Artikel ini akan diperkenalkan di sini Dalam prosesnya, kami telah mengumpul dan meneroka data dan algoritma.
Kualiti tinggi (prestasi kos tinggi) yang sesuai untuk pengeluaran industri ) Enjin ASR, yang sepatutnya mempunyai ciri-ciri berikut:
| Kebolehskalaan tinggi |
Tugas pengecaman pertuturan adalah untuk mengenali sepenuhnya daripada sekeping ucapan Kandungan teks (ucapan ke teks).
Sistem ASR yang memenuhi keperluan pengeluaran perindustrian moden bergantung pada sejumlah besar dan pelbagai data latihan "Pelbagai" di sini merujuk kepada data tidak homogen seperti persekitaran sekeliling pembesar suara, konteks adegan (medan) dan loghat pembesar suara.
Untuk senario perniagaan stesen B, kami perlu menyelesaikan masalah permulaan dingin data latihan suara Kami akan menghadapi cabaran berikut:
- Permulaan sejuk: Terdapat. hanya sejumlah kecil data pada permulaan data sumber terbuka, data yang dibeli dan senario perniagaan kurang dipadankan.
- Pelbagai senario perniagaan: Senario perniagaan audio dan video Stesen B meliputi berpuluh-puluh medan, yang boleh dianggap sebagai medan umum dan mempunyai keperluan tinggi untuk "kepelbagaian" data.
- Campuran Cina dan Inggeris: Stesen B mempunyai lebih ramai pengguna muda, dan terdapat lebih banyak video pengetahuan am yang dicampur dalam bahasa Cina dan Inggeris.
Untuk masalah di atas, kami telah menggunakan penyelesaian data berikut:
Penapisan data perniagaan
Bilibili mempunyai sebilangan kecil sari kata (sari kata cc) yang diserahkan oleh pemilik atau pengguna UP, tetapi terdapat juga beberapa masalah:
- Cap masa tidak tepat dan cap masa mula dan tamat daripada ayat selalunya antara Antara perkataan pertama dan terakhir atau selepas beberapa perkataan
- Tiada koresponden yang lengkap antara ucapan dan teks, lebih banyak perkataan, kurang perkataan, ulasan atau terjemahan, dan sari kata mungkin dihasilkan berdasarkan makna;
- Penukaran digital, Sebagai contoh, sari kata adalah 2002 (sebutan sebenar ialah 2002, 2002, dll.); pada data sumber terbuka, data produk siap yang dibeli dan sejumlah kecil data beranotasi Model asas menggunakan teks sari kata yang diserahkan untuk melatih model sub-bahasa, yang digunakan untuk penjajaran masa ayat dan penapisan sari kata; . anotasi manual data, sejumlah besar tanpa pengawasan (wav2vec, HuBERT, data2vec, dll.) [1][2] dan separa diselia telah muncul dalam industri Kaedah latihan.
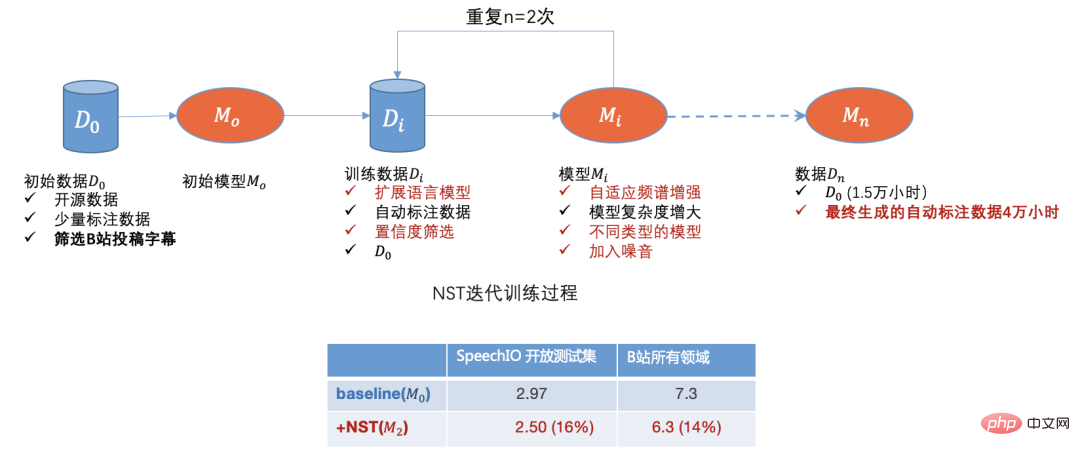
Terdapat sejumlah besar data perniagaan tidak berlabel di tapak B. Kami juga memperoleh sejumlah besar data video tidak berlabel daripada tapak web lain Kami menggunakan kaedah latihan separa penyeliaan yang dipanggil NST (Latihan Pelajar Noisy) [3 ] pada peringkat awal , Pada mulanya, hampir 500,000 manuskrip telah disaring mengikut medan dan pengedaran volum siaran, dan akhirnya menghasilkan kira-kira 40,000 jam data anotasi automatik Selepas 15,000 jam latihan data anotasi ketepatan pengecaman meningkat kira-kira 15%.
