


Ke arah model besar, gergasi teknologi melatih model yang lebih besar, manakala ahli akademik memikirkan cara untuk mengoptimumkannya. Baru-baru ini, kaedah mengoptimumkan kuasa pengkomputeran telah meningkat ke tahap yang baru.
Model bahasa berskala besar (LLM) telah merevolusikan bidang pemprosesan bahasa semula jadi (NLP), menunjukkan keupayaan luar biasa seperti kemunculan dan epiphany. Walau bagaimanapun, jika anda ingin membina model dengan keupayaan umum tertentu, berbilion parameter diperlukan, yang sangat meningkatkan ambang untuk penyelidikan NLP. Proses penalaan model LLM biasanya memerlukan sumber GPU yang mahal, seperti peranti GPU 8×80GB, yang menyukarkan makmal dan syarikat kecil untuk mengambil bahagian dalam penyelidikan dalam bidang ini.
Baru-baru ini, orang ramai sedang mengkaji teknik penalaan halus parameter cekap (PEFT), seperti LoRA dan penalaan Awalan, yang menyediakan penyelesaian untuk penalaan LLM dengan sumber terhad. Walau bagaimanapun, kaedah ini tidak menyediakan penyelesaian praktikal untuk penalaan halus parameter penuh, yang telah diiktiraf sebagai kaedah yang lebih berkuasa daripada penalaan halus cekap parameter.
Dalam kertas kerja "Penalaan Halus Parameter Penuh untuk Model Bahasa Besar dengan Sumber Terhad" yang dikemukakan oleh pasukan Qiu Xipeng di Universiti Fudan minggu lepas, penyelidik mencadangkan pengoptimuman baharu Pengoptimuman Memori RENDAH ( LOMO).
Dengan menyepadukan LOMO dengan teknik penjimatan memori sedia ada, pendekatan baharu mengurangkan penggunaan memori kepada 10.8% berbanding pendekatan standard (Penyelesaian Kelajuan Dalam). Hasilnya, pendekatan baharu ini membolehkan penalaan halus parameter penuh model 65B pada mesin dengan 8×RTX 3090s, setiap satu dengan memori 24GB.

Pautan kertas: https://arxiv.org/abs/2306.09782
Dalam karya ini, penulis menganalisis empat aspek penggunaan memori dalam LLM: pengaktifan, keadaan pengoptimum, tensor dan parameter kecerunan, dan mengoptimumkan proses latihan dalam tiga aspek:
Teknologi baharu menjadikan penggunaan memori sama dengan penggunaan parameter ditambah pengaktifan dan tensor kecerunan maksimum. Penggunaan memori penalaan halus parameter penuh ditolak ke tahap yang melampau, yang hanya bersamaan dengan penggunaan inferens. Ini kerana jejak ingatan proses ke hadapan+belakang seharusnya tidak kurang daripada proses ke hadapan sahaja. Perlu diingat bahawa apabila menggunakan LOMO untuk menyimpan memori, kaedah baharu memastikan proses penalaan halus tidak terjejas, kerana proses kemas kini parameter masih bersamaan dengan SGD.
Kajian ini menilai memori dan prestasi pemprosesan LOMO dan menunjukkan bahawa dengan LOMO, penyelidik boleh melatih model parameter 65B pada 8 RTX 3090 GPU. Selain itu, untuk mengesahkan prestasi LOMO pada tugas hiliran, mereka menggunakan LOMO untuk menala semua parameter LLM pada koleksi set data SuperGLUE. Hasilnya menunjukkan keberkesanan LOMO untuk mengoptimumkan LLM dengan berbilion parameter.
Dalam bahagian kaedah, artikel ini memperkenalkan LOMO (OPTIMISASI INGATAN RENDAH) secara terperinci. Secara umumnya, tensor kecerunan mewakili kecerunan tensor parameter, dan saiznya adalah sama dengan parameter, yang menghasilkan overhed memori yang lebih besar. Rangka kerja pembelajaran mendalam sedia ada seperti tensor kecerunan kedai PyTorch untuk semua parameter. Pada masa ini, terdapat dua sebab untuk menyimpan tensor kecerunan: mengira keadaan pengoptimum dan menormalkan kecerunan.
Memandangkan kajian ini menggunakan SGD sebagai pengoptimum, tiada keadaan pengoptimuman yang bergantung kepada kecerunan, dan mereka mempunyai beberapa alternatif kepada penormalan kecerunan.
