


This article brings you a detailed analysis of threads and processes in Node.js. It has certain reference value. Friends in need can refer to it. I hope it will be helpful to you.
There was a lot of early debate about Node.js focusing on its single-threaded model. In a famous article "Five reasons why PHP is better than Node.js" written by Jani Hartikainen, more There is a finger pointed directly at the single-threaded vulnerability of Node.js.
If the PHP code is damaged, it will not bring down the entire server. PHP code only runs in its own process scope. When a request displays an error, it only affects the specific request. In the Node.js environment, all requests are served in a single process. When a request causes an unknown error, the entire server will be affected.
Another very different point between Node.js and Apache PHP is the running time of the process. Of course, this is also written in this article as a reason why PHP is better than Node.js.
The PHP process is short-lived. In PHP, each process's request duration is very short, which means you don't have to worry about resource allocation and memory. Node.js processes need to run for a long time, and you need to be careful and manage memory properly. For example, if you forget to delete an entry from global data, this can easily lead to a memory leak.
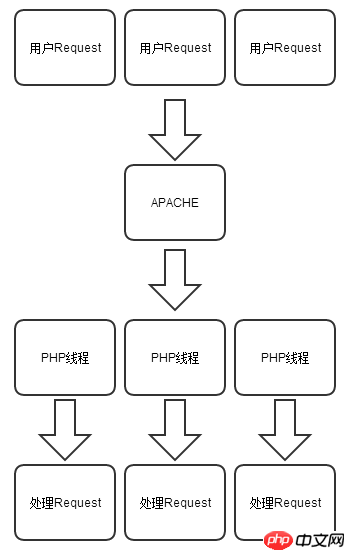
Here we do not want to cause a debate about the superiority of PHP and Node.js. PHP and Node.js each represent a development language in the Internet era, just like we discuss sports cars and off-road vehicles. It doesn’t matter who is better, they all have their own strengths and applicable scenarios. We can use the following two figures to gain a deeper understanding of the differences between PHP and Node.js in processing HTTP requests.
PHP model:
Node.js model:
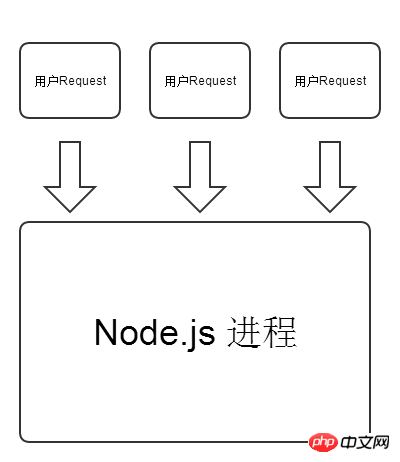
So you are writing When coding Node.js, you must keep a clear head. Any hidden exception will crash the entire Node.js process if it is triggered. But this feature also brings convenience to us when writing code. For example, to implement a simple website visit count, Node.js only needs to define a variable var count=0; in the memory, and execute count every time a user requests it. ; That’s it.
var http = require('http');
var count = 0;
http.createServer(function (request, response) {
response.writeHead(200, {'Content-Type': 'text/plain'});
response.end((++count).toString())
}).listen(8124);
console.log('Server running at http://127.0.0.1:8124/');But for PHP, you need to use a third-party medium to store this count value, such as creating a count.txt file to save the number of visits to the website.
$counter_file = ("count.txt");
$visits = file($counter_file);
$visits[0]++;
$fp = fopen($counter_file,"w");
fputs($fp,"$visits[0]");
fclose($fp);
echo "$visits[0]";
?>Single-threaded js
Google’s V8 Javascript engine has proven its performance in the Chrome browser, so Ryan Dahl, the author of Node.js, chose v8 as the engine for Node.js Execution engine, v8 not only gives Node.js efficient performance, but also determines that Node.js, like the famous Nginx, is based on a single thread. Of course, this is the original intention of the author Ryan Dahl in designing Node.js.
The advantages and disadvantages of single-threading
The single-threading of Node.js has its advantages, but it is not perfect. How does it ensure non-blocking while maintaining the single-threaded model?
High performance
First of all, single thread avoids the overhead of frequently creating and switching threads like traditional PHP, making the execution speed faster. Second, the resource usage is small. Friends who have done stress testing on the Node.js web server may find that Node.js still takes up very little memory under heavy load. The same load of PHP is due to the model of one thread per request. , will occupy a large amount of physical memory, which is likely to cause the server to frequently swap and lose response due to exhaustion of physical memory.
