


自然言語処理では、実際には多くの情報が繰り返されます。
プロンプトの単語を効果的に圧縮できれば、モデルがサポートするコンテキストの長さをある程度拡張することと同じになります。
既存の情報エントロピー手法は、特定の単語や語句を削除することでこの冗長性を削減します。
しかし、情報エントロピーに基づく計算は、テキストの一方向のコンテキストのみをカバーしており、圧縮に必要な重要な情報が無視される可能性があり、また、情報エントロピーの計算方法は完全ではありません。圧縮のヒントと一致するのは、単語の実際の目的です。
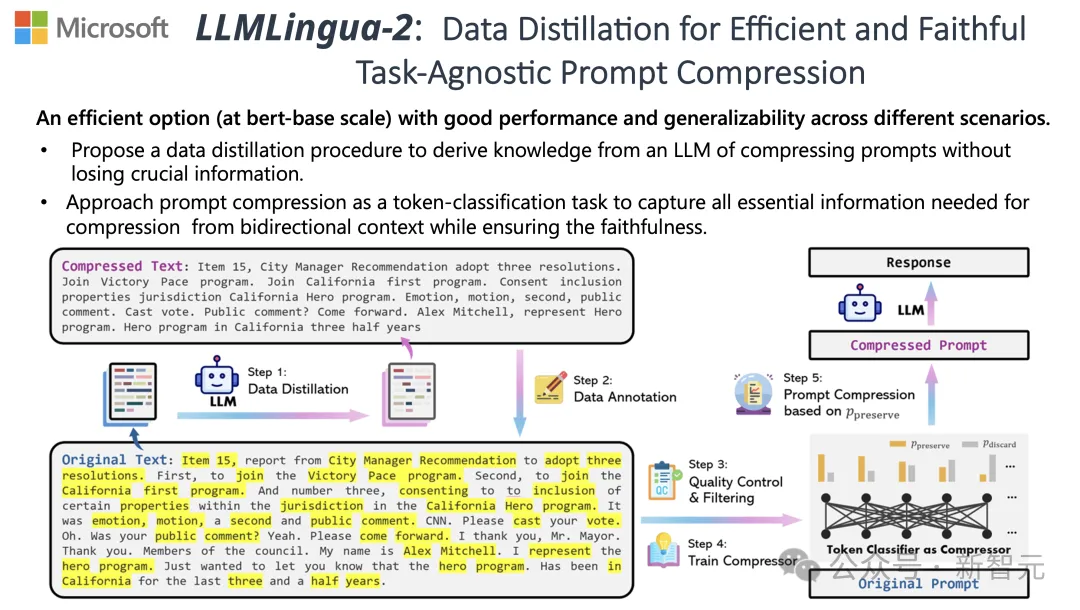
これらの課題に対処するために、清華大学の研究者とマイクロソフトは共同で、LLMLingua-2 と呼ばれる新しいデータ処理プロセスを提案しました。大規模言語モデル (LLM) から知識を抽出し、重要な情報が失われないようにしながらプロンプトの単語を圧縮することで情報の洗練を実現することを目的としています。
このプロジェクトは GitHub で 3.1,000 個のスターを獲得しました
結果は、LLMLingua-2 が次のことを実行できることを示しています。テキストの長さが元の 20% に大幅に削減され、処理時間とコストが効果的に削減されます。
さらに、LLMLingua 2 の処理速度は、以前のバージョンの LLMLingua や他の同様のテクノロジーと比較して 3 ~ 6 倍向上しています。

論文アドレス: https://arxiv.org/abs/2403.12968
このプロセス内、生のテキストが最初にモデルに入力されます。
モデルは、各単語の重要性を評価し、単語間の関係も考慮しながら、それを保持するか削除するかを決定します。
最後に、モデルは最も高いスコアを持つ単語を選択して、より短いプロンプト単語を形成します。
