大規模モデルと AI データベースの組み合わせは、大規模モデルと真にインテリジェントなビッグデータのコスト削減と効率向上のための魔法の武器になりました。

大型モデル (LLM) の波は 1 年以上にわたって押し寄せており、特に GPT-4、Gemini-1.5、Claude- 3 You Fang と私が代表するモデルがステージに登場し、当然の注目の的になります。 LLM トラックでは、モデル パラメーターの増加に焦点を当てた研究もあれば、マルチモダリティに夢中になっている研究もあります...その中でも、コンテキストの長さを処理する LLM の能力は、モデルを評価するための重要な指標となっています。コンテキストが強いということは、モデルがより強力なリトリーブ性能。たとえば、一部のモデルは一度に最大 100 万個のトークンを処理できるため、多くの研究者は RAG (検索拡張生成) 手法が依然として必要かどうかを検討するようになりました。 RAG はロング コンテキスト モデルによって消滅すると考える人もいますが、この見解は多くの研究者やアーキテクトによって反論されています。彼らは、一方で、データ構造は複雑で定期的に変化し、多くのデータには重要な時間次元があり、LLM には複雑すぎる可能性があると考えています。一方で、企業や業界の膨大な異種データをすべてコンテキスト ウィンドウに入れるのは非現実的です。大規模なモデルと AI データベースを組み合わせることで、専門的で正確なリアルタイム情報が AI 生成システムに注入され、錯覚が大幅に軽減され、システムの実用性が向上します。同時に、データ中心の LLM メソッドは、AI データベースの大規模なデータ管理とクエリ機能を活用して、大規模なモデルのトレーニングと微調整のコストを大幅に削減し、さまざまなシナリオでの小規模なサンプルの調整をサポートすることもできます。システム。要約すると、大規模モデルと AI データベースの組み合わせにより、コストが削減され、大規模モデルの効率が向上するだけでなく、ビッグデータが真にインテリジェントになります。 数年間の開発と反復を経て、MyScaleDB がついにオープンソースになりました RAG の出現により、LLM は大規模な知識ベースから情報を正確に抽出し、リアルタイムで専門的かつ洞察力に富んだ回答を生成できるようになりました。これに伴い、RAGシステムの中核機能であるベクトルデータベースも急速に発展しており、ベクトルデータベースの設計思想によれば、専用のベクトルデータベース、キーワードとベクトルを組み合わせた検索システム、 SQL ベクトル データベース。
- Pinecone/Weaviate/Milvus に代表される特化したベクトル データベースは、最初からベクトル検索を目的として設計、構築されており、ベクトル検索性能は優れていますが、普遍的ではないし、データ管理機能も弱い。
