan maklumat visual yang tidak mencukupi dalam model bahasa besar berbilang modal, penyelidik dari Institut Teknologi Harbin (Shenzhen) mencadangkan model bahasa besar berbilang mod yang dipertingkatkan dwi-lapisan pengetahuan-JiuTian-LION.

Kandungan yang perlu ditulis semula ialah: Pautan kertas: https://arxiv.org/abs/2311.11860
GitHub: https://github.com/iTimmyan/i
Laman Utama projek: https://rshaojimmy.github.io/Projects/JiuTian-LION
Berbanding dengan kerja sedia ada, JiuTian menganalisis konflik dalaman antara tugas pemahaman peringkat imej dan tugas kedudukan peringkat wilayah buat kali pertama , dan mencadangkan strategi penalaan halus arahan bersegmen dan penyesuai hibrid untuk mencapai peningkatan bersama bagi kedua-dua tugas.
Dengan menyuntik persepsi spatial yang terperinci dan pengetahuan visual semantik peringkat tinggi, Jiutian telah mencapai peningkatan prestasi yang ketara pada 17 tugasan bahasa visual termasuk penerangan imej, masalah visual dan penyetempatan visual (seperti sehingga 5 pada Penaakulan Ruang Visual ) % peningkatan prestasi), mencapai tahap terkemuka antarabangsa dalam 13 tugasan penilaian Perbandingan prestasi ditunjukkan dalam Rajah 1.
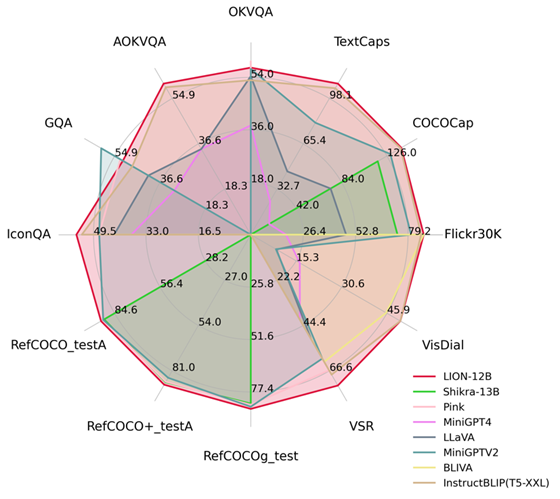
Rajah 1: Berbanding dengan MLLM lain, Jiutian telah mencapai prestasi optimum pada kebanyakan tugas.
JiuTian-LIONDengan memberikan keupayaan persepsi pelbagai mod model bahasa besar (LLM), beberapa kerja telah mula menjana model bahasa besar berbilang modal (MLLM) dan telah membuat kemajuan cemerlang dalam banyak tugas bahasa visual . Walau bagaimanapun, MLLM sedia ada terutamanya menggunakan pengekod visual yang telah dilatih pada pasangan teks imej, seperti CLIP-ViT
Tugas utama pengekod visual ini adalah untuk mempelajari penjajaran modal teks imej berbutir kasar pada peringkat imej, tetapi mereka tidak mempunyai persepsi visual yang komprehensif dan keupayaan pengekstrakan maklumat, tidak dapat melaksanakan pemahaman visual yang terperinci
Sebahagian besarnya, masalah pengekstrakan maklumat visual yang tidak mencukupi dan pemahaman yang tidak mencukupi ini akan membawa kepada kecenderungan kedudukan visual, penaakulan ruang yang tidak mencukupi dan tidak mencukupi. pemahaman tentang MLLM. Terdapat banyak kecacatan seperti ilusi objek, seperti yang ditunjukkan dalam Rajah 2
