
このサイトでは学術的、技術的な内容のコラムを公開しています。近年、このサイトの AIxiv コラムには 2,000 件を超えるレポートが寄せられ、世界中の主要な大学や企業のトップ研究室がカバーされ、学術交流と普及を効果的に促進しています。共有したい優れた作品がある場合は、お気軽に寄稿するか、報告のために当社までご連絡ください。提出電子メール: liyazhou@jiqizhixin.com; zhaoyunfeng@jiqizhixin.com。
ビデオ理解の新しい領域を探索してください。Mamba モデルは、コンピューター ビジョン研究の新しいトレンドをリードします。従来のアーキテクチャの制限は打ち破られ、状態空間モデル Mamba は、長いシーケンス処理における独自の利点により、ビデオ理解の分野に革命的な変化をもたらしました。 南京大学、上海人工知能研究所、復旦大学、浙江大学の研究チームが画期的な研究成果を発表しました。彼らは、ビデオ モデリングにおける Mamba の複数の役割を包括的に検討し、14 のモデル/モジュール用の Video Mamba Suite を提案し、12 のビデオ理解タスクについて詳細な評価を実施します。その結果は興味深いものでした。Mamba はビデオ固有のタスクとビデオ言語によるタスクの両方で強力な可能性を示し、効率とパフォーマンスの理想的なバランスを実現しました。これは技術的な飛躍であるだけでなく、将来のビデオ理解研究への強力な推進力でもあります。 
- 論文タイトル: Video Mamba Suite: State Space Model as a Versatile Alternative for Video Understanding
- 論文リンク: https://arxiv.org/abs/2403.09626
- コードリンク: https ://github.com/OpenGVLab/video-mamba-suite
今日の急速に発展しているコンピュータービジョン分野において、ビデオ理解テクノロジーは業界の進歩の重要な原動力の 1 つとなっています。多くの研究者は、ビデオ コンテンツのより深い分析を実現するために、さまざまな深層学習アーキテクチャの探索と最適化に取り組んでいます。初期のリカレント ニューラル ネットワーク (RNN) や 3 次元畳み込みニューラル ネットワーク (3D CNN) から、現在大いに期待されている Transformer モデルに至るまで、それぞれの技術的進歩により、ビデオ データに対する理解と応用が大幅に広がりました。 特に、Transformer モデルは、ターゲット検出、画像セグメンテーション、マルチモーダル質問応答など (ただしこれらに限定されない) 優れたパフォーマンスにより、ビデオ理解の複数の分野で目覚ましい成果を達成しました。ただし、ビデオ データの固有の超長時間シーケンスの特性に直面して、Transformer モデルはその固有の制限も露呈します。つまり、計算の複雑さが二次的に増加するため、超長時間のビデオ シーケンスを直接モデル化することが非常に困難になります。 