


Pada peringkat ini, model pengubah visual (ViT) telah digunakan secara meluas dalam pelbagai tugas penglihatan komputer seperti pengelasan imej, pengesanan sasaran dan segmentasi, dan boleh mencapai hasil SOTA dalam perwakilan visual dan pengecaman. Memandangkan prestasi model penglihatan komputer selalunya dikaitkan secara positif dengan bilangan parameter dan masa latihan, komuniti AI telah bereksperimen dengan model ViT yang semakin berskala besar.
Tetapi harus diingat bahawa apabila model mula melebihi skala teraflops, medan tersebut telah menghadapi beberapa kesesakan utama. Melatih satu model boleh mengambil masa berbulan-bulan dan memerlukan beribu-ribu GPU, meningkatkan keperluan pemecut dan menghasilkan model ViT berskala besar yang mengecualikan ramai pengamal.
Untuk meluaskan skop penggunaan model ViT, penyelidik Meta AI telah membangunkan kaedah latihan yang lebih cekap. Adalah sangat penting untuk mengoptimumkan latihan untuk penggunaan pemecut yang optimum. Walau bagaimanapun, proses ini memakan masa dan memerlukan kepakaran yang tinggi. Untuk menyediakan percubaan yang teratur, penyelidik mesti memilih daripada pengoptimuman yang tidak terkira banyaknya: mana-mana satu daripada berjuta-juta operasi yang dilakukan semasa sesi latihan mungkin terhalang oleh ketidakcekapan.
Meta AI mendapati bahawa ia boleh meningkatkan kecekapan pengiraan dan storan dengan menggunakan satu siri pengoptimuman pada pelaksanaan ViTnya dalam PyCls, pangkalan kod klasifikasi imejnya. Untuk model ViT yang dilatih menggunakan PyCI, pendekatan Meta AI boleh meningkatkan kelajuan latihan dan daya pemprosesan setiap pemecut (TFLOPS).
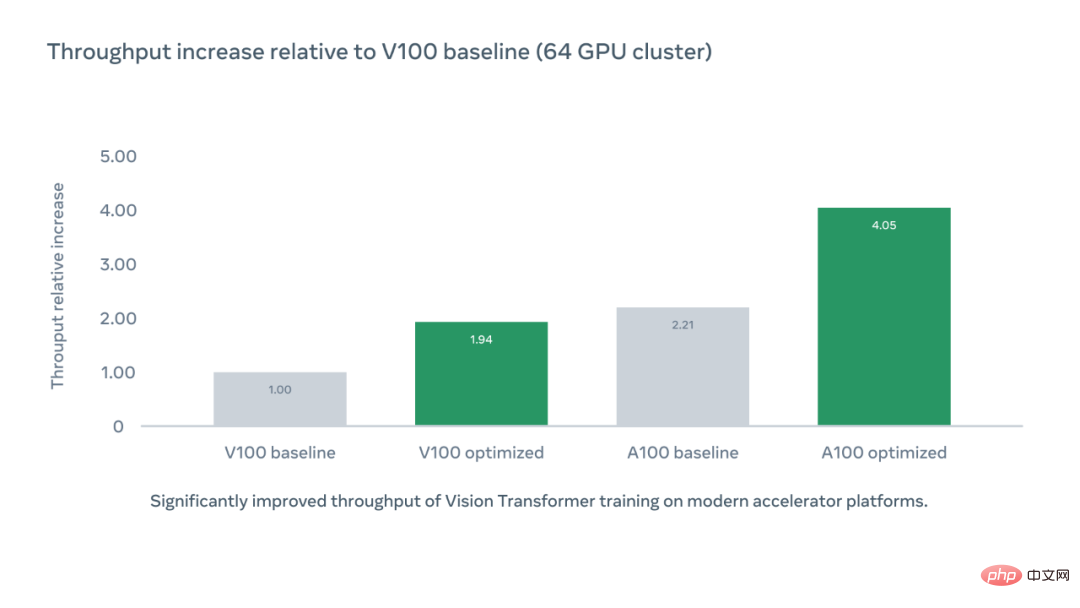
Graf di bawah menunjukkan peningkatan relatif dalam daya tahan pemecut setiap cip berbanding penanda aras V100 menggunakan asas kod PyCI yang dioptimumkan, manakala pemprosesan pemecut yang dioptimumkan A100 ialah penanda aras V100.