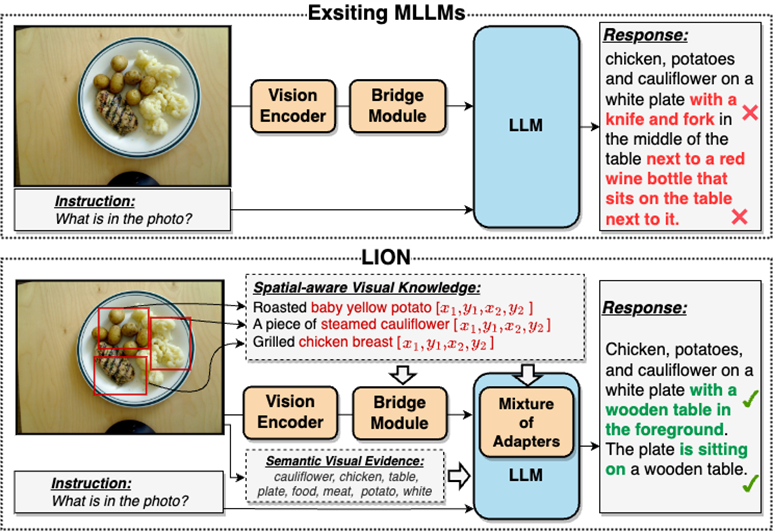
Sila rujuk Rajah 2: JiuTian-LION ialah model bahasa besar berbilang mod yang dipertingkatkan dengan pengetahuan visual dua lapisan
Berbanding dengan model bahasa besar berbilang mod (MLLM) sedia ada, Jiutian secara berkesan meningkatkan keupayaan pemahaman visual MLLM dengan menyuntik pengetahuan visual kesedaran spatial yang halus dan bukti visual semantik peringkat tinggi, menjana respons teks yang lebih tepat dan mengurangkan Fenomena halusinasi MLLMs
Double-layer visual model bahasa besar multi-modal yang dipertingkatkan-JiuTian-LION
Untuk menyelesaikan kekurangan MLLMs, penyelidik mencadangkan dan mencari maklumat visual. kaedah MLLM yang dipertingkatkan pengetahuan visual dwi-lapisan dicadangkan, dipanggil JiuTian-LION. Rangka kerja kaedah khusus ditunjukkan dalam Rajah 3
Kaedah ini terutamanya meningkatkan MLLM daripada dua aspek, penyepaduan progresif pengetahuan Visual sedar Spatial berbutir halus (Penggabungan Progresif pengetahuan Visual sedar Ruang Berbutir halus) dan tahap tinggi perisian di bawah gesaan lembut Gesaan Lembut bagi Bukti Visual Semantik Tahap Tinggi.
Secara khusus, penyelidik mencadangkan strategi penalaan halus arahan tersegmen untuk menyelesaikan konflik dalaman antara tugas pemahaman peringkat imej dan tugas penyetempatan peringkat wilayah. Mereka secara beransur-ansur menyuntik pengetahuan kesedaran spatial yang terperinci ke dalam MLLM. Pada masa yang sama, mereka menambah label imej sebagai bukti visual semantik peringkat tinggi pada MLLM, dan menggunakan kaedah gesaan lembut untuk mengurangkan kesan negatif yang mungkin dibawa oleh label yang salah Gambar rajah rangka kerja model JiuTian-LION adalah seperti berikut:
Kerja ini menggunakan strategi latihan bersegmen untuk mempelajari terlebih dahulu pemahaman peringkat imej dan tugasan kedudukan peringkat wilayah berdasarkan cawangan Q-Former dan Vision Aggregator-MLP, dan kemudian menggunakan penyesuai hibrid dengan mekanisme penghalaan untuk menggabungkan tugas yang berbeza secara dinamik dalam peringkat latihan akhir Prestasi model peningkatan pengetahuan bercabang pada dua tugas.