Thread safety
Single-threaded js also ensures absolute thread safety. You don’t have to worry about program crashes caused by the same variable being read and written by multiple threads at the same time. For example, the web access statistics we did before, because of the absolute thread safety of single thread, it is impossible to read and write the count variable at the same time. Our statistics code will not cause problems even if there are hundreds of concurrent user requests. Compared with PHP's method of storing files to record access, you will face the problem of concurrently writing files at the same time. Thread safety also frees developers from the tragedy caused by forgetting to lock or unlock variables in multi-thread programming.
Single-threaded asynchronous and non-blocking
Node.js is single-threaded, but how does it make I/O asynchronous and non-blocking? In fact, Node.js still uses multi-threading to access I/O at the bottom level. Interested friends can look at the source code of the fs module of Node.js, which uses libuv to handle I/O, so in our opinion Node.js The code is non-blocking and asynchronous.
Blocking/non-blocking and asynchronous/synchronization are two different concepts. Synchronization does not mean blocking, but blocking definitely means synchronization.
举个现实生活中的例子,我去食堂打饭,我选择了A套餐,然后工作人员帮我去配餐,如果我就站在旁边,等待工作人员给我配餐,这种情况就称之为同步;若工作人员帮我配餐的同时,排在我后面的人就开始点餐,这样整个食堂的点餐服务并没有因为我在等待A套餐而停止,这种情况就称之为非阻塞。这个例子就简单说明了同步但非阻塞的情况。
再如果我在等待配餐的时候去买饮料,等听到叫号再回去拿套餐,此时我的饮料也已经买好,这样我在等待配餐的同时还执行了买饮料的任务,叫号就等于执行了回调,就是异步非阻塞了。
阻塞的单线程
既然Node.js是单线程异步非阻塞的,是不是我们就可以高枕无忧了呢?
还是拿上面那个买套餐的例子,如果我在买饮料的时候,已经叫我的号让我去拿套餐,可是我等了好久才拿到饮料,所以我可能在大厅叫我的餐号之后很久才拿到A套餐,这也就是单线程的阻塞情况。
在浏览器中,js都是以单线程的方式运行的,所以我们不用担心js同时执行带来的冲突问题,这对于我们编码带来很多的便利。
但是对于在服务端执行的Node.js,它可能每秒有上百个请求需要处理,对于在浏览器端工作良好的单线程js是否也能同样在服务端表现良好呢?
我们看如下代码:
var start = Date.now();//获取当前时间戳
setTimeout(function () {
console.log(Date.now() - start);
for (var i = 0; i < 1000000000; i++){//执行长循环
}
}, 1000);
setTimeout(function () {
console.log(Date.now() - start);
}, 2000);最终我们的打印结果是:(结果可能因为你的机器而不同)
1000
3738
对于我们期望2秒后执行的setTimeout函数其实经过了3738毫秒之后才执行,换而言之,因为执行了一个很长的for循环,所以我们整个Node.js主线程被阻塞了,如果在我们处理100个用户请求中,其中第一个有需要这样大量的计算,那么其余99个就都会被延迟执行。
其实虽然Node.js可以处理数以千记的并发,但是一个Node.js进程在某一时刻其实只是在处理一个请求。
单线程和多核
线程是cpu调度的一个基本单位,一个cpu同时只能执行一个线程的任务,同样一个线程任务也只能在一个cpu上执行,所以如果你运行Node.js的机器是像i5,i7这样多核cpu,那么将无法充分利用多核cpu的性能来为Node.js服务。
多线程
在C++、C#、python等其他语言都有与之对应的多线程编程,有些时候这很有趣,带给我们灵活的编程方式;但是也可能带给我们一堆麻烦,需要学习更多的Api知识,在编写更多代码的同时也存在着更多的风险,线程的切换和锁也会造成系统资源的开销。
就像上面的那个例子,如果我们的Node.js有创建子线程的能力,那问题就迎刃而解了:
var start = Date.now();
createThread(function () { //创建一个子线程执行这10亿次循环
console.log(Date.now() - start);
for (var i = 0; i < 1000000000; i++){}
});
setTimeout(function () { //因为10亿次循环是在子线程中执行的,所以主线程不受影响
console.log(Date.now() - start);
}, 2000);可惜也可以说可喜的是,Node.js的核心模块并没有提供这样的api给我们,我们真的不想多线程又回归回来。不过或许多线程真的能够解决我们某方面的问题。