- Elasticsearch/OpenSearch に代表されるキーワードおよびベクトル検索システムは、キーワード検索機能が充実しているため、本番環境で広く使用されていますが、多くのシステム リソースとキーワードとベクトルを占有します。結合クエリの精度とパフォーマンスは満足のいくものではありません。
- pgvector (PostgreSQL 用ベクター検索プラグイン) や MyScale AI データベースに代表される SQL ベクター データベースは SQL をベースにしており、強力なデータ管理機能を備えています。ただし、PostgreSQL 行ストレージの欠点とベクトル アルゴリズムの制限により、pgvector は複雑なベクトル クエリの精度が低くなります。
MyScale AI データベース (MyScaleDB) 高性能 SQL 列ストレージ データベースをベースとし、高性能と高データを備えた自社開発密度ベクトル インデックス アルゴリズム、検索およびストレージ エンジンは、SQL とベクトルの共同クエリ向けに深く開発され、最適化されています。 は、専用ベクトルの総合的なパフォーマンスと費用対効果を大幅に上回る世界初の SQL ベクトル データベース製品です。データベース。 大規模な構造化データ シナリオにおける SQL データベースの長期にわたる磨きのおかげで、MyScaleDB は文字列を含む大規模なベクトルと構造化データの両方をサポートします。効率的です。 JSON、空間、時系列などの複数のデータ型のストレージとクエリをサポートしており、RAG システムの精度をさらに向上させ、Elasticsearch などのシステムを置き換えるために、強力な転置テーブルとキーワード検索機能を近い将来リリースする予定です。 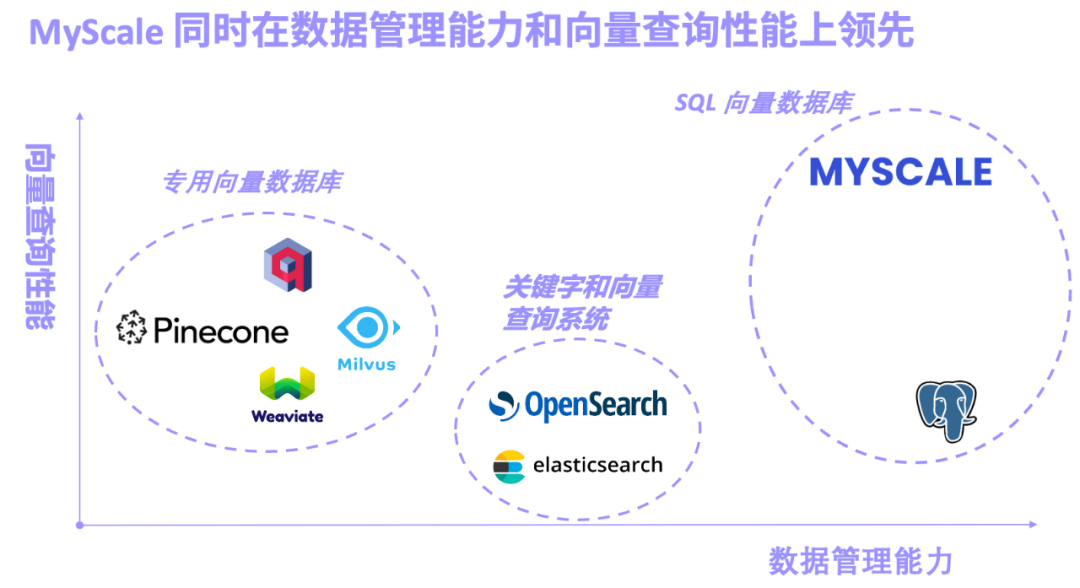
 6 年近くの開発といくつかのバージョンの反復を経て、MyScaleDB は最近オープンソースになりました。すべての開発者と企業ユーザーは GitHub に参加して、SQL を使用して運用レベルの AI アプリケーションを構築する新しい方法を切り開くことを歓迎します。 プロジェクト アドレス: https://github.com/myscale/myscaledbSQL と完全な互換性があり、改善されました精度、コスト削減完全な SQL データ管理機能、強力かつ効率的な構造化、ベクトルおよび異種混合データ ストレージとクエリ機能の助けを借りて、MyScaleDB は次のことを行うことが期待されています。大規模モデルとビッグデータを真に指向した最初の AI データベース になります。 SQL の誕生から半世紀、NoSQL やビッグ データなどの波にさらされているにもかかわらず、進化し続ける SQL データベースは依然としてデータ管理市場で大きなシェアを占めており、Elasticsearch や Spark などの検索およびビッグ データ システムでも SQL インターフェイスが次々とサポートされています。