Kerja ini juga mengekstrak label imej sebagai bukti visual semantik peringkat tinggi melalui RAM, dan kemudian mencadangkan kaedah gesaan lembut untuk meningkatkan kesan suntikan semantik peringkat tinggi
Secara progresif menggabungkan kesedaran spatial berbutir halus pengetahuan
Apabila melaksanakan latihan campuran satu peringkat secara langsung mengenai tugas pemahaman peringkat imej (termasuk penerangan imej dan menjawab soalan visual) dan tugasan penyetempatan peringkat wilayah (termasuk pemahaman ekspresi terarah, penjanaan ekspresi terarah, dll.), MLLM akan menghadapi konflik dalaman antara dua tugasan Akibatnya, prestasi keseluruhan yang lebih baik tidak dapat dicapai pada semua tugas.
Penyelidik percaya bahawa konflik dalaman ini disebabkan terutamanya oleh dua isu. Masalah pertama ialah kekurangan pra-latihan penjajaran modal peringkat wilayah Pada masa ini, kebanyakan MLLM dengan keupayaan kedudukan peringkat serantau mula-mula menggunakan sejumlah besar data yang berkaitan untuk pra-latihan penjajaran modal berdasarkan sumber latihan yang terhad penyesuaian ciri visual kepada tugasan peringkat rantau.
Isu lain ialah perbezaan dalam corak input-output antara tugas pemahaman peringkat imej dan tugasan penyetempatan peringkat wilayah, yang kedua memerlukan model untuk memahami ayat pendek khusus tentang koordinat objek (dalam bentuk 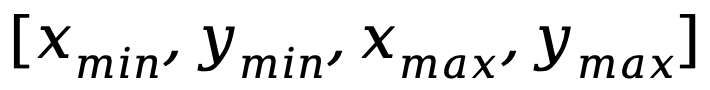 ) . Untuk menyelesaikan masalah di atas, penyelidik mencadangkan strategi penalaan halus arahan tersegmen dan penyesuai hibrid dengan mekanisme penghalaan.
) . Untuk menyelesaikan masalah di atas, penyelidik mencadangkan strategi penalaan halus arahan tersegmen dan penyesuai hibrid dengan mekanisme penghalaan.
Seperti yang ditunjukkan dalam Rajah 4, penyelidik membahagikan proses penalaan halus arahan satu peringkat kepada tiga peringkat:
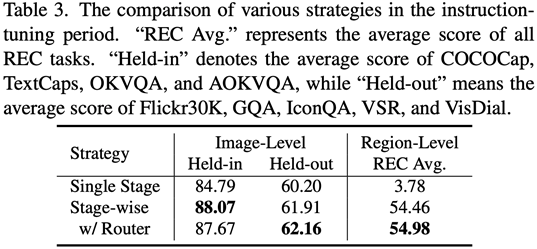
Gunakan penyesuai ViT, Q-Former dan tahap imej untuk mempelajari tugas pemahaman tahap imej bagi pengetahuan visual global; gunakan Vision Aggregator, MLP dan penyesuai peringkat serantau mempelajari tugas penentududukan peringkat serantau dengan pengetahuan visual yang sedar ruang berbutir halus dengan mekanisme penghalaan dicadangkan untuk menyepadukan secara dinamik pengetahuan visual tentang butiran yang berbeza yang dipelajari dalam berbeza; cawangan. Jadual 3 menunjukkan kelebihan prestasi strategi penalaan halus arahan tersegmen berbanding latihan satu peringkat
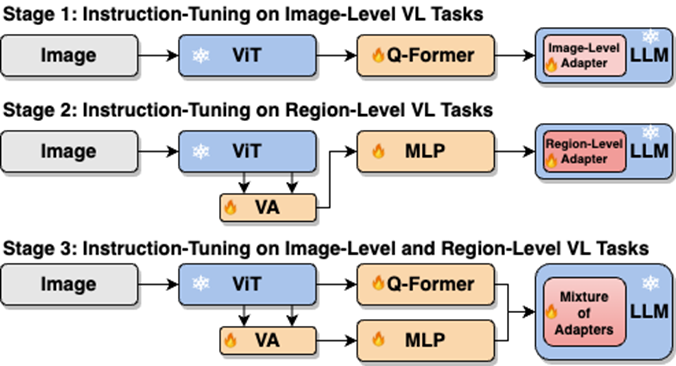
Rajah 4: Strategi penalaan halus arahan tersegmen
menggesa Bukti visual semantik peringkat tinggi perlu ditulis semula
Secara khusus, pertama Ekstrak tag imej melalui RAM, dan kemudian gunakan templat arahan khusus "Menurut
Digabungkan dengan frasa khusus "guna atau sebahagiannya" dalam templat, vektor pembayang lembut boleh membimbing model untuk mengurangkan potensi kesan negatif label yang salah.