この文脈において、Mamba に代表される状態空間モデル アーキテクチャは、線形計算量の利点により、Transformer の基礎となる長いシーケンス データを処理するための強力な可能性を示しています。代替モデルには可能性があります。それにもかかわらず、ビデオ理解の分野における状態空間モデル アーキテクチャの現在の適用には依然としていくつかの制限があります。第 1 に、主に分類や検索などのグローバル ビデオ理解タスクに焦点を当てています。第 2 に、直接的な時空間モデリング手法を主に検討しています。しかし、より多様なモデリング手法の探求はまだ不十分です。 これらの制限を克服し、ビデオ理解の分野における Mamba モデルの可能性を包括的に評価するために、研究チームは video-mamba-suite (Video Mamba Suite) を慎重に構築しました。このスイートは、既存の研究を補完することを目的としており、一連の詳細な実験と分析を通じてビデオ理解における Mamba の多様な役割と潜在的な利点を探ります。 研究チームは、Mamba モデルのアプリケーションを 4 つの異なる役割に分割し、それに応じて 14 のモデル/モジュールを含むビデオ Mamba スイートを構築しました。 12 のビデオ理解タスクを包括的に評価した後の実験結果は、ビデオおよびビデオ言語タスクの処理における Mamba の大きな可能性を明らかにするだけでなく、効率とパフォーマンスの優れたバランスも示しています。著者らは、この研究がビデオ理解の分野における将来の研究のための参考リソースと洞察を提供することを楽しみにしています。 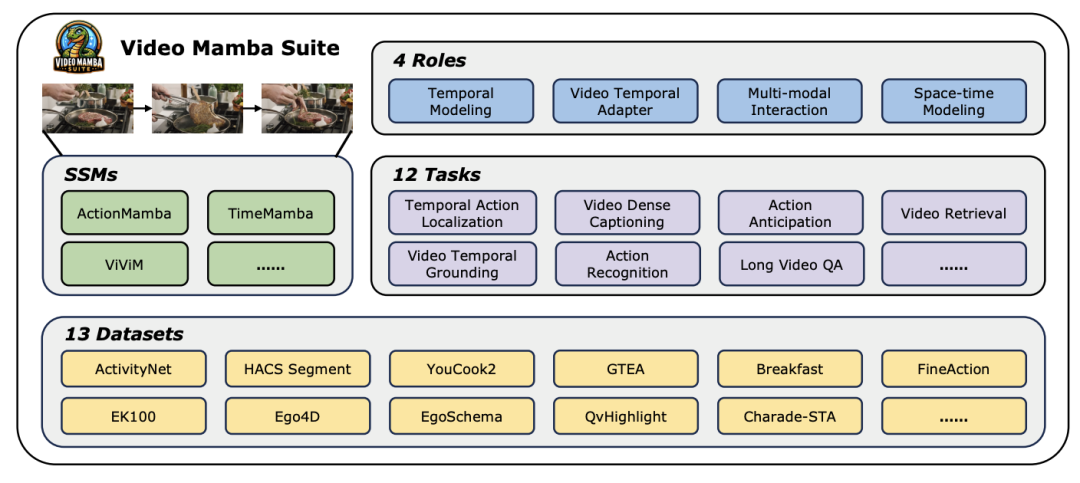
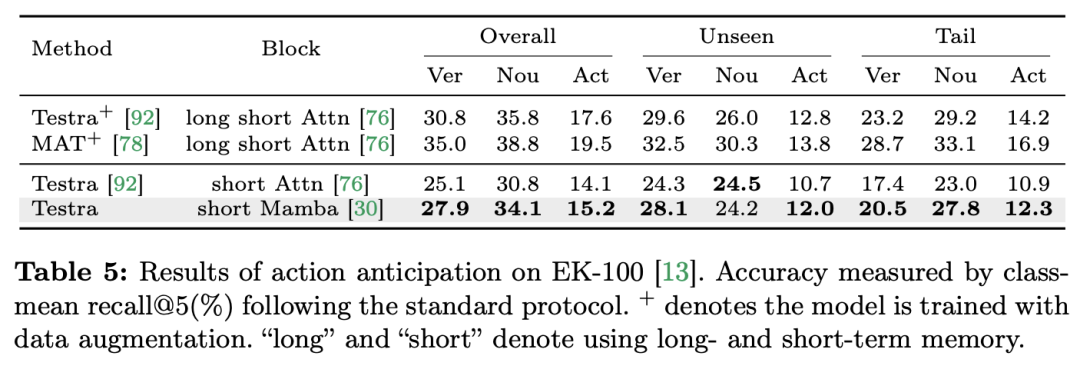
ビデオの理解は、コンピュータービジョン研究の基本的な問題であり、その中心は、ビデオ内の時空間ダイナミクスをキャプチャし、それを使用してアクティビティとその進化の性質を特定および推測することです。プロセス。現在、ビデオ理解のためのアーキテクチャの探索は主に 3 つの方向に分かれています。 まず、フレームベースの特徴符号化手法は、リカレントネットワーク (GRU や LSTM など) を通じて時間依存性をモデル化しますが、このセグメント化された時空間モデリング手法では、結合時空間情報を取得することが困難です。第 2 に、3 次元畳み込みカーネルの使用により、畳み込みニューラル ネットワークにおける空間的相関と時間的相関を同時に考慮できるようになります。 言語と画像の分野での Transformer モデルの大成功に伴い、ビデオ Transformer モデルはビデオ理解の分野でも大きな進歩を遂げ、RNN や 3D-CNN を超える機能を実証しました。 Video Transformer は、ビデオを一連のトークンにカプセル化し、アテンション メカニズムを使用してグローバル コンテキスト インタラクションとデータ依存の動的計算を実装することにより、ビデオ内の時間または時空間情報を統合された方法で処理します。 ただし、長いビデオを処理する場合の Video Transformer の計算効率には限界があるため、速度とパフォーマンスのバランスを取るいくつかのバリアント モデルが登場しました。