チームは、MeetingBank、LongBench、ZeroScrolls、GSM8K、BBH を含む複数のデータセットで LLMLingua-2 モデルをテストしました。
このモデルは小規模ですが、ベンチマーク テストで大幅なパフォーマンスの向上を達成し、さまざまな大規模な言語モデル (GPT-3.5 から Mistral-7B まで) でパフォーマンスを実証します。言語間での優れた汎化能力(英語から中国語へ)。
システム プロンプト:
優れた言語学者として、あなたは、長い要約段落を変換するのが得意です。可能な限り多くの情報を保持しながら、重要でない単語を削除してテキストを簡潔な表現にします。
ユーザーヒント:
指定されたテキストを短い形式に圧縮してください(GPT-4) 元のテキストをできるだけ正確に復元できるようにする式です。通常のテキスト圧縮とは異なり、次の 5 つの条件に従う必要があります:
1. 重要でない単語のみを削除します。
2. 元の単語の順序は変更しません。
3. 元の語彙を変更しないでください。
4. 略語や絵文字は使用しないでください。
5. 新しい単語や記号を追加しないでください。
できるだけ多くの情報を保持しながら、元のテキストを可能な限り圧縮してください。理解できましたら、次のテキストを圧縮してください: {圧縮するテキスト}
圧縮されたテキストは次のとおりです: [...]
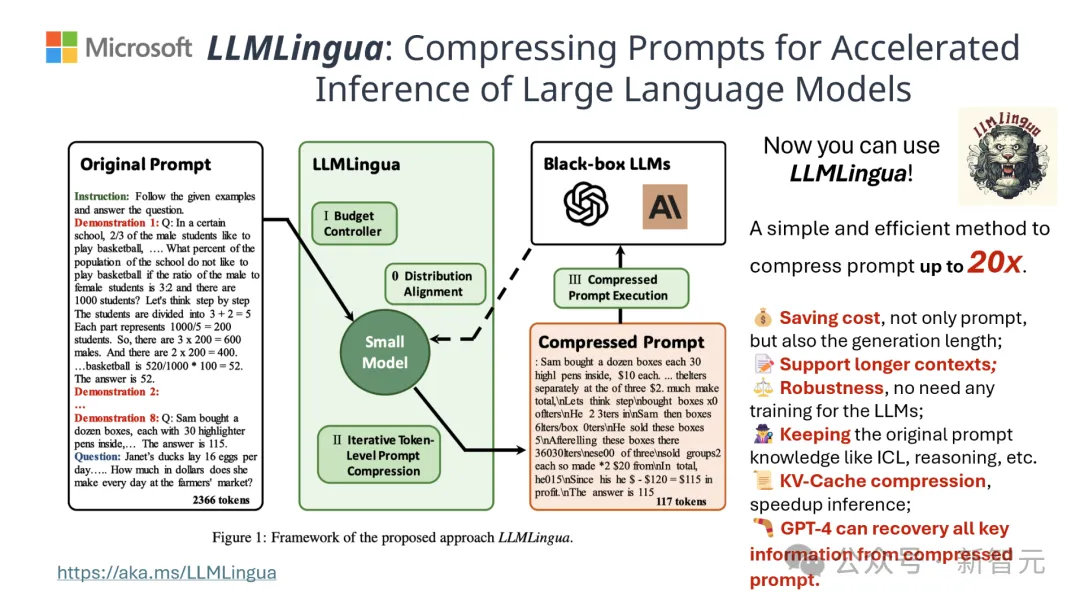
結果は、LLMLingua-2 が、質疑応答、要約作成、論理的推論などの複数言語タスクにおいて、元の LLMLingua モデルやその他の選択的コンテキスト戦略よりも大幅に優れていることを示しています。
この圧縮方法は、さまざまな大規模言語モデル (GPT-3.5 から Mistral-7B まで) やさまざまな言語 (英語から中国語まで) に対しても同様に効果的であることは言及する価値があります。
