


이번 글에서는 SQL에서 discover와 row_number() over()의 차이점과 사용법을 주로 소개합니다. 필요하신 분들은 참고하시면 됩니다.
1 서문
데이터베이스의 데이터를 조작하기 위해 SQL 문을 작성할 때 몇 가지 불편한 문제가 발생할 수 있습니다. 예를 들어 동일한 필드에 동일한 이름을 가진 레코드의 경우 하나만 표시하면 되지만 실제로 데이터베이스에는 여러 개가 포함될 수 있습니다. 동일한 이름의 레코드로 인해 검색 중에 여러 레코드가 표시됩니다. 이는 원래 의도에 어긋납니다! 따라서 이러한 상황이 발생하지 않도록 하려면 "중복 제거" 처리를 수행해야 합니다. 그러면 "중복 제거"란 무엇입니까? 직설적으로 말하면, 동일한 필드에 동일한 내용을 가진 레코드에 대해 하나의 레코드만 표시된다는 의미입니다.
그럼 '중복제거' 기능은 어떻게 구현하나요? 이와 관련하여 이 기능을 달성하는 방법에는 두 가지가 있습니다.
첫 번째는 select 문을 작성할 때 고유 키워드를 추가합니다.
두 번째는 select 문을 작성할 때 row_number() over() 함수를 호출합니다. 🎜>.
위의 두 가지 방법 모두 '중복 제거' 기능을 구현할 수 있는데, 둘 사이의 유사점과 차이점은 무엇인가요? 다음으로 저자가 자세한 지침을 제공합니다.2개의 구별
SQL에서는 고유한 고유 값을 반환하는 데 키워드 구별이 사용됩니다. 구문 형식은 다음과 같습니다.SELECT DISTINCT 列名称 FROM 表名称
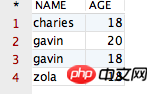
/** * 其中 PPPRDER 为 Schema 的名字,即表 distinct, row_number() 및 over()의 차이점에 대한 자세한 설명, row_number() 및 over()의 차이점에 대한 자세한 설명 在 PPPRDER 中 */ select distinct, row_number() 및 over()의 차이점에 대한 자세한 설명, row_number() 및 over()의 차이점에 대한 자세한 설명 from PPPRDER.distinct, row_number() 및 over()의 차이점에 대한 자세한 설명, row_number() 및 over()의 차이점에 대한 자세한 설명
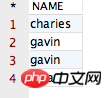
select distinct, row_number() 및 over()의 차이점에 대한 자세한 설명 distinct, row_number() 및 over()의 차이점에 대한 자세한 설명, row_number() 및 over()의 차이점에 대한 자세한 설명 from PPPRDER.distinct, row_number() 및 over()의 차이점에 대한 자세한 설명, row_number() 및 over()의 차이점에 대한 자세한 설명
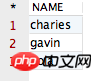
select distinct, row_number() 및 over()의 차이점에 대한 자세한 설명 distinct, row_number() 및 over()의 차이점에 대한 자세한 설명, row_number() 및 over()의 차이점에 대한 자세한 설명, age from PPPRDER.distinct, row_number() 및 over()의 차이점에 대한 자세한 설명, row_number() 및 over()의 차이점에 대한 자세한 설명
구별이 여러 필드에 적용될 때 동일한 필드 값을 가진 레코드만 "중복 제거"하기 때문입니다. 분명히 우리의 "불량" 4개 레코드는 이 조건을 충족하지 않으므로 구별됩니다. 위의 4개 레코드는 동일하지 않습니다. 빈말입니다. 다음으로 "distinct, row_number() 및 over()의 차이점에 대한 자세한 설명, row_number() 및 over()의 차이점에 대한 자세한 설명" 테이블에 동일한 레코드를 추가하고 확인해 보겠습니다. 레코드를 추가한 후의 테이블은 다음과 같습니다.
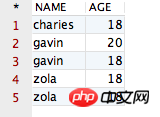
select distinct, row_number() 및 over()의 차이점에 대한 자세한 설명 distinct, row_number() 및 over()의 차이점에 대한 자세한 설명, row_number() 및 over()의 차이점에 대한 자세한 설명, age from PPPRDER.distinct, row_number() 및 over()의 차이점에 대한 자세한 설명, row_number() 및 over()의 차이점에 대한 자세한 설명
3 row_number() over()
SQL Server 데이터베이스에는 row_number()에 대한 row_number() 함수가 제공됩니다. 데이터베이스 테이블입니다. 레코드에 번호가 매겨져 있으며, 그 뒤에는 over() 함수가 따르며, over()의 기능은 테이블의 레코드를 그룹화하고 정렬하는 것입니다. 두 가지 모두에 사용되는 구문은 다음과 같습니다.