Rajah 1
Melalui data sumber terbuka, data penyerahan stesen B, data anotasi manual dan data anotasi automatik, kami pada mulanya telah menyelesaikan masalah permulaan sejuk data . Dengan model Dengan lelaran, kami boleh menapis data domain dengan pengecaman yang lemah,
, dengan itu membentuk kitaran ke hadapan. Selepas menyelesaikan masalah data pada mulanya, kami akan menumpukan pada pengoptimuman algoritma model di bawah.
Pengoptimuman Algoritma Model
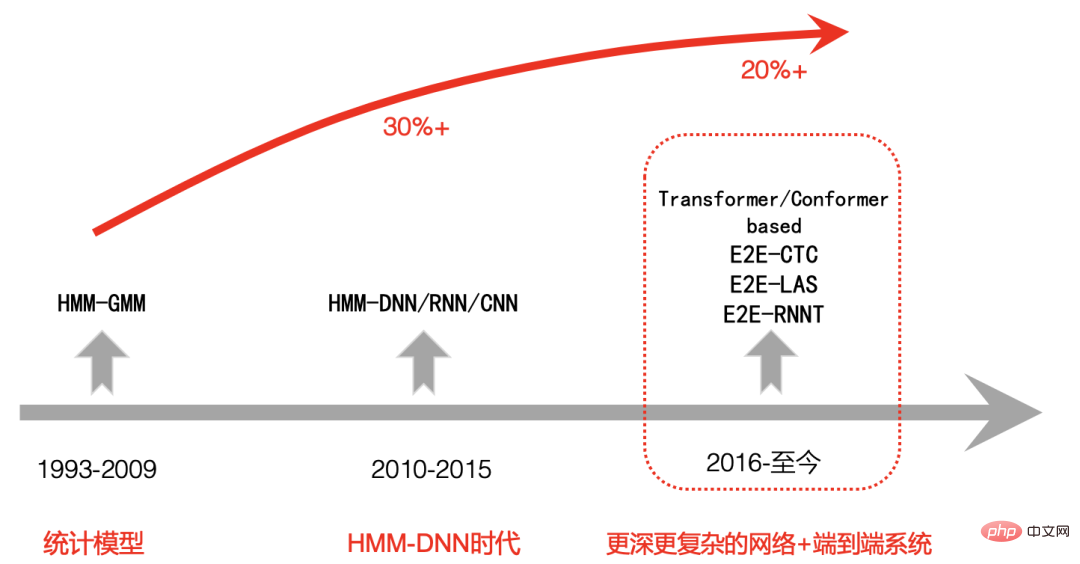
Sejarah Perkembangan Teknologi ASR
Mari kita semak secara ringkas sejarah perkembangan pengecaman pertuturan moden, yang boleh dibahagikan secara kasar kepada tiga peringkat: Peringkat pertama adalah dari 1993 hingga 2009, apabila pengecaman pertuturan telah berada di Dalam era HMM-GMM, masa lalu berdasarkan padanan templat standard mula beralih kepada model statistik Tumpuan penyelidikan juga beralih daripada perbendaharaan kata kecil dan perkataan terpencil kepada perbendaharaan kata yang besar dan pengecaman pertuturan berterusan yang tidak spesifik Sejak tahun 1990-an , pertuturan telah terus bertambah baik untuk masa yang lama Perkembangan pengecaman agak perlahan, dan kadar ralat pengecaman tidak menurun dengan ketara. Peringkat kedua ialah dari 2009 hingga sekitar 2015. Dengan peningkatan ketara kuasa pengkomputeran GPU, pembelajaran mendalam mula meningkat dalam pengecaman pertuturan pada tahun 2009, dan rangka kerja pengecaman pertuturan mula berubah menjadi HMM-DNN, dan mula Pada era DNN, ketepatan pengecaman pertuturan telah dipertingkatkan dengan ketara. Peringkat ketiga ialah selepas 2015. Disebabkan peningkatan teknologi hujung ke hujung, pembangunan CV, NLP dan bidang AI lain mempromosikan satu sama lain Pengecaman pertuturan mula menggunakan rangkaian yang lebih mendalam dan kompleks. sambil mengguna pakai Teknologi hujung ke hujung telah meningkatkan lagi prestasi pengecaman pertuturan, malah melebihi tahap manusia dalam beberapa keadaan terhad.
