


Google が推進する JAX のパフォーマンスは、最近のベンチマーク テストで Pytorch や TensorFlow のパフォーマンスを上回り、7 つの指標で 1 位にランクされました。

そして、最高の JAX パフォーマンスを備えた TPU ではテストは完了しませんでした。

現在、開発者の間では、Pytorch の方が Tensorflow よりも人気があります。
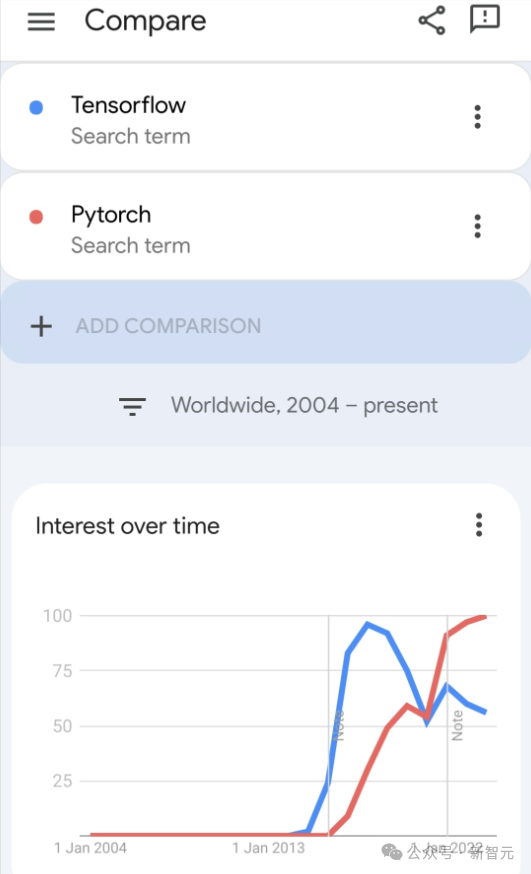
しかし、将来的には、おそらくより大規模なモデルが JAX プラットフォームに基づいてトレーニングされ、実行されるようになるでしょう。
最近、Keras チームは 3 つのバックエンド (TensorFlow、JAX、PyTorch) を実装し、ネイティブ PyTorch TensorFlow と組み合わせました。 Keras 2 のベンチマークが行われました。
まず、彼らは、生成および非生成 AI タスク用の一連の主流のコンピューター ビジョンおよび自然言語処理モデルを選択しました。

Keras バージョンのモデルの場合、KerasCV および KerasNLP の既存の実装を使用して構築されます。ネイティブ PyTorch バージョンでは、インターネットで最も人気のあるオプションを選択しました:
- HuggingFace Transformers の BERT、Gemma、Mistral
- HuggingFace ディフューザーからの StableDiffusion
# - Meta からの SegmentAnything
#彼らは、PyTorch バックエンドを使用する Keras 3 バージョンと区別するために、このモデルのセットを「ネイティブ PyTorch」と呼んでいます。
彼らはすべてのベンチマークに合成データを使用し、すべての LLM トレーニングと推論で bfloat16 精度を使用し、すべての LLM トレーニングで LoRA (微調整) を使用しました。
PyTorch チームの提案に従って、ネイティブ PyTorch 実装で torch.compile(model, mode="reduce-overhead") を使用しました (Gemma と Mistral のトレーニングを除く)非互換性があります)。
