


ビデオ理解の分野では、マルチモーダル モデルは短いビデオ分析では画期的な進歩を遂げ、強力な理解能力を実証しましたが、映画レベルの長いビデオに直面すると、ビデオでは無力に見えます。 。したがって、長いビデオの分析と理解、特に数時間にわたる映画コンテンツの理解は、今日の大きな課題となっています。
モデルが長いビデオを理解することが難しいのは、主に品質と多様性に欠陥がある長いビデオ データ リソースの不足に起因します。さらに、このデータの収集とラベル付けには多大な作業が必要です。
このような問題に直面して、テンセントと復丹大学の研究チームは、革新的な AI 生成フレームワークである MovieLLM を提案しました。 MovieLLM は、高品質で多様なビデオ データを生成するだけでなく、関連する多数の質問と回答のデータ セットを自動的に生成する革新的な方法を採用し、データの次元と深さを大幅に強化します。プロセスも非常に重要であり、人的投資を削減します。

MovieLLM は、GPT-4 と拡散モデルの強力な生成機能を巧みに利用し、「ストーリーを拡張する」連続フレーム記述生成戦略を採用しています。 「テキスト反転」方法は、テキストの説明と一致するシーン画像を生成するように拡散モデルをガイドするために使用され、それによって完全な映画の連続フレームが作成されます。
 手法の概要
手法の概要
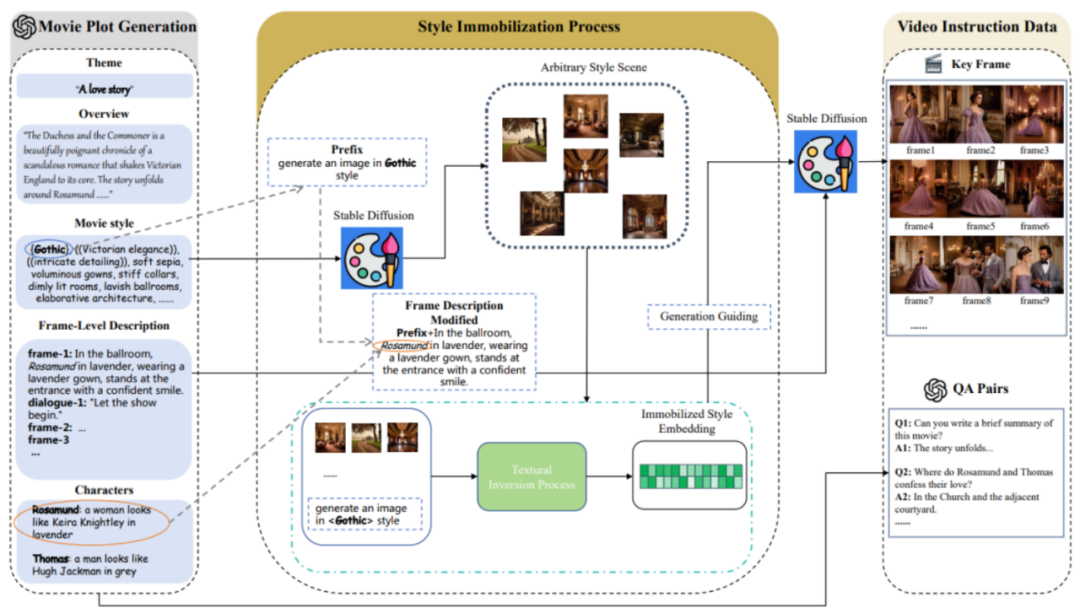 MovieLLM には主に 3 つのステージが含まれています:
MovieLLM には主に 3 つのステージが含まれています:
1. ムービー プロットの生成。
Web や既存のデータセットに依存してプロットを生成するのではなく、MovieLLM は GPT-4 の機能を最大限に活用して合成データを生成します。 GPT-4 は、テーマ、概要、スタイルなどの特定の要素を提供することで、後続の生成プロセスに合わせた映画のようなキーフレーム記述を生成します。
#2. スタイル修正プロセス。
MovieLLM は、「テキスト反転」テクノロジーを巧みに使用して、スクリプト内で生成されたスタイル記述を拡散モデルの潜在空間に固定します。この方法により、モデルは固定スタイルでシーンを生成し、統一された美学を維持しながら多様性を維持することができます。
#3. ビデオコマンドデータの生成。
最初の 2 つのステップに基づいて、固定スタイルの埋め込みとキー フレームの説明が取得されました。これらに基づいて、MovieLLM はスタイル埋め込みを使用して拡散モデルをガイドし、キー フレームの説明に準拠するキー フレームを生成し、映画のプロットに従ってさまざまな説明用の質問と回答のペアを段階的に生成します。
 #上記の手順の後、MovieLLM は高品質で多様なスタイル、一貫したムービー フレーム、および対応する質問と回答のペア データを作成します。ムービー データ タイプの詳細な分布は次のとおりです。
#上記の手順の後、MovieLLM は高品質で多様なスタイル、一貫したムービー フレーム、および対応する質問と回答のペア データを作成します。ムービー データ タイプの詳細な分布は次のとおりです。
この論文は、MovieLLM に基づいて構築されたデータを使用して、長時間ビデオの理解に焦点を当てた大規模なモデルである LLaMA-VID を微調整することにより、モデルの機能を大幅に強化しました。さまざまな長さのビデオコンテンツを理解できるようになります。長いビデオの理解については、現時点ではテスト ベンチマークを提案する作業がありません。そのため、この記事では、長いビデオの理解機能をテストするためのベンチマークも提案します。
MovieLLM はトレーニング用に特に短いビデオ データを構築しませんでしたが、トレーニングを通じて、さまざまな短いビデオ ベンチマークでパフォーマンスの向上が観察されました。結果は次のとおりです:
ベースライン モデルと比較すると、MSVD-QA と MSRVTT-QA の 2 つのテスト データ セットに大幅な改善が見られます。

