合成データは、大規模モデルの数学的推論の可能性を解き放ち続けています。
数学的問題解決能力は、言語モデルの知能レベルを示す重要な指標として常に考えられてきました。通常、非常に大規模なモデル、または広範な数学的事前トレーニングを受けたモデルのみが、数学的問題で適切に実行できる可能性があります。 最近、Swin-Transformer チームによって作成され、西安交通大学、中国科学技術大学、清華大学、マイクロソフトの学者によって完成された研究成果が発表されました。 Research Asia Xwin はこの認識を覆し、一般的な事前トレーニング下の 7B (つまり 70 億パラメータ) スケール言語モデル (LLaMA-2-7B) が数学的問題を解決する上で強力な可能性を示しており、合成に基づいて使用できることを明らかにしました。 -データの調整方法により、モデルが数学的機能をより安定して刺激できるようになります。 この研究は、「Common 7B Language Models Already Possess Strong Math Capabilities」というタイトルで arXiv に公開されました。 
- 論文リンク: https://arxiv.org/pdf/2403.04706.pdf
- コードリンク: https://github.com/Xwin-LM/Xwin-LM
研究チームは最初、LLaMA を実行するために 7.5K のデータのみを使用しました。 - 2-7B モデル命令は、GSM8K および MATH でモデルのパフォーマンスを評価するために微調整されています。実験結果は、テストセット内の各質問に対して生成された 256 の回答から最良の回答を選択する場合、テストの精度はそれぞれ 97.7% と 72.0% に達する可能性があることを示しています。