Meta AI mula-mula menganalisis asas kod PyCIs untuk mengesahkan potensi kecekapan latihan yang rendah sumber, akhirnya menumpukan pada pilihan format digital. Secara lalai, kebanyakan aplikasi menggunakan format titik terapung ketepatan tunggal 32-bit untuk mewakili nilai rangkaian saraf. Menukar kepada format separuh ketepatan 16-bit (FP16) boleh mengurangkan jejak memori model dan masa pelaksanaan, tetapi selalunya juga mengurangkan ketepatan.
Para penyelidik menggunakan penyelesaian kompromi, iaitu ketepatan campuran. Dengan itu, sistem melakukan pengiraan dalam format ketepatan tunggal untuk mempercepatkan latihan dan mengurangkan penggunaan memori, sambil menyimpan keputusan dalam ketepatan tunggal untuk mengekalkan ketepatan. Daripada menukar bahagian rangkaian secara manual kepada separuh ketepatan, mereka bereksperimen dengan mod latihan ketepatan campuran automatik yang berbeza, yang bertukar secara automatik antara format digital. Ketepatan campuran automatik mod yang lebih maju bergantung terutamanya pada operasi separuh ketepatan dan berat model. Tetapan seimbang yang digunakan oleh penyelidik boleh mempercepatkan latihan tanpa mengorbankan ketepatan.
Untuk menjadikan proses lebih cekap, penyelidik menggunakan sepenuhnya algoritma latihan Selari Data Sepenuhnya Sharder (FSDP) dalam perpustakaan FairScale, yang membandingkan parameter, keadaan Gradien dan pengoptimum dipecahkan. Melalui algoritma FSDP, penyelidik boleh membina model berskala lebih besar menggunakan GPU yang lebih sedikit. Selain itu, kami menggunakan pengoptimum MTA, pengelas ViT terkumpul dan susun atur tensor input detik kelompok untuk melangkau operasi transpos berlebihan.
