


CLIP は Contrastive Language-Image Pre-training の略で、対照的なテキストと画像のペアに基づく事前トレーニング方法またはモデルです。対照的な学習に依存するマルチモーダル モデルです。CLIP のトレーニング データテキストと画像のペアで構成されており、画像は対応するテキストの説明とペアになっています。モデルは、対照学習を通じて、テキストと画像のペアの関係を理解することを目的としています。

Open AIは、2021年1月にDALL-EとCLIPをリリースしました。どちらのモデルも画像とテキストを組み合わせることができるマルチモーダルモデルです。 DALL-E はテキストに基づいて画像を生成するモデルですが、CLIP はテキストを監視信号として使用して、転送可能な視覚モデルをトレーニングします。
安定拡散モデルでは、CLIP テキスト エンコーダによって抽出されたテキスト特徴が、クロス アテンションを通じて拡散モデルの UNet に埋め込まれます。具体的には、テキストの特徴が注目のキーと値として使用され、UNet の特徴がクエリとして使用されます。つまり、CLIP は実際には、文字情報と画像情報を有機的に結合する、文字と画像の間の重要な架け橋です。この組み合わせにより、モデルは異なるモダリティ間で情報をよりよく理解して処理できるようになり、複雑なタスクを処理する際により良い結果が得られます。このようにして、安定拡散モデルは CLIP のテキスト エンコーディング機能をより効果的に利用できるため、全体的なパフォーマンスが向上し、アプリケーション領域が拡大します。
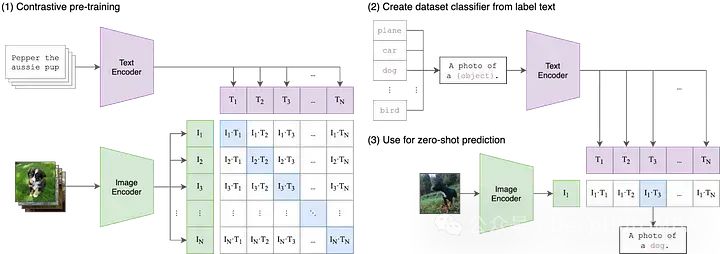
これは、2021 年に OpenAI によって公開された最初の論文です。 CLIP、頭字語を 3 つのコンポーネントに分解する必要があります: (1) 対比、(2) 言語と画像、(3) 事前トレーニング。
言語とイメージから始めましょう。
従来の機械学習モデルでは、通常、テキスト、画像、表形式データ、音声など、単一の入力データのみを受け入れることができます。予測を行うためにさまざまなデータ モダリティを使用する必要がある場合は、複数の異なるモデルをトレーニングする必要があります。 CLIP では、「Language-Image」は、モデルがテキスト (言語) と画像の両方の入力データを受け入れることができることを意味します。この設計により、CLIP はさまざまなモダリティの情報をより柔軟に処理できるようになり、予測機能と適用範囲が向上します。
CLIP は、テキスト エンコーダーと画像エンコーダーという 2 つの異なるエンコーダーを使用してテキストと画像の入力を処理します。これら 2 つのエンコーダは、入力データを低次元の潜在空間にマッピングし、各入力に対応する埋め込みベクトルを生成します。重要な点は、テキスト エンコーダーと画像エンコーダーがデータを同じ空間に埋め込むことです。つまり、元の CLIP 空間は 512 次元のベクトル空間です。この設計により、追加の変換や処理を行わずに、テキストと画像を直接比較および照合できます。このようにして、CLIP はテキストの説明と画像コンテンツを同じベクトル空間で表現できるため、クロスモーダルな意味論的な位置合わせと検索機能が可能になります。この共有埋め込みスペースの設計により、CLIP の一般化機能と適応性が向上し、さまざまなタスクやデータセットで適切に実行できるようになります。