この結果は、一般的な事前トレーニング下でも 7B レベルが達成できることを示しています。小規模なモデルであっても高品質の答えを生成する可能性があるという発見は、強力な数学的推論の可能性は大規模で数学的に関連した事前トレーニング済みモデルに限定されないというこれまでの見解に疑問を投げかけます。 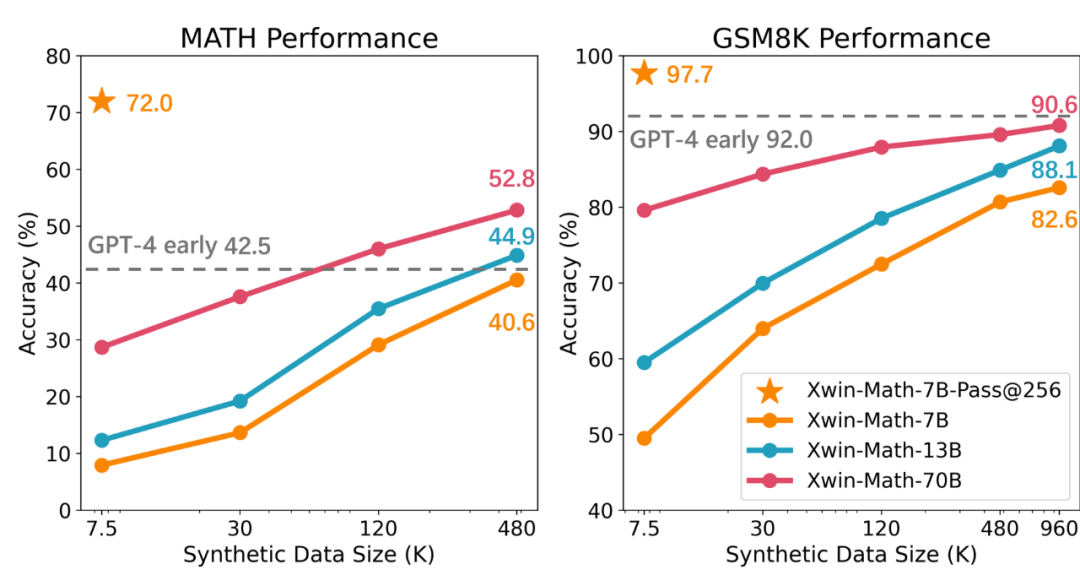
ただし、研究では、言語モデルには強力な数学的推論の可能性があるものの、現在の言語モデルの主な問題は、その固有の数学的能力を一貫して刺激することが難しいことであるとも指摘しています。たとえば、前の実験で質問ごとに生成された回答が 1 つだけ考慮された場合、GSM8K ベンチマークと MATH ベンチマークの精度はそれぞれ 49.5% と 7.9% に低下します。これは、モデルの数学的機能の不安定性を反映しています。この問題を解決するために、研究チームは教師あり微調整(SFT)データセットを拡張する方法を採用し、SFTデータの増加に伴い、正解を生成するモデルの信頼性が大幅に向上することを発見しました。 研究では、合成データを使用することで SFT データセットを効果的に拡大でき、この方法は実際のデータとほぼ同じ効果があることにも言及しました。研究チームは GPT-4 Turbo API を使用して合成数学的質問と問題解決プロセスを生成し、プロンプトの単語の簡単な検証を通じて質問の品質を保証しました。この方法を通じて、チームは SFT データセットを 7.5K から約 100 万サンプルまで拡張することに成功し、ほぼ完璧なスケーリング則を達成しました。結果として得られた Xwin-Math-7B モデルは、GSM8K と MATH でそれぞれ 82.6% と 40.6% の精度を達成し、以前の SOTA モデルを大幅に上回り、一部の 70B モデルをも上回り、飛躍的な改善を達成しました。 