Paksi X bagi rajah di bawah menunjukkan kemungkinan pengoptimuman, dan paksi Y menunjukkan peningkatan relatif dalam daya pemprosesan pemecut berbanding penanda aras selari data teragih (DDP) apabila berlatih dengan ViT -H/16.
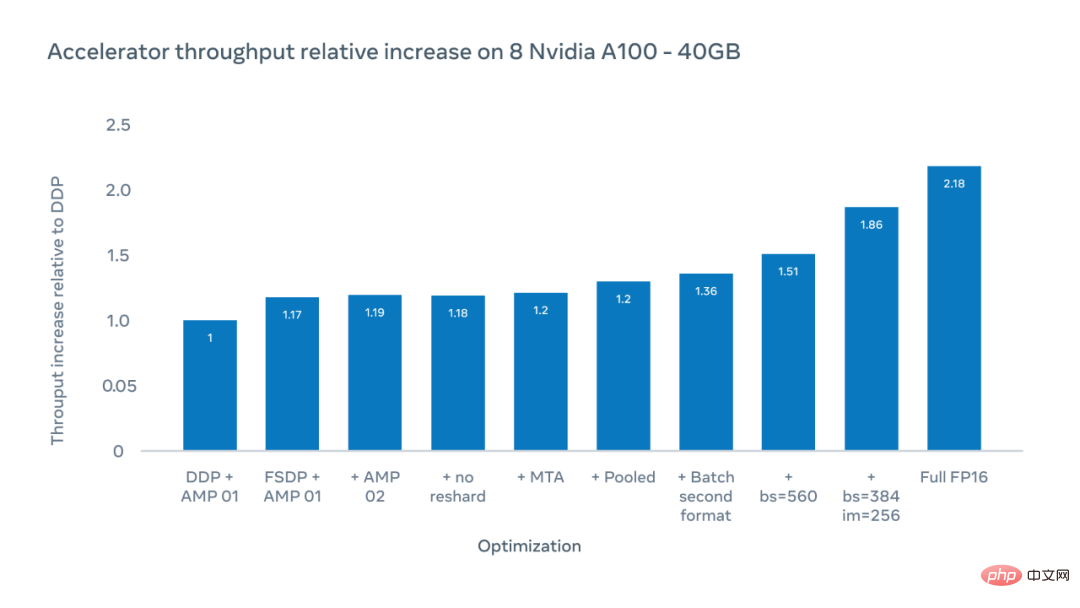
Para penyelidik mencapai peningkatan 1.51x dalam daya pemprosesan pemecut apabila jumlah saiz tampalan ialah 560, dari segi pelaksanaan sesaat pada setiap cip pemecut Diukur dengan bilangan operasi titik terapung. Dengan meningkatkan saiz imej daripada 224 piksel kepada 256 piksel, mereka dapat meningkatkan daya pemprosesan kepada 1.86x. Walau bagaimanapun, menukar saiz imej bermakna menukar hiperparameter, yang akan memberi kesan kepada ketepatan model. Apabila berlatih dalam mod FP16 penuh, daya pengeluaran relatif meningkat kepada 2.18x. Walaupun ketepatan kadangkala dikurangkan, dalam eksperimen ketepatan dikurangkan kurang daripada 10%.
Paksi Y bagi rajah di bawah ialah masa zaman, tempoh latihan terakhir pada keseluruhan set data ImageNet-1K. Di sini kami menumpukan pada masa latihan sebenar untuk konfigurasi sedia ada, yang biasanya menggunakan saiz imej 224 piksel.
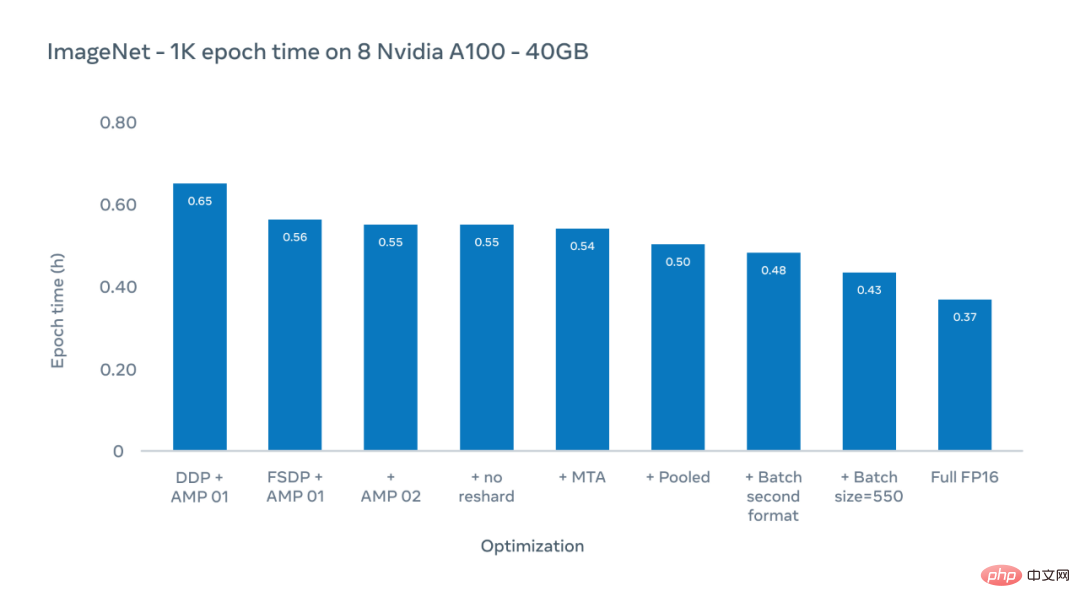
Penyelidik Meta AI menggunakan skema pengoptimuman untuk mengurangkan masa zaman (tempoh satu sesi latihan pada keseluruhan dataset ImageNet-1K) daripada 0.65 jam kepada 0.43 jam.