Hasil eksperimen
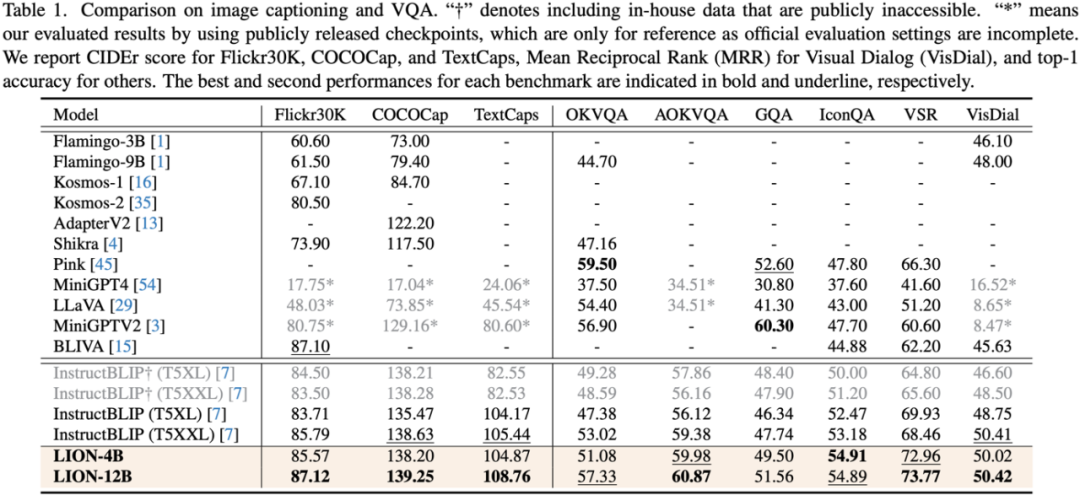 Para penyelidik menjalankan penilaian ke atas 17 set penanda aras tugas termasuk kapsyen imej, jawapan soalan visual (VQA), dan pemahaman ekspresi pengajaran (REC).
Para penyelidik menjalankan penilaian ke atas 17 set penanda aras tugas termasuk kapsyen imej, jawapan soalan visual (VQA), dan pemahaman ekspresi pengajaran (REC).
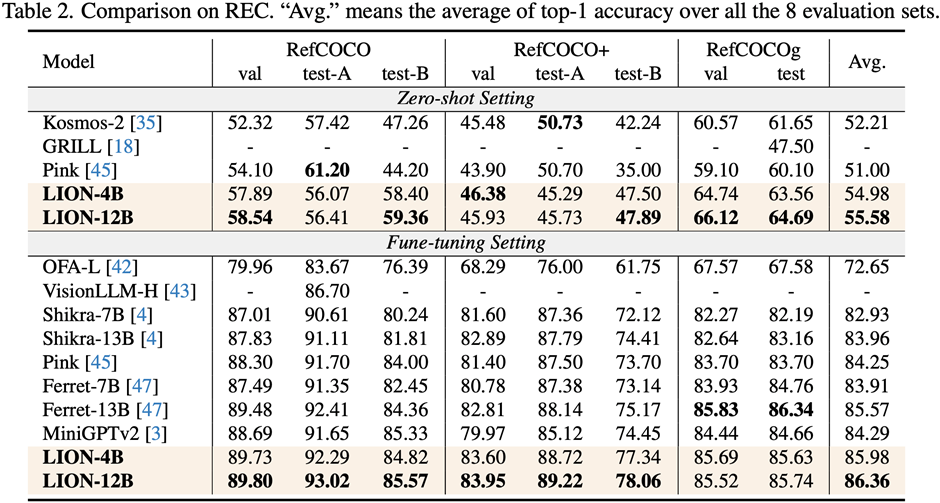
Seperti yang dapat dilihat daripada Rajah 5, terdapat perbezaan dalam keupayaan Jiutian dan MLLM lain dalam tugasan berbilang bahasa visual yang berbeza, menunjukkan bahawa Jiutian berprestasi lebih baik dalam pemahaman visual yang halus dan keupayaan penaakulan spatial visual, dan mampu untuk mengeluarkan output dengan respons teks Kurang halusinasi

Kandungan yang ditulis semula ialah: Angka kelima menunjukkan analisis kualitatif perbezaan keupayaan Model Besar Sembilan Hari, InstructBLIP dan Shikra
analisis sampel, Ia menunjukkan bahawa model Jiutian mempunyai keupayaan pemahaman dan pengecaman yang sangat baik dalam kedua-dua tugas bahasa visual peringkat imej dan peringkat wilayah.

Gambar keenam: Melalui analisis lebih banyak contoh, keupayaan model besar Jiutian ditunjukkan dari perspektif imej dan pemahaman visual peringkat serantau
Ini kerja mencadangkan Model bahasa besar berbilang modal baharu - Jiutian: model bahasa besar berbilang modal yang dipertingkatkan dengan pengetahuan visual dua lapisan.
(2) Kerja ini dinilai pada 17 set penanda aras tugas bahasa visual termasuk penerangan imej, jawapan soalan visual dan pemahaman ekspresi instruksional, antaranya 13 set penilaian mencapai prestasi terbaik semasa.