Mereka mencadangkan LOMO, seperti yang ditunjukkan dalam Algoritma 1, yang menggabungkan pengiraan kecerunan dan kemas kini parameter dalam satu langkah, dengan itu mengelakkan penyimpanan tensor kecerunan.
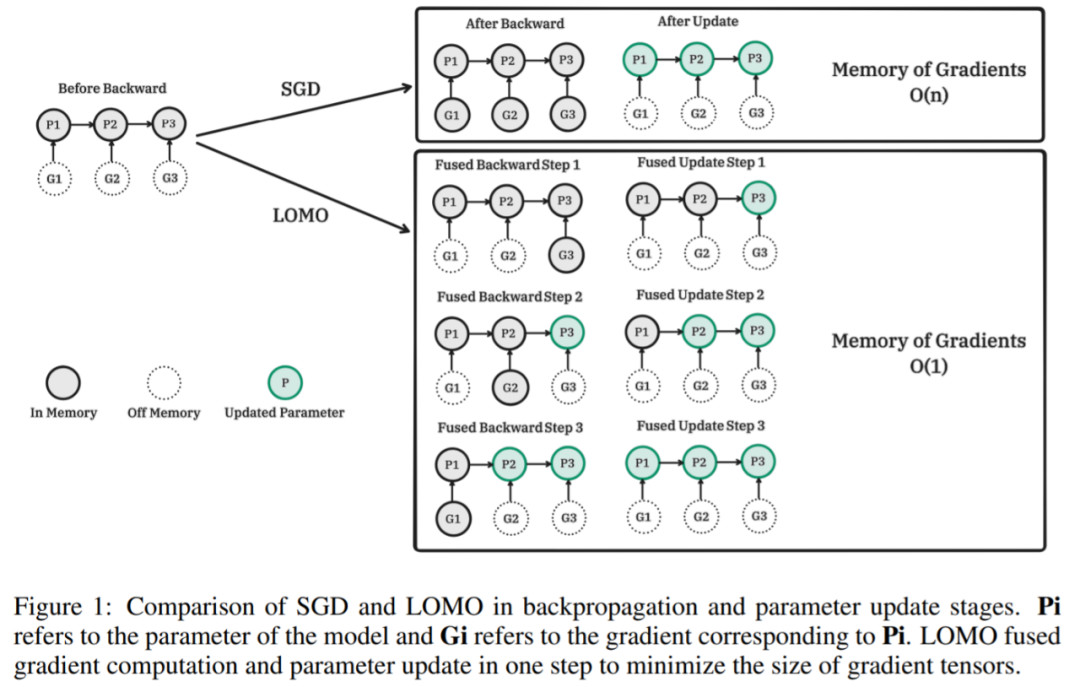
Rajah berikut menunjukkan perbandingan antara SGD dan LOMO dalam perambatan belakang dan peringkat kemas kini parameter. Pi ialah parameter model, dan Gi ialah kecerunan yang sepadan dengan Pi. LOMO menyepadukan pengiraan kecerunan dan kemas kini parameter ke dalam satu langkah untuk meminimumkan tensor kecerunan.
LOMO algoritma pseudokod sepadan:

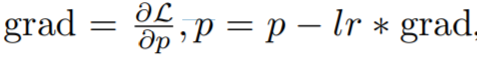
, iaitu proses dua langkah, pertama ialah mengira kecerunan dan kemudian kemas kini parameter. Versi bersatu ialah
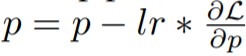
Idea utama penyelidikan ini adalah untuk mengemas kini parameter serta-merta apabila mengira kecerunan, supaya tensor kecerunan adalah tidak disimpan dalam ingatan. Langkah ini boleh dicapai dengan menyuntik fungsi cangkuk ke dalam perambatan belakang. PyTorch menyediakan API berkaitan untuk menyuntik fungsi cangkuk, tetapi adalah mustahil untuk mencapai kemas kini segera yang tepat dengan API semasa. Sebaliknya, kajian ini menyimpan kecerunan paling banyak satu parameter dalam ingatan dan mengemas kini setiap parameter satu demi satu dengan perambatan belakang. Kaedah ini mengurangkan penggunaan memori kecerunan daripada menyimpan kecerunan semua parameter kepada kecerunan hanya satu parameter.