Gambar 2
B battle ASR penyelesaian teknikal
Pengenalan kepada konsep penting
Untuk memudahkan pemahaman, berikut adalah pengenalan ringkas kepada beberapa konsep asas yang pentingUnit pemodelan
Hibrid atau E2E
Rangka kerja hibrid peringkat kedua HMM-DNN berdasarkan rangkaian neural mempunyai peningkatan yang besar berbanding dengan ketepatan pengecaman pertuturan sistem HMM-GMM peringkat pertama Perkara ini juga telah dipersetujui sebulat suara oleh semua orang.
Walau bagaimanapun, fasa ketiga perbandingan sistem hujung ke hujung (E2E) dengan fasa kedua juga menjadi kontroversi dalam industri untuk satu tempoh masa [4]. berkaitan pengubah Dengan kemunculan model, keupayaan perwakilan model semakin kuat dan kukuh
Pada masa yang sama, dengan peningkatan ketara kuasa pengkomputeran GPU, kami boleh menambah lebih banyak latihan data, dan. penyelesaian hujung ke hujung secara beransur-ansur menunjukkan kelebihannya Semakin banyak syarikat memilih penyelesaian hujung ke hujung.
Di sini kami membandingkan kedua-dua penyelesaian ini berdasarkan senario perniagaan stesen B:
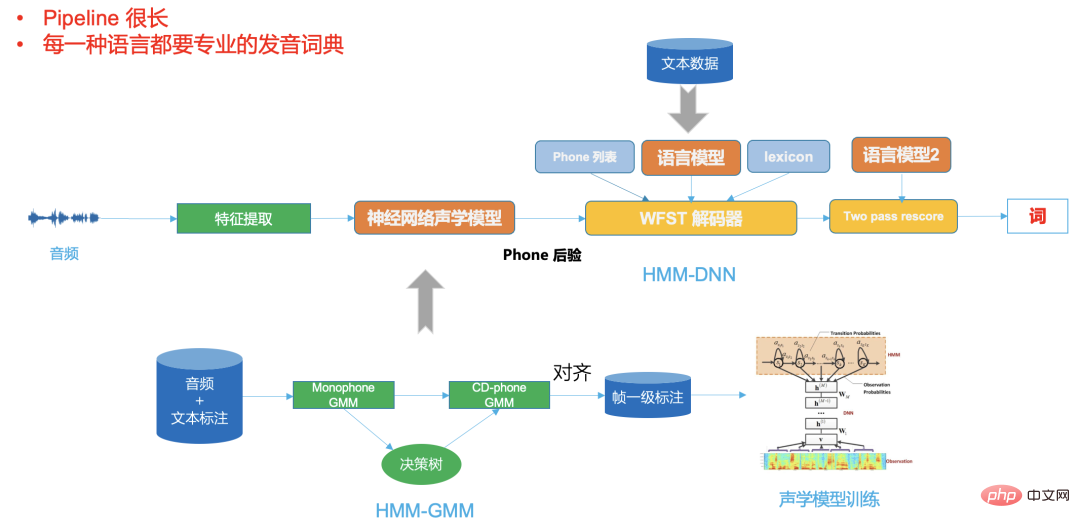
Rajah 3
Rajah 2 ialah DNN biasa - Rangka kerja HMM, anda dapat melihat bahawa saluran paipnya sangat panjang, bahasa yang berbeza memerlukan kamus sebutan profesional,
dan sistem hujung ke hujung dalam Rajah 3 meletakkan semua ini dalam model rangkaian saraf, input rangkaian saraf ialah Audio (atau ciri), output ialah hasil pengecaman yang kita inginkan.