最近、状態空間モデル (SSM) が自然言語処理 (NLP) の分野でその利点を示しています。最新の SSM は、線形時間計算量を維持しながら、長いシーケンスをモデル化する際に強力な表現機能を発揮します。これは、その選択メカニズムにより、完全なコンテキストを保存する必要がなくなるためです。特に Mamba モデルは、時変パラメータを SSM に組み込み、効率的なトレーニングと推論を実現するハードウェア対応アルゴリズムを提案します。 Mamba の優れたスケーリング パフォーマンスは、Mamba が Transformer の有望な代替手段となり得ることを示しています。 同時に、Mamba は高いパフォーマンスと効率を備えているため、ビデオを理解するタスクに非常に適しています。画像/ビデオモデリングにおける Mamba の応用を探る初期の試みがいくつかありましたが、ビデオ理解における Mamba の有効性はまだ不明です。ビデオ理解における Mamba の可能性に関する包括的な研究が不足しているため、さまざまなビデオ関連タスクにおける Mamba の機能のさらなる探究が制限されています。 上記の問題に対応して、研究チームはビデオ理解の分野における Mamba の可能性を調査しました。彼らの研究の目標は、Mamba がこの分野でトランスフォーマーの実行可能な代替品になり得るかどうかを評価することです。これを行うために、彼らはまず、ビデオを理解する上でのマンバのさまざまな役割についてどのように考えるかという問題に取り組みました。これに基づいて、Mamba がどのタスクをより良く実行するかをさらに研究しました。 この論文では、ビデオモデリングにおける Mamba の役割を次の 4 つのカテゴリに分類しています: 1) 時間モデル、2) 時間モジュール、3) マルチモーダル インタラクション ネットワーク、4) 時空間モデル。研究チームは、役割ごとに、さまざまなビデオ理解タスクに関するビデオ モデリング機能を研究しました。 Manba と Transformer を公平に争わせるために、研究チームは、標準または変更された Transformer アーキテクチャに基づいて比較対象のモデルを慎重に選択しました。これに基づいて、12 のビデオ理解タスクに適した 14 のモデル/モジュールを含む Video Mamba Suite を入手しました。研究チームは、Video Mamba Suite が将来、SSM ベースのビデオ理解モデルを探索するための基本リソースになることを期待しています。 タスクとデータ: 研究チームは、5つのビデオタイミングタスクでMambaのパフォーマンスを評価しました: 時間的アクションローカリゼーション ( HACSセグメント)、時間的アクション セグメンテーション (GTEA)、高密度ビデオ キャプション (ActivityNet、YouCook)、ビデオ セグメント キャプション (ActivityNet、YouCook)、およびアクション予測 (Epic-Kitchen-100)。 