(3) Kerja ini mencadangkan strategi penalaan halus arahan tersegmen untuk menyelesaikan konflik dalaman antara pemahaman peringkat imej dan tugasan penyetempatan peringkat wilayah, dan mencapai peningkatan bersama antara kedua-dua tugas
(4) Ini kerja berjaya menyepadukan pemahaman peringkat imej dan tugasan kedudukan peringkat serantau untuk memahami secara menyeluruh adegan visual pada pelbagai peringkat Pada masa hadapan, keupayaan pemahaman visual yang komprehensif ini boleh digunakan untuk menjelmakan adegan pintar untuk membantu robot melakukan dengan lebih baik dan lebih pintar memahami persekitaran semasa untuk membuat keputusan yang berkesan.
🎜Atas ialah kandungan terperinci Selesaikan 13 tugas bahasa visual! Institut Teknologi Harbin mengeluarkan model besar berbilang modal 'Jiutian', dengan prestasi meningkat sebanyak 5%. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
 Bagaimana untuk menerangi Douyin kawan rapat
Bagaimana untuk menerangi Douyin kawan rapat
 Apakah yang perlu saya lakukan jika komputer saya dimulakan dan skrin menunjukkan skrin hitam tanpa isyarat?
Apakah yang perlu saya lakukan jika komputer saya dimulakan dan skrin menunjukkan skrin hitam tanpa isyarat?
 Tembok api Kaspersky
Tembok api Kaspersky
 ralat aplikasi plugin.exe
ralat aplikasi plugin.exe
 nvidia geforce 940mx
nvidia geforce 940mx
 Adakah anda tahu jika anda membatalkan orang lain sejurus selepas mengikuti mereka di Douyin?
Adakah anda tahu jika anda membatalkan orang lain sejurus selepas mengikuti mereka di Douyin?
 Bagaimana untuk mengira bayaran pengendalian bayaran balik keretapi 12306
Bagaimana untuk mengira bayaran pengendalian bayaran balik keretapi 12306
 Sepuluh pertukaran mata wang digital teratas
Sepuluh pertukaran mata wang digital teratas








![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