さらに、LLMLingua-2 のデプロイメントは、わずか 2 行のコードで実現できます。
現在、このモデルは広く使用されている RAG フレームワーク LangChain と LlamaIndex に統合されています。
既存の情報エントロピーベースのテキスト圧縮方法が直面する問題を克服するために、LLMLingua-2 は革新的なデータを採用しています。抽出戦略。
この戦略は、GPT-4 などの大規模な言語モデルから重要な情報を抽出し、重要なコンテンツを失うことなく効率的なテキスト編集を実現し、誤った情報の追加を回避します。
プロンプト デザイン
GPT-4 のテキスト圧縮の可能性を最大限に活用するには、鍵となるのは次の方法です。正確な圧縮命令を設定します。
つまり、テキストを圧縮するときに、元のテキストでそれほど重要ではない単語のみを削除し、その過程で新しい単語が導入されるのを避けるように GPT-4 に指示します。
これの目的は、圧縮されたテキストが元のテキストの信頼性と完全性を可能な限り維持することです。

##注釈とフィルタリング
研究者は GPT-4 を使用しました。大規模な言語モデルから抽出された知識に基づいて、新しいデータ注釈アルゴリズムが開発されました。
このアルゴリズムは、元のテキスト内の各単語をマークし、圧縮プロセス中にどの単語を保持する必要があるかを明確に示すことができます。
構築されたデータセットの高品質を確保するために、品質の低いデータサンプルを特定して除外するための 2 つの品質監視メカニズムも設計しました。

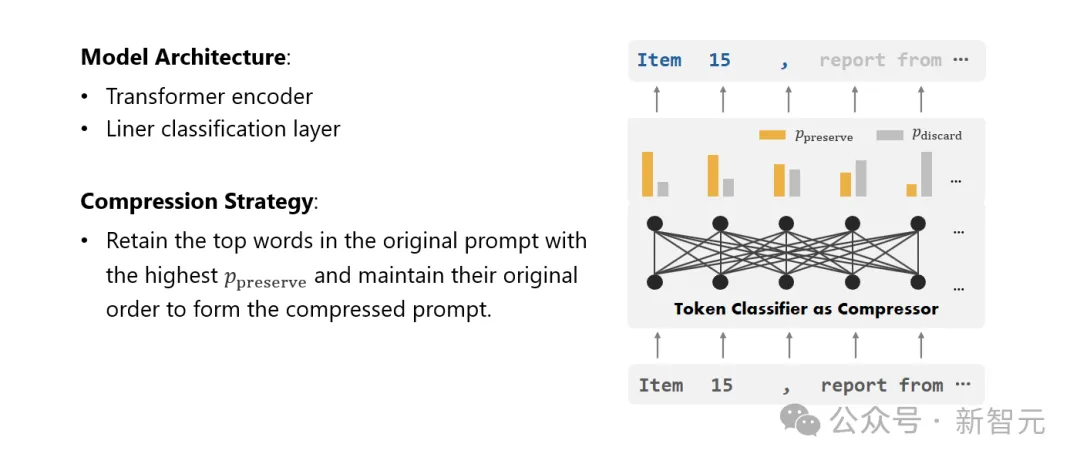
コンプレッサー
研究者たちはついにテキスト圧縮の問題を解決しました。これは各単語 (トークン) を分類するタスクに変換され、強力な Transformer が特徴抽出器として使用されます。
