


Stable Diffusion 3 のリリース後、Stability AI は本日詳細な技術レポートをリリースしました。
この論文では、Stable Diffusion 3 のコア テクノロジー、つまり拡散モデルの改良版と DiT に基づくヴィンセント グラフの新しいアーキテクチャの詳細な分析を提供します。

レポートアドレス:
//m.sbmmt.com/link /e5fb88b398b042f6cccce46bf3fa53e8
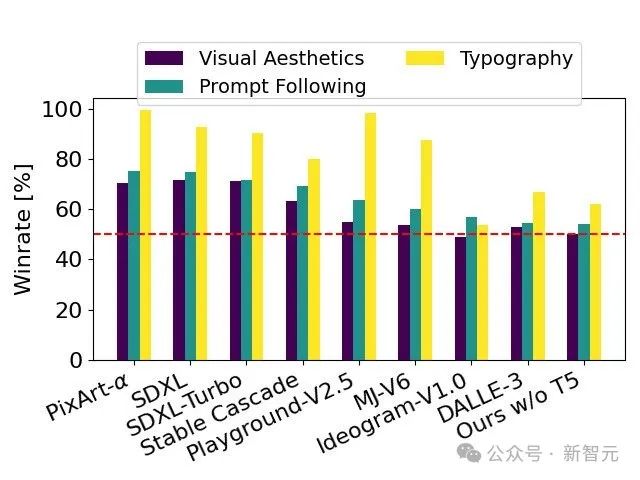
人間による評価テストに合格した Stable Diffusion 3 は、フォント デザインとプロンプトへの正確な応答の点で、DALL・E 3、Midjourney v6、および Ideogram v1 を上回りました。
Stability AI の新しく開発されたマルチモーダル拡散トランス (MMDiT) アーキテクチャは、画像と言語の表現に特化した独立した重みセットを使用します。以前のバージョンの SD 3 と比較して、MMDiT はテキストの理解とスペルの点で大幅な改善を達成しました。

人間のフィードバックに基づいて、技術レポートは SD 3 から大きな数まで評価します。オープンソース モデル SDXL、SDXL Turbo、Stable Cascade、Playground v2.5、Pixart-α、およびクローズド ソース モデル DALL・E 3、Midjourney v6、Ideogram v1 が詳細に評価されました。
評価者は、割り当てられたプロンプトの一貫性、テキストの明瞭さ、画像の全体的な美しさに基づいて、各モデルに最適な出力を選択します。

テスト結果は、Stable Diffusion 3 がプロンプトへの従うこと、テキストの明確な表示、画像の視覚的な美しさにおいて最高レベルの精度を達成していることを示しています。または現在の最先端のヴィンセント図生成テクノロジーを超えています。
SD 3 モデルはハードウェア向けにまったく最適化されていませんが、8B パラメーターがあり、RTX 4090 コンシューマ GPU で実行できます。 24 GB のビデオ メモリ、および 50 のサンプリング ステップを使用すると、1024x1024 の解像度の画像を生成するのに 34 秒かかります。
さらに、Stable Diffusion 3 は、リリース時に 8 億から 80 億の範囲のパラメータを持つ複数のバージョンを提供する予定で、これによりハードウェアの使用しきい値をさらに下げることができます。