Kebanyakan penggunaan memori LOMO adalah konsisten dengan penggunaan memori kaedah penalaan halus yang cekap parameter, menunjukkan bahawa menggabungkan LOMO dengan kaedah ini hanya menghasilkan sedikit peningkatan dalam penggunaan memori kecerunan. Ini membolehkan lebih banyak parameter ditala untuk kaedah PEFT.
Dalam bahagian eksperimen, penyelidik menilai kaedah cadangan mereka dari tiga aspek iaitu penggunaan memori, daya pemprosesan dan prestasi hiliran. Tanpa penjelasan lanjut, semua eksperimen telah dilakukan menggunakan model LLaMA 7B hingga 65B.
Penggunaan memori
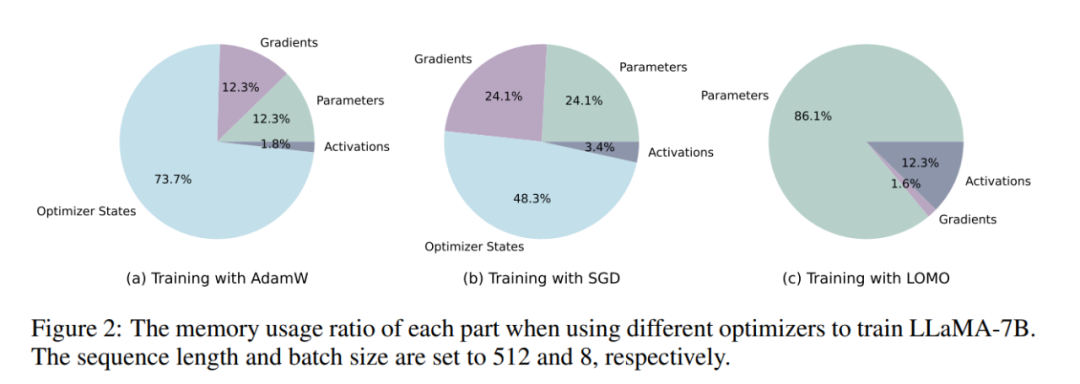
Para penyelidik mula-mula menganalisis status model dan penggunaan memori yang diaktifkan. Seperti yang ditunjukkan dalam Jadual 1, berbanding dengan pengoptimum AdamW, penggunaan pengoptimum LOMO menghasilkan pengurangan ketara dalam penggunaan memori, daripada 102.20GB kepada 14.58GB berbanding dengan SGD, apabila melatih model LLaMA-7B, penggunaan memori berkurangan daripada 51.99GB dikurangkan kepada 14.58GB. Pengurangan ketara dalam penggunaan memori adalah disebabkan terutamanya oleh pengurangan keperluan memori untuk keadaan kecerunan dan pengoptimum. Oleh itu, semasa proses latihan, memori kebanyakannya diduduki oleh parameter, yang bersamaan dengan penggunaan memori semasa inferens.
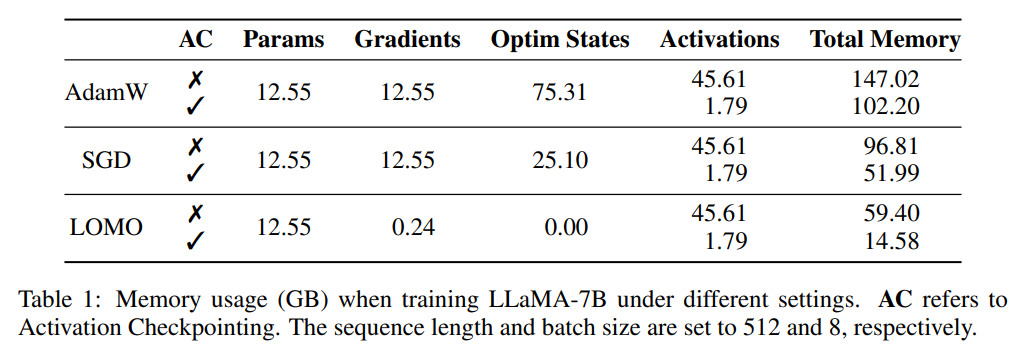
Seperti yang ditunjukkan dalam Rajah 2, jika pengoptimum AdamW digunakan untuk latihan LLaMA-7B, sebahagian besar memori ( 73.7%) diberikan kepada keadaan pengoptimum. Menggantikan pengoptimum AdamW dengan pengoptimum SGD secara berkesan mengurangkan peratusan memori yang diduduki oleh keadaan pengoptimum, sekali gus mengurangkan penggunaan memori GPU (daripada 102.20GB kepada 51.99GB). Jika LOMO digunakan, kemas kini parameter dan ke belakang digabungkan menjadi satu langkah, seterusnya menghapuskan keperluan memori untuk keadaan pengoptimum.