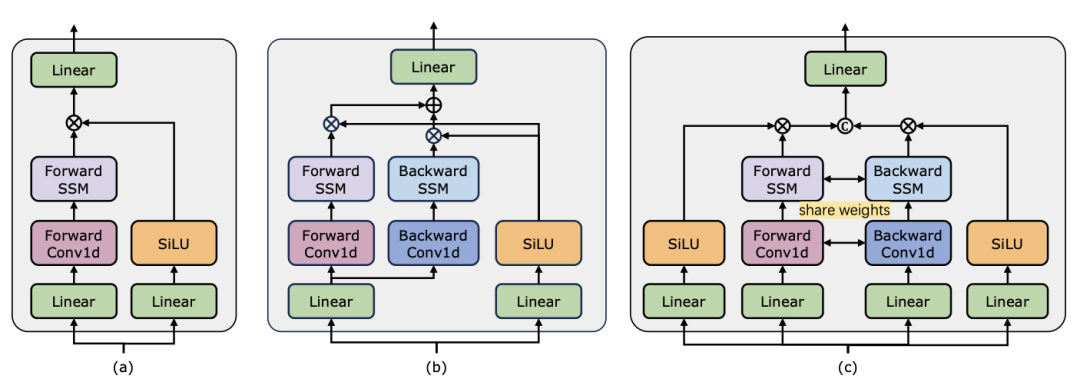 ベースラインとチャレンジャー: 研究チームは、各タスクのベースラインとして Transformer ベースのモデルを選択しました。具体的には、これらのベースライン モデルには、ActionFormer、ASFormer、Testra、PDVC が含まれます。 Mamba チャレンジャーを構築するために、ベースライン モデルの Transformer モジュールを Mamba ベースのモジュールに置き換えました。これには、上に示した 3 つのモジュール、元の Mamba (a)、ViM (b)、および元々の DBM (c) が含まれます。研究チームによって設計された) モジュール。この論文では、因果推論を含むアクション予測タスクにおいて、ベースライン モデルのパフォーマンスを元の Mamba モジュールと比較していることは注目に値します。 結果と分析: この論文では、4 つのタスクに関する異なるモデルの比較結果が示されています。全体的に見て、一部の Transformer ベースのモデルには、パフォーマンスを向上させるための注意バリアントが組み込まれています。以下の表は、既存の Transformer シリーズ方式と比較した Mamba シリーズの優れたパフォーマンスを示しています。
ベースラインとチャレンジャー: 研究チームは、各タスクのベースラインとして Transformer ベースのモデルを選択しました。具体的には、これらのベースライン モデルには、ActionFormer、ASFormer、Testra、PDVC が含まれます。 Mamba チャレンジャーを構築するために、ベースライン モデルの Transformer モジュールを Mamba ベースのモジュールに置き換えました。これには、上に示した 3 つのモジュール、元の Mamba (a)、ViM (b)、および元々の DBM (c) が含まれます。研究チームによって設計された) モジュール。この論文では、因果推論を含むアクション予測タスクにおいて、ベースライン モデルのパフォーマンスを元の Mamba モジュールと比較していることは注目に値します。 結果と分析: この論文では、4 つのタスクに関する異なるモデルの比較結果が示されています。全体的に見て、一部の Transformer ベースのモデルには、パフォーマンスを向上させるための注意バリアントが組み込まれています。以下の表は、既存の Transformer シリーズ方式と比較した Mamba シリーズの優れたパフォーマンスを示しています。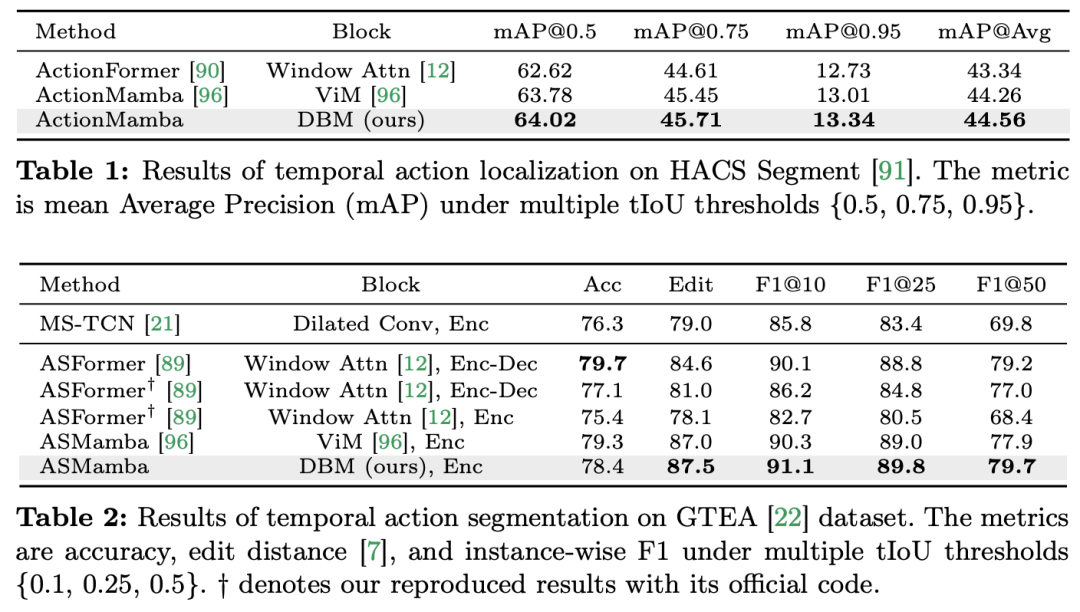
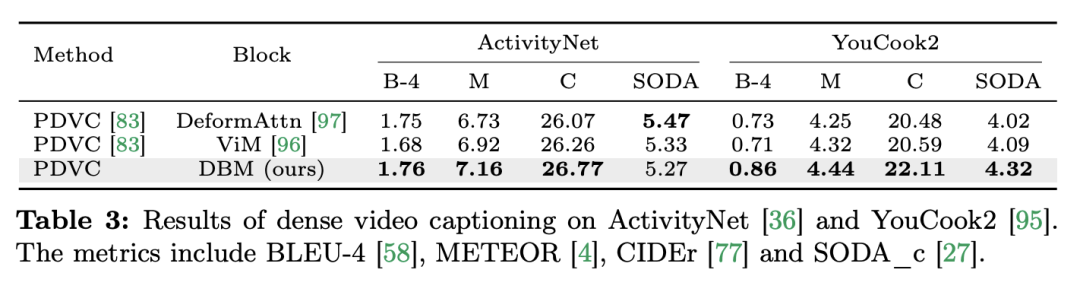