このツールは、テキストのコンテキストを理解して、テキスト圧縮に重要な情報を正確に取得できます。
研究者のモデルは、注意深く構築されたデータセットでトレーニングすることにより、単語をその重要性に基づいて保持すべきかどうかを決定するための確率値を計算することができます。 、それでも破棄する必要があります。
研究者らは、さまざまなタスクで LLMLingua-2 のパフォーマンスをテストしました。これらのタスクには、コンテキスト学習、テキスト要約、ダイアログ生成、複数および単一ドキュメントの質問応答、コード生成、およびドメイン内データセットとドメイン外データセットの両方を含む合成タスクが含まれます。
テスト結果は、研究者の方法が高いパフォーマンスを維持しながらパフォーマンスの損失を最小限に抑え、タスクに特化しないテキスト圧縮方法の中で優れたパフォーマンスを発揮することを示しています。
- ドメイン内テスト (MeetingBank)
研究者らは、MeetingBank での LLMLingua-2 のパフォーマンスを比較しました。テスト セットと他の強力なベースライン方法が比較されます。
モデルのサイズはベースラインで使用された LLaMa-2-7B よりもはるかに小さいですが、研究者の手法は質問応答やテキスト要約タスクのパフォーマンスを大幅に向上させただけでなく、元のテキスト プロンプトも同様に実行されました。
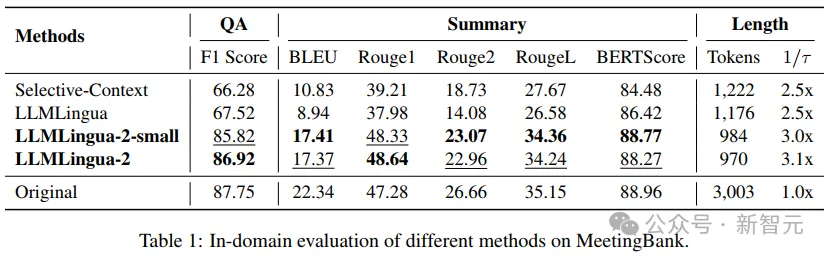
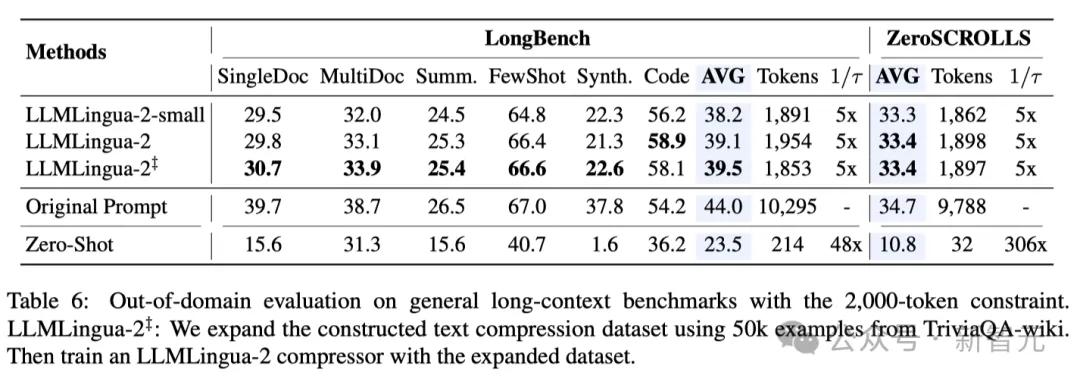
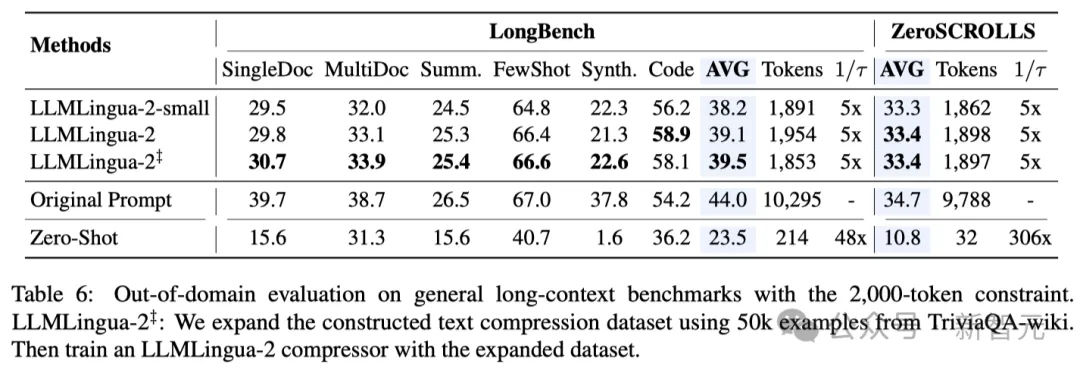
-ドメイン外テスト (LongBench、GSM8K、BBH)
研究者のモデルが MeetingBank の会議記録データでのみトレーニングされたことを考慮して、研究者らは、長文テキスト、論理的推論、文脈学習などのさまざまなシナリオでその一般化機能をさらに調査しました。