Paksi-x carta di bawah mewakili bilangan cip pemecut GPU A100 dalam konfigurasi tertentu, dan paksi-y mewakili daya pemprosesan mutlak dalam TFLOPS setiap cip.
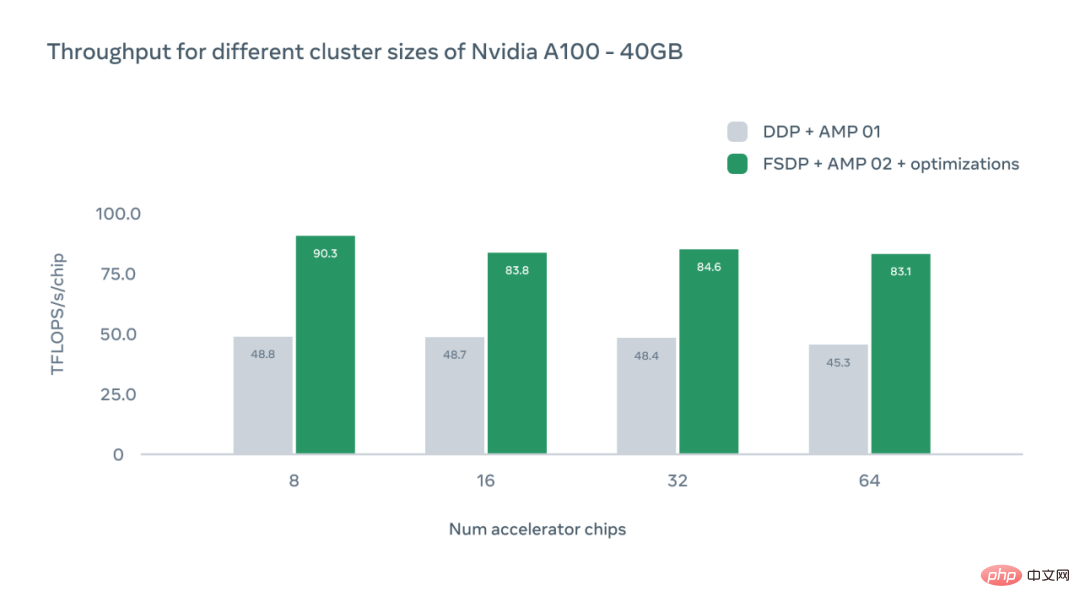
Kajian ini turut membincangkan kesan konfigurasi GPU yang berbeza. Dalam setiap kes, sistem mencapai daya pemprosesan yang lebih tinggi daripada tahap garis dasar selari data teragih (DDP). Apabila bilangan cip meningkat, kita dapat melihat sedikit penurunan dalam daya pemprosesan disebabkan oleh overhed komunikasi antara peranti. Walau bagaimanapun, walaupun dengan 64 GPU, sistem Meta adalah 1.83x lebih pantas daripada penanda aras DDP.
Menggandakan daya pengeluaran yang boleh dicapai dalam latihan ViT boleh menggandakan saiz kluster latihan dengan berkesan dan meningkatkan Penggunaan pemecut secara langsung mengurangkan pelepasan karbon model AI. Memandangkan pembangunan model besar baru-baru ini telah membawa arah aliran model yang lebih besar dan masa latihan yang lebih lama, pengoptimuman ini dijangka membantu bidang penyelidikan terus mendorong teknologi terkini, memendekkan masa pemulihan dan meningkatkan produktiviti.
Atas ialah kandungan terperinci Tanpa menimbun parameter atau bergantung pada masa, Meta mempercepatkan proses latihan ViT dan meningkatkan daya pengeluaran sebanyak 4 kali ganda.. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
















![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



