


自動運転の分野では、研究者たちは GPT/Sora などの大型モデルの方向性も模索しています。
自動運転は、生成型 AI と比較して、最近の AI において最も活発な研究開発分野の 1 つでもあります。完全自動運転システムを構築する際の大きな課題は、悪天候、複雑な道路レイアウト、予測不可能な人間の行動など、複雑で予測不可能なシナリオを伴う AI のシーン理解です。
現在の自動運転システムは、通常、3D 認識、動作予測、計画の 3 つの部分で構成されます。具体的には、3D 認識は主に身近な物体の検出と追跡に使用されますが、珍しい物体とその属性を識別する能力には限界があります。一方、動作予測と計画は主に物体の軌道動作に焦点を当てますが、通常、物体と車両の関係は無視されます。 .間の意思決定レベルの相互作用これらの制限は、複雑な交通シナリオを処理する際の自動運転システムの精度と安全性に影響を与える可能性があります。したがって、将来の自動運転技術は、さまざまな種類の物体をより適切に識別して予測し、車両の走行経路をより効果的に計画してシステムのインテリジェンスと信頼性を向上させるためにさらに改良する必要があります。
実装 自動運転の鍵推進とは、データ駆動型のアプローチを知識駆動型のアプローチに変換することであり、これには論理的推論機能を備えた大規模なモデルのトレーニングが必要です。この方法でのみ、自動運転システムがロングテール問題を真に解決し、L4 機能に移行することができます。現在、GPT4 や Sora のような大型モデルの登場が続く中、スケール効果により強力な少数ショット/ゼロショット能力も発揮され、新たな開発の方向性を検討するようになりました。
最新の研究論文は清華大学クロスインフォメーション研究所とリーオート社から提供されており、その中でDriveVLMと呼ばれる新しいモデルが紹介されています。このモデルは、生成人工知能の分野で登場したビジュアル言語モデル (VLM) からインスピレーションを得ています。 DriveVLM は、視覚的な理解と推論において優れた能力を実証しました。
本研究は、業界で初めて自動運転速度制御システムを提案したものであり、その手法は主流の自動運転プロセスと論理的思考能力を備えた大規模モデルプロセスを完全に組み合わせたものであり、 (Orin プラットフォームに基づく) テストのために大規模なモデルをターミナルに正常にデプロイします。
DriveVLM は、シナリオ記述、シナリオ分析、階層計画という 3 つの主要モジュールを含む、Chain-of-Though (CoT) プロセスをカバーします。シーン記述モジュールでは、言語を使用して運転環境を説明し、シーン内の主要オブジェクトを特定します。シーン分析モジュールは、これらの主要オブジェクトの特性と自動運転車への影響を深く研究します。一方、階層計画モジュールは、段階的に計画を策定します。要素 アクションと決定はウェイポイントに記述されます。
これらのモジュールは、従来の自動運転システムの認識、予測、計画のステップに対応しますが、異なる点は、非常に困難であった物体の認識、意図レベルの予測、およびタスクレベルの計画を処理することです。過去に。