Xwin-Math-70B モデルは、MATH 評価セットで 52.8% の結果を達成し、GPT-4 の初期バージョンを大幅に上回りました。 LLaMA シリーズの基本モデルに基づく研究が MATH で GPT-4 を超えたのはこれが初めてです。 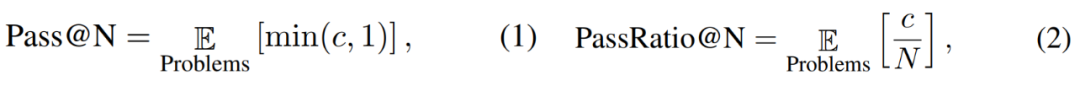
研究者らは、モデルが N 個の出力で正しい答えを出力できるかどうかを評価することを目的として、Pass@N および PassRatio@N 評価指標も定義しました (これは、モデルが N 個の出力の可能性を示す)モデル)、数学的能力)、および正答率(モデルの数学的能力の安定性を示します)。 SFT データの量が少ない場合、モデルの Pass@256 はすでに非常に高くなりますが、SFT データの規模をさらに拡大すると、モデルの Pass@256 はほとんど増加しませんが、PassRatio@256 は大幅に増加します。これは、合成データに基づく教師あり微調整がモデルの数学的機能の安定性を向上させる効果的な方法であることを示しています。 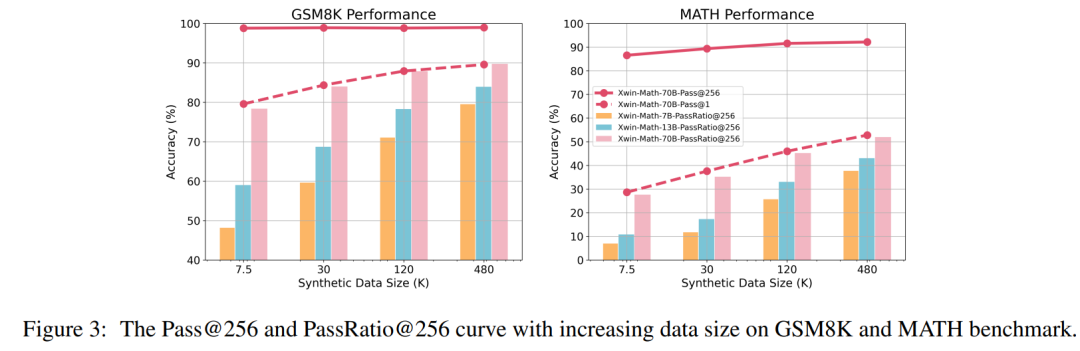
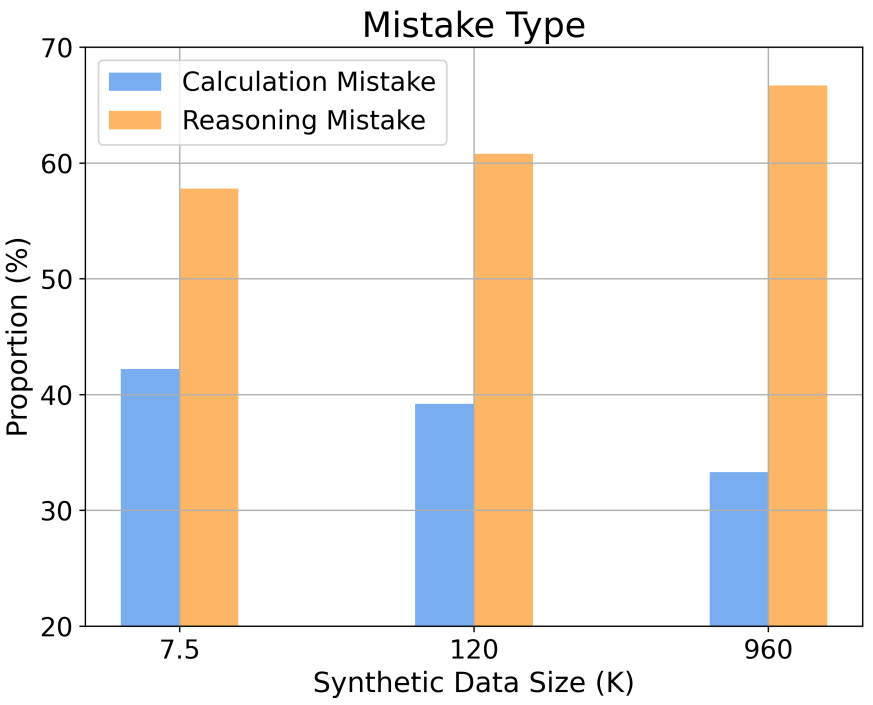
さらに、この調査では、さまざまな推論の複雑さとエラーの種類におけるスケーリング動作についての洞察が得られます。たとえば、SFT データセットのサイズが増加するにつれて、数学的問題を解決するモデルの精度は、推論ステップ数とのべき乗関係に従います。トレーニング サンプル内の長い推論ステップの割合を増やすことにより、困難な問題を解決する際のモデルの精度を大幅に向上させることができます。同時に、この研究では、推論エラーよりも計算エラーの方が軽減しやすいことも判明しました。 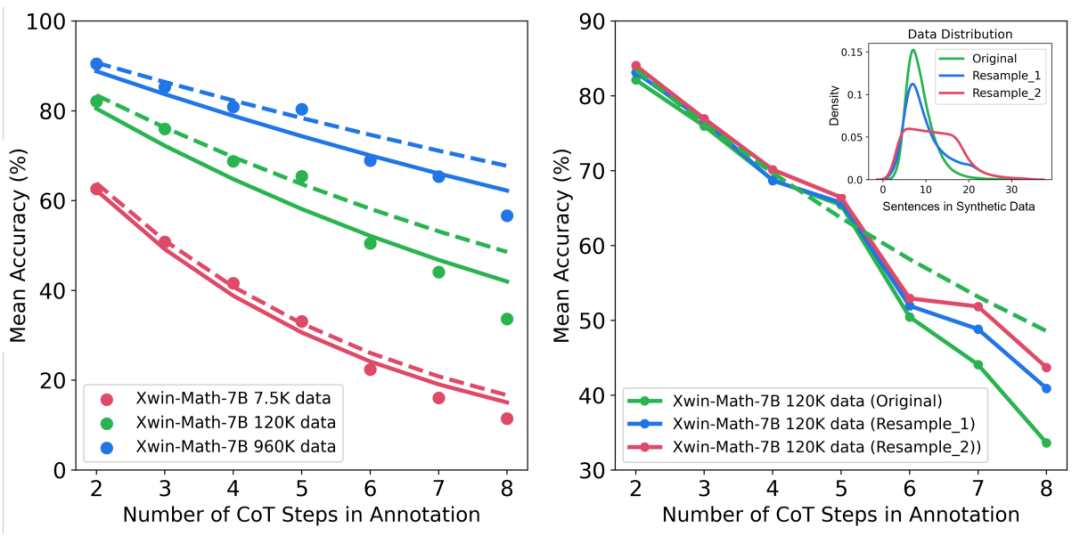