tagg2模块
Jorge Chamorro Bieling是tagg(Threads a gogo for Node.js)包的作者,他硬是利用phread库和C语言让Node.js支持了多线程的开发,我们看一下tagg模块的简单示例:
var Threads = require('threads_a_gogo');//加载tagg包
function fibo(n) {//定义斐波那契数组计算函数
return n > 1 ? fibo(n - 1) + fibo(n - 2) : 1;
}
var t = Threads.create().eval(fibo);
t.eval('fibo(35)', function(err, result) {//将fibo(35)丢入子线程运行
if (err) throw err; //线程创建失败
console.log('fibo(35)=' + result);//打印fibo执行35次的结果
});
console.log('not block');//打印信息了,表示没有阻塞上面这段代码利用tagg包将fibo(35)这个计算丢入了子线程中进行,保证了Node.js主线程的舒畅,当子线程任务执行完毕将会执行主线程的回调函数,把结果打印到屏幕上,执行结果如下:
not block
fibo(35)=14930352
斐波那契数列,又称黄金分割数列,这个数列从第三项开始,每一项都等于前两项之和:0、1、1、2、3、5、8、13、21、……。
注意我们上面代码的斐波那契数组算法并不是最优算法,只是为了模拟cpu密集型计算任务。
由于tagg包目前只能在linux下安装运行,所以我fork了一个分支,修改了部分tagg包的代码,发布了tagg2包。tagg2包同样具有tagg包的多线程功能,采用新的node-gyp命令进行编译,同时它跨平台支持,mac,linux,windows下都可以使用,对开发人员的api也更加友好。安装方法很简单,直接npm install tagg2。
一个利用tagg2计算斐波那契数组的http服务器代码:
var express = require('express');
var tagg2 = require("tagg2");
var app = express();
var th_func = function(){//线程执行函数,以下内容会在线程中执行
var fibo =function fibo (n) {//在子线程中定义fibo函数
return n > 1 ? fibo(n - 1) + fibo(n - 2) : 1;
}
var n = fibo(~~thread.buffer);//执行fibo递归
thread.end(n);//当线程执行完毕,执行thread.end带上计算结果回调主线程
};
app.get('/', function(req, res){
var n = ~~req.query.n || 1;//获取用户请求参数
var buf = new Buffer(n.toString());
tagg2.create(th_func, {buffer:buf}, function(err,result){
//创建一个js线程,传入工作函数,buffer参数以及回调函数
if(err) return res.end(err);//如果线程创建失败
res.end(result.toString());//响应线程执行计算的结果
})
});
app.listen(8124);
console.log('listen on 8124');其中~~req.query.n表示将用户传递的参数n取整,功能类似Math.floor函数。
我们用express框架搭建了一个web服务器,根据用户发送的参数n的值来创建子线程计算斐波那契数组,当子线程计算完毕之后将结果响应给客户端。由于计算是丢入子线程中运行的,所以整个主线程不会被阻塞,还是能够继续处理新请求的。
我们利用apache的http压力测试工具ab来进行一次简单的压力测试,看看执行斐波那契数组35次,100客户端并发100个请求,我们的QPS (Query Per Second)每秒查询率在多少。
ab的全称是ApacheBench,是Apache附带的一个小工具,用于进行HTTP服务器的性能测试,可以同时模拟多个并发请求。
我们的测试硬件:linux 2.6.4 4cpu 8G 64bit,网络环境则是内网。
ab压力测试命令:
ab -c 100 -n 100 http://192.168.28.5:8124/?n=35
压力测试结果:
Server Software:
Server Hostname: 192.168.28.5
Server Port: 8124
Document Path: /?n=35
Document Length: 8 bytes
Concurrency Level: 100
Time taken for tests: 5.606 seconds
Complete requests: 100
Failed requests: 0
Write errors: 0
Total transferred: 10600 bytes
HTML transferred: 800 bytes
Requests per second: 17.84 [#/sec](mean)
Time per request: 5605.769 [ms](mean)
Time per request: 56.058 [ms](mean, across all concurrent requests)
Transfer rate: 1.85 [Kbytes/sec] received
Connection Times (ms)
min mean[+/-sd] median max
Connect: 3 4 0.8 4 6
Processing: 455 5367 599.7 5526 5598
Waiting: 454 5367 599.7 5526 5598
Total: 461 5372 599.3 5531 5602
Percentage of the requests served within a certain time (ms)
50% 5531
66% 5565
75% 5577
80% 5581
90% 5592
95% 5597
98% 5600
99% 5602