VLM は視覚的な理解においては優れた性能を発揮しますが、空間基盤と推論には限界があり、そのコンピューティング能力要件により、エンドサイドの推論の速度に課題が生じます。したがって、著者らはさらに、DriveVLM と従来のシステムの利点を組み合わせたハイブリッド システムである DriveVLMDual を提案します。 DriveVLM-Dual は、オプションで DriveVLM を、3D オブジェクト検出器、占有ネットワーク、モーション プランナーなどの従来の 3D 認識および計画モジュールと統合し、システムが 3D 接地および高周波計画機能を実現できるようにします。このデュアルシステム設計は、人間の脳の遅い思考プロセスと速い思考プロセスに似ており、運転シナリオのさまざまな複雑さに効果的に適応できます。
新しい研究では、シーン理解と計画 (SUP) タスクの定義もさらに明確になり、シーン分析とメタアクション計画における DriveVLM と DriveVLM-Dual の機能を評価するためのいくつかの新しい評価指標が提案されています。さらに、著者らは大規模なデータ マイニングとアノテーション作業を実行して、SUP タスク用の社内 SUP-AD データセットを構築しました。
nuScenes データセットと独自のデータセットで広範な実験を行った結果、特に少数のショットで DriveVLM の優位性が実証されました。さらに、DriveVLM-Dual は、最先端のエンドツーエンドの動作計画手法を超えています。
論文「DriveVLM: 自動運転と大規模ビジョン言語モデルの融合」

#論文リンク: https://arxiv.org/abs/ 2402.12289
プロジェクト接続: https://tsinghua-mars-lab.github.io/DriveVLM/
DriveVLM の全体的なプロセスを図 1 に示します:
連続フレームのビジュアル イメージをエンコードし、機能調整モジュールを通じて LMM と対話します。
VLM モデルの考え方をガイドするためにシーンの説明から開始し、最初に時間をガイドします。シーン、車線環境などの静的シーンは、運転の決定に影響を与える主要な障害物をガイドするために使用されます。
主要な障害物を分析し、従来の 3D 検出と VLM で理解された障害物を介してそれらを照合し、確認をさらに改善します。障害物の有効性と錯覚の除去、このシナリオにおける主要な障害物の特徴とそれらが運転に及ぼす影響について説明します。
減速、駐車、左折、右折などの重要な「メタ決定」を与え、次にそのメタ決定に基づいた運転戦略の説明を与え、最後にホスト車両の将来の走行軌跡。
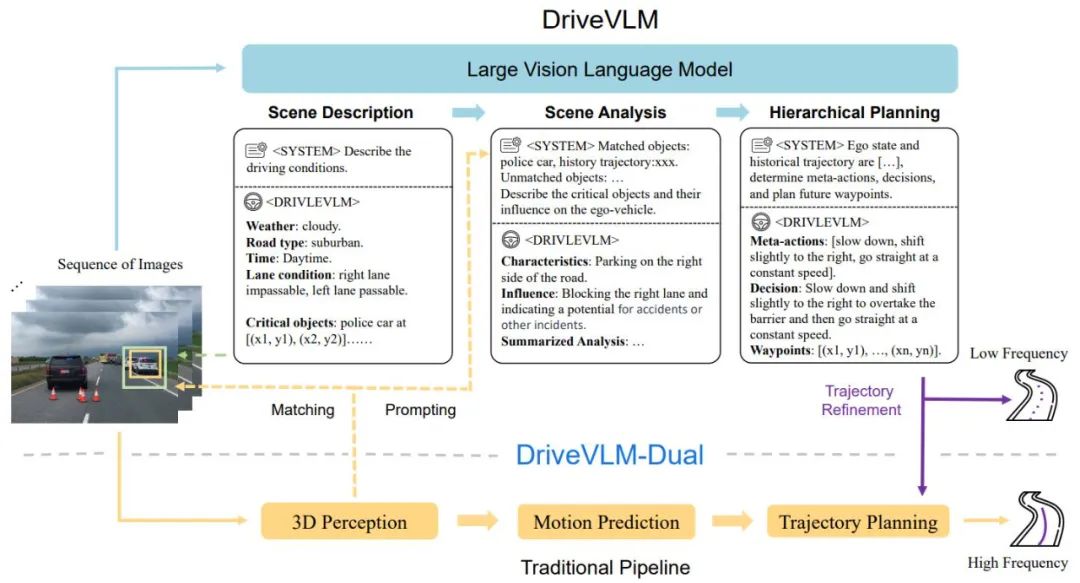
#図 1. DriveVLM および DriveVLM-Dual モデルのパイプライン。一連の画像は大規模視覚言語モデル (VLM) によって処理され、特別な思考連鎖 (CoT) 推論を実行して、運転計画の結果が導き出されます。大規模な VLM には、ビジュアル トランスフォーマー エンコーダーと大規模言語モデル (LLM) が含まれます。ビジュアル エンコーダーはイメージ タグを生成し、次にアテンション ベースのエクストラクターがこれらのタグを LLM と位置合わせし、最後に LLM が CoT 推論を実行します。 CoT プロセスは、シナリオ記述、シナリオ分析、階層計画の 3 つのモジュールに分割できます。