モデルの数学的推論一般化能力を反映するハンガリーの高校数学テストでも、Xwin-Math は 65% のスコアを獲得しました。 GPT-4に。これは、研究でデータが合成された方法が評価セットに大幅に過剰適合せず、良好な一般化能力を示したことを示しています。 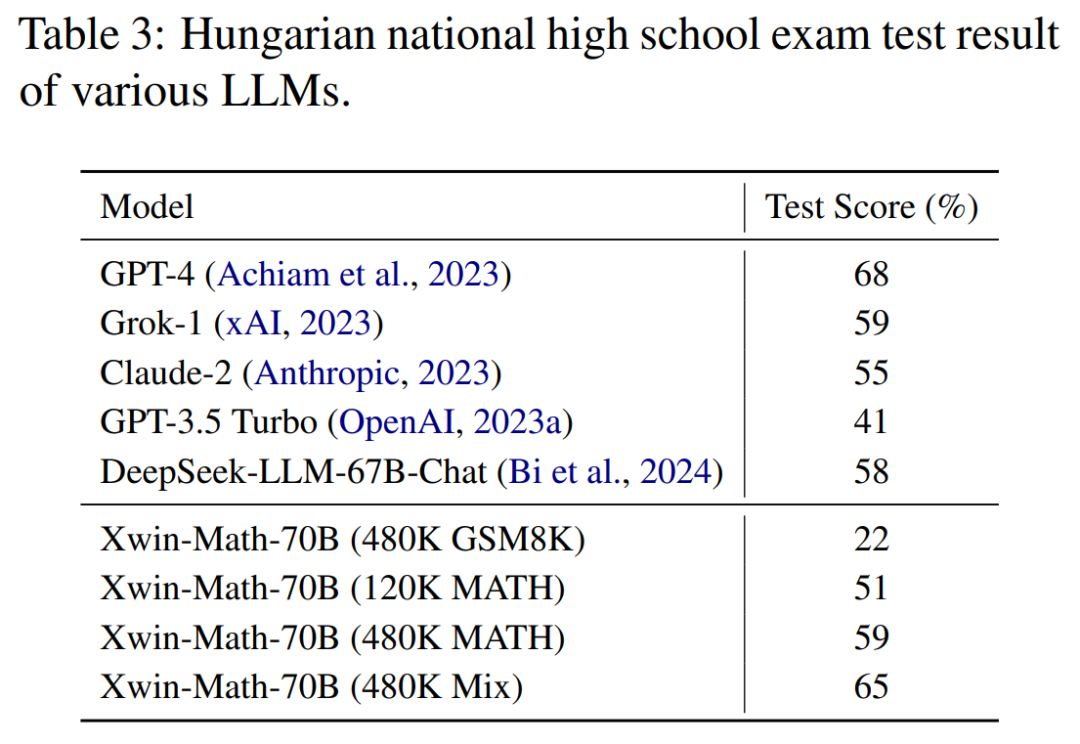

この研究は、SFT データの拡張における合成データの有効性を実証するだけでなく、数学的推論機能における大規模言語モデルの研究に新しい視点を提供します。研究チームは、彼らの研究がこの分野における将来の探求と進歩の基礎を築いたと述べ、数学的問題の解決において大きな進歩を遂げるために人工知能を促進することを楽しみにしていると述べた。人工知能技術が進歩し続けるにつれて、AI が数学の分野でさらに優れたパフォーマンスを発揮し、複雑な数学的問題を解決する際に人間により多くの支援を提供できるようになることが期待されます。 アブレーション実験結果やその他のデータ合成手法の評価指標についても触れていますので、詳しくは全文をご覧ください。 以上がLLaMA-2-7Bの数学能力の上限は97.7%に達している? Xwin-Math が合成データの可能性を解き放つの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
































![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