テキストと画像データを同じベクトル空間に埋め込むことは出発点としては有用かもしれませんが、これを行うだけでは効果はありません。モデルがテキストと画像の表現を効果的に比較できるという保証はありません。たとえば、テキストへの「犬」または「犬の写真」の埋め込みと犬の画像の埋め込みとの間に、合理的で解釈可能な関係を確立することが重要です。ただし、これら 2 つのモデル間のギャップを埋める方法が必要です。
マルチモーダル機械学習では、2 つのモダリティを調整するさまざまな手法がありますが、現在最も一般的な手法はコントラストです。対照的な手法では、2 つのモダリティから入力のペア、つまり画像とそのキャプションを取得し、これらの入力データのペアをできるだけ正確に表現するようにモデルの 2 つのエンコーダーをトレーニングします。同時に、モデルは、ペアになっていない入力 (犬の画像や「車の写真」というテキストなど) を取得し、それらをできるだけ遠くから表現するように促されます。 CLIP は、画像とテキストに対する最初の対比学習手法ではありませんが、そのシンプルさと有効性により、マルチモーダル アプリケーションの主流となっています。
事前トレーニング
CLIP 自体はゼロショット分類、セマンティック検索などのタスクに役立ちますが、アプリケーションは便利ですが、CLIP は、Stable Diffusion や DALL-E から StyleCLIP や OWL-ViT まで、多数のマルチモーダル アプリケーションのビルディング ブロックとしても使用されます。これらの下流アプリケーションのほとんどでは、初期の CLIP モデルが「事前トレーニング」の開始点とみなされ、モデル全体が新しいユースケースに合わせて微調整されます。
OpenAI は、元の CLIP モデルのトレーニングに使用されるデータを明示的に指定したり共有したりしませんでしたが、CLIP の論文では、このモデルがインターネットから収集された 4 億の画像とテキストのペアで実行されたと述べられています。訓練された。
//m.sbmmt.com/link/7c1bbdaebec5e20e91db1fe61221228f

CLIP を使用すると、OpenAI は 4 億の画像とテキストのペアを使用します。詳細が提供されていないため、おそらくデータセットの構築方法を正確に知っているでしょう。しかし、新しいデータセットを説明する際に、彼らはインスピレーションとして Google のコンセプト キャプションに注目しました。これは比較的小規模なデータセット (330 万の画像とキャプションのペア) で、高価なフィルタリングと後処理技術を使用しています。これらの技術は強力ですが、特に拡張性があるわけではありません)。 。
そのため、高品質のデータセットが研究の方向性になりました。CLIP の直後、ALIGN はスケール フィルタリングによってこの問題を解決しました。 ALIGN は、慎重に注釈が付けられ、厳選された小規模な画像キャプション データセットに依存せず、代わりに 18 億ペアの画像と代替テキストを活用します。