すぐに使えるパフォーマンスを測定するために、高レベルの API (HuggingFace の Trainer()、標準の PyTorch トレーニング ループ、Keras model.fit() など) を使用します。そして構成を最小限に抑えます。
ハードウェア構成すべてのベンチマーク テストは、40 GB のビデオ メモリを備えた NVIDIA A100 GPU、12 個の仮想 CPU、85 GB のホストとして構成された Google Cloud Compute Engine を使用して実施されました。メモリ。
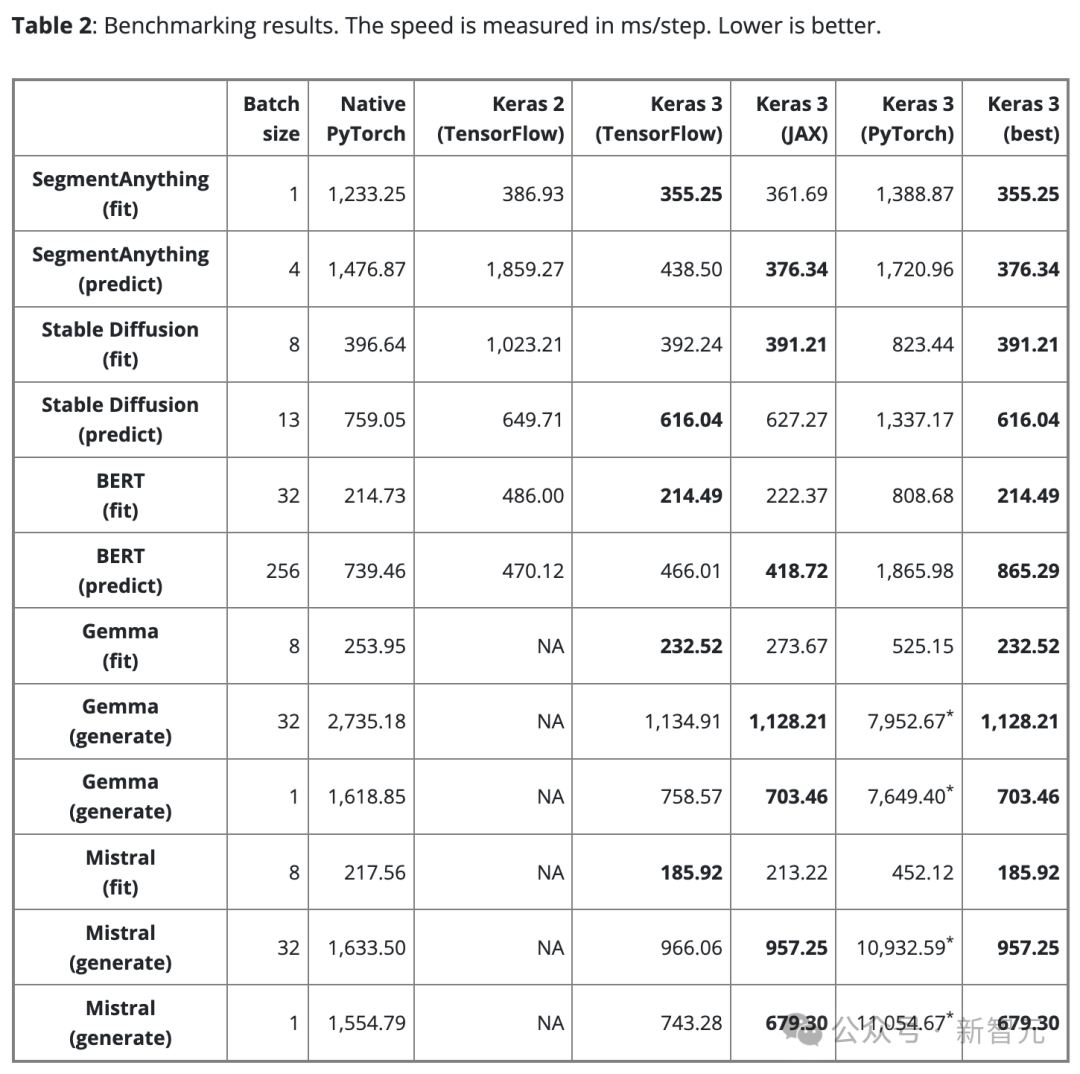
ベンチマーク結果表 2 は、ベンチマーク結果をステップ/ミリ秒で示しています。各ステップには、単一バッチのデータに対するトレーニングまたは予測が含まれます。
結果は 100 ステップの平均ですが、最初のステップにはモデルの作成とコンパイルが含まれており、余分な時間がかかるため、最初のステップは除外されます。
公平な比較を確保するために、同じモデルとタスク (トレーニングまたは推論) に対して同じバッチ サイズが使用されます。
ただし、モデルやタスクが異なると、スケールやアーキテクチャが異なるため、データ バッチ サイズが大きすぎることによるメモリ オーバーフローを避けるために、必要に応じて調整できます。サイズが小さすぎるため、GPU が十分に活用されていません。
バッチ サイズが小さすぎると、Python のオーバーヘッドが増加するため、PyTorch の動作が遅くなる可能性があります。
大規模な言語モデル (Gemma と Mistral) については、同様の数のパラメーター (7B) を持つ同じタイプのモデルであるため、テスト時に同じバッチ サイズも使用されました。
単一バッチのテキスト生成に対するユーザーのニーズを考慮して、バッチ サイズ 1 のテキスト生成についてもベンチマーク テストを実施しました。
次のことを発見してください 1
「最適な」ものはない終わり。