専用のベクトル データベースはベクトル用に最適化され、システムが設計されていますが、通常、そのクエリ インターフェイスには標準化が欠けており、高度なクエリ言語がありません。その結果、インターフェイスの汎化機能が弱くなります。たとえば、Pinecone のクエリ インターフェイスには、ページングや集計などの一般的なデータベース機能はおろか、取得するフィールドの指定さえ含まれていません。 #インターフェースの汎化能力が弱いということは、インターフェースが頻繁に変更されることを意味し、学習コストが増加します。 MyScale チームは、体系的に最適化された SQL およびベクトル システムにより、ベクトル検索の高いパフォーマンスを確保しながら完全な SQL サポートを維持できると信じており、オープンソース評価の結果がこれを十分に実証しています。
6 年近くの開発といくつかのバージョンの反復を経て、MyScaleDB は最近オープンソースになりました。すべての開発者と企業ユーザーは GitHub に参加して、SQL を使用して運用レベルの AI アプリケーションを構築する新しい方法を切り開くことを歓迎します。 プロジェクト アドレス: https://github.com/myscale/myscaledbSQL と完全な互換性があり、改善されました精度、コスト削減完全な SQL データ管理機能、強力かつ効率的な構造化、ベクトルおよび異種混合データ ストレージとクエリ機能の助けを借りて、MyScaleDB は次のことを行うことが期待されています。大規模モデルとビッグデータを真に指向した最初の AI データベース になります。 SQL の誕生から半世紀、NoSQL やビッグ データなどの波にさらされているにもかかわらず、進化し続ける SQL データベースは依然としてデータ管理市場で大きなシェアを占めており、Elasticsearch や Spark などの検索およびビッグ データ システムでも SQL インターフェイスが次々とサポートされています。専用のベクトル データベースはベクトル用に最適化され、システムが設計されていますが、通常、そのクエリ インターフェイスには標準化が欠けており、高度なクエリ言語がありません。その結果、インターフェイスの汎化機能が弱くなります。たとえば、Pinecone のクエリ インターフェイスには、ページングや集計などの一般的なデータベース機能はおろか、取得するフィールドの指定さえ含まれていません。 #インターフェースの汎化能力が弱いということは、インターフェースが頻繁に変更されることを意味し、学習コストが増加します。 MyScale チームは、体系的に最適化された SQL およびベクトル システムにより、ベクトル検索の高いパフォーマンスを確保しながら完全な SQL サポートを維持できると信じており、オープンソース評価の結果がこれを十分に実証しています。