これらの代替テキストの説明は、平均するとタイトルよりもはるかにノイズが多くなりますが、データセットの巨大なサイズがこれを補って余りあります。著者らは、基本的なフィルタリングを使用して、重複、1,000 を超える関連する代替テキストを含む画像、および情報のない代替テキスト (一般的すぎる、または珍しいタグを含む) を削除しました。これらの簡単な手順により、ALIGN はさまざまなゼロショット タスクや微調整タスクにおいて最先端のレベルに達するか、それを超えます。
https://arxiv.org/abs/2102.05918

ALIGN と同様に、K-LITE も比較の問題を解決しています。事前にトレーニングされた高品質の画像とテキストのペアの数が限られているという問題。
K-LITE は、概念の説明、つまりコンテキストや未知の概念としての定義や説明を説明することに重点を置き、幅広い理解を促進します。一般的な説明は、人々が初めて専門用語や珍しい語彙を紹介するとき、通常は単にそれらを定義するか、誰もが知っているものに例えて使用するというものです。
このアプローチを実装するために、マイクロソフトとカリフォルニア大学バークレー校の研究者は、WordNet と Wiktionary を使用して画像とテキストのペアのテキストを強化しました。 ImageNet のクラス ラベルなどの一部の孤立した概念では、概念自体が強化されますが、タイトル (GCC など) では、最も一般的でない名詞句が強化されます。この追加の構造化された知識により、事前トレーニングされたモデルは転移学習タスクで大幅な改善を示します。
#https://arxiv.org/abs/2204.09222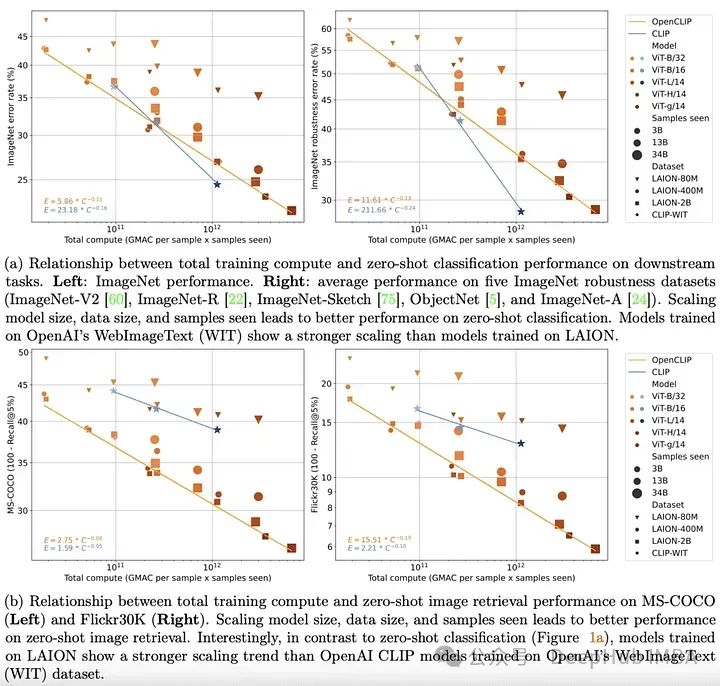
2022 年末までに、テキストとビジュアルの分野でトランスフォーマー モデルが確立されます。両方の分野における先駆的な実証研究により、単峰性タスクにおける変圧器モデルのパフォーマンスが単純なスケーリング則で十分に説明できることも明確に示されました。これは、トレーニング データの量、トレーニング時間、またはモデルのサイズが増加するにつれて、モデルのパフォーマンスをかなり正確に予測できることを意味します。
OpenCLIP は、これまでにリリースされた最大のオープンソースの画像とテキストのペア データセット (5B) を使用して、上記の理論をマルチモーダル シナリオに拡張し、トレーニング データ ペア モデルのパフォーマンスを体系的に研究します。ゼロショットおよび微調整タスクのパフォーマンスへの影響。ユニモーダルの場合と同様に、この研究では、マルチモーダル タスクにおけるモデルのパフォーマンスが、計算、見られるサンプル数、モデル パラメーターの数に関してべき乗則に応じてスケールされることが明らかになりました。
べき乗則の存在よりもさらに興味深いのは、べき乗則スケーリングと事前トレーニング データの関係です。 OpenAI の CLIP モデル アーキテクチャとトレーニング方法を維持しながら、OpenCLIP モデルはサンプル画像取得タスクでより強力なスケーリング機能を示します。 ImageNet でのゼロショット画像分類の場合、OpenAI のモデル (独自のデータセットでトレーニングされた) は、より強力なスケーリング機能を実証しました。これらの調査結果は、下流のパフォーマンスにおけるデータ収集とフィルタリング手順の重要性を強調しています。 https://arxiv.org/abs/2212.07143