Keras の 3 つのバックエンドにはそれぞれ独自の強みがありますが、重要なのは、パフォーマンスの点では、どのバックエンドも常に勝てるわけではないということです。
どのバックエンドが最速であるかの選択は、多くの場合、モデルのアーキテクチャに依存します。
この点は、最適なパフォーマンスを追求するには、さまざまなフレームワークを選択することの重要性を強調しています。 Keras 3 を使用すると、バックエンドを簡単に切り替えて、モデルに最適なバックエンドを見つけることができます。
Found 2
Keras 3 のパフォーマンスは、一般に PyTorch の標準実装を超えています。
ネイティブ PyTorch と比較して、Keras 3 はスループット (ステップ/ミリ秒) が大幅に向上しています。
特に、10 個のテスト タスクのうち 5 個では、速度の向上が 50% を超えました。その中で、最も高いものは290%に達しました。
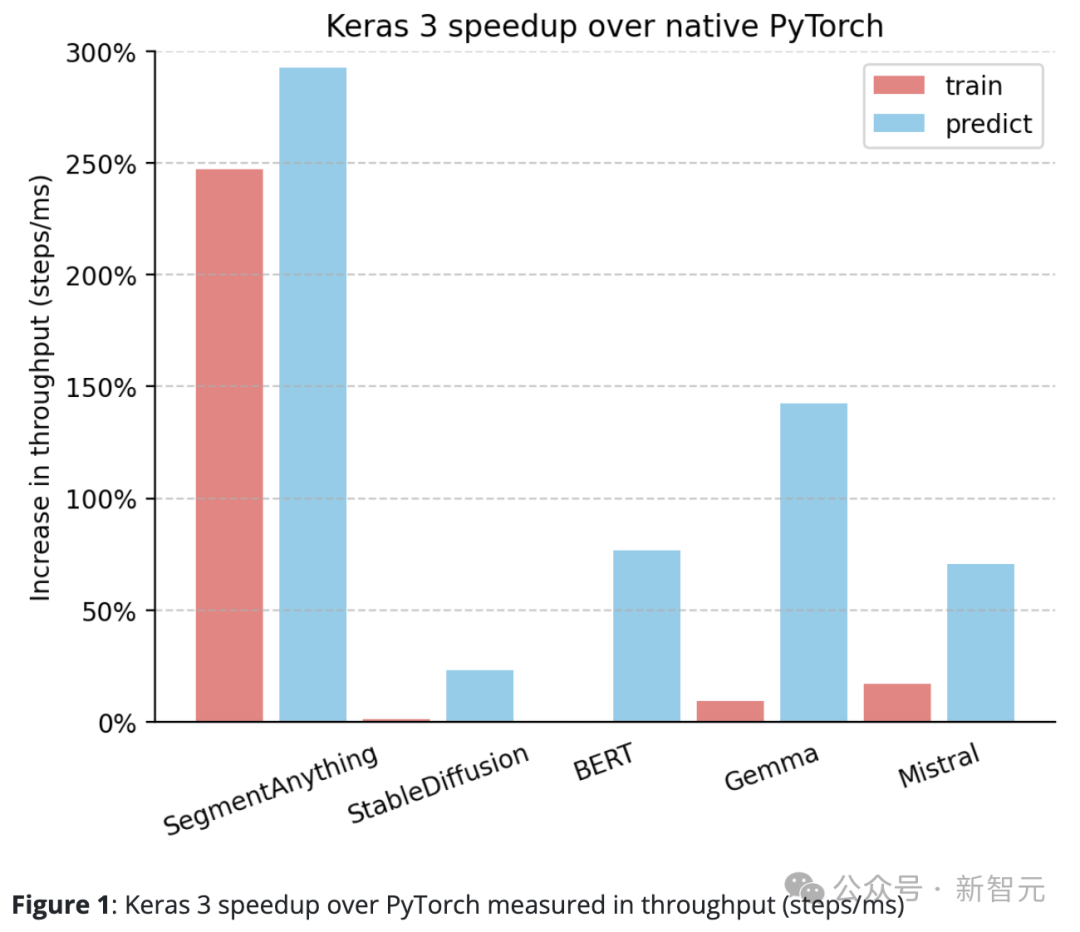
100% の場合は、Keras 3 が PyTorch の 2 倍高速であることを意味し、0% の場合は、パフォーマンスが低いことを意味します。この 2 つは同等です
Discover 3
Keras 3 は、「クラス最高のパフォーマンス」を提供します。箱"。
言い換えれば、テストに参加するすべての Keras モデルはまったく最適化されていません。対照的に、ネイティブの PyTorch 実装を使用する場合、ユーザーは通常、さらにパフォーマンスの最適化を自分で実行する必要があります。
上で共有したデータに加えて、HuggingFace Diffusers の StableDiffusion 推論機能をバージョン 0.25.0 から 0.3.0 にアップグレードすると、パフォーマンスが向上することもテスト中にわかりました。 100%以上。
同様に、HuggingFace Transformers でも、Gemma をバージョン 4.38.1 からバージョン 4.38.2 にアップグレードすると、パフォーマンスが大幅に向上しました。
