


Pengarang|. Dalam beberapa tahun kebelakangan ini, teknologi bahasa suara pintar telah berkembang dengan pesat, secara beransur-ansur mengubah cara orang bekerja dan hidup, dan telah mengemukakan keperluan yang lebih tinggi untuk teknologi suara pintar dalam bidang sosial.
Baru-baru ini, di Persidangan Teknologi Kecerdasan Buatan Global AISummit yang dihoskan oleh 51CTO, Liu Zhongliang, ketua algoritma suara Soul, memberikan ucaptama "The Road to Practicing Soul Intelligent Voice Technology" , berdasarkan Beberapa senario perniagaan Soul berkongsi beberapa pengalaman praktikal Soul dalam teknologi suara pintar.
Kandungan ucapan kini disusun seperti berikut, dengan harapan dapat memberi inspirasi kepada semua orang.
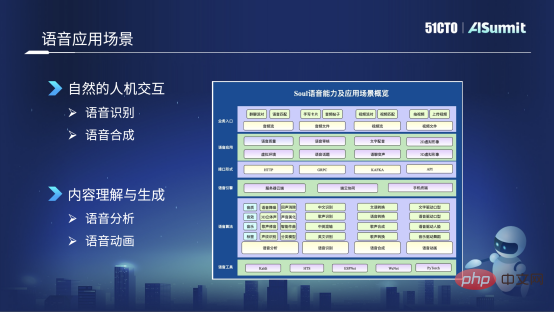
Senario aplikasi suara Soul
Soul ialah senario sosial yang mengasyikkan yang disyorkan berdasarkan graf minat Dalam senario ini, terdapat banyak pertukaran suara, jadi dalam A lot data telah terkumpul sepanjang tempoh masa yang lalu. Pada masa ini, terdapat kira-kira berjuta-juta jam dalam sehari Jika anda mengalih keluar beberapa kesunyian, bunyi bising, dsb. dalam panggilan suara, dan hanya mengira klip audio yang bermakna ini, terdapat kira-kira 6 hingga 7 bilion klip audio. Pintu masuk utama ke perniagaan suara Soul adalah seperti berikut:Voice Party
Kumpulan boleh membuat bilik di mana ramai pengguna boleh mengadakan sembang suara.
Malah, kebanyakan pengguna platform Soul tidak mahu menunjukkan muka atau mendedahkan diri mereka, jadi kami membuat 3D The Avatar yang dibangunkan sendiri imej atau penutup kepala diberikan kepada pengguna untuk membantu pengguna mengekspresikan diri mereka dengan lebih baik atau mengekspresikan diri mereka tanpa tekanan.
juga merupakan bilik, di mana ramai orang boleh bermain permainan bersama-sama.
Senario yang lebih tersendiri ialah padanan suara, atau ia sama seperti panggilan WeChat, iaitu, anda boleh bersembang satu-satu.
Berdasarkan senario ini, kami telah membina keupayaan suara yang dibangunkan sendiri, terutamanya memfokuskan pada dua arah utama: yang pertama ialah interaksi manusia-komputer semula jadi, dan yang kedua ialah pemahaman dan penjanaan kandungan . Terdapat empat aspek utama: pertama ialah pengecaman pertuturan dan sintesis pertuturan; yang kedua ialah analisis pertuturan dan animasi pertuturan muzik. Kemudian terdapat pengecaman pertuturan, seperti pengecaman bahasa Cina, pengecaman suara nyanyian, dan bacaan campuran bahasa Cina dan Inggeris. Yang ketiga berkaitan dengan sintesis pertuturan, seperti penukaran hiburan, penukaran suara, dan sintesis suara nyanyian. Keempat ialah animasi suara, yang terutamanya merangkumi beberapa bentuk mulut dipacu teks, bentuk mulut dipacu suara dan teknologi animasi suara lain.
Berdasarkan keupayaan algoritma pertuturan ini, kami mempunyai banyak borang aplikasi pertuturan, seperti pengesanan kualiti pertuturan, termasuk peningkatan, semakan pertuturan, alih suara teks, Topik suara, bunyi persekitaran maya, seperti kesan bunyi spatial 3D ini, dsb. Berikut ialah pengenalan kepada teknologi yang digunakan dalam dua senario perniagaan semakan suara dan avatar.
