4 月 27 日に開催された中関村フォーラム一般 人工知能 パラレル フォーラムで、人民大学科学技術学部発のスタートアップ企業である Sophon Engine が新しいマルチモーダル大型モデルを盛大にリリースしました。 Awaker 1.0 は、AGI ステップに向けた重要なステップです。 前世代の Sophon エンジンの ChatImg シーケンス モデルと比較して、Awaker 1.0 は新しい MOE アーキテクチャを採用し、独立して更新する機能を備えています。業界で「真の」独立したマルチモーダルな大規模モデルを実現します。 ビジュアル生成の点では、Awaker 1.0 は完全に自社開発したビデオ生成ベース VDT を使用しており、写真ビデオ生成において Sora よりも優れた結果を達成し、「最後のステップ」を突破します。大型モデルの「キロメートル」は着陸が困難です。 
Awaker 1.0 は、視覚的な理解と視覚的な生成を超統合した大規模なマルチモーダル モデルです。理解側では、Awaker 1.0 はデジタル世界と現実世界と対話し、タスクの実行中にシーンの動作データをモデルにフィードバックして、生成側での継続的な更新とトレーニングを実現します。Awaker 1.0 は高品質のマルチパフォーマンスを生成できます。モーダル コンテンツは、現実世界をシミュレートし、理解側モデルにさらに多くのトレーニング データを提供します。 特に重要なことは、Awaker 1.0 はその「本物の」自律アップデート機能により、より幅広い業界シナリオに適しており、より複雑な実践的なタスクを解決できることです。 AIエージェント、身体化インテリジェンス、総合管理、セキュリティ検査など。 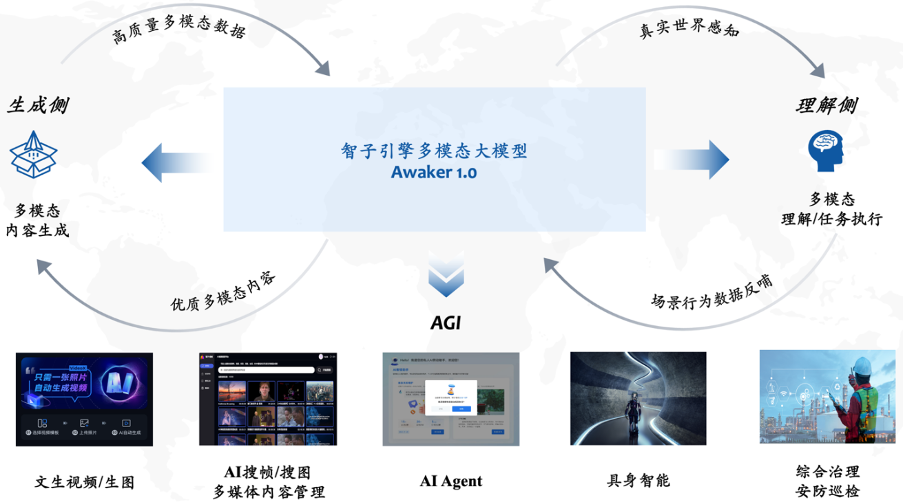
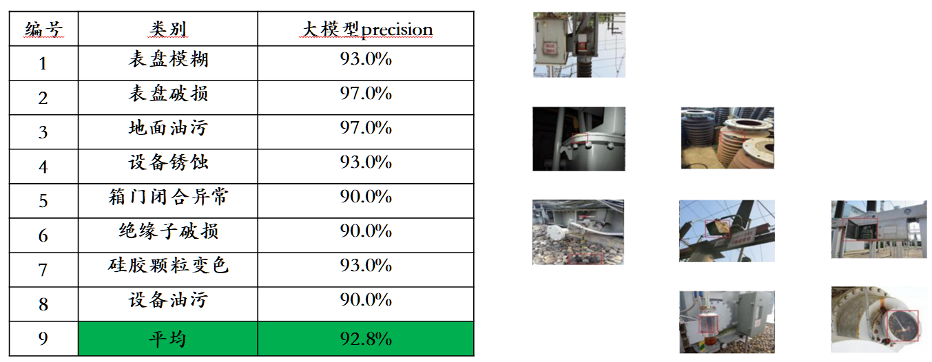
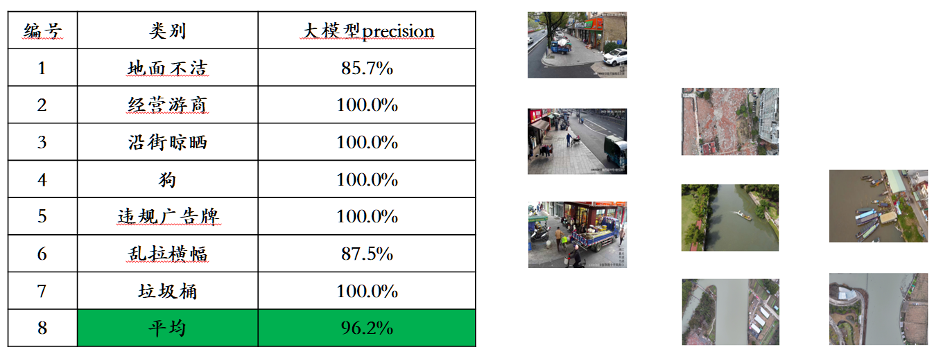
理解面では、Awaker 1.0 のベースシート モデルは主に、マルチモーダルおよびマルチタスクの事前トレーニングにおける深刻な競合の問題を解決します。慎重に設計されたマルチタスク MOE アーキテクチャの恩恵を受け、Awaker 1.0 のベース モデルは、Sophon Engine の前世代のマルチモーダル大規模モデル ChatImg の基本機能を継承するだけでなく、各マルチモーダル タスクに必要な固有の機能を学習することもできます。 。前世代のマルチモーダル大規模モデル ChatImg と比較して、Awaker 1.0 の基本モデル機能は複数のタスクにおいて大幅に向上しました。 主流のマルチモーダル評価リストにおける評価データ漏洩の問題を考慮して、当社では厳格な基準を採用して独自の評価セットを構築しています。個人の携帯写真アルバムから来ています。このマルチモーダル評価セットでは、Awaker 1.0 および国内外の 3 つの最先端マルチモーダル大型モデルに対して公正な手動評価を実施します。詳細な評価結果は以下の表に示されています。 GPT-4V と Intern-VL は、検出タスクを直接サポートしていないことに注意してください。それらの検出結果は、モデルがオブジェクト指向を記述する言語を使用することを要求することによって取得されます。 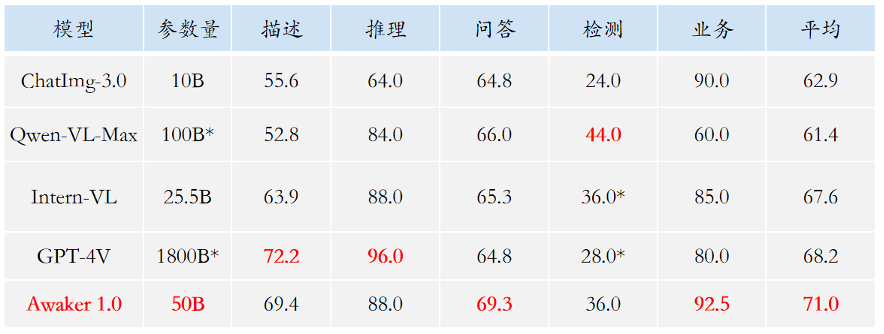