研究チームは、シングルモーダルタスクに焦点を当てるだけでなく、クロスモーダルインタラクションタスクにおけるMambaのパフォーマンスも評価しました。この論文では、ビデオ時間的位置特定 (VTG) タスクを使用して Mamba のパフォーマンスを評価しています。対象となるデータセットには、QvHighlight と Charade-STA が含まれます。 タスクとデータ: 研究チームは、時間的アクションローカリゼーション (HACS セグメント)、時間的アクションセグメンテーション (GTEA)、高密度ビデオ字幕 (ActivityNet、YouCook )、ビデオ段落字幕の 5 つのビデオ時間的タスクにおける Mamba のパフォーマンスを評価しました。 (ActivityNet、YouCook) およびアクション予測 (Epic-Kitchen-100)。 ベースラインとチャレンジャー: 研究チームは UniVTG を使用して Mamba ベースの VTG モデルを構築しました。 UniVTG は、マルチモーダル インタラクション ネットワークとして Transformer を採用しています。ビデオ機能とテキスト機能が与えられると、位置情報とモダリティ情報を保存するために、各モダリティに学習可能な位置埋め込みとモダリティ タイプ埋め込みが最初に追加されます。次に、テキスト トークンとビデオ トークンが連結されて結合入力が形成され、それがさらにマルチモーダル Transformer エンコーダーに供給されます。最後に、テキスト拡張されたビデオ特徴が抽出され、予測ヘッドに供給されます。クロスモーダルな Mamba 競合製品を作成するために、研究チームは双方向 Mamba ブロックをスタックしてマルチモーダル Mamda エンコーダーを形成し、Transformer ベースラインを置き換えることを選択しました。 結果と分析: このペーパーでは、QvHighlight を通じて複数のモデルのパフォーマンスをテストします。 Mamba の平均 mAP は 44.74 で、これは Transformer と比較して大幅な改善です。 Charade-STA では、Mamba ベースの方法が Transformer と同様の競争力を示します。これは、Mamba が複数のモダリティを効果的に統合する可能性があることを示しています。 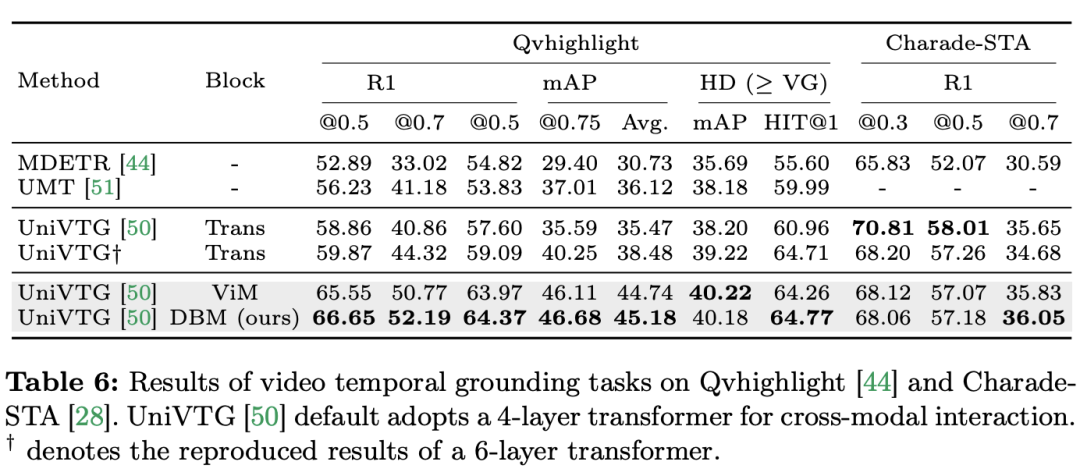
Mamba がリニア スキャンに基づいたモデルであるのに対し、Transformer はグローバル マーク インタラクションに基づいていることを考慮すると、研究チームは、マーク シーケンス内のテキストの位置がマルチモーダル集約の効果に影響を与える可能性があると直感的に信じています。これを調査するために、彼らは表にさまざまなテキストと視覚の融合方法を含め、図に 4 つの異なるマークの配置を示しています。結論としては、テキストの条件が視覚的特徴の左側に融合されている場合に最良の結果が得られるということです。 QvHighlight はこの融合にあまり影響を与えませんが、Charade-STA はテキストの位置に特に敏感であり、これはデータセットの特性に起因すると考えられます。 