しかし、OpenCLIP がリリースされた直後、LAION データ セットは違法な画像が含まれていたため、インターネットから削除されました。MetaCLIP: CLIP データをわかりやすく理解する
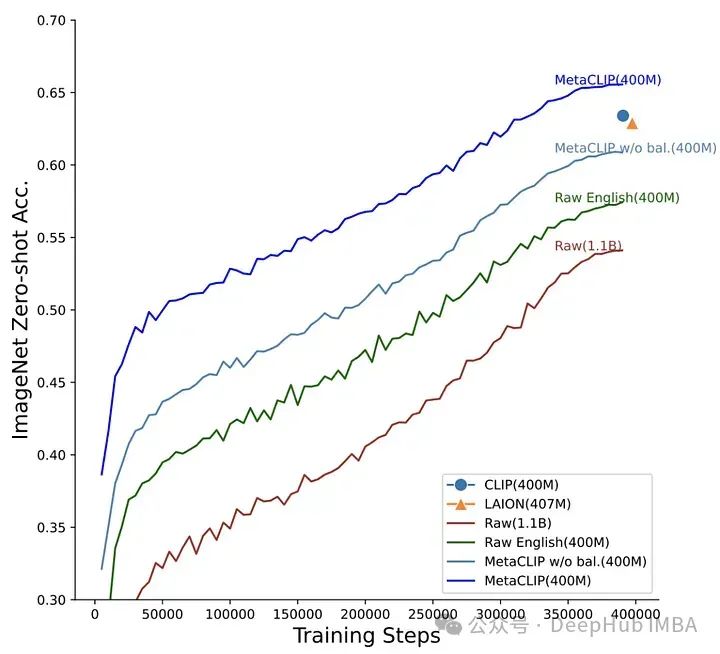
この仮説を検証するために、著者はモデルのアーキテクチャとトレーニング手順を修正し、実験を実施しました。 MetaCLIP チームは、部分文字列のマッチング、フィルタリング、およびデータ分散のバランスに関するさまざまな戦略をテストし、トレーニング データ セット内で各テキストが最大 20,000 回出現したときに最高のパフォーマンスが達成されることを発見しました。この理論をテストするには、次のようにします。初期データプールで 5,400 万回出現した「写真」という単語も、トレーニング データでは画像とテキストのペアが 20,000 に制限されていました。この戦略を使用して、MetaCLIP は Common Crawl データセットからの 4 億の画像とテキストのペアでトレーニングされ、さまざまなベンチマークで OpenAI の CLIP モデルを上回りました。 これを検証するために、著者は概念的な 12M からの高品質データを使用して、低品質データから高品質データをフィルタリングするように CLIP モデルをトレーニングします。このデータ フィルタリング ネットワーク (DFN) は、キュレートされていないデータセット (この場合は共通クロール) から高品質のデータのみを選択することで、より大規模で高品質のデータセットを構築するために使用されます。フィルタリングされたデータでトレーニングされた CLIP モデルは、初期の高品質データのみでトレーニングされたモデルや、フィルタリングされていない大量のデータでトレーニングされたモデルよりも優れたパフォーマンスを発揮しました。 https://arxiv.org/abs/2309.17425DFN: データ フィルタリング ネットワーク
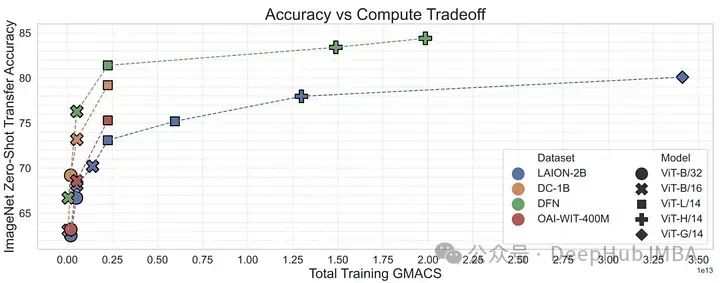
OpenAI の CLIP モデルは大きく変わりました私たちはマルチモーダルなデータを扱います。しかし、CLIP は始まりにすぎません。トレーニング前のデータからトレーニング方法や対比損失関数の詳細に至るまで、CLIP ファミリは過去数年間で驚くべき進歩を遂げました。 ALIGN はノイズの多いテキストをスケーリングし、K-LITE は外部知識を強化し、OpenCLIP はスケーリングの法則を研究し、MetaCLIP はデータ管理を最適化し、DFN はデータ品質を強化します。これらのモデルは、マルチモーダル人工知能の開発における CLIP の役割についての理解を深め、画像とテキストの接続における進歩を示しています。
以上がヴィンセント図の基礎となる CLIP モデルの開発のレビューの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。





























![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