는 다음을 의미합니다. 테이블의 레코드를 COLUMN1 필드로 그룹화하고 COLUMN2 필드로 정렬합니다. 여기서 ROW_NUMBER() OVER(PARTITION BY COLUMN1 ORDER BY COLUMN2)
로그인 후 복사
PARTITION BY: 그룹화를 나타냄 ORDER BY: 정렬을 나타냄
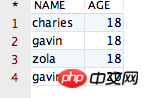
接下来,咱们还用表“distinct, row_number() 및 over()의 차이점에 대한 자세한 설명, row_number() 및 over()의 차이점에 대한 자세한 설명”中的数据进行测试。首先,给出没有使用 row_number() over() distinct, row_number() 및 over()의 차이점에 대한 자세한 설명时查询的结果,如下所示:
然后,运行如下 SQL 语句,
select PPPRDER.distinct, row_number() 및 over()의 차이점에 대한 자세한 설명, row_number() 및 over()의 차이점에 대한 자세한 설명.*, row_number() over(partition by age order by distinct, row_number() 및 over()의 차이점에 대한 자세한 설명, row_number() 및 over()의 차이점에 대한 자세한 설명 desc) from PPPRDER.distinct, row_number() 및 over()의 차이점에 대한 자세한 설명, row_number() 및 over()의 차이점에 대한 자세한 설명
得到的结果如下所示:
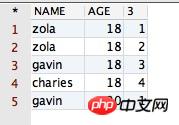
从上面的结果可以看出,其在原表的基础上,多了一列标有数字排序的列。那么反过来分析咱们运行的 SQL 语句,发现其确实按字段 AGE 的值进行分组了,也按字段 NAME 的值进行排序啦!因此,distinct, row_number() 및 over()의 차이점에 대한 자세한 설명的功能得到了验证。
接下来,咱们就研究如何用 row_number() over() distinct, row_number() 및 over()의 차이점에 대한 자세한 설명实现“去重”的功能。通过观察上面的结果,咱们可以发现,如果以 NAME 分组,以 AGE 排序,然后再取每组的第一个记录或许就可以实现“去重”的功能啊!那么试试看,运行如下 SQL 语句,
/* * 其中 distinct, row_number() 및 over()의 차이점에 대한 자세한 설명 表示最后添加的那一列 */ select * from (select PPPRDER.distinct, row_number() 및 over()의 차이점에 대한 자세한 설명, row_number() 및 over()의 차이점에 대한 자세한 설명.*, row_number() over(partition by distinct, row_number() 및 over()의 차이점에 대한 자세한 설명, row_number() 및 over()의 차이점에 대한 자세한 설명 order by age desc) distinct, row_number() 및 over()의 차이점에 대한 자세한 설명 from PPPRDER.distinct, row_number() 및 over()의 차이점에 대한 자세한 설명, row_number() 및 over()의 차이점에 대한 자세한 설명) where distinct, row_number() 및 over()의 차이점에 대한 자세한 설명 = 1
运行后,得到的结果如下所示:
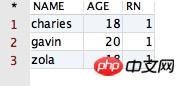
观察以上的结果,我们发现,哎呀,数据“去重”的功能一不小心就被咱们实现了啊!不过很遗憾,如果咱们细心的话,会发现一个很不爽的事情,那就是在执行以上 SQL 语句进行“去重”的时候,有一条 NAME 值为“gavin”、AGE 值为“18”的记录被过滤掉了,但是在现实生活会中,同名不同年龄的事情太正常了。
4 总结
通过阅读及实践以上内容,咱们已经知道了,无论是用关键字 distinct, row_number() 및 over()의 차이점에 대한 자세한 설명 还是用distinct, row_number() 및 over()의 차이점에 대한 자세한 설명 row_number() over() 都可以实现数据“去重”的功能。但是在实现使用的过程中,咱们要特别注意两者的用法特点以及区别。
在使用关键字 distinct, row_number() 및 over()의 차이점에 대한 자세한 설명 的时候,咱们要知道其作用于单个字段和多个字段的时候是有区别的,作用于单个字段时,其“去重”的是表中所有该字段值重复的数据;作用于多个字段的时候,其“去重”的表中所有字段(即 distinct, row_number() 및 over()의 차이점에 대한 자세한 설명 具体作用的多个字段)值都相同的数据。
在使用distinct, row_number() 및 over()의 차이점에 대한 자세한 설명 row_number() over() 的时候,其是按先分组排序后,再取出每组的第一条记录来进行“去重”的(在本篇博文中如此)。当然,在此处咱们还可以通过不同的限制条件来进行“去重”,具体如何实现,就需要大家自己去动脑思考啦!
最后,在本篇博文中,作者详述了自己对用关键字 distinct, row_number() 및 over()의 차이점에 대한 자세한 설명 和distinct, row_number() 및 over()의 차이점에 대한 자세한 설명 row_number() over() 进行数据“去重”的一些认识,希望以上的内容能够对大家有所帮助!
【相关推荐】
1. Mysql免费视频教程
2. 详解innodb_index_stats导入数据时 提示表主键冲突的错误
3. 实例详解 mysql中innodb_autoinc_lock_mode
위 내용은 distinct, row_number() 및 over()의 차이점에 대한 자세한 설명의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!
















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