実際の複雑な AI アプリケーション シナリオでは、SQL とベクトルを組み合わせることで、データ モデリングの柔軟性が大幅に向上し、開発プロセスを簡素化できます。たとえば、MyScale チームと北京科学知能研究所が協力する Science Navigator プロジェクトでは、MyScaleDB を使用して大規模な科学文献データを取得し、インテリジェントな質問応答を実行します。10 を超える主要な SQL テーブル構造があり、その多くは確立されています。ベクトル、テーブルインデックスを反転し、主キーと外部キーを使用して関連付けを行います。実際のクエリでは、システムには構造化データ、ベクトル データ、キーワード データの結合クエリや、複数のテーブルの関連クエリも含まれます。これらのモデリングと相関関係は、専用のベクトル データベースで実現するのが難しく、最終システムの反復が遅くなり、クエリが非効率になり、メンテナンスが難しくなります。
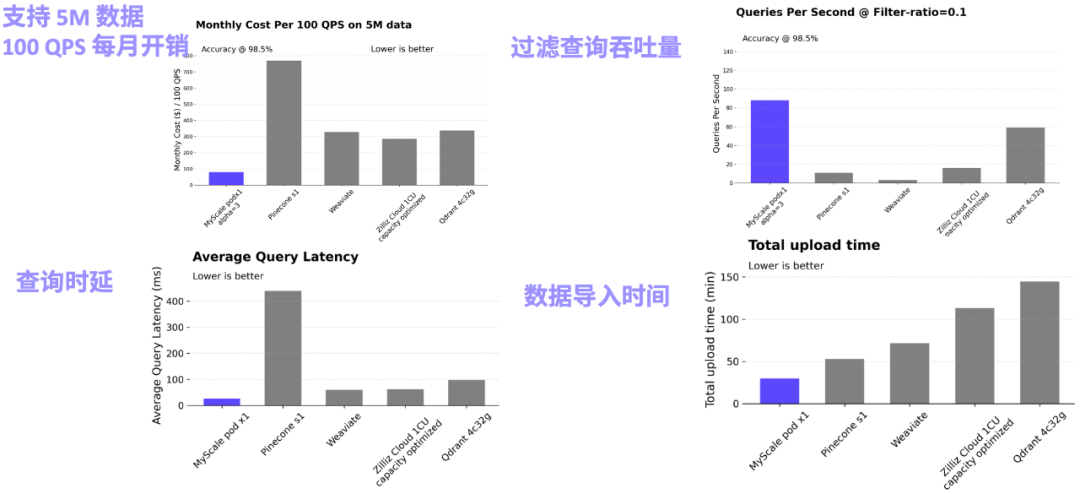
Science Navigator のメイン テーブル構造図 (太字の列はベクトル インデックスまたは逆インデックスを設定します) 次の共同クエリをサポート構造化データ、ベクトル データ、キーワード データ実際の RAG システムでは、取得の精度と効果が実装を制限する主なボトルネックとなっています。これには、AI データベースが構造化データ、ベクトル データ、キーワード データの結合クエリを効率的にサポートし、検索精度を包括的に向上させる必要があります。 たとえば、財務シナリオでは、ユーザーはドキュメント ライブラリに対して「2023 年の特定の企業のグローバル ビジネスの収益はいくらですか?」、「ある企業のグローバル ビジネスの収益はいくらですか?」というクエリを実行する必要があります。 「会社」、「2023 年」、およびその他の構造化されたメタ情報はベクトルによってうまく捉えることができず、対応する段落に直接反映されない場合もあります。データベース全体に対して直接ベクトル検索を実行すると、大量のノイズ情報が取得され、システムの最終的な精度が低下します。一方、会社名や年などは文書のメタ情報として取得できることが多いので、ベクトルクエリのフィルタ条件として WHERE year=2023 AND company ILIKE "%%" を使用することで、正確に位置を特定し、関連情報が得られるため、システムの信頼性が大幅に向上します。金融、製造、科学研究、その他のシナリオにおいて、MyScale チームは異種データ モデリングと関連クエリの力を観察してきました。多くのシナリオでは、精度は 60% から 90%## にも達します。 # 改善。 