Awaker 1.0 の基本モデルは、視覚的な質問応答とビジネス アプリケーションのタスクにおいて GPT-4V、Qwen-VL-Max、Intern-VL を同時に上回っていることがわかりました。記述、推論、検出タスクでも 2 番目に良い結果が得られました。全体として、Awaker 1.0 の平均スコアは国内外の 3 つの最も先進的なモデルを上回り、マルチタスク MOE アーキテクチャの有効性が実証されました。以下に、比較分析の具体的な例をいくつか示します。 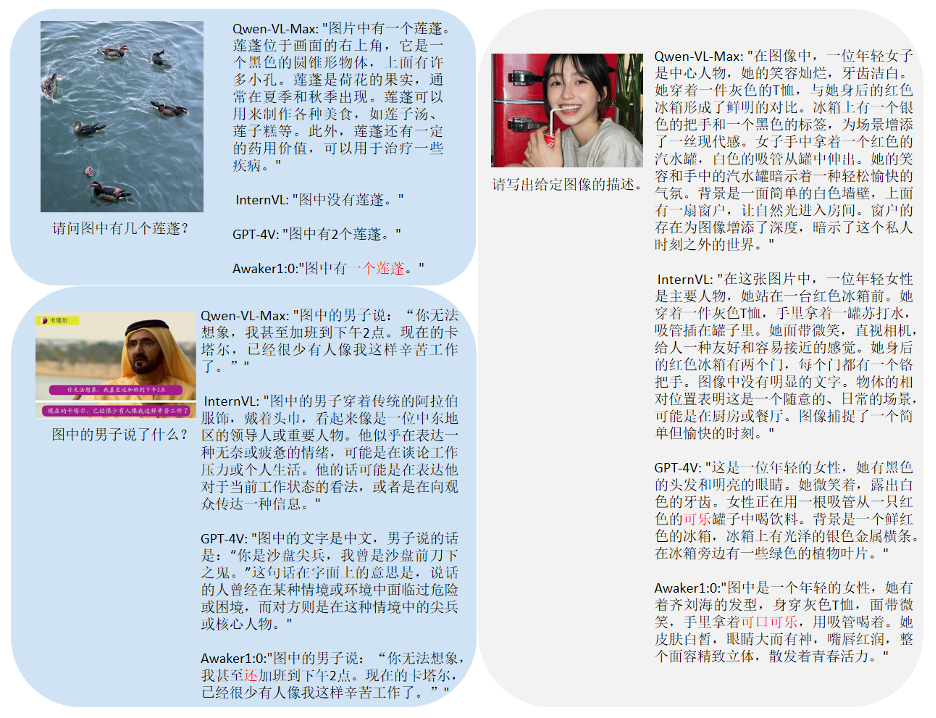
これらの比較例からわかるように、Awaker 1.0 は計数と OCR の質問に対して正しい回答を与えることができますが、他の 3 つのモデルはすべて不正解 (または部分的に不正解) です。詳細な説明タスクでは、Qwen-VL-Max は幻覚を起こしやすく、Intern-VL は画像の内容を正確に説明できますが、一部の詳細では正確さと具体性が十分ではありません。 GPT-4V と Awaker 1.0 は、画像の内容を詳細に記述するだけでなく、写真に写っているコカ・コーラなど、画像内の詳細を正確に識別することもできます。 覚醒する身体化されたインテリジェンス: AGI に向けて
マルチモダリティマルチモーダルな大型モデルの視覚的理解機能を、身体化された知能のカメラと自然に組み合わせることができるため、モデルと身体化された知能は非常に自然です。人工知能の分野では、「マルチモーダル大規模モデル身体化知能」が汎用人工知能 (AGI) を実現する実現可能な道であるとさえ考えられています。
一方で、人々は身体化されたインテリジェンスが適応可能であることを期待しています。つまり、エージェントは継続的な学習を通じて変化するアプリケーション環境に適応でき、既知の複数の環境でタスクを実行できます。 -モーダルタスクはますます良くなり、未知のマルチモーダルタスクにもすぐに適応できます。
その一方で、人々はまた、身体化された知性が真に創造的であることを期待しており、環境の自律的な探索を通じて新しい戦略や解決策を発見し、境界を探索できることを期待しています。人工知能の機能。マルチモーダルな大規模モデルを身体化された知能の「頭脳」として使用することで、身体化された知能の適応性と創造性を劇的に向上させ、最終的には AGI の閾値に近づく (または AGI を達成する) 可能性があります。
しかし、既存の大規模なマルチモーダル モデルには 2 つの明らかな問題があります。1 つ目は、モデルの反復更新サイクルが長く、多大な人的および財政的投資が必要であることです。 、モデルのトレーニング データはすべて既存のデータから派生しており、モデルは大量の新しい知識を継続的に取得することはできません。 RAG と長いコンテキストを通じて継続的な新しい知識を注入することもできますが、マルチモーダル大規模モデル自体はこれらの新しい知識を学習しないため、これら 2 つの修復方法も追加の問題を引き起こします。
つまり、現在の大規模なマルチモーダル モデルは、創造性どころか、実際のアプリケーション シナリオにもあまり適応できず、業界で実装すると常に失敗するというさまざまな問題が発生します。起きます。 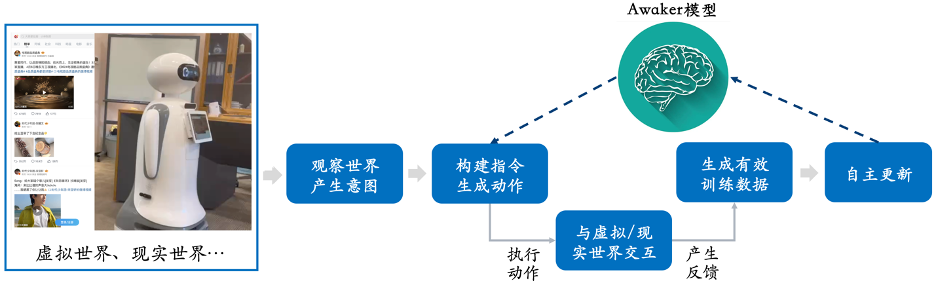 Sophon Engineが今回リリースしたAwaker 1.0は、身体化された知性の「頭脳」として活用できる、自律更新機構を備えた世界初のマルチモーダル大型モデルです。 。 Awaker 1.0 の自律更新メカニズムには、アクティブなデータ生成、モデルの反映と評価、継続的なモデル更新という 3 つの主要なテクノロジーが含まれています。
Sophon Engineが今回リリースしたAwaker 1.0は、身体化された知性の「頭脳」として活用できる、自律更新機構を備えた世界初のマルチモーダル大型モデルです。 。 Awaker 1.0 の自律更新メカニズムには、アクティブなデータ生成、モデルの反映と評価、継続的なモデル更新という 3 つの主要なテクノロジーが含まれています。
他の大規模なマルチモーダル モデルとは異なり、Awaker 1.0 は「ライブ」であり、そのパラメーターはリアルタイムで継続的に更新できます。
上記のフレーム図からわかるように、Awaker 1.0 はさまざまなスマート デバイスと組み合わせることができ、スマート デバイスを通じて世界を観察し、行動意図を生成し、コマンドを自動的に構築します。スマートデバイスを制御してさまざまなアクションを実行します。スマートデバイスは、さまざまなアクションを完了すると、さまざまなフィードバックを自動的に生成します。Awaker 1.0 は、これらのアクションとフィードバックから効果的なトレーニング データを取得し、継続的に自己更新し、モデルのさまざまな機能を継続的に強化します。
新しい知識の注入を例に挙げると、Awaker 1.0 はインターネット上の最新のニュース情報を継続的に学習し、新しく学習したニュース情報に基づいてさまざまな複雑な質問に答えることができます。 RAG やロングコンテキストの従来の方法とは異なり、Awaker 1.0 は真に新しい知識を学習し、モデルのパラメーターを「記憶」することができます。 上記の例からわかるように、Awaker 1.0 は 3 日間連続で自己更新することで、毎日その日のニュース情報を学習し、質問に答えるときに対応する情報を正確に話すことができます。同時に、Awaker 1.0 は継続的な学習プロセス中に学習した知識を忘れません。たとえば、Wisdom S7 の知識は 2 日後でも Awaker 1.0 によって記憶されているか、理解されています。 Awaker 1.0 は、さまざまなスマート デバイスと組み合わせて、クラウド エッジのコラボレーションを実現することもできます。 Awaker 1.0は、さまざまなエッジスマートデバイスを制御してさまざまなタスクを実行するための「頭脳」としてクラウドにデプロイされます。エッジ スマート デバイスがさまざまなタスクを実行するときに得られるフィードバックは、Awaker 1.0 に継続的に送信され、トレーニング データを継続的に取得し、自身を継続的に更新できるようになります。  上記のクラウド エッジ コラボレーションの技術的ルートは、電力網やスマート シティのインテリジェントな検査などのアプリケーション シナリオに適用され、従来の小型モデルよりもはるかに優れた認識結果を達成しました。 、業界の顧客から高い評価を得ています。
上記のクラウド エッジ コラボレーションの技術的ルートは、電力網やスマート シティのインテリジェントな検査などのアプリケーション シナリオに適用され、従来の小型モデルよりもはるかに優れた認識結果を達成しました。 、業界の顧客から高い評価を得ています。
#Real World Simulator: VDT
# 世代##Awaker 1.0 の側面は、Sophon Engine が独自に開発した Sora 風のビデオ生成ベース VDT であり、現実世界のシミュレーターとして使用できます。 VDTの研究結果は、OpenAIがSoraをリリースする10か月前の2023年5月にarXivのWebサイトで公開された。 VDTの学術論文が人工知能のトップ国際会議であるICLR 2024に採択されました。 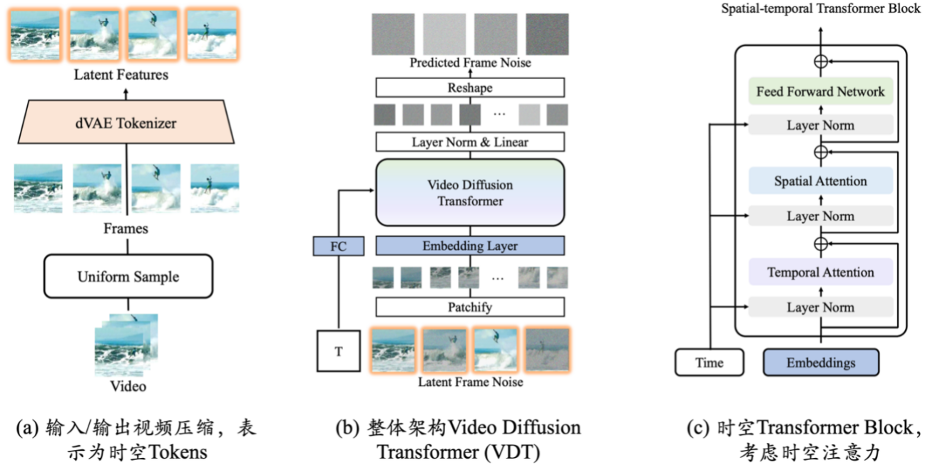 #ビデオ生成ベース VDT の革新には、主に次の側面が含まれます。
#ビデオ生成ベース VDT の革新には、主に次の側面が含まれます。
適用Transformer テクノロジーによる拡散ベースのビデオ生成は、ビデオ生成の分野における Transformer の大きな可能性を示しています。 VDT の利点は、優れた時間依存キャプチャ機能であり、時間の経過に伴う 3 次元オブジェクトの物理ダイナミクスのシミュレーションなど、時間的にコヒーレントなビデオ フレームの生成を可能にします。 VDT がさまざまなビデオ生成タスクを処理できるようにするための、統合された時空間マスク モデリング メカニズムを提案し、この技術の幅広い応用を実現します。単純なトークン空間スプライシングなどの VDT の柔軟な条件付き情報処理方法は、さまざまな長さや形式の情報を効果的に統合します。同時に、時空間マスク モデリング メカニズムと組み合わせることで、VDT は普遍的なビデオ拡散ツールとなり、無条件生成、ビデオの後続フレーム予測、フレーム補間、画像生成ビデオ、およびビデオ フレームを変更することなく適用できます。モデル構造の完成およびその他のビデオ生成タスク。