Vincent 図の生成プロセスでは、モデルを処理する必要があります。テキストと画像を同時にこれら 2 つの異なる種類の情報。そこで著者はこの新しいフレームワークをMMDiTと呼んでいます。
テキストから画像への生成プロセスでは、モデルは 2 つの異なる情報タイプ (テキストと画像) を同時に処理する必要があります。このため、著者らはこの新しいテクノロジーを MMDiT (Multimodal Diffusion Transformer の略) と呼んでいます。
以前のバージョンの Stable Diffusion と同様に、SD 3 は事前トレーニングされたモデルを使用してテキストと画像の適切な表現を抽出します。
具体的には、2 つの CLIP モデルと 1 つの T5 という 3 つの異なるテキスト エンコーダを利用してテキスト情報を処理し、より高度な自動エンコーディング モデルを使用して画像情報を処理しました。
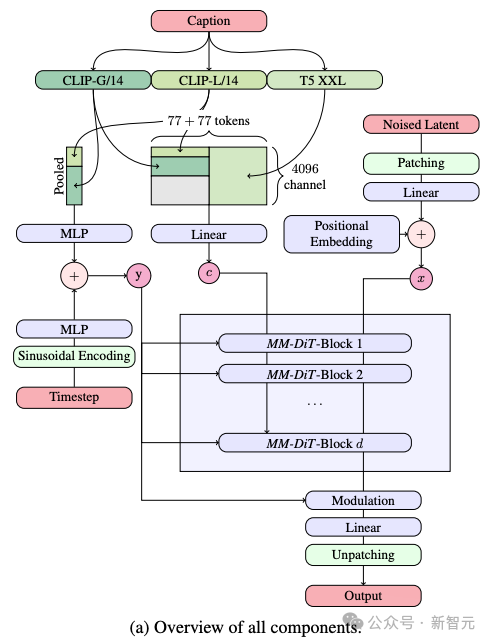
SD 3 のアーキテクチャは、拡散トランス (DiT) に基づいて構築されています。テキスト情報と画像情報の違いにより、SD 3 はこれら 2 種類の情報のそれぞれに独立した重みを設定します。
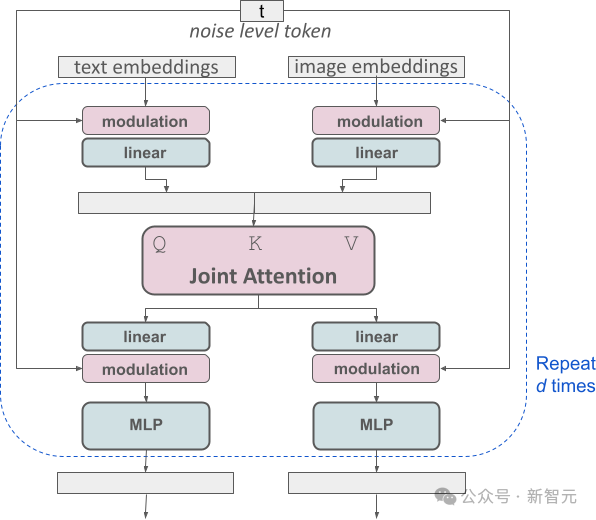
この設計は、情報の種類ごとに 2 つの独立した Transformer を装備することに相当しますが、アテンション機構を実行すると、2 種類の情報のデータ列がマージされ、それぞれの分野で使用できるようになります。独立して動作しながら、相互参照と統合を維持できます。
この独自のアーキテクチャを通じて、画像とテキストの情報が流れて相互作用することができるため、生成された結果のコンテンツの理解が向上します。全体的な理解と視覚的な表現。
さらに、このアーキテクチャは、将来的にはビデオを含む他のモダリティにも簡単に拡張できます。