従来のデータベース製品は、AI 時代におけるベクトル クエリの重要性を徐々に認識し、データベースにベクトル機能を追加し始めていますが、クエリの精度には依然として大きな問題があります。彼らの共同の質問。たとえば、クエリをフィルタリングするシナリオでは、フィルタリング率が 0.1 の場合、Elasticsearch の QPS はわずか約 5 に低下しますが、PostgresSQL (pgvector プラグインを使用) の検索精度はフィルタリング時の約 50% にすぎません。比率が 0.01 であるため、クエリが不安定になり、精度とパフォーマンスによってアプリケーション シナリオが大幅に制限されます。また、MyScale は、pgvector のコストの 36% と ElasticSearch のコストの 12% のみを使用して、 さまざまなフィルタリング率のさまざまなシナリオで 高パフォーマンスおよび高精度の クエリを実現します。
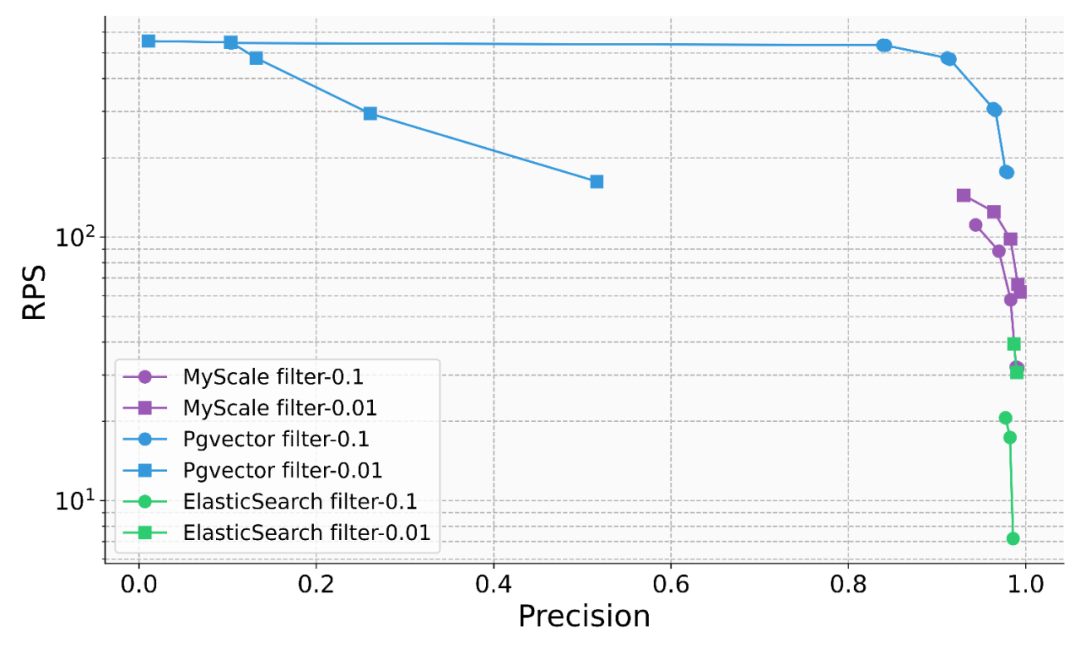 さまざまなフィルタリング割合のシナリオで、myscale は高精度かつ高性能のクエリを実現します 実際のシナリオにおけるパフォーマンスとコストのバランス大規模なモデル アプリケーションではベクトル検索の重要性と注目度が高いため、さらに多くのことが必要になります。詳細 チームはベクトル データベース トラックに投資しました。誰もが最初に純粋なベクトル検索シナリオで QPS を改善することに焦点を当てていましたが、純粋なベクトル検索では十分とは程遠いです!実際の戦闘シナリオでは、データ モデリング、クエリの柔軟性と精度、データ密度、クエリのパフォーマンス、コストのバランスがより重要な問題になります。
さまざまなフィルタリング割合のシナリオで、myscale は高精度かつ高性能のクエリを実現します 実際のシナリオにおけるパフォーマンスとコストのバランス大規模なモデル アプリケーションではベクトル検索の重要性と注目度が高いため、さらに多くのことが必要になります。詳細 チームはベクトル データベース トラックに投資しました。誰もが最初に純粋なベクトル検索シナリオで QPS を改善することに焦点を当てていましたが、純粋なベクトル検索では十分とは程遠いです!実際の戦闘シナリオでは、データ モデリング、クエリの柔軟性と精度、データ密度、クエリのパフォーマンス、コストのバランスがより重要な問題になります。
RAG シナリオでは、純粋なベクトル クエリのパフォーマンスが 10 倍を超え、ベクトルは膨大なリソースを占有し、結合クエリ関数が欠如し、パフォーマンスと精度が低下するのは、多くの場合、現在のパフォーマンスの結果です。独自のベクター データベースの正常性。 MyScaleDB は、実際の大規模データ シナリオにおける AI データベースの総合的なパフォーマンスの向上に取り組んでいます .