Throughput
Penyelidik membandingkan prestasi throughput LOMO, AdamW dan SGD. Eksperimen telah dijalankan pada pelayan yang dilengkapi dengan 8 RTX 3090 GPU.
Untuk model 7B, daya pengeluaran LOMO menunjukkan kelebihan yang ketara, melebihi AdamW dan SGD sebanyak kira-kira 11 kali. Peningkatan ketara ini boleh dikaitkan dengan keupayaan LOMO untuk melatih model 7B pada satu GPU, yang mengurangkan overhed komunikasi antara GPU. Daya pengeluaran SGD yang lebih tinggi sedikit berbanding dengan AdamW boleh dikaitkan dengan fakta bahawa SGD tidak termasuk pengiraan momentum dan varians.
Bagi model 13B, kerana had memori, ia tidak boleh dilatih dengan AdamW pada 8 RTX 3090 GPU sedia ada. Dalam kes ini, model selari diperlukan untuk LOMO, yang masih mengatasi prestasi SGD dari segi daya pemprosesan. Kelebihan ini dikaitkan dengan sifat LOMO yang cekap memori dan fakta bahawa hanya dua GPU diperlukan untuk melatih model dengan tetapan yang sama, sekali gus mengurangkan kos komunikasi dan meningkatkan daya pemprosesan. Selain itu, SGD menghadapi isu kehabisan memori (OOM) pada 8 RTX 3090 GPU semasa melatih model 30B, manakala LOMO berprestasi baik dengan hanya 4 GPU.
Akhirnya, penyelidik berjaya melatih model 65B menggunakan 8 RTX 3090 GPU, mencapai daya pemprosesan sebanyak 4.93 TGS. Dengan konfigurasi pelayan dan LOMO ini, proses latihan model pada 1000 sampel (setiap sampel mengandungi 512 token) mengambil masa lebih kurang 3.6 jam.
Prestasi Hilir
Untuk menilai keberkesanan LOMO dalam memperhalusi model bahasa besar, penyelidik menjalankan Satu siri eksperimen yang meluas. Mereka membandingkan LOMO dengan dua kaedah lain, satu ialah Zero-shot, yang tidak memerlukan penalaan halus, dan satu lagi ialah LoRA, teknik penalaan halus cekap parameter yang popular.
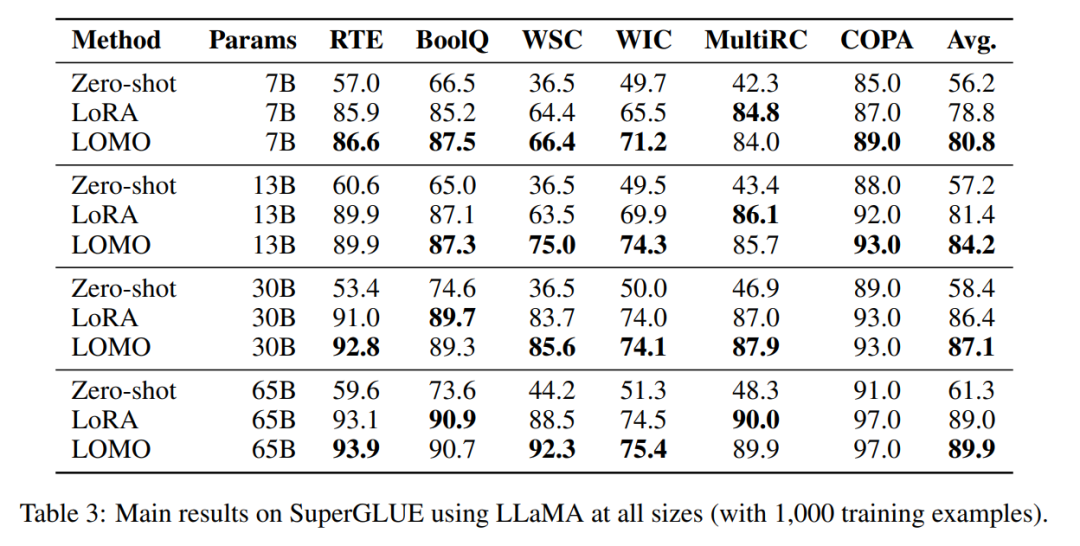
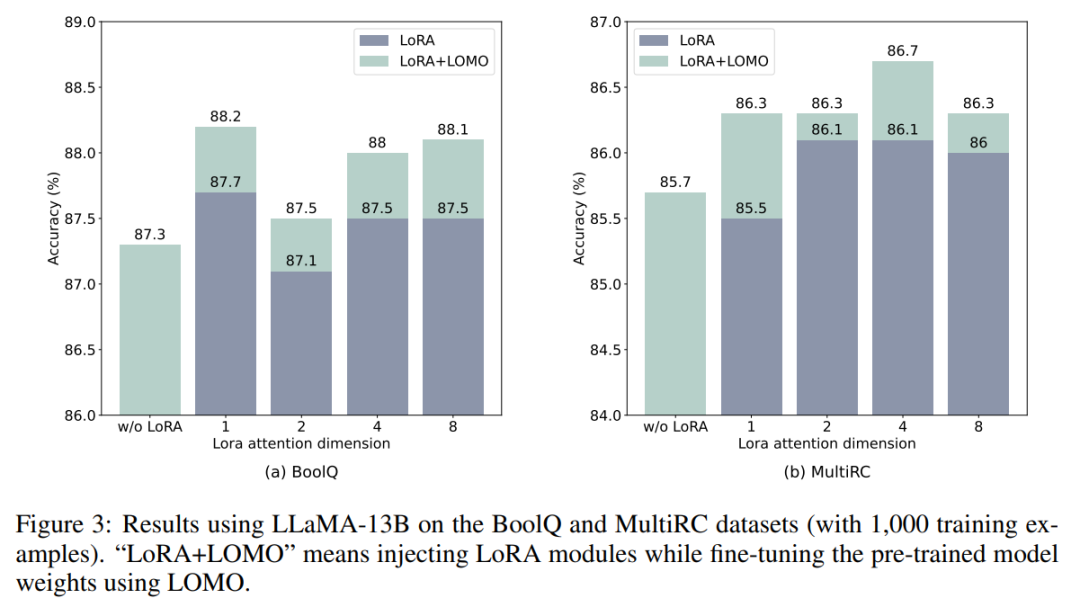