ビデオ タイミング アダプターとしての Mamba 研究チームは、ポスト タイミング モデリングにおける Mamba のパフォーマンスを評価することに加えて、ビデオ タイミング アダプターとしてのその有効性も調べました。 Two Towers モデルは、きめ細かいナレーションを含む 400 万のビデオ クリップを含む自己中心的なデータに対してビデオとテキストの対比学習を実行することで事前トレーニングされています。 タスクとデータ: 研究チームは、時間的アクションローカリゼーション (HACS セグメント)、時間的アクションセグメンテーション (GTEA)、高密度ビデオ字幕 (ActivityNet、YouCook)、ビデオを含む 5 つのビデオ時間的タスクにおける Mamba のパフォーマンスを評価しました。段落の字幕 (ActivityNet、YouCook) とアクション予測 (Epic-Kitchen-100)。 ベースラインとチャレンジャー: TimeSformer は、ビデオ内の空間的関係と時間的関係を個別にモデル化するために、個別の時空間的注意ブロックを採用しています。この目的を達成するために、研究チームは双方向 Mamba ブロックをタイミング アダプターとして導入し、元のタイミング自己注意を置き換え、個別の時空間相互作用を改善しました。公正な比較のために、TimeSformer の空間アテンション レイヤーは変更されていません。ここで、研究チームは ViM ブロックをタイミング モジュールとして使用し、結果として得られたモデルを TimeMamba と呼びました。 標準 ViM ブロックにはセルフアテンション ブロックよりも多くのパラメーター (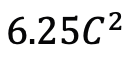 よりわずかに多い) があることは注目に値します (C は特徴次元)。したがって、公平な比較のために、論文では ViM ブロックの拡大率 E を 1 に設定し、パラメーター サイズを
よりわずかに多い) があることは注目に値します (C は特徴次元)。したがって、公平な比較のために、論文では ViM ブロックの拡大率 E を 1 に設定し、パラメーター サイズを 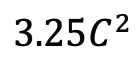 に削減します。 TimeSformer で使用される通常の残留接続形式に加えて、研究チームは Frozen スタイルの適応も検討しました。以下は 5 つのアダプター構造です:
に削減します。 TimeSformer で使用される通常の残留接続形式に加えて、研究チームは Frozen スタイルの適応も検討しました。以下は 5 つのアダプター構造です: 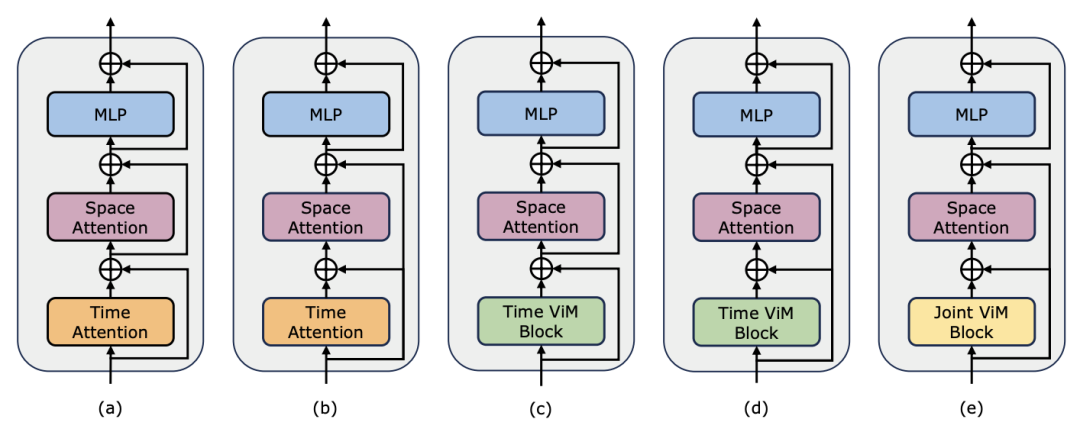
1. ゼロショットのマルチインスタンス取得。研究チームはまず、テーブル内の個別の時空間相互作用を持つさまざまなモデルを評価し、論文で再現されたアナと雪の女王スタイルの残差接続が LaViLa の接続と一致していることを発見しました。オリジナルのスタイルとアナと雪の女王のスタイルを比較すると、アナと雪の女王のスタイルが常により良い結果を生み出すことを観察するのは難しくありません。さらに、同じ適応方法の下では、ViM ベースの時間モジュールは常に注意ベースの時間モジュールよりも優れています。 論文で使用されている ViM 時間ブロックのパラメータが時間セルフ アテンション ブロックよりも少ないことは注目に値します。これは、Mamba 選択的スキャンのより優れたパラメータ利用と情報抽出機能を強調しています。 