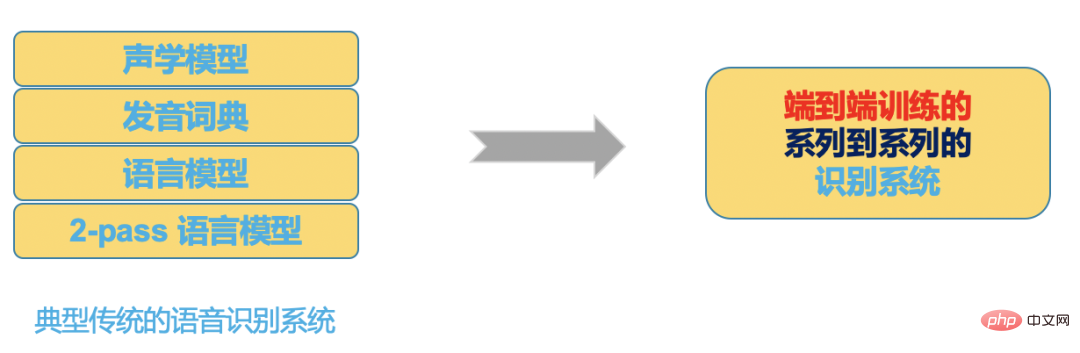
Rajah 4
Dengan perkembangan teknologi, kelebihan sistem hujung ke hujung dalam alatan pembangunan, komuniti dan prestasi semakin menjadi-jadi jelas: - Perbandingan alat dan komuniti yang mewakili
|
混合框架(hybrid) |
端到端框架(E2E) |
代表性开源工具及社区 |
HTK, Kaldi |
Espnet, Wenet, DeepSpeech, K2等 |
编程语言 |
C/C++, Shell |
Python, Shell |
可扩展性 |
从头开发 |
TensorFlow/Pytorch |
rangka kerja hujung ke hujung (E2E) |
| perwakilan Alat dan komuniti sumber terbuka |
Espnet, Wenet, DeepSpeech, K2, dll. |
| Bahasa pengaturcaraan |
|
Dibangunkan dari awal |
Perbandingan prestasi
Jadual berikut menunjukkan hasil optimum (kadar ralat perkataan CER) set data biasa berdasarkan alat perwakilan:
|
Rangka kerja hibrid (hibrid) |
Rangka Kerja Hujung-ke-Hujung (E2E) |
Mewakili Alat |
Kaldi |
Espnet |
mewakili teknologi |
tdnn+chain+ rnnlm rescoring |
conformer-las/ctc/rnnt |
Librispeech |
3.06 |
1.90 |
GigaSpeech |
14.8 >
| 10.80 |
Aishell-1 | 7.43 | 4.72WenetSpeech |
12.83 >|
Ringkasnya, dengan memilih sistem hujung ke hujung, berbanding rangka kerja hibrid tradisional, berdasarkan sumber tertentu, kami boleh membangunkan sistem ASR berkualiti tinggi dengan lebih pantas dan lebih baik.
Sudah tentu, berdasarkan rangka kerja hibrid, jika kita turut menggunakan model yang sama maju dan penyahkod yang sangat dioptimumkan, kita boleh mencapai hasil hampir hujung ke hujung, tetapi kita mungkin perlu melabur beberapa kali ganda tenaga kerja dan sumber dalam pembangunan Optimumkan sistem ini.
Pemilihan penyelesaian hujung ke hujung
Bilibili mempunyai ratusan ribu jam audio yang perlu ditranskripsi setiap hari Keperluan pemprosesan dan kelajuan sistem ASR adalah sangat tinggi, dan ketepatan penjanaan sari kata AI juga tinggi Pada masa yang sama, liputan pemandangan stesen B juga sangat luas pilih sistem ASR yang munasabah dan cekap.
Sistem ASR yang ideal
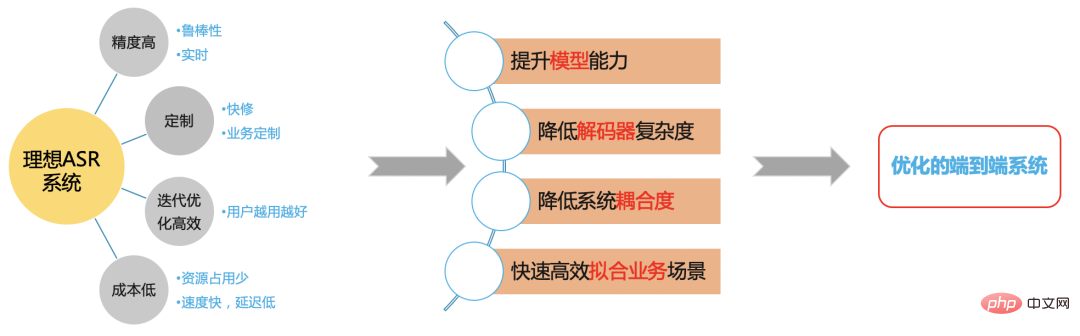
Rajah 5
Kami berharap dapat membina sistem ASR yang cekap berdasarkan rangka kerja hujung ke hujung untuk menyelesaikan masalah di stesen B Masalah senario.
