
