100% 5602 (longest request)我们看到Requests per second表示每秒我们服务器处理的任务数量,这里是17.84。第二个我们比较关心的是两个Time per request结果,上面一行Time per request:5605.769 [ms](mean)表示当前这个并发量下处理每组请求的时间,而下面这个Time per request:56.058 [ms](mean, across all concurrent requests)表示每个用户平均处理时间,因为我们本次测试并发是100,所以结果正好是上一行的100分之1。得出本次测试平均每个用户请求的平均等待时间为56.058 [ms]。
另外我们看下最后带有百分比的列表,可以看到50%的用户是在5531 ms以内返回的,最慢的也不过5602 ms,响应延迟非常的平均。
我们如果用cluster来启动4个进程,是否可以充分利用cpu达到tagg2那样的QPS呢?我们在同样的网络环境和测试机上运行如下代码:
var cluster = require('cluster');//加载clustr模块
var numCPUs = require('os').cpus().length;//设定启动进程数为cpu个数
if (cluster.isMaster) {
for (var i = 0; i < numCPUs; i++) {
cluster.fork();//启动子进程
}
} else {
var express = require('express');
var app = express();
var fibo = function fibo (n) {//定义斐波那契数组算法
return n > 1 ? fibo(n - 1) + fibo(n - 2) : 1;
}
app.get('/', function(req, res){
var n = fibo(~~req.query.n || 1);//接收参数
res.send(n.toString());
});
app.listen(8124);
console.log('listen on 8124');
}在终端屏幕上打印了4行信息:
listen on 8124
listen on 8124
listen on 8124
listen on 8124
我们成功启动了4个cluster之后,用同样的ab压力测试命令对8124端口进行测试,结果如下:
Server Software:
Server Hostname: 192.168.28.5
Server Port: 8124
Document Path: /?n=35
Document Length: 8 bytes
Concurrency Level: 100
Time taken for tests: 10.509 seconds
Complete requests: 100
Failed requests: 0
Write errors: 0
Total transferred: 16500 bytes
HTML transferred: 800 bytes
Requests per second: 9.52 [#/sec](mean)
Time per request: 10508.755 [ms](mean)
Time per request: 105.088 [ms](mean, across all concurrent requests)
Transfer rate: 1.53 [Kbytes/sec] received
Connection Times (ms)
min mean[+/-sd] median max
Connect: 4 5 0.4 5 6
Processing: 336 3539 2639.8 2929 10499
Waiting: 335 3539 2639.9 2929 10499
Total: 340 3544 2640.0 2934 10504
Percentage of the requests served within a certain time (ms)
50% 2934
66% 3763
75% 4527
80% 5153
90% 8261
95% 9719
98% 10308
99% 10504
100% 10504 (longest request)通过和上面tagg2包的测试结果对比,我们发现区别很大。首先每秒处理的任务数从17.84 [#/sec]下降到了9.52 [#/sec],这说明我们web服务器整体的吞吐率下降了;然后每个用户请求的平均等待时间也从56.058 [ms]提高到了105.088 [ms],用户等待的时间也更长了。
最后我们发现用户请求处理的时长非常的不均匀,50%的用户在2934 ms内返回了,最慢的等待达到了10504 ms。虽然我们使用了cluster启动了4个Node.js进程处理用户请求,但是对于每个Node.js进程来说还是单线程的,所以当有4个用户跑满了4个Node.js的cluster进程之后,新来的用户请求就只能等待了,最后造成了先到的用户处理时间短,后到的用户请求处理时间比较长,就造成了用户等待时间非常的不平均。
v8引擎
大家看到这里是不是开始心潮澎湃,感觉js一统江湖的时代来临了,单线程异步非阻塞的模型可以胜任大并发,同时开发也非常高效,多线程下的js可以承担cpu密集型任务,不会有主线程阻塞而引起的性能问题。
但是,不论tagg还是tagg2包都是利用phtread库和v8的v8::Isolate Class类来实现js多线程功能的。
Isolate代表着一个独立的v8引擎实例,v8的Isolate拥有完全分开的状态,在一个Isolate实例中的对象不能够在另外一个Isolate实例中使用。嵌入式开发者可以在其他线程创建一些额外的Isolate实例并行运行。在任何时刻,一个Isolate实例只能够被一个线程进行访问,可以利用加锁/解锁进行同步操作。
换而言之,我们在进行v8的嵌入式开发时,无法在多线程中访问js变量,这条规则将直接导致我们之前的tagg2里面线程执行的函数无法使用Node.js的核心api,比如fs,crypto等模块。如此看来,tagg2包还是有它使用的局限性,针对一些可以使用js原生的大量计算或循环可以使用tagg2,Node.js核心api因为无法从主线程共享对象的关系,也就不能跨线程使用了。
libuv
最后,如果我们非要让Node.js支持多线程,还是提倡使用官方的做法,利用libuv库来实现。
libuv是一个跨平台的异步I/O库,它主要用于Node.js的开发,同时他也被Mozilla's Rust language, Luvit, Julia, pyuv等使用。它主要包括了Event loops事件循环,Filesystem文件系统,Networking网络支持,Threads线程,Processes进程,Utilities其他工具。
在Node.js核心api中的异步多线程大多是使用libuv来实现的,下一章将带领大家开发一个让Node.js支持多线程并基于libuv的Node.js包。
多进程
在支持html5的浏览器里,我们可以使用webworker来将一些耗时的计算丢入worker进程中执行,这样主进程就不会阻塞,用户也就不会有卡顿的感觉了。在Node.js中是否也可以使用这类技术,保证主线程的通畅呢?
cluster
cluster可以用来让Node.js充分利用多核cpu的性能,同时也可以让Node.js程序更加健壮,官网上的cluster示例已经告诉我们如何重新启动一个因为异常而奔溃的子进程。
webworker
想要像在浏览器端那样启动worker进程,我们需要利用Node.js核心api里的child_process模块。child_process模块提供了fork的方法,可以启动一个Node.js文件,将它作为worker进程,当worker进程工作完毕,把结果通过send方法传递给主进程,然后自动退出,这样我们就利用了多进程来解决主线程阻塞的问题。
我们先启动一个web服务,还是接收参数计算斐波那契数组:
var express = require('express');
var fork = require('child_process').fork;
var app = express();
app.get('/', function(req, res){
var worker = fork('./work_fibo.js') //创建一个工作进程
worker.on('message', function(m) {//接收工作进程计算结果
if('object' === typeof m && m.type === 'fibo'){
worker.kill();//发送杀死进程的信号
res.send(m.result.toString());//将结果返回客户端
}
});
worker.send({type:'fibo',num:~~req.query.n || 1});
//发送给工作进程计算fibo的数量
});
app.listen(8124);我们通过express监听8124端口,对每个用户的请求都会去fork一个子进程,通过调用worker.send方法将参数n传递给子进程,同时监听子进程发送消息的message事件,将结果响应给客户端。
下面是被fork的work_fibo.js文件内容:
var fibo = function fibo (n) {//定义算法
return n > 1 ? fibo(n - 1) + fibo(n - 2) : 1;
}
process.on('message', function(m) {
//接收主进程发送过来的消息
if(typeof m === 'object' && m.type === 'fibo'){
var num = fibo(~~m.num);
//计算jibo
process.send({type: 'fibo',result:num})
//计算完毕返回结果
}
});
process.on('SIGHUP', function() {
process.exit();//收到kill信息,进程退出
});我们先定义函数fibo用来计算斐波那契数组,然后监听了主线程发来的消息,计算完毕之后将结果send到主线程。同时还监听process的SIGHUP事件,触发此事件就进程退出。
这里我们有一点需要注意,主线程的kill方法并不是真的使子进程退出,而是会触发子进程的SIGHUP事件,真正的退出还是依靠process.exit();。
下面我们用ab 命令测试一下多进程方案的处理性能和用户请求延迟,测试环境不变,还是100个并发100次请求,计算斐波那切数组第35位:
Server Software:
Server Hostname: 192.168.28.5
Server Port: 8124
Document Path: /?n=35
Document Length: 8 bytes
Concurrency Level: 100
Time taken for tests: 7.036 seconds
Complete requests: 100
Failed requests: 0
Write errors: 0
Total transferred: 16500 bytes
HTML transferred: 800 bytes
Requests per second: 14.21 [#/sec](mean)
Time per request: 7035.775 [ms](mean)
Time per request: 70.358 [ms](mean, across all concurrent requests)
Transfer rate: 2.29 [Kbytes/sec] received
Connection Times (ms)
min mean[+/-sd] median max
Connect: 4 4 0.2 4 5
Processing: 4269 5855 970.3 6132 7027
Waiting: 4269 5855 970.3 6132 7027
Total: 4273 5860 970.3 6136 7032
Percentage of the requests served within a certain time (ms)
50% 6136
66% 6561
75% 6781
80% 6857
90% 6968
95% 7003
98% 7017
99% 7032
100% 7032 (longest request)压力测试结果QPS约为14.21,相比cluster来说,还是快了很多,每个用户请求的延迟都很平均,因为进程的创建和销毁的开销要大于线程,所以在性能方面略低于tagg2,不过相对于cluster方案,这样的提升还是令我们满意的。
换一种思路
使用child_process模块的fork方法确实可以让我们很好的解决单线程对cpu密集型任务的阻塞问题,同时又没有tagg2包那样无法使用Node.js核心api的限制。
但是如果我的worker具有多样性,每次在利用child_process模块解决问题时都需要去创建一个worker.js的工作函数文件,有点麻烦。我们是不是可以更加简单一些呢?