さらに、研究チームは時空ViMブロックをさらに検証しました。時空間 ViM ブロックは、ビデオ シーケンス全体にわたる共同時空間モデリングで時間 ViM ブロックを置き換えます。驚くべきことに、グローバル モデリングの導入にも関わらず、時空間 ViM ブロックは実際にパフォーマンスの低下を引き起こしました。この目的を達成するために、研究チームは、スキャンベースの時空間が事前に訓練された空間注意ブロックを破壊して、空間特徴分布を生成する可能性があると推測しています。以下は実験結果です: 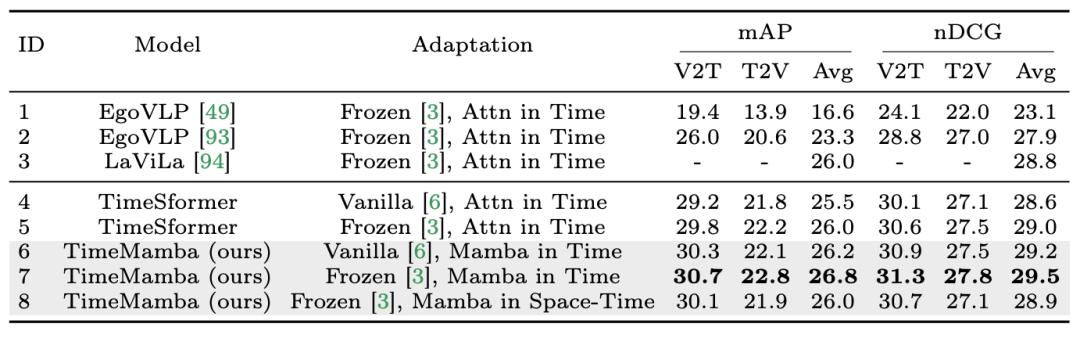
2. マルチインスタンスの取得とアクション認識を微調整します。研究チームは、マルチインスタンスの検索とアクション認識のために、Epic-Kitchens-100 データセット上の 16 フレームの微調整された事前トレーニング済みモデルを引き続き使用しています。実験結果から、TimeMamba が動詞認識のコンテキストで TimeSformer よりも大幅に優れており、2.8 パーセント ポイントを超えていることがわかります。これは、TimeMamba が詳細なタイミングを効果的にモデル化できることを示しています。 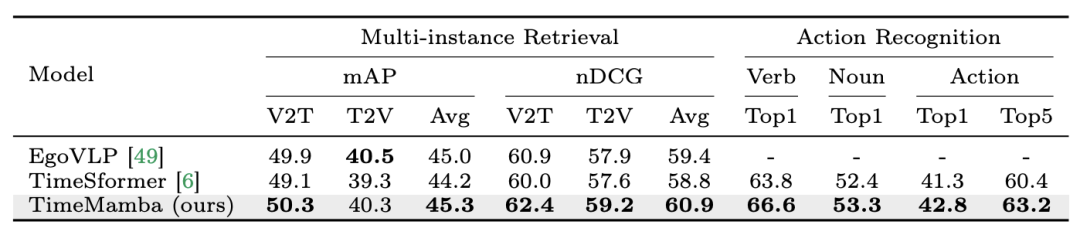
3. ゼロサンプルの長いビデオ Q&A。研究チームはさらに、EgoSchema データセットでのモデルの長いビデオ Q&A パフォーマンスを評価しました。以下は実験結果です: 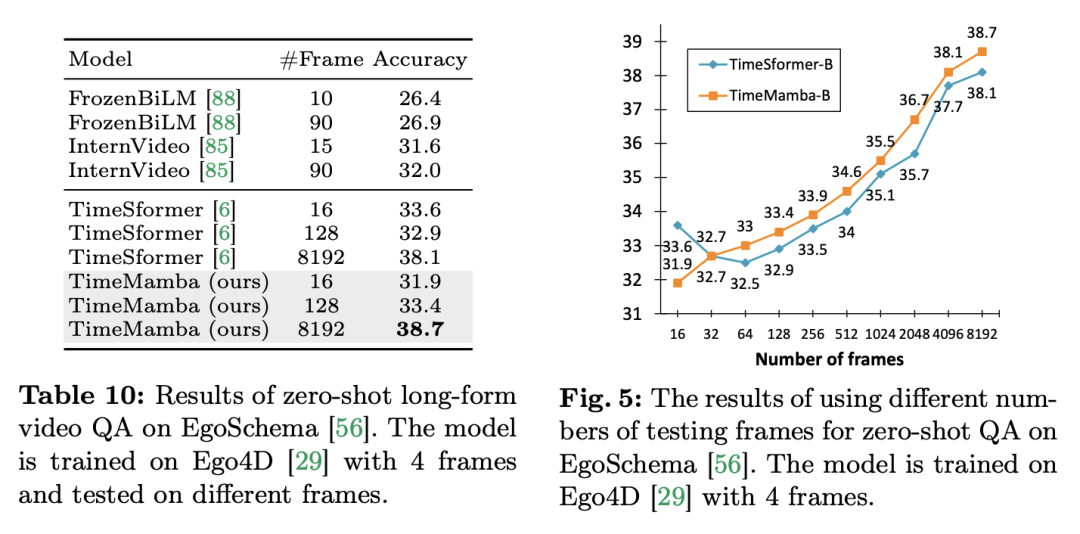
TimeSformer と TimeMamba はどちらも、Ego4D で事前トレーニングした後、大規模な事前トレーニングされたモデル (InternVideo など) のパフォーマンスを超えます。さらに、研究チームは、ViM ブロックの長いビデオ時間モデリング機能の影響を調査するために、固定 FPS のビデオから開始してテスト フレームの数を継続的に増加しました。どちらのモデルも 4 フレームで事前トレーニングされていますが、TimeMamba と TimeSformer のパフォーマンスはフレーム数が増加するにつれて着実に向上します。一方、8192 フレームを使用すると、大幅な改善が見られます。入力フレームが 32 を超えると、一般に TimeMamba は TimeSformer よりも多くのフレームから恩恵を受けます。これは、時間的セルフアテンションにおける Temporal ViM ブロックの優位性を示しています。 タスクとデータ: さらに、この論文では、時空間モデリング、特にEpic-KitchensにおけるMambaの機能も評価しています。モデルのパフォーマンスゼロショットのマルチインスタンス検索では、100 個のデータセットで評価されました。 ベースラインと競合他社: ViViT と TimeSformer は、空間的注意を伴う ViT を時空間的統合注意を伴うモデルに変換することを研究しています。これに基づいて、研究チームはViMモデルの空間選択的スキャニングをさらに拡張し、時空間選択的スキャニングを含めました。