これらのパフォーマンスの向上は、HuggingFace のパフォーマンスの最適化への重点と取り組みを強調しています。
SegmentAnything など、手動による最適化があまり行われない一部のモデルでは、研究著者が提供する実装が使用されます。この場合、Keras とのパフォーマンスの差は、他のほとんどのモデルよりも大きくなります。
これは、Keras がすぐに使える優れたパフォーマンスを提供でき、ユーザーはすべての最適化手法を深く掘り下げることなく、高速なモデル実行速度を享受できることを示しています。
発見 4
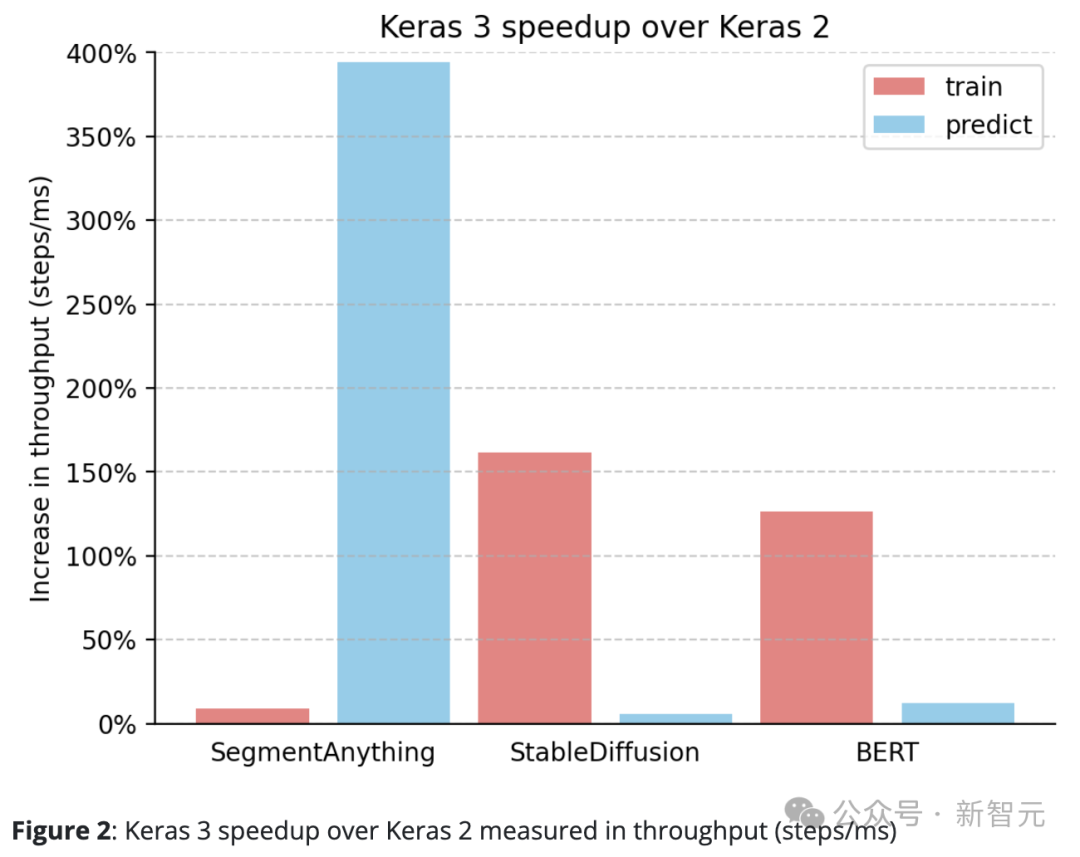
Keras 3 は常に Keras 2 を上回っています。
たとえば、SegmentAnything の推論速度は驚くべき 380% 向上し、StableDiffusion のトレーニング処理速度は 150% 以上向上し、BERT のトレーニング処理速度も 100 以上向上しました。 %。
これは主に、Keras 2 が場合によってはより多くの TensorFlow fusion 操作を直接使用するためで、これは XLA コンパイルには最適な選択ではない可能性があります。
Keras 3 にアップグレードして TensorFlow バックエンドを使い続けるだけでも、パフォーマンスが大幅に向上する可能性があることは注目に値します。
フレームワークのパフォーマンスは、使用される特定のモデルに大きく依存します。
Keras 3 は、タスクに最適なフレームワークを選択するのに役立ちます。この選択は、ほとんどの場合、Keras 2 および PyTorch 実装よりも優れたパフォーマンスを発揮します。
さらに重要なのは、Keras 3 モデルは、基礎となる複雑な最適化を行わなくても、すぐに使用できる優れたパフォーマンスを提供することです。
以上がGoogle は大喜び: JAX のパフォーマンスが Pytorch や TensorFlow を上回りました! GPU 推論トレーニングの最速の選択肢となる可能性がありますの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