在我们启动Node.js程序时,node命令可以带上-e这个参数,它将直接执行-e后面的字符串,如下代码就将打印出hello world。
node -e "console.log('hello world')"
合理的利用这个特性,我们就可以免去每次都创建一个文件的麻烦。
var express = require('express');
var spawn = require('child_process').spawn;
var app = express();
var spawn_worker = function(n,end){//定义工作函数
var fibo = function fibo (n) {
return n > 1 ? fibo(n - 1) + fibo(n - 2) : 1;
}
end(fibo(n));
}
var spawn_end = function(result){//定义工作函数结束的回调函数参数
console.log(result);
process.exit();
}
app.get('/', function(req, res){
var n = ~~req.query.n || 1;
//拼接-e后面的参数
var spawn_cmd = '('+spawn_worker.toString()+'('+n+','+spawn_end.toString()+'));'
console.log(spawn_cmd);//注意这个打印结果
var worker = spawn('node',['-e',spawn_cmd]);//执行node -e "xxx"命令
var fibo_res = '';
worker.stdout.on('data', function (data) { //接收工作函数的返回
fibo_res += data.toString();
});
worker.on('close', function (code) {//将结果响应给客户端
res.send(fibo_res);
});
});
app.listen(8124);代码很简单,我们主要关注3个地方。
第一、我们定义了spawn_worker函数,他其实就是将会在-e后面执行的工作函数,所以我们把计算斐波那契数组的算法定义在内,spawn_worker函数接收2个参数,第一个参数n表示客户请求要计算的斐波那契数组的位数,第二个end参数是一个函数,如果计算完毕则执行end,将结果传回主线程;
第二、真正当Node.js脚步执行的字符串其实就是spawn_cmd里的内容,它的内容我们通过运行之后的打印信息,很容易就能明白;
第三、我们利用child_process的spawn方法,类似在命令行里执行了node -e "js code",启动Node.js工作进程,同时监听子进程的标准输出,将数据保存起来,当子进程退出之后把结果响应给用户。
现在主要的焦点就是变量spawn_cmd到底保存了什么,我们打开浏览器在地址栏里输入:
http://127.0.0.1:8124/?n=35
下面就是程序运行之后的打印信息,
(function (n,end){
var fibo = function fibo (n) {
return n > 1 ? fibo(n - 1) + fibo(n - 2) : 1;
}
end(fibo(n));
}(35,function (result){
console.log(result);
process.exit();
}));对于在子进程执行的工作函数的两个参数n和end现在一目了然,n代表着用户请求的参数,期望获得的斐波那契数组的位数,而end参数则是一个匿名函数,在标准输出中打印计算结果然后退出进程。
node -e命令虽然可以减少创建文件的麻烦,但同时它也有命令行长度的限制,这个值各个系统都不相同,我们通过命令getconf ARG_MAX来获得最大命令长度,例如:MAC OSX下是262,144 byte,而我的linux虚拟机则是131072 byte。
多进程和多线程
大部分多线程解决cpu密集型任务的方案都可以用我们之前讨论的多进程方案来替代,但是有一些比较特殊的场景多线程的优势就发挥出来了,下面就拿我们最常见的http web服务器响应一个小的静态文件作为例子。
以express处理小型静态文件为例,大致的处理流程如下: 1、首先获取文件状态,判断文件的修改时间或者判断etag来确定是否响应304给客户端,让客户端继续使用本地缓存。 2、如果缓存已经失效或者客户端没有缓存,就需要获取文件的内容到buffer中,为响应作准备。 3、然后判断文件的MIME类型,如果是类似html,js,css等静态资源,还需要gzip压缩之后传输给客户端 4、最后将gzip压缩完成的静态文件响应给客户端。
下面是一个正常成功的Node.js处理静态资源无缓存流程图:

这个流程中的(2),(3),(4)步都经历了从js到C++ ,打开和释放文件,还有调用了zlib库的gzip算法,其中每个异步的算法都会有创建和销毁线程的开销,所以这样也是大家诟病Node.js处理静态文件不给力的原因之一。
为了改善这个问题,我之前有利用libuv库开发了一个改善Node.js的http/https处理静态文件的包,名为ifile,ifile包,之所以可以加速Node.js的静态文件处理性能,主要是减少了js和C++的互相调用,以及频繁的创建和销毁线程的开销,下图是ifile包处理一个静态无缓存资源的流程图:
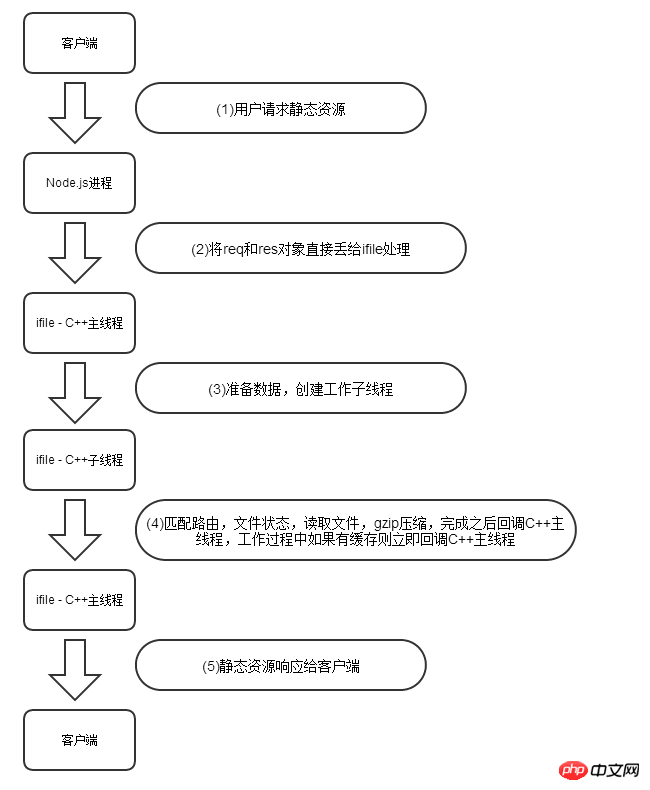
由于全部工作都是在libuv的子线程中执行的,所以Node.js主线程不会阻塞,当然性能也会大幅提升了,使用ifile包非常简单,它能够和express无缝的对接。
var express = require('express');
var ifile = require("ifile");
var app = express();
app.use(ifile.connect()); //默认值是 [['/static',__dirname]];
app.listen(8124);上面这4行代码就可以让express把静态资源交给ifile包来处理了,我们在这里对它进行了一个简单的压力测试,测试用例为响应一个大小为92kb的jquery.1.7.1.min.js文件,测试命令:
ab -c 500 -n 5000 -H "Accept-Encoding: gzip"
http://192.168.28.5:8124/static/jquery.1.7.1.min.js
由于在ab命令中我们加入了-H "Accept-Encoding: gzip",表示响应的静态文件希望是gzip压缩之后的,所以ifile将会把压缩之后的jquery.1.7.1.min.js文件响应给客户端。结果如下:
Server Software:
Server Hostname: 192.168.28.5
Server Port: 8124
Document Path: /static/jquery.1.7.1.min.js
Document Length: 33016 bytes
Concurrency Level: 500
Time taken for tests: 9.222 seconds
Complete requests: 5000
Failed requests: 0
Write errors: 0
Total transferred: 166495000 bytes
HTML transferred: 165080000 bytes
Requests per second: 542.16 [#/sec](mean)
Time per request: 922.232 [ms](mean)
Time per request: 1.844 [ms](mean, across all concurrent requests)
Transfer rate: 17630.35 [Kbytes/sec] received
Connection Times (ms)
min mean[+/-sd] median max
Connect: 0 49 210.2 1 1003
Processing: 191 829 128.6 870 1367
Waiting: 150 824 128.5 869 1091
Total: 221 878 230.7 873 1921
Percentage of the requests served within a certain time (ms)
50% 873
66% 878
75% 881
80% 885
90% 918
95% 1109
98% 1815
99% 1875
100% 1921 (longest request)我们首先看到Document Length一项结果为33016 bytes说明我们的jquery文件已经被成功的gzip压缩,因为源文件大小是92kb;其次,我们最关心的Requests per second:542.16 [#/sec](mean),说明我们每秒能处理542个任务;最后,我们看到,在这样的压力情况下,平均每个用户的延迟在1.844 [ms]。
我们看下使用express框架处理这样的压力会是什么样的结果,express测试代码如下:
var express = require('express'); var app = express(); app.use(express.compress());//支持gzip app.use('/static', express.static(__dirname + '/static')); app.listen(8124);
代码同样非常简单,注意这里我们使用:
app.use('/static', express.static(__dirname + '/static'));
而不是:
app.use(express.static(__dirname));
后者每个请求都会去匹配一次文件是否存在,而前者只有请求url是/static开头的才会去匹配静态资源,所以前者效率更高一些。然后我们执行相同的ab压力测试命令看下结果:
Server Software:
Server Hostname: 192.168.28.5
Server Port: 8124
Document Path: /static/jquery.1.7.1.min.js
Document Length: 33064 bytes
Concurrency Level: 500
Time taken for tests: 16.665 seconds