LOMO dan LoRA pada asasnya bebas antara satu sama lain. Untuk mengesahkan kenyataan ini, penyelidik menjalankan eksperimen pada set data BoolQ dan MultiRC menggunakan LLaMA-13B. Keputusan ditunjukkan dalam Rajah 3.
Mereka mendapati bahawa LOMO terus meningkatkan prestasi LoRA, tidak kira berapa tinggi keputusan yang dicapai LoRA. Ini menunjukkan bahawa kaedah penalaan halus berbeza yang digunakan oleh LOMO dan LoRA adalah saling melengkapi. Khususnya, LOMO memfokuskan pada memperhalusi berat model pra-latihan, manakala LoRA melaraskan modul lain. Oleh itu, LOMO tidak menjejaskan prestasi LoRA sebaliknya, ia memudahkan penalaan model yang lebih baik untuk tugas hiliran.
Lihat kertas asal untuk butiran lanjut.
Atas ialah kandungan terperinci 65 bilion parameter, 8 GPU boleh memperhalusi semua parameter: Pasukan Qiu Xipeng telah menurunkan ambang untuk model besar. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
 Apakah itu mata wang digital
Apakah itu mata wang digital
 Bagaimana untuk membuka fail ESP
Bagaimana untuk membuka fail ESP
 Bagaimana untuk mematikan perlindungan masa nyata dalam Pusat Keselamatan Windows
Bagaimana untuk mematikan perlindungan masa nyata dalam Pusat Keselamatan Windows
 Apakah ciri baharu Hongmeng OS 3.0?
Apakah ciri baharu Hongmeng OS 3.0?
 Bagaimana untuk membuka kunci telefon oppo jika saya terlupa kata laluan
Bagaimana untuk membuka kunci telefon oppo jika saya terlupa kata laluan
 Bagaimana untuk menyelesaikan masalah yang localhost tidak boleh dibuka
Bagaimana untuk menyelesaikan masalah yang localhost tidak boleh dibuka
 MySQL mencipta prosedur tersimpan
MySQL mencipta prosedur tersimpan
 Bagaimana untuk membeli dan menjual Bitcoin? Tutorial Dagangan Bitcoin
Bagaimana untuk membeli dan menjual Bitcoin? Tutorial Dagangan Bitcoin








![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