LLMLingua-2 は 1 つのデータセットでのみトレーニングされましたが、ドメイン外テストでは、そのパフォーマンスが現在の状態に匹敵するだけでなく、 -art タスク独立圧縮 これらの方法は同等ですが、場合によってはさらに優れています。
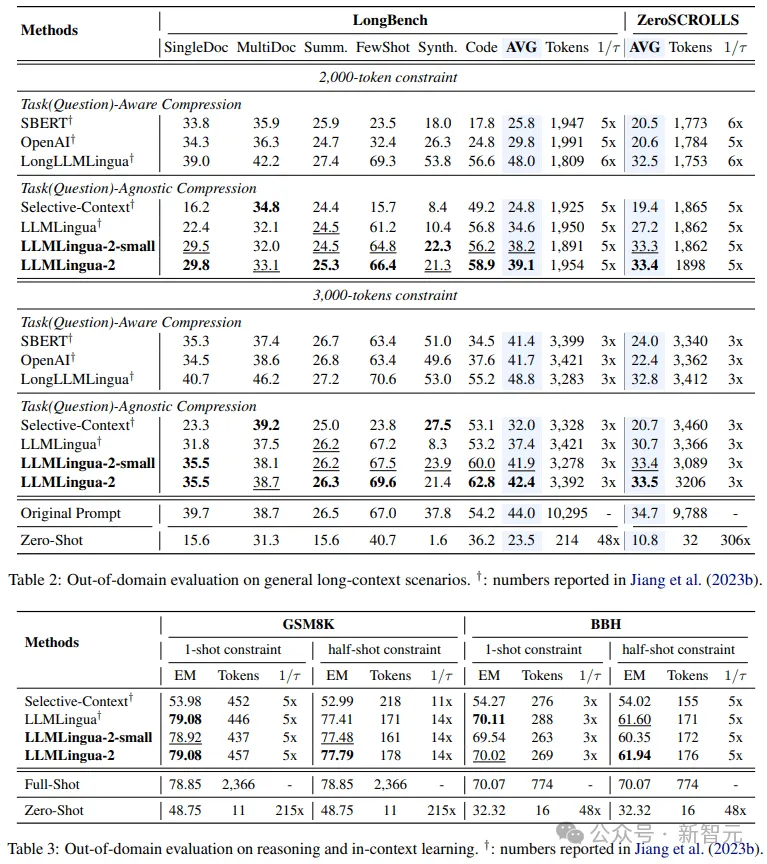
研究者のより小さなモデル (BERT ベースのサイズ) であっても、元のヒントと同等のパフォーマンスを達成することができました。場合によっては、それよりも劣ったり、場合によっては、元の先端の少し上にあります。
研究者のアプローチは有望な結果を達成しましたが、Longbench の LongLLMlingua などの他のタスク認識圧縮方法と比較すると、まだ欠点があります。
研究者らは、このパフォーマンスのギャップは質問から得られる追加情報のせいだと考えています。ただし、研究者のモデルはタスクに依存しないため、さまざまなシナリオに導入した場合に汎用性が高く、効率的なオプションとなります。
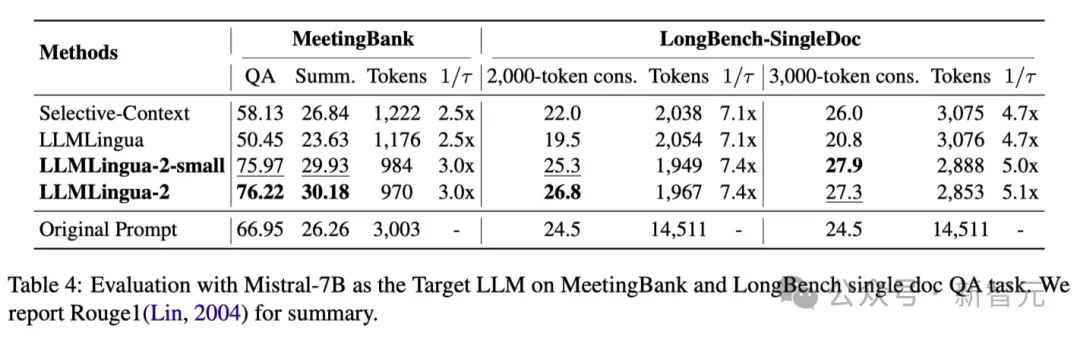
上記の表 4 は、ターゲット LLM として Mistral-7Bv0.1 4 を使用したさまざまな方法の結果を示しています。
他のベースライン手法と比較して、研究者の手法はパフォーマンスが大幅に向上しており、ターゲット LLM に対する優れた一般化能力を示しています。
LLMLingua-2 のパフォーマンスが元のプロンプトよりもさらに優れていることは注目に値します。
研究者らは、Mistral-7B は GPT-3.5-Turbo ほど長いコンテキストの管理が得意ではないのではないかと推測しています。
研究者のアプローチは、より高い情報密度で短いヒントを提供することで、Mistral7B の最終推論パフォーマンスを効果的に向上させます。