Semakan kandungan suaraSemakan kandungan suara adalah untuk melabelkan klip audio untuk kandungan yang berkaitan dengan politik, pornografi, penyalahgunaan, pengiklanan, dsb., atau untuk Pengenalan, melalui pengesanan dan semakan teg pelanggaran ini, untuk memastikan keselamatan rangkaian. Teknologi teras yang digunakan di sini ialah pengecaman pertuturan hujung ke hujung, yang membantu dalam menukar audio pengguna kepada teks, dan kemudian menyediakan pemeriksaan kualiti sekunder kepada pengulas hiliran.
 Sistem pengecaman pertuturan hujung ke hujung
Sistem pengecaman pertuturan hujung ke hujung
Gambar di bawah ialah rangka kerja pengecaman pertuturan hujung ke hujung yang sedang kami gunakan Pertama, ia akan menangkap a serpihan audio pengguna Untuk pengekstrakan ciri, terdapat banyak ciri yang digunakan pada masa ini Kami terutamanya menggunakan ciri Alfa-Bank, dan dalam beberapa senario kami cuba menggunakan ciri yang telah dilatih seperti Wav2Letter. Selepas mendapat ciri audio, pengesanan titik akhir akan dilakukan, iaitu untuk mengesan sama ada orang itu bercakap dan sama ada klip audio itu mempunyai suara manusia. Pada masa ini digunakan pada asasnya beberapa VD tenaga klasik dan model DNVD.
Selepas mendapat ciri ini, kami akan menghantarnya ke modul pemarkahan akustik Kami menggunakan Transformer CDC pada mulanya untuk model akustik ini, dan kini telah diulang kepada Conformer CDC. Selepas pemarkahan akustik ini, kami akan menghantar satu siri skor jujukan kepada penyahkod Penyahkod bertanggungjawab untuk menyahkod teks, dan ia akan melakukan skor kedua berdasarkan hasil pengecaman. Dalam proses ini, model yang kami gunakan pada dasarnya adalah beberapa seperti model EngelM tradisional, dan beberapa model pembelajaran mendalam Transformer yang lebih arus perdana pada masa ini untuk penskoran. Akhir sekali, kami juga akan melakukan pasca pemprosesan, seperti beberapa pengesanan tanda baca, penyelarasan teks, pelicinan ayat, dll., dan akhirnya mendapat hasil pengecaman teks yang bermakna dan tepat, seperti "Persidangan Kepintaran Buatan Global 2022" .
Dalam sistem pengecaman pertuturan hujung ke hujung, sebenarnya, hujung ke hujung yang kita bincangkan adalah terutamanya dalam bahagian pemarkahan akustik yang Kami gunakan hujung ke hujung teknologi, dan bahagian lain terutamanya tradisional dan beberapa kaedah pembelajaran mendalam klasik.
Dalam proses membina sistem di atas, kami sebenarnya menghadapi banyak masalah berikut:
Untuk menangani masalah ini, kami menggunakan tiga kaedah berikut untuk menyelesaikannya.
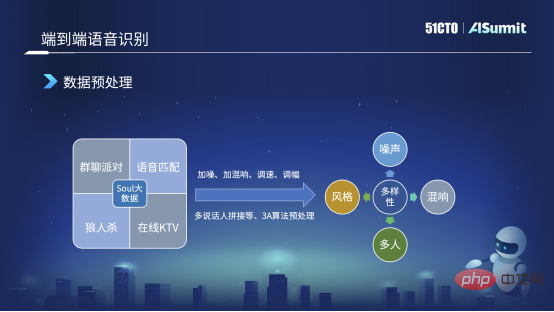
Prapemprosesan dataSoul mempunyai banyak senario dan kompleks. Contohnya, dalam parti sembang kumpulan, akan ada situasi di mana berbilang orang bertindih atau AB sentiasa bercakap. Sebagai contoh, dalam KTV dalam talian, akan ada situasi di mana orang menyanyi dan bercakap pada masa yang sama. Tetapi apabila kami melabelkan data, kerana ia agak mahal, kami akan memilih data yang agak bersih di bawah senario ini untuk pelabelan Sebagai contoh, kami mungkin melabelkan 10,000 jam data bersih. Walau bagaimanapun, kerumitan data bersih adalah berbeza daripada data dalam senario sebenar, jadi kami akan melakukan beberapa prapemprosesan data berdasarkan data bersih ini. Sebagai contoh, beberapa kaedah prapemprosesan data klasik termasuk menambah hingar, menambah gema, melaraskan kelajuan, melaraskan kelajuan lebih cepat atau lebih perlahan, melaraskan tenaga, menambah atau mengurangkan tenaga.