DriveVLM-Dual は、DriveVLM の環境に関する包括的な理解と意思決定軌道の推奨事項を活用することで、従来の自動運転パイプラインの意思決定と計画能力を向上させるハイブリッド システムです。 3D 認識の結果を言葉による合図に組み込んで 3D シーンの理解を強化し、リアルタイムのモーション プランナーで軌道のウェイポイントをさらに洗練します。 VLM はロングテール オブジェクトの識別や複雑なシーンの理解には優れていますが、オブジェクトの空間的位置や詳細な動作ステータスを正確に理解するのに苦労することが多く、この欠点が大きな課題となります。さらに悪いことに、VLM のモデル サイズが巨大であるため、待ち時間が長くなり、自動運転のリアルタイム応答能力が妨げられます。これらの課題に対処するために、著者は、DriveVLM と従来の自動運転システムの連携を可能にする DriveVLM-Dual を提案します。この新しいアプローチには、2 つの重要な戦略が含まれています。1 つは 3D 認識と組み合わせた主要オブジェクト分析で、高次元の運転意思決定情報を提供し、もう 1 つは高周波軌道の改良です。 さらに、複雑でロングテールの運転シナリオを処理する際の DriveVLM と DriveVLMDual の可能性を最大限に引き出すために、研究者らは、一連の評価指標だけでなく、シーン理解プランニングと呼ばれるタスクを正式に定義しました。さらに、著者らは、シーンの理解とデータセットの計画を管理するためのデータマイニングとアノテーションのプロトコルを提案しています。 モデルを完全にトレーニングするために、著者は、自動マイニング、知覚アルゴリズムのプレブラッシング、GPT-4 などの複数の方法と組み合わせた、一連の Drive LLM アノテーション ツールとアノテーション ソリューションを新たに開発しました。大規模なモデルの概要と手動の注釈。効率的な注釈ソリューションの現在のセットを形成します。各クリップ データには数十の注釈コンテンツが含まれています。
図 2 2. SUP-AD データセットのアノテーション サンプル。
著者らは、図 3 に示すように、SUP-AD での計画のためのシーン理解 (自動運転における計画のためのシーン理解) データセットを構築するための包括的なデータ マイニングと注釈パイプラインも提案しています。 、100k の画像と 1000k の画像とテキストのペアが含まれています。具体的には、まず大規模なデータベースからロングテール オブジェクト マイニングと挑戦的なシーン マイニングを実行してサンプルを収集し、次に各サンプルからキーフレームを選択し、さらにシーン アノテーションを実行します。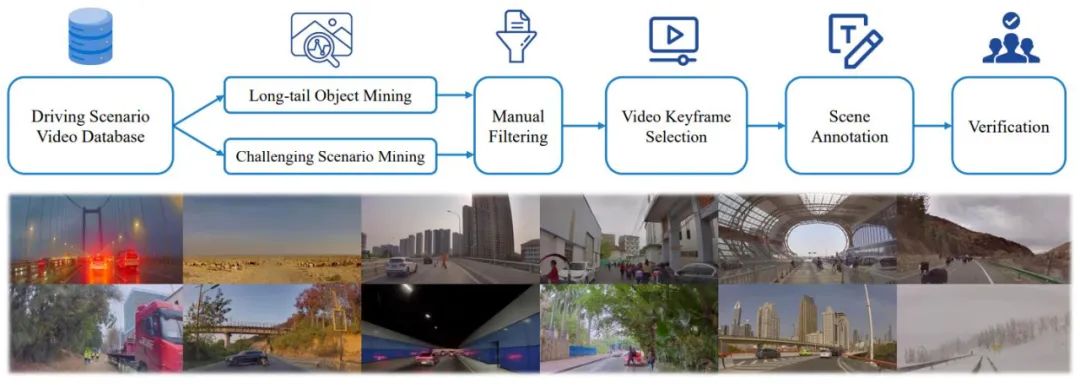
図 3. シナリオの理解とデータセットの計画を構築するためのデータ マイニングとアノテーション パイプライン (上)。データセットからランダムにサンプリングされたシナリオの例 (以下) は、データセットの多様性と複雑さを示しています。
SUP-AD は、7.5:1:1.5 の比率でトレーニング、検証、テストの部分に分かれています。著者らは、トレーニング分割でモデルをトレーニングし、新しく提案されたシーン記述とメタアクション メトリクスを使用して、検証/テスト分割でモデルのパフォーマンスを評価します。 nuScenes データセットは、それぞれ約 20 秒続く 1,000 のシーンを含む大規模な都市シーンの運転データセットです。キーフレームには、データセット全体にわたって 2Hz で均一に注釈が付けられます。ここで著者らは、検証セグメンテーションにおけるモデルのパフォーマンスを評価する指標として変位誤差 (DE) と衝突率 (CR) を採用します。 著者らは、表 1 に示すように、いくつかの大規模なビジュアル言語モデルを使用して DriveVLM のパフォーマンスを実証し、GPT-4V と比較しています。 DriveVLM はバックボーンとして Qwen-VL を利用しており、他のオープンソース VLM と比較して最高のパフォーマンスを実現し、応答性と柔軟なインタラクションが特徴です。最初の 2 つの大規模なモデルはオープンソース化されており、トレーニングの微調整に同じデータが使用されています。GPT-4V は、迅速なエンジニアリングのために複雑なプロンプトを使用します。 ###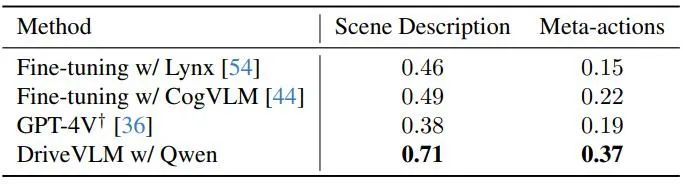