SD 3 のキュー追従機能の改善のおかげで、モデルはさまざまなトピックや機能に焦点を当てた画像を正確に生成できます。画像スタイルも高い自由度を保っています。

再重み付け手法による整流の改善
新しい Diffusion の発売に加えてトランスフォーマー アーキテクチャ、SD 3 では、拡散モデルも大幅に改善されました。
SD 3 は、トレーニング データとノイズを直線の軌道に沿って接続するための整流フロー (RF) 戦略を採用しています。
この方法では、モデルの推論パスがより直接的なものになるため、サンプル生成をより少ないステップで完了できます。
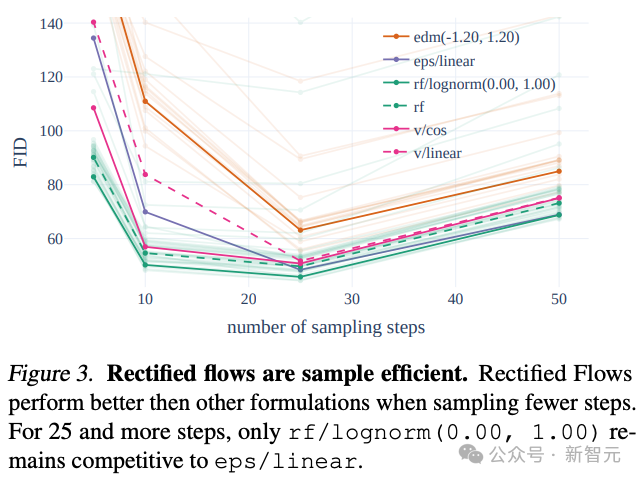
著者は、トレーニング プロセスに革新的な軌道サンプリング プランを導入しました。特に、軌道の中央部分の重みを増やし、これらの部分 ミッションはさらに困難です。
他の 60 の拡散軌跡 (LDM、EDM、ADM など) と比較することにより、著者らは、以前の RF 手法がより少ないサンプリングステップでより良いパフォーマンスを発揮したにもかかわらず、サンプリングが不十分であることを発見しました。ステップ数が増加すると、パフォーマンスは徐々に低下します。
この状況を回避するために、著者が提案した重み付き RF 手法を使用すると、モデルのパフォーマンスを向上し続けることができます。
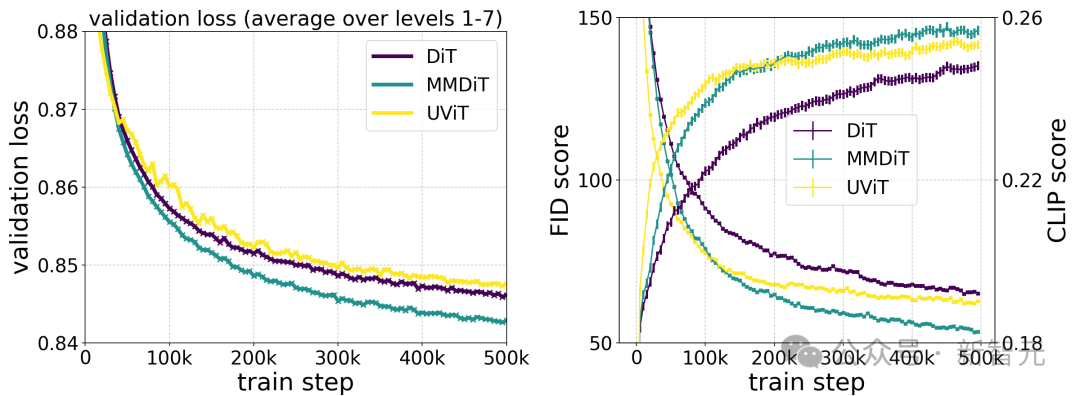
安定性 AI は、15 個のモジュールと 4 億 5000 万のパラメータから 38 個のモジュールと 8B のパラメータまで、さまざまなサイズの複数のモデルをトレーニングし、両方のサイズのモデルを見つけました。トレーニングステップにより、検証損失がスムーズに削減されます。
これがモデル出力の大幅な改善を意味するかどうかを検証するために、自動画像位置合わせメトリクスと人間の好みスコアも評価しました。
結果は、これらの評価指標が検証損失と強い相関があることを示しており、検証損失がモデルの全体的なパフォーマンスを測定するための有効な指標であることを示しています。
さらに、この拡大傾向は飽和点に達していないため、将来的にモデルのパフォーマンスをさらに向上できると楽観的に考えています。
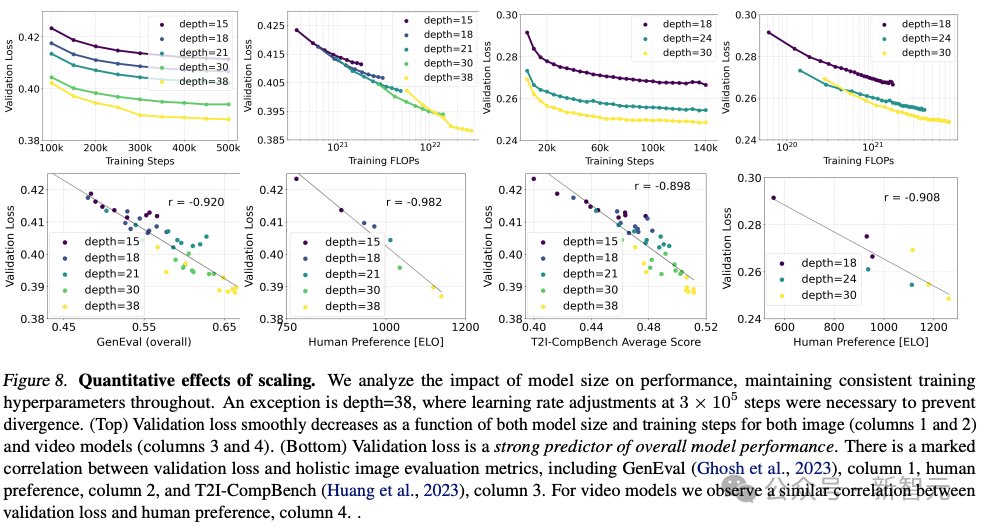
著者は、解像度 256 * 256 ピクセル、バッチ サイズ 4096 で、さまざまな数のパラメーターを使用して 500k ステップのモデルをトレーニングしました。