Selain kaedah ini, kami akan melakukan beberapa prapemprosesan data yang disasarkan atau penambahan data untuk beberapa masalah yang timbul dalam senario perniagaan kami. Sebagai contoh, saya baru sahaja menyebut bahawa mudah untuk berbilang pembesar suara bertindih dalam parti sembang kumpulan, jadi kami akan membuat audio penyambung berbilang pembesar suara, yang bermaksud kami akan memotong klip audio tiga pembesar suara ABC dan melakukan ia bersama-sama.
Oleh kerana sesetengah panggilan audio dan video akan melakukan beberapa prapemprosesan algoritma 3D asas pada keseluruhan bahagian hadapan audio, seperti pembatalan gema automatik, pengurangan hingar pintar, dsb., jadi kami turut untuk menyesuaikan diri dengan senario penggunaan dalam talian, kami juga akan melakukan beberapa prapemprosesan algoritma 3D.
Selepas prapemprosesan data dengan cara ini, kita boleh mendapatkan pelbagai data, seperti data dengan bunyi bising, beberapa bergema, berbilang orang atau malah berbilang gaya akan dikembangkan. Sebagai contoh, kami akan mengembangkan 10,000 jam kepada kira-kira 50,000 jam atau bahkan 80,000 hingga 90,000 jam Dalam kes ini, liputan dan keluasan data akan menjadi sangat tinggi.
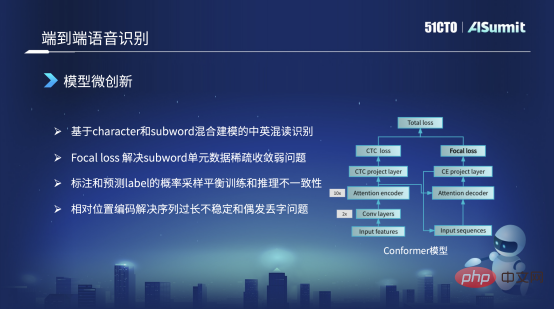
Rangka kerja utama model yang kami gunakan masih struktur Conformer. Di sebelah kiri struktur Conformer ini ialah rangka kerja CDC Pengekod klasik. Di sebelah kanan ialah Penyahkod Perhatian. Tetapi semua orang menyedari bahawa dalam Kehilangan di sebelah kanan, struktur Conformer asal ialah Kehilangan CE, dan kami menggantikannya dengan Kehilangan Fokus di sini. Sebab utama ialah kami menggunakan Focal Loss untuk menyelesaikan masalah tidak menumpu unit jarang dan latihan data jarang, atau masalah latihan yang lemah, yang boleh diselesaikan.
Sebagai contoh, dalam bacaan bercampur Cina-Inggeris, kami mempunyai sangat sedikit perkataan Inggeris dalam data latihan Dalam kes ini, unit ini tidak boleh dipelajari dengan baik. Melalui Focal Loss, kita boleh meningkatkan berat Lossnya, yang boleh mengurangkan beberapa masalah kuantiti atau masalah latihan yang lemah, dan menyelesaikan beberapa kes buruk.
Perkara kedua ialah strategi latihan kita akan berbeza Contohnya, kita juga akan menggunakan beberapa kaedah latihan campuran dalam strategi latihan Contohnya, dalam latihan awal, apabila kita melatih bahagian Decode input, Kami masih menggunakan data jujukan Label yang dilabel dengan tepat sebagai input. Tetapi apabila model latihan menumpu, pada peringkat kemudian kita akan mencuba sebahagian daripada Label yang diramalkan mengikut kebarangkalian tertentu sebagai input Penyahkod untuk melakukan beberapa helah Apakah yang diselesaikan oleh helah ini? Ia adalah fenomena bahawa ciri input model latihan dan model inferens dalam talian adalah tidak konsisten Dengan cara ini, kita boleh menyelesaikannya sebahagiannya.
Tetapi terdapat satu lagi masalah sebenarnya, dalam model Conformer asal atau model yang disediakan oleh Vnet atau ESPnet, lalai adalah maklumat kedudukan mutlak. Walau bagaimanapun, maklumat kedudukan mutlak tidak dapat menyelesaikan masalah pengenalan apabila jujukan terlalu panjang, jadi kami akan menukar maklumat kedudukan mutlak kepada pengekodan kedudukan relatif untuk menyelesaikan masalah ini. Dengan cara ini, masalah yang timbul semasa proses pengecaman, seperti pengulangan beberapa perkataan atau kehilangan kata atau perkataan sekali-sekala, juga dapat diselesaikan.
Yang pertama ialah model akustik Kami akan menukar model autoregresif kepada model ini berdasarkan CDC Pengekod Kaedah penyahkodan +WFST terlebih dahulu menyelesaikan sebahagian daripada hasil pengecaman, seperti NBest, 10best atau 20best. Berdasarkan 20best, kami akan menghantarnya ke Decorde Rescore untuk pemarkahan semula kedua Ini boleh mengelakkan kebergantungan masa dan memudahkan pengiraan atau penaakulan selari GPT.
Selain kaedah pecutan klasik, kami juga menggunakan kaedah pengkuantitian hibrid, iaitu, dalam proses penaakulan ke hadapan pembelajaran mendalam, kami menggunakan 8Bit untuk sebahagian daripada pengiraan, tetapi Di bahagian teras, seperti bahagian fungsi kewangan, kami masih menggunakan 16bit, terutamanya kerana kami akan membuat keseimbangan yang sesuai antara kelajuan dan ketepatan.
Selepas pengoptimuman ini, keseluruhan kelajuan inferens agak pantas. Tetapi semasa proses pelancaran sebenar kami, kami juga menemui beberapa masalah kecil, yang saya fikir boleh dianggap sebagai helah.
Di peringkat model bahasa, sebagai contoh, adegan kami mempunyai banyak teks sembang, tetapi terdapat juga nyanyian Kami memerlukan model yang sama untuk menyelesaikan kedua-dua pertuturan dan Selesaikan nyanyian. Dari segi model bahasa, seperti teks berbual, ia biasanya berpecah-belah dan pendek, jadi selepas eksperimen kami, kami mendapati bahawa model tiga elemen adalah lebih baik, tetapi model lima elemen tidak membawa peningkatan.
Tetapi sebagai contoh, untuk nyanyian, teksnya agak panjang, dan struktur ayat serta tatabahasanya agak tetap, jadi semasa percubaan, lima yuan adalah lebih baik daripada tiga yuan. Dalam kes ini, kami menggunakan tatabahasa hibrid untuk memodelkan model bahasa teks sembang dan teks nyanyian secara bersama. Kami menggunakan model pencampuran "tiga yuan + lima yuan", tetapi pencampuran "tiga yuan + lima yuan" ini bukanlah perbezaan dalam erti kata tradisional Kami tidak membuat perbezaan, tetapi menggunakan tatabahasa tiga yuan daripada berbual, ambil nyanyian empat yuan dan tatabahasa lima yuan dan gabungkannya secara langsung. Arpa yang diperolehi dengan cara ini pada masa ini lebih kecil dan lebih pantas dalam proses penyahkodan Lebih penting lagi, ia mengambil sedikit memori video. Kerana apabila penyahkodan pada GPU, saiz memori video ditetapkan. Oleh itu, kita perlu mengawal saiz model bahasa pada tahap tertentu untuk meningkatkan kesan pengecaman melalui model bahasa sebanyak mungkin.
Selepas beberapa pengoptimuman dan helah pada model akustik dan model bahasa, kelajuan inferens kami kini sangat pantas. Kadar masa nyata pada asasnya boleh mencapai tahap 0.1 atau 0.2.

terutamanya membantu pengguna menjana lebih banyak kandungan seperti bunyi, bentuk mulut, ekspresi, postur, dsb. daripada teknologi teras yang diperlukan untuk menyatakan tanpa tekanan atau lebih semula jadi dan bebas ialah sintesis pertuturan pelbagai modal.
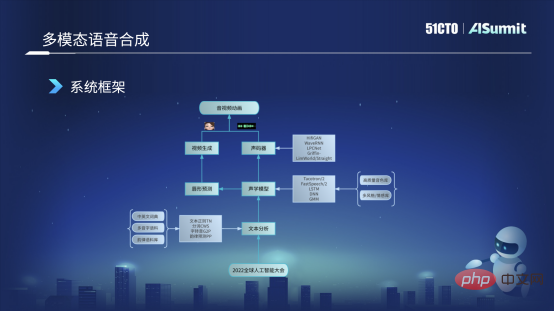
Rajah berikut ialah rangka kerja asas sistem sintesis pertuturan yang sedang digunakan. Pertama, kami akan mendapatkan teks input pengguna, seperti "Persidangan Kecerdasan Buatan Global 2022", dan kemudian kami akan menghantarnya ke modul analisis teks Modul ini terutamanya menganalisis teks dalam pelbagai aspek, seperti penyusunan teks dan Beberapa perkataan segmentasi, perkara yang paling penting ialah pemindahan diri, menukar perkataan kepada fonem, dan beberapa ramalan rima dan fungsi lain. Selepas analisis teks ini, kita boleh mendapatkan beberapa ciri linguistik ayat pengguna, dan ciri ini akan dihantar ke model akustik. Untuk model akustik, pada masa ini kami menggunakan beberapa penambahbaikan dan latihan model berdasarkan rangka kerja FastSpeech.
Model akustik memperoleh ciri akustik, seperti ciri Mel, atau maklumat seperti tempoh atau tenaga, dan arah aliran cirinya akan dibahagikan kepada dua bahagian. Kami akan menghantar sebahagian daripadanya kepada vocoder, yang digunakan terutamanya untuk menjana bentuk gelombang audio yang boleh kami dengar. Arah aliran lain dihantar ke ramalan bentuk bibir Kita boleh meramalkan pekali BS yang sepadan dengan bentuk bibir melalui modul ramalan bentuk bibir. Selepas mendapat nilai ciri BS, kami akan menghantarnya ke modul penjanaan video, yang menjadi tanggungjawab pasukan visual dan boleh menjana avatar maya, iaitu imej maya dengan bentuk mulut dan ekspresi. Pada akhirnya, kami akan menggabungkan avatar dan audio maya, dan akhirnya menghasilkan animasi audio dan video. Ini ialah rangka kerja asas dan proses asas bagi keseluruhan sintesis pertuturan pelbagai modal kami.
Isu utama dalam proses sintesis pertuturan pelbagai mod:
Kaedah pemprosesan Soul adalah selaras dengan penambahbaikan akhir- suara ke hujung Sama dalam sistem pengecaman.
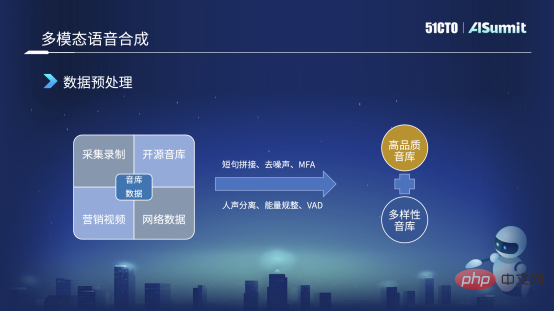
Perpustakaan bunyi kami datang daripada banyak sumber Gambar di sebelah kiri adalah yang pertama kami kumpulkan dan rakam. Kedua, sudah tentu kami sangat berterima kasih kepada syarikat data sumber terbuka, yang akan membuka sumber beberapa perpustakaan bunyi, dan kami juga akan menggunakannya untuk melakukan beberapa eksperimen. Ketiga, akan ada beberapa video pemasaran awam di peringkat syarikat pada platform kami Semasa membuat video, kami menjemput beberapa sauh berkualiti tinggi untuk membuatnya, jadi kualiti bunyi juga sangat berkualiti. Keempat, beberapa data rangkaian awam, seperti dalam proses dialog, beberapa timbres adalah berkualiti tinggi, jadi kami juga akan merangkak beberapa dan kemudian melakukan beberapa pra-anotasi, terutamanya untuk melakukan beberapa eksperimen dalaman dan pra-latihan.