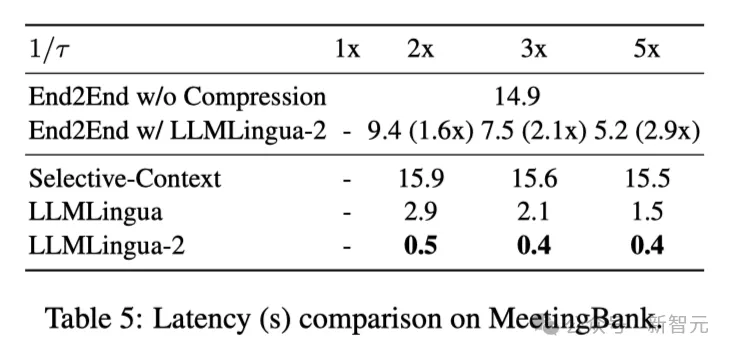
上の表 5 は、さまざまな圧縮率を使用した V100-32G GPU 上のさまざまなシステムのレイテンシを示しています。
結果は、他の圧縮方法と比較して、LLMLlingua2 は計算オーバーヘッドがはるかに少なく、エンドツーエンドの速度が 1.6 倍から 2.9 倍向上できることを示しています。
さらに、研究者の手法では GPU メモリのコストを 8 分の 1 に削減できるため、ハードウェア リソースの需要も削減できます。
コンテキスト認識観察研究者らは、圧縮率が増加するにつれて、LLMLingua-2 が完全なコンテキストを備えた最も有益な単語を効果的に維持できることを観察しました。
これは、双方向のコンテキスト認識型特徴抽出機能と、タイムリーな圧縮という目標に向けて明示的に最適化された戦略の採用によるものです。
研究者らは、圧縮率が増加するにつれて、LLMLingua-2 が完全なコンテキストに関連する最も有益な単語を効果的に維持できることを観察しました。
これは、双方向のコンテキスト認識型特徴抽出機能と、タイムリーな圧縮という目標に向けて明示的に最適化された戦略の採用によるものです。
最後に、研究者らは GPT-4 に LLMLlingua-2 圧縮プロンプトからの元のトーンを再構築させました。
結果は、GPT-4 が元のチップを効果的に再構築できることを示しており、LLMLingua-2 圧縮中に重要な情報が失われていないことを示しています。
以上が清華マイクロソフトは、新しいプロンプトワード圧縮ツールをオープンソース化し、長さが 80% 削減されました。 GitHub が 3.1,000 個のスターを獲得の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