Perbandingan sistem hujung ke hujung
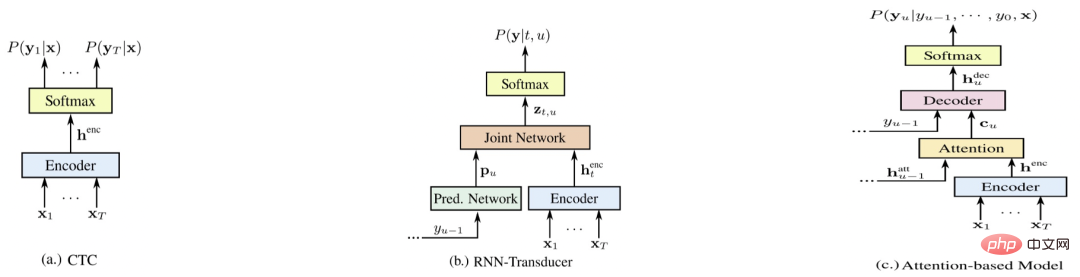
Rajah 6
Rajah 4 ialah tiga wakil sistem hujung ke hujung [5 ], masing-masing E2E-CTC, E2E-RNNT, dan E2E-AED Berikut membandingkan kelebihan dan kekurangan setiap sistem dari pelbagai aspek (skor lebih tinggi, lebih baik)
- Perbandingan sistem<.>
E2E-RNNT
E2E-CTC Dioptimumkan
|
Ketepatan pengecaman |
6 |
5 |
6 |
|
Siaran Langsung (Strim) |
3 |
5 |
5 |
|
Kos dan Kelajuan |
4 |
3 |
5 |
Pembaikan Pantas |
3 |
3 |
6 |
Lelaran yang pantas dan cekap |
6 |
4 |
5 |
- Perbandingan ketepatan bukan penstriman (kadar ralat perkataan CER)
|
2000小时 |
15000小时 |
Kaldi Chain model+LM |
13.7 |
-- |
E2E-AED |
11.8 |
6.6 |
E2E-RNNT |
12.4 |
-- |
E2E-CTC(greedy) |
13.1 |
7.1 |
优化的E2E-CTC+LM |
10.2 |
5.8 |
Di atas adalah hasil adegan kehidupan dan makanan di stesen B berdasarkan 2,000 jam dan 15,000 jam data latihan video masing-masing dan E2E-CTC menggunakan model bahasa lanjutan yang dilatih dengan korpus yang sama >E2E-AED dan E2E-RNNT tidak menggunakan model bahasa lanjutan, dan sistem hujung ke hujung adalah berdasarkan model Conformer.
Ia boleh dilihat daripada jadual kedua bahawa ketepatan sistem E2E-CTC tunggal tidak begitu lemah berbanding sistem hujung ke hujung yang lain, tetapi pada masa yang sama sistem E2E-CTC mempunyai perkara berikut kelebihan:
Oleh kerana tiada struktur autoregresif (dekoder AED dan ramalan RNNT) rangkaian saraf, sistem E2E-CTC mempunyai kelebihan semula jadi dalam penstriman, kelajuan penyahkodan dan kos penggunaan; Dari segi penyesuaian perniagaan, sistem E2E-CTC Ia juga lebih mudah untuk menyambung secara luaran pelbagai model bahasa (nnlm dan ngram), yang menjadikan kestabilan generalisasinya jauh lebih baik daripada sistem hujung ke hujung lain dalam medan terbuka umum yang tidak mempunyai data yang mencukupi untuk dilindungi sepenuhnya. -
-
Penyelesaian ASR berkualiti tinggi
Rangka kerja ASR boleh skala ketepatan tinggi