Sebagai tindak balas kepada kerumitan data ini, kami melakukan beberapa prapemprosesan data, seperti penyambungan ayat pendek Seperti yang dinyatakan sebentar tadi, semasa proses pengumpulan, ayat mungkin panjang atau pendek. Kami Untuk menambah panjang pustaka bunyi, kami akan memotong ayat pendek, dan kami akan mengeluarkan beberapa senyap semasa proses Jika senyap terlalu lama, ia akan mempunyai beberapa kesan.
Yang kedua ialah denoising Contohnya, dalam data rangkaian atau video pemasaran yang kami dapat, kami akan mengeluarkan bunyi tersebut melalui beberapa kaedah peningkatan pertuturan.
Ketiga, sebenarnya, kebanyakan anotasi semasa ialah bunyi beranotasi yang ditukar kepada perkataan, tetapi sempadan fonem pada dasarnya tidak digunakan sebagai anotasi sekarang, jadi kami biasanya menggunakan jenis ini. MFA untuk memaksa kaedah Penjajaran untuk mendapatkan maklumat sempadan fonem.
Pemisahan vokal berikut agak istimewa, kerana kami mempunyai muzik latar belakang dalam video pemasaran, jadi kami akan melakukan pemisahan vokal dan memberikan muzik latar Alih keluar dan dapatkan data bunyi kering . Kami juga melakukan beberapa penyelarasan tenaga dan beberapa VAD terutamanya dalam dialog atau data rangkaian. Saya menggunakan VAD untuk mengesan suara manusia yang berkesan, dan kemudian menggunakannya untuk melakukan beberapa pra-anotasi atau pra-latihan.
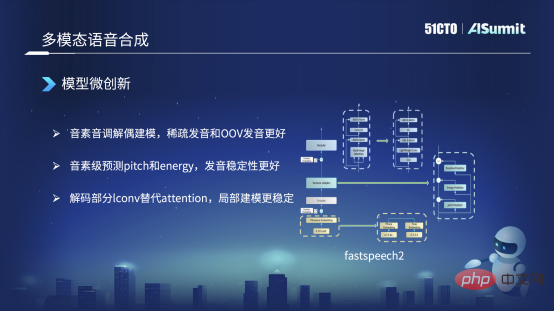
Dalam proses membuat FastSpeech, kami terutamanya membuat perubahan dalam tiga aspek. Jenis di sebelah kiri gambar di sebelah kiri ialah model asas FastSpeech urutan fonem, seperti Sama seperti gambar di sebelah kiri, urutan fonem yang membosankan seperti "hello". Tetapi kita akan membahagikannya kepada bahagian kanan, dua bahagian, iaitu bahagian kiri adalah urutan fonem, dengan hanya fonem dan tiada nada. Yang di sebelah kanan hanya mempunyai nada dan tiada fonem. Dalam kes ini, kami akan menghantarnya ke ProNet (bunyi) masing-masing dan mendapatkan dua Pembenaman. Kedua-dua Pembenaman akan dipotong bersama untuk menggantikan kaedah Pembenaman sebelumnya. Dalam kes ini, kelebihannya ialah ia boleh menyelesaikan masalah sebutan jarang, atau beberapa sebutan tidak ada dalam korpus latihan kami Masalah seperti ini pada dasarnya boleh diselesaikan.
Cara kedua yang kami ubah ialah cara asal adalah dengan terlebih dahulu meramalkan tempoh, iaitu gambar di sebelah kanan, dan kemudian berdasarkan tempoh ini kami mengembangkan set bunyi, dan kemudian ramalkan tenaga dan Pitch. Sekarang kami telah menukar susunan Kami akan meramalkan Pitch dan Tenaga berdasarkan tahap fonem, dan kemudian selepas ramalan, kami akan melanjutkannya ke tempoh peringkat bingkai. Kelebihan ini ialah sepanjang proses sebutan fonem yang lengkap, sebutannya agak stabil, yang merupakan perubahan dalam senario kami.