表 1. SUP-AD データ セットのテスト セットの結果。ここでは GPT-4V の公式 API が使用され、Lynx と CogVLM の場合はトレーニング分割が微調整に使用されます。
表 2 に示すように、DriveVLM-Dual は、VAD と組み合わせると、nuScenes 計画タスクで最先端のパフォーマンスを実現します。これは、新しい方法が複雑なシーンを理解するために調整されているにもかかわらず、通常のシーンでも良好に機能することを示しています。 DriveVLM-Dual は UniAD よりも大幅に改善されていることに注意してください。平均計画変位誤差は 0.64 メートル減少し、衝突率は 51% 減少します。
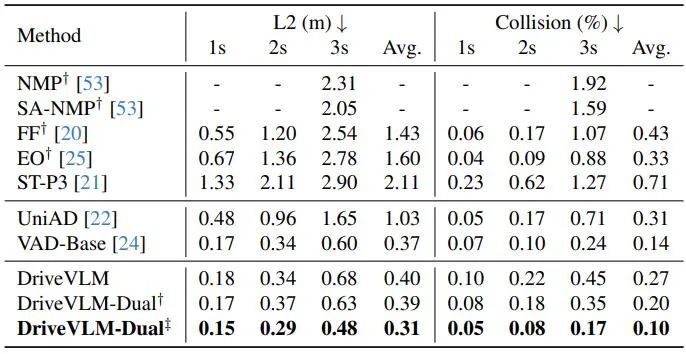
#表 2. nuScenes 検証データセットの計画結果。 DriveVLM-Dual は最適なパフォーマンスを実現します。 †Uni-ADを使用した知覚および占有予測結果を表します。 ‡ すべてのモデルが自我状態を入力として受け取る VAD を使用することを示します。図 4. DriveVLM の定性的結果。オレンジ色の曲線は、今後 3 秒間のモデルの計画された将来の軌道を表します。  DriveVLM の定性的結果を図 4 に示します。図 4a では、DriveVLM は、近づいてくるサイクリストに関する思慮深い計画決定と組み合わせて、現在のシーンの状況を正確に予測します。また、DriveVLM は、前方の交通警察の手信号を効果的に理解し、自車に進行を指示します。また、右側の三輪車に乗っている人も考慮して、正しい運転判断を下します。これらの定性的な結果は、複雑なシナリオを理解し、適切な運転計画を作成する DriveVLM モデルの優れた能力を示しています。
DriveVLM の定性的結果を図 4 に示します。図 4a では、DriveVLM は、近づいてくるサイクリストに関する思慮深い計画決定と組み合わせて、現在のシーンの状況を正確に予測します。また、DriveVLM は、前方の交通警察の手信号を効果的に理解し、自車に進行を指示します。また、右側の三輪車に乗っている人も考慮して、正しい運転判断を下します。これらの定性的な結果は、複雑なシナリオを理解し、適切な運転計画を作成する DriveVLM モデルの優れた能力を示しています。
図 7: SUP-AD データ集中におけるさまざまな運転シナリオ。

# 図 9. Sup-AD データの集中牛クラスターと牛群。牛の群れが車の前をゆっくりと移動しているため、政策は車がゆっくりと移動していることを推論し、牛から安全な距離を保つ必要があります。図 16. DriveVLM 出力の視覚化。 DriveVLM は倒木とその位置を正確に検出し、適切な迂回路を計画します。

以上が清華大学とアイデアルは、自動運転機能を向上させるための視覚的な大規模言語モデルである DriveVLM を提案しました。の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