Rajah 7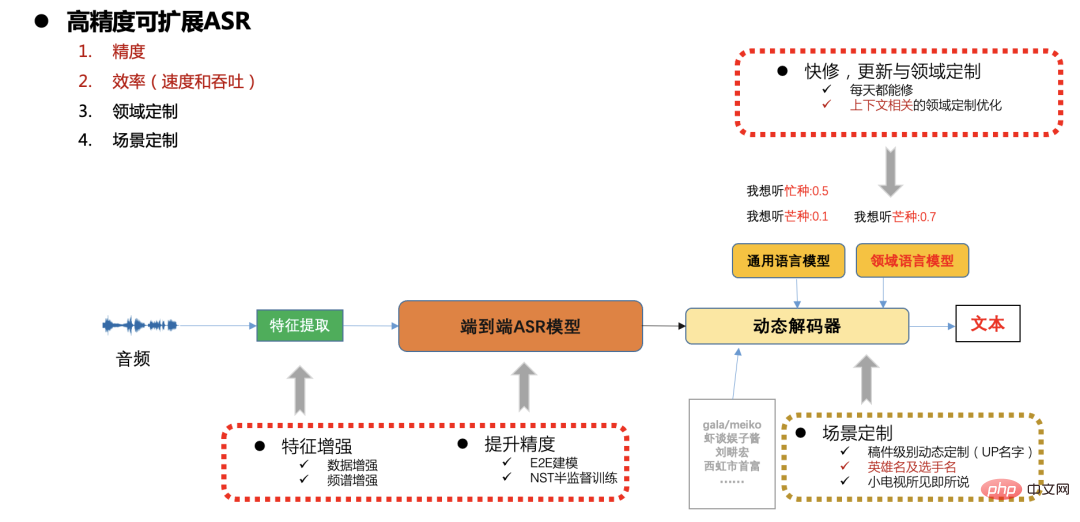 Dalam persekitaran pengeluaran stesen B, terdapat keperluan yang tinggi untuk kelajuan, ketepatan dan penggunaan sumber, dan terdapat juga kemas kini pantas dalam senario yang berbeza . dan keperluan penyesuaian (seperti perkataan entiti yang berkaitan dengan manuskrip, penyesuaian permainan popular dan acara sukan, dsb.), Di sini kami secara amnya menggunakan sistem CTC hujung ke hujung dan menyelesaikan masalah penyesuaian berskala melalui penyahkod dinamik. Berikut akan menumpukan pada ketepatan model, kelajuan dan kerja pengoptimuman skalabiliti.
Latihan diskriminasi CTC hujung ke hujung
Sistem kami menggunakan aksara Cina ditambah pemodelan BPE Inggeris Selepas latihan pelbagai tugas berdasarkan AED dan CTC, kami hanya mengekalkan Untuk bahagian CTC, kami akan melakukan latihan diskriminatif kemudian Kami menggunakan latihan diskriminatif hujung-ke-hujung [6][7]:
Kriteria latihan diskriminasi
Kriteria Diskriminasi-MMI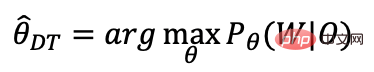

Perbezaan daripada latihan diskriminatif tradisional
1. Pendekatan tradisional- a. Mula-mula jana penjajaran dan penyahkodan yang sepadan dengan semua korpus latihan pada CPU; Semasa latihan, setiap kumpulan mini menggunakan penjajaran dan kekisi yang telah dijana masing-masing untuk mengira kecerunan pengangka dan penyebut dan mengemas kini model
2. Pendekatan kami
a terus dalam Kira kecerunan pengangka dan penyebut pada GPU dan kemas kini model; > 1. Pemodelan terus Hujung ke hujung aksara dan BPE Bahasa Inggeris, meninggalkan struktur pemindahan keadaan hmm telefon 2. Butiran pemodelan adalah besar, input latihan tidak lebih kurang dipotong, dan konteksnya adalah; keseluruhan ayat;
Jadual berikut adalah berdasarkan 15,000 jam data Selepas latihan CTC selesai, 3,000 jam dipilih untuk latihan diskriminasi menggunakan keyakinan penyahkodan keputusan latihan diskriminatif bagi mmi bebas kekisi hujung ke hujung adalah lebih baik daripada Latihan DT tradisional, selain meningkatkan ketepatan, keseluruhan proses latihan boleh diselesaikan dalam GPU aliran tensor/pytorch.
Set ujian video bilibili
garis dasar CTC
| 6.96
|
DT tradisional |
6.63 |
E2E LFMMI DT |
6.13 |
Berbanding dengan sistem hibrid, cap waktu hasil penyahkodan sistem hujung ke hujung tidak begitu tepat latihan AED tidak sejajar dengan masa Model terlatih CTC jauh lebih tepat daripada cap waktu AED, tetapi terdapat juga lonjakan masalah. Setiap kali Tempoh perkataan adalah tidak tepat;
Dekoder End-to-end End CTC
Dalam proses pembangunan teknologi pengecaman pertuturan, sama ada peringkat pertama berasaskan GMM-HMM atau peringkat kedua berdasarkan DNN -Rangka kerja hibrid HMM, penyahkod adalah komponen yang sangat penting. Prestasi penyahkod secara langsung menentukan kelajuan dan ketepatan sistem ASR terakhir Pengembangan dan penyesuaian perniagaan juga kebanyakannya bergantung pada penyelesaian penyahkod yang fleksibel dan cekap. Penyahkod tradisional, sama ada penyahkod dinamik atau penyahkod statik berdasarkan WFST, mereka bukan sahaja bergantung pada banyak pengetahuan teori, tetapi juga memerlukan reka bentuk kejuruteraan perisian profesional Membangunkan enjin penyahkod tradisional dengan prestasi unggul bukan sahaja memerlukan a banyak pembangunan tenaga manusia pada peringkat awal, dan kos penyelenggaraan seterusnya juga sangat tinggi. Penyahkod WFST tradisional perlu menyusun hmm, konteks tripon, kamus dan model bahasa ke dalam rangkaian bersatu, iaitu HCLG, dalam ruang carian rangkaian FST bersatu, yang boleh meningkatkan kelajuan penyahkodan. Dengan kematangan teknologi sistem hujung ke hujung, unit pemodelan sistem hujung ke hujung mempunyai butiran yang lebih besar, seperti perkataan Cina atau potongan perkataan Inggeris, kerana struktur pemindahan HMM tradisional, konteks tripon dan sebutan dikeluarkan kamus, yang menjadikan ruang carian penyahkodan seterusnya lebih kecil, jadi kami memilih penyahkod dinamik yang ringkas dan cekap berdasarkan carian pancaran Rajah berikut menunjukkan dua rangka kerja penyahkodan tradisional, hujung ke hujung penyahkod dinamik Penyahkod mempunyai kelebihan berikut:
menggunakan lebih sedikit sumber, biasanya 1/5 daripada sumber penyahkodan WFST
mempunyai gandingan yang rendah, memudahkan penyesuaian perniagaan dan mudah untuk menyepadukan dengan pelbagai model bahasa Penyahkodan, tidak perlu menyusun semula sumber penyahkodan untuk setiap pengubahsuaian - Kelajuan penyahkodan adalah pantas, menggunakan penyahkodan segerak perkataan [8], yang biasanya 5 kali lebih cepat daripada kelajuan penyahkodan WFST
- Model Menggunakan inferens separuh ketepatan F16
Model ditukar kepada FasterTransformer[9], berdasarkan pengubah yang sangat dioptimumkan oleh nvidia; >Menggunakan triton untuk menggunakan model inferens, mengumpulkan kelompok secara automatik, meningkatkan kecekapan penggunaan GPU sepenuhnya 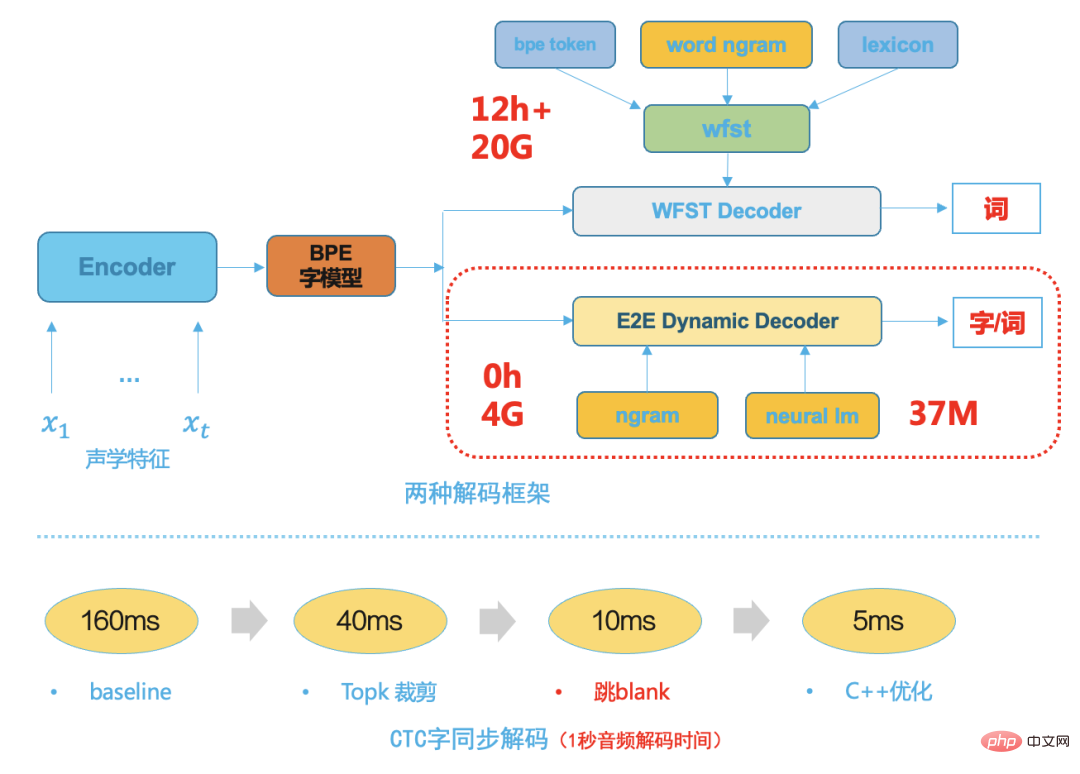