この拡張モデルに ViViM という名前を付けます。研究チームは、初期化に ImageNet-1K で事前トレーニングされた ViM モデルを使用しました。 ViM モデルには、フラット トークン シーケンスの中央に挿入される cls トークンが含まれています。 下の図は、ViM モデルを ViViM に変換する方法を示しています。 M フレームを含む特定の入力の場合、各フレームに対応するトークン シーケンスの中央に cls トークンを挿入します。さらに、研究チームは時間的位置の埋め込みを追加し、フレームごとにゼロに初期化しました。次に、平坦化されたビデオ シーケンスが ViViM モデルに入力されます。モデルの出力は、各フレームの cls トークンの平均を計算することによって取得されます。 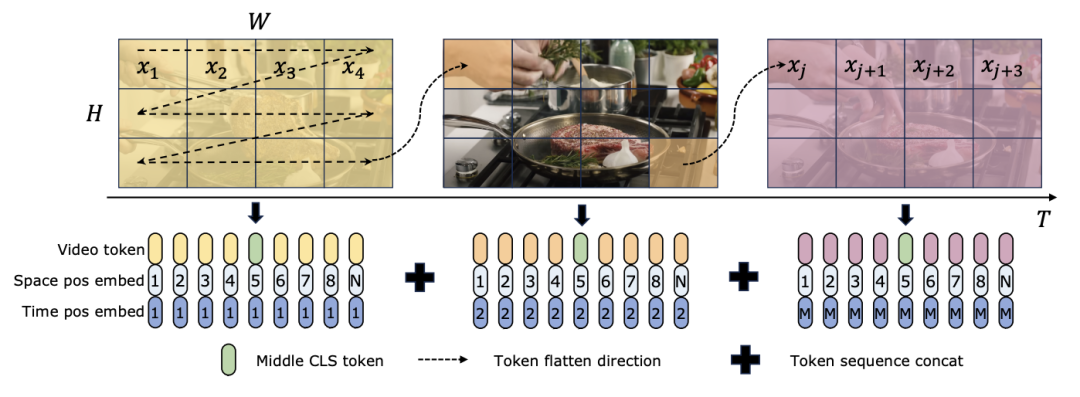
結果と分析: この論文では、ゼロサンプルのマルチインスタンス検索における ViViM の結果をさらに研究しています。実験結果を次の表に示します。時間モデルは、ゼロサンプルのマルチインスタンス取得を実行します。取得時のパフォーマンス。どちらも ImageNet-1K で事前トレーニングされた ViT と ViViM を比較すると、ViViM が ViT よりも優れていることがわかります。興味深いことに、ImageNet-1K での ViT-S と ViM-S のパフォーマンスの差は小さい (79.8 対 80.5) にもかかわらず、ViViM-S はゼロショット マルチインスタンス取得 (+2.1 mAP @Avg) で大幅な向上を示しています。 ViViM は長いシーケンスのモデリングに非常に効果的であり、パフォーマンスが向上します。 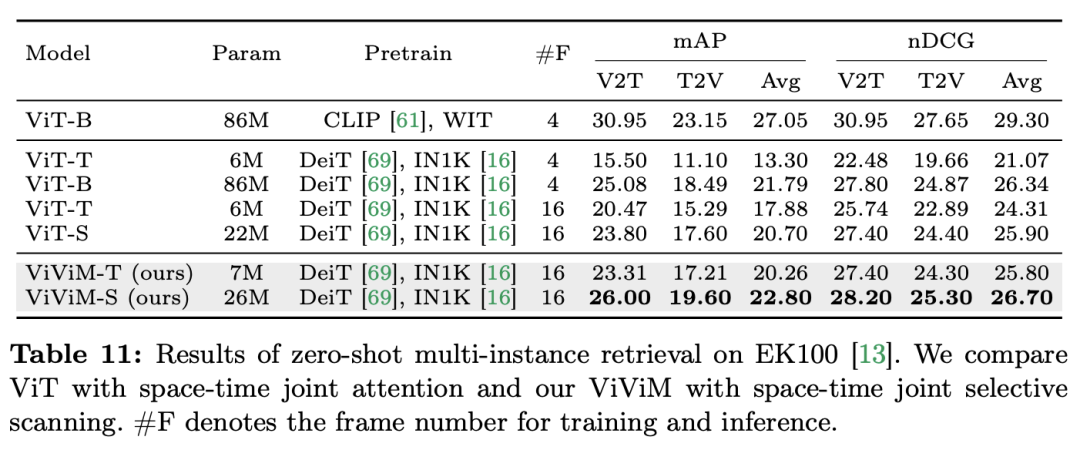
結論
この論文は、ビデオ理解の分野におけるパフォーマンスを包括的に評価することにより、従来のトランスフォーマーの実行可能な代替手段としての Mamba の可能性を実証します。研究チームは、12 のビデオ理解タスク用の 14 のモデル/モジュールで構成される Video Mamba Suite を通じて、複雑な時空間ダイナミクスを効率的に処理する Mamba の能力を実証しました。 Mamba は優れたパフォーマンスを提供するだけでなく、より優れた効率とパフォーマンスのバランスも実現します。これらの発見は、Mamba がビデオ分析タスクに適していることを強調するだけでなく、コンピューター ビジョンの分野での応用に新たな道を開くものでもあります。今後の研究では、Mamba の適応性をさらに調査し、その有用性をより複雑なマルチモーダルビデオ理解の課題に拡張することができます。 以上が12 のビデオ理解タスクで、マンバが初めてトランスフォーマーを破りましたの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。



















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