ビデオ生成に基づくパフォーマンス ベンチマークでは、5 つの評価領域すべてでパフォーマンスの向上が達成されました。
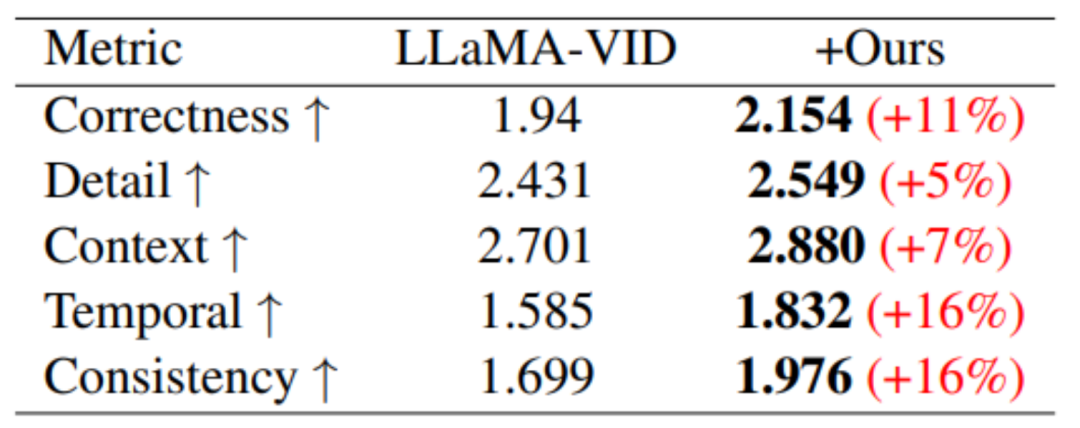
#長いビデオの理解という点では、MovieLLM のトレーニングを通じて、概要、プロット、タイミングに対するモデルの理解が大幅に向上しました。

さらに、MovieLLM は、固定スタイルで画像を生成する他の同様の方法と比較して、生成品質の点でも優れた結果をもたらします。
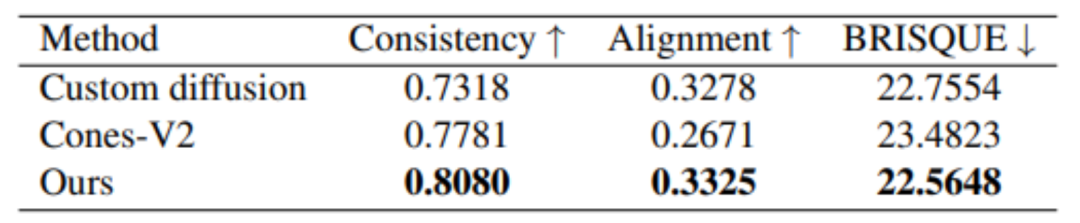
つまり、MovieLLM が提案するデータ生成ワークフローは、モデルの映画レベルのビデオ データを生成するという課題を大幅に軽減し、データの生成を改善します。コンテンツ、コントロール、多様性。同時に、MovieLLM は映画レベルの長いビデオを理解するマルチモーダル モデルの能力を大幅に強化し、他の分野が同様のデータ生成方法を採用するための貴重な参考資料となります。
この研究に興味のある読者は、論文の原文を読んで研究内容をさらに詳しく知ることができます。
以上がAI の短いビデオを使用して長いビデオの理解を「フィードバック」し、Tencent の MovieLLM フレームワークは映画レベルの連続フレーム生成を目指していますの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