Yang ketiga ialah kami membuat perubahan alternatif pada bahagian Dekoder iaitu bahagian atas. Penyahkod asal menggunakan kaedah Perhatian, tetapi kami kini telah beralih kepada kaedah Iconv atau Convolution. Kelebihan ini adalah kerana walaupun Perhatian Kendiri boleh menangkap maklumat sejarah dan maklumat kontekstual yang sangat berkuasa, keupayaannya untuk memodelkan secara beransur-ansur adalah agak lemah. Jadi selepas bertukar kepada Convolution, keupayaan kami untuk mengendalikan pemodelan tempatan jenis ini akan menjadi lebih baik. Sebagai contoh, apabila sebutan, fenomena yang baru menyebut bahawa sebutan itu agak bisu atau kabur pada dasarnya boleh diselesaikan. Ini adalah beberapa perubahan besar yang kami ada pada masa ini.
Sebelah kiri ialah bentuk mulut tersintesis, dan sebelah kanan ialah suara tersintesis beberapa Pengekod dan tempoh dalam maklumat model akustik.
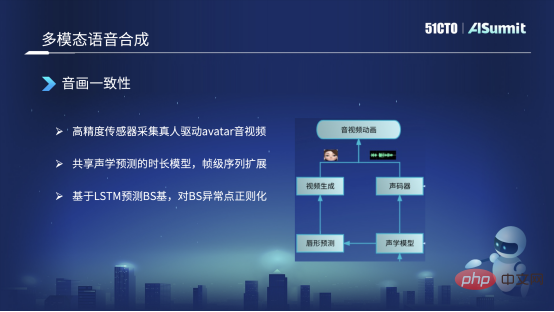
Kami terutamanya melakukan tiga tindakan. Yang pertama ialah kami sebenarnya mengumpul beberapa data berketepatan tinggi Contohnya, kami akan menemui beberapa orang sebenar untuk memakai beberapa penderia ketepatan tinggi untuk memacu imej Avatar yang telah kami ramalkan, mendapatkan audio dan video resolusi tinggi dan lakukan. beberapa anotasi. Dengan cara ini, anda akan mendapat beberapa data teks, audio dan video yang disegerakkan.
Perkara kedua, mungkin juga disebut bagaimana kita menyelesaikan masalah konsistensi audio dan video? Kerana kita mula-mula mensintesis bunyi melalui sintesis teks Selepas mendapat bunyi, kita akan membuat ramalan dari bunyi ke bentuk mulut Dalam proses ini, ia akan kelihatan tidak simetri pada tahap bingkai. Pada masa ini, kami menggunakan kaedah ini untuk berkongsi model akustik antara bentuk mulut tersintesis dan suara tersintesis, dan melakukannya selepas jujukan peringkat bingkai dikembangkan. Pada masa ini, ia boleh dijamin untuk diselaraskan pada tahap bingkai, memastikan ketekalan audio dan video.
Akhir sekali, pada masa ini, kami tidak menggunakan kaedah berasaskan urutan untuk meramal bentuk mulut atau asas BS Kami menggunakan LSTM untuk meramalkan asas BS. Selepas pekali BS yang diramalkan, tetapi ia mungkin meramalkan beberapa keabnormalan, kami juga akan melakukan beberapa pemprosesan pasca, seperti regularisasi Sebagai contoh, jika asas BS terlalu besar atau terlalu kecil, ia akan menyebabkan bentuk mulut terbuka terlalu luas atau malah berubah terlalu kecil. Kami akan menetapkan Skop tidak boleh terlalu besar dan akan dikawal dalam julat yang munasabah. Pada masa ini, pada asasnya adalah mungkin untuk memastikan konsistensi audio dan video.
Pertama ialah pengecaman berbilang modal Dalam situasi hingar tinggi, audio digabungkan dengan bentuk mulut untuk pengiktirafan pelbagai mod, meningkatkan ketepatan pengecaman.
Yang kedua ialah sintesis pertuturan berbilang modal dan penukaran pertuturan masa nyata, yang boleh mengekalkan emosi dan ciri gaya pengguna, tetapi hanya menukar timbre pengguna kepada timbre lain.
Atas ialah kandungan terperinci Jalan ke pelaksanaan praktikal teknologi suara pintar Soul. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
















![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