上の図は、大規模なモデルを長時間トレーニングした場合のサンプル品質への影響を示しています。
上の表は、GenEval の結果を示しています。著者らが提案した学習方法を使用し、学習画像の解像度を上げると、最大のモデルがほとんどのカテゴリで良好なパフォーマンスを示し、総合スコアで DALL・E を 3 上回りました。
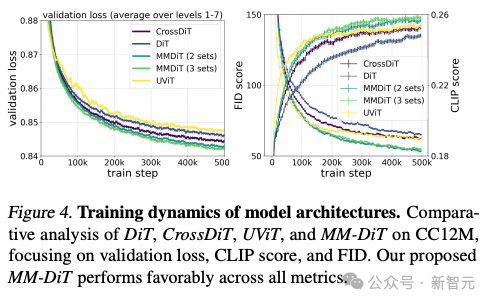
著者によるさまざまなアーキテクチャ モデルのテスト比較によると、MMDiT は非常に効果的で、DiT、Cross DiT、UViT、MM-DiT を上回っています。
推論フェーズ中にメモリを大量に消費する 4.7B パラメータの T5 テキスト エンコーダを削除することで、SD 3 のメモリ要件は大幅に軽減され、パフォーマンスの損失は最小限に抑えられます。
このテキスト エンコーダを削除しても、画像の視覚的な美しさには影響しません (T5 なしの勝率は 50%) が、テキストを正確に追従する能力はわずかに低下するだけです (46%)。勝率) 。
ただし、SD 3 のテキスト生成機能を最大限に活用するために、著者は依然として T5 エンコーダの使用を推奨します。
著者は、これがなければ、テキストを生成する組版のパフォーマンスがさらに向上することを発見したためです (勝率 38%)。

ネチズンは安定性 AI についてユーザーをからかい続けるが、その使用を拒否する彼らは少し焦っているようで、誰もが使えるように早くオンラインに公開するよう強く主張しました。
技術アプリケーションを読んだ後、ネチズンは、写真サークルがオープンソースがクローズドを圧倒する最初のトラックになりそうだと述べましたソース!
以上がStable Diffusion 3 の技術レポートが流出、Sora アーキテクチャは再び大きな成果を上げました!オープンソース コミュニティは Midjourney と DALL·E 3 を激しく攻撃していますか?の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