Complete requests: 5000
Failed requests: 0
Write errors: 0
Total transferred: 166890000 bytes
HTML transferred: 165320000 bytes
Requests per second: 300.03 [#/sec](mean)
Time per request: 1666.517 [ms](mean)
Time per request: 3.333 [ms](mean, across all concurrent requests)
Transfer rate: 9779.59 [Kbytes/sec] received
Connection Times (ms)
min mean[+/-sd] median max
Connect: 0 173 539.8 1 7003
Processing: 509 886 350.5 809 9366
Waiting: 238 476 277.9 426 9361
Total: 510 1059 632.9 825 9367
Percentage of the requests served within a certain time (ms)
50% 825
66% 908
75% 1201
80% 1446
90% 1820
95% 1952
98% 2560
99% 3737
100% 9367 (longest request)同样分析一下结果,Document Length:33064 bytes表示文档大小为33064 bytes,说明我们的gzip起作用了,每秒处理任务数从ifile包的542下降到了300,最长用户等待时间也延长到了9367 ms,可见我们的努力起到了立竿见影的作用,js和C++互相调用以及线程的创建和释放并不是没有损耗的。
但是当我在express的谷歌论坛里贴上这些测试结果,并宣传ifile包的时候,express的作者TJ,给出了不一样的评价,他在回复中说道:
请牢记你可能不需要这么高等级吞吐率的系统,就算是每月百万级别下载量的npm网站,也仅仅每秒处理17个请求而已,这样的压力甚至于PHP也可以处理掉(又黑了一把php)。
确实如TJ所说,性能只是我们项目的指标之一而非全部,一味的去追求高性能并不是很理智。
ifile包开源项目地址:https://github.com/DoubleSpout/ifile
总结
单线程的Node.js给我们编码带来了太多的便利和乐趣,我们应该时刻保持清醒的头脑,在写Node.js代码中切不可与PHP混淆,任何一个隐藏的问题都可能击溃整个线上正在运行的Node.js程序。
单线程异步的Node.js不代表不会阻塞,在主线程做过多的任务可能会导致主线程的卡死,影响整个程序的性能,所以我们要非常小心的处理大量的循环,字符串拼接和浮点运算等cpu密集型任务,合理的利用各种技术把任务丢给子线程或子进程去完成,保持Node.js主线程的畅通。
The use of threads/processes is not without overhead. Reducing the number of threads/processes created and destroyed as much as possible can improve the overall performance and error probability of our system.
Finally, please do not blindly pursue high performance and high concurrency, because we may not need the system to have such a high throughput rate. Efficient, agile, and low-cost development are what the project needs, which is also the key to why Node.js can stand out among many development languages.
Related recommendations:
How to write variables (code) when passing parameters in url
JS tutorial--Knapsack capacity of dynamic programming algorithm Question
Explanation of knowledge about scope and closure in javaScript
The above is the detailed content of Detailed analysis of threads and processes in Node.js. For more information, please follow other related articles on the PHP Chinese website!
















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