その MyScale Vector Database Benchmark は、500 万ベクトルのスケールで主流のベクトル データベース システムを比較する業界初の製品でもあり、さまざまなクエリ シナリオ パフォーマンスと費用対効果を評価するオープンソースの評価システムです。誰もが注目し、問題を提起することができます。 MyScaleチームは、実際のアプリケーションシナリオではAIデータベースを最適化する余地がまだたくさんあるとし、今後も製品を磨き続け、実際の評価システムを改善していきたいと述べた。
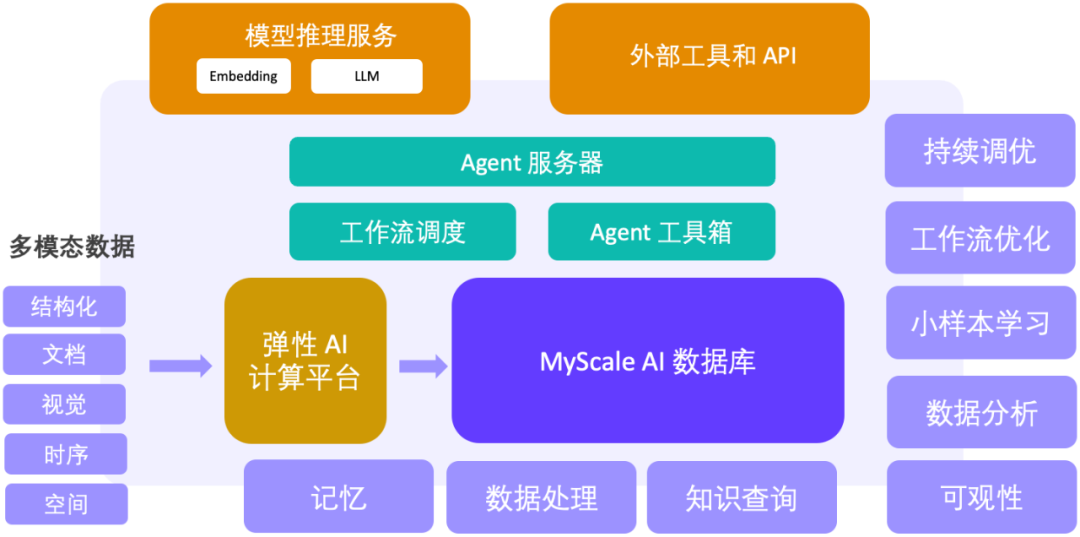
#MyScale Vector Database Benchmark プロジェクトのアドレス: https://github.com/myscale/vector-db-benchmark Outlook: AI データベースによってサポートされるビッグ モデル ビッグ データ エージェント プラットフォーム 機械学習ビッグ データがインターネットとインターネット 情報システムの世代の成功と大規模モデルの時代の文脈において、MyScale チームは新世代の大規模モデルとビッグ データ ソリューションの提案にも取り組んでいます。 高性能 SQL ベクトル データベース を強固なサポートとして使用する MyScaleDB は、大規模なデータ処理、ナレッジ クエリ、可観測性、データ分析、小規模サンプル学習の主要な機能を提供し、AI とデータの閉ループを構築します。 次世代ビッグモデルビッグデータエージェントプラットフォームの重要な基盤となります。 MyScale チームはすでに、科学研究、金融、産業、医療、その他の分野でこのソリューションの実装を検討しています。
テクノロジーの急速な発展に伴い、今後 5 ~ 10 年以内に、ある種の汎用人工知能 (AGI) が登場すると予想されます。この問題に関して、私たちは考えずにはいられません。静的で仮想的で人間と競合する大規模なモデルが必要なのでしょうか、それとも別のより包括的な解決策があるのでしょうか?データは間違いなく、大規模なモデル、世界、ユーザーの間の重要なリンクです。MyScale チームのビジョンは、大規模なモデルとビッグ データを有機的に組み合わせて、よりプロフェッショナルで、リアルタイムで、共同作業で効率的な AI システムを作成することです。人間の温かさと価値に満ちています。 ###
以上が長いテキストは RAG を殺すことはできません: SQL+ ベクトルは大規模モデルとビッグ データの新しいパラダイムを推進し、MyScale AI データベースは正式にオープンソースになりますの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
































![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