Di bawah satu GPU T4, kelajuan meningkat sebanyak 30%, daya pemprosesan meningkat sebanyak 2 kali ganda, dan 3000 jam audio boleh ditranskripsikan dalam masa 1 jam; artikel terutamanya memperkenalkan pelaksanaan teknologi pengecaman pertuturan dalam senario stesen B, cara menyelesaikan masalah data latihan dari awal, pemilihan penyelesaian teknikal keseluruhan, dan pelbagai Pengenalan dan pengoptimuman sub-modul, termasuk latihan model, pengoptimuman penyahkod dan penempatan inferens perkhidmatan. Pada masa hadapan, kami akan meningkatkan lagi pengalaman pengguna dalam senario pendaratan yang berkaitan, seperti menggunakan teknologi kata panas segera untuk mengoptimumkan ketepatan perkataan entiti yang berkaitan pada peringkat manuskrip digabungkan dengan penstriman teknologi berkaitan ASR, penyesuaian yang lebih cekap menyokong masa nyata; transkripsi sari kata untuk permainan dan acara sukan. Rujukan[1] A Baevski, H Zhou, et al wav2vec 2.0: Rangka Kerja Penyeliaan Sendiri bagi Perwakilan Pertuturan [2] A Baevski , W Hsu, et al. data2vec: Rangka Kerja Umum untuk Pembelajaran Seliaan Sendiri dalam Pertuturan, Penglihatan dan Bahasa[3] Daniel S, Y Zhang, et al Meningkatkan Latihan Pelajar Bising untuk Pengecaman Pertuturan Automatik
- [4] C Lüscher, E Beck, et al RWTH ASR Systems untuk LibriSpeech: Hibrid vs Perhatian -- tanpa Pembesaran Data
- [5] R Prabhavalkar, K Rao, et al , Perbandingan Model Jujukan-ke-Jujukan untuk Pengecaman Pertuturan
- [6] D Povey, V Peddinti1, et al, Rangkaian neural terlatih jujukan tulen untuk ASR berdasarkan MMI tanpa kekisi
[7] H Xiang, Z Ou, PEMODELAN AKUSTIK TENGAH PERINGKAT BERASASKAN CRF DENGAN TOPOLOGI CTC[8] Z Chen, W Deng, et al, Penyahkodan Segerak Telefon dengan Kekisi CTC [9] //m.sbmmt.com/link/2ea6241cf767c279cf1e80a790df1885
Pengarang terbitan ini: Deng Wei
Jurutera Algoritma Kanan
Ketua Arahan Pengecaman Pertuturan Bilibili
|
|
|



 Apakah kemahiran yang diperlukan untuk bekerja dalam industri PHP?
Apakah kemahiran yang diperlukan untuk bekerja dalam industri PHP?
 Bagaimana untuk membuka fail pdb
Bagaimana untuk membuka fail pdb
 Bagaimana untuk membaca data dalam fail excel dalam python
Bagaimana untuk membaca data dalam fail excel dalam python
 Perbezaan antara bahasa c dan python
Perbezaan antara bahasa c dan python
 Bagaimana untuk melihat prosedur tersimpan dalam MySQL
Bagaimana untuk melihat prosedur tersimpan dalam MySQL
 Cara menggunakan fungsi bulan
Cara menggunakan fungsi bulan
 Windows tidak dapat menyambung ke penyelesaian wifi
Windows tidak dapat menyambung ke penyelesaian wifi
 vcruntime140.dll tidak dapat ditemui dan pelaksanaan kod tidak dapat diteruskan
vcruntime140.dll tidak dapat ditemui dan pelaksanaan kod tidak dapat diteruskan








![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