私たちは、VDT による単純な物理法則のシミュレーションの探索に焦点を当て、Physion データセットで VDT をトレーニングしました。以下の例では、VDT が放物線の軌道に沿って移動するボールや、平面上を転がって他の物体と衝突するボールなどの物理プロセスをうまくシミュレートしていることがわかります。同時に、2 行目の 2 番目の例からは、ボールが衝撃不足で柱を倒すことがなかったため、VDT がボールの速度と勢いを捉えていることもわかります。これは、Transformer アーキテクチャが特定の物理法則を学習できることを証明しています。 また、写真ビデオ生成タスクについても徹底的に調査しました。私たちはもともと顔やキャラクターの動的な変化に敏感であるため、このタスクではビデオ生成の品質に対する非常に高い要件が求められます。このタスクの特殊性を考慮すると、VDT (または Sora) と制御可能な生成を組み合わせて、写真ビデオ生成の課題に対処する必要があります。現在、Sophon エンジンはフォト ビデオ生成の主要テクノロジーのほとんどを突破し、Sora よりも優れたフォト ビデオ生成品質を実現しています。 Sophon エンジンは今後も制御可能なポートレート生成アルゴリズムの最適化を進め、商用化も積極的に検討していきます。現時点では、確実な商業着陸シナリオが発見されており、近い将来、大型モデルの着陸における「ラストワンマイル」の困難を打破すると期待されている。  将来的には、より汎用性の高い VDT が、マルチモーダルな大規模モデル データ ソースの問題を解決する強力なツールになるでしょう。ビデオ生成を使用することで、VDT は現実世界をシミュレートし、ビジュアル データ作成の効率をさらに向上させ、マルチモーダル大型モデル Awaker の独立した更新を支援できるようになります。
将来的には、より汎用性の高い VDT が、マルチモーダルな大規模モデル データ ソースの問題を解決する強力なツールになるでしょう。ビデオ生成を使用することで、VDT は現実世界をシミュレートし、ビジュアル データ作成の効率をさらに向上させ、マルチモーダル大型モデル Awaker の独立した更新を支援できるようになります。
##Awaker 1.0 は、Sophon エンジン チームの最終目標です。 AGI」 目標に向けた重要な一歩。研究チームは、自己探索や内省などの AI の自律学習能力が知能レベルの重要な評価基準であり、パラメーター サイズの継続的な増加 (スケーリング則) と同様に重要であると考えています。 Awaker 1.0は、「アクティブなデータ生成、モデルの反映と評価、継続的なモデル更新」などの主要な技術フレームワークを実装しており、理解側と生成側の両方でブレークスルーを達成し、マルチモーダル大規模な開発を加速することが期待されています。産業をモデル化し、最終的には人間が AGI を実現できるようにします。
以上が全国人民代表大会のマルチモーダルモデルがAGIに移行:初めて独立した更新を実現し、写真ビデオの生成はSoraを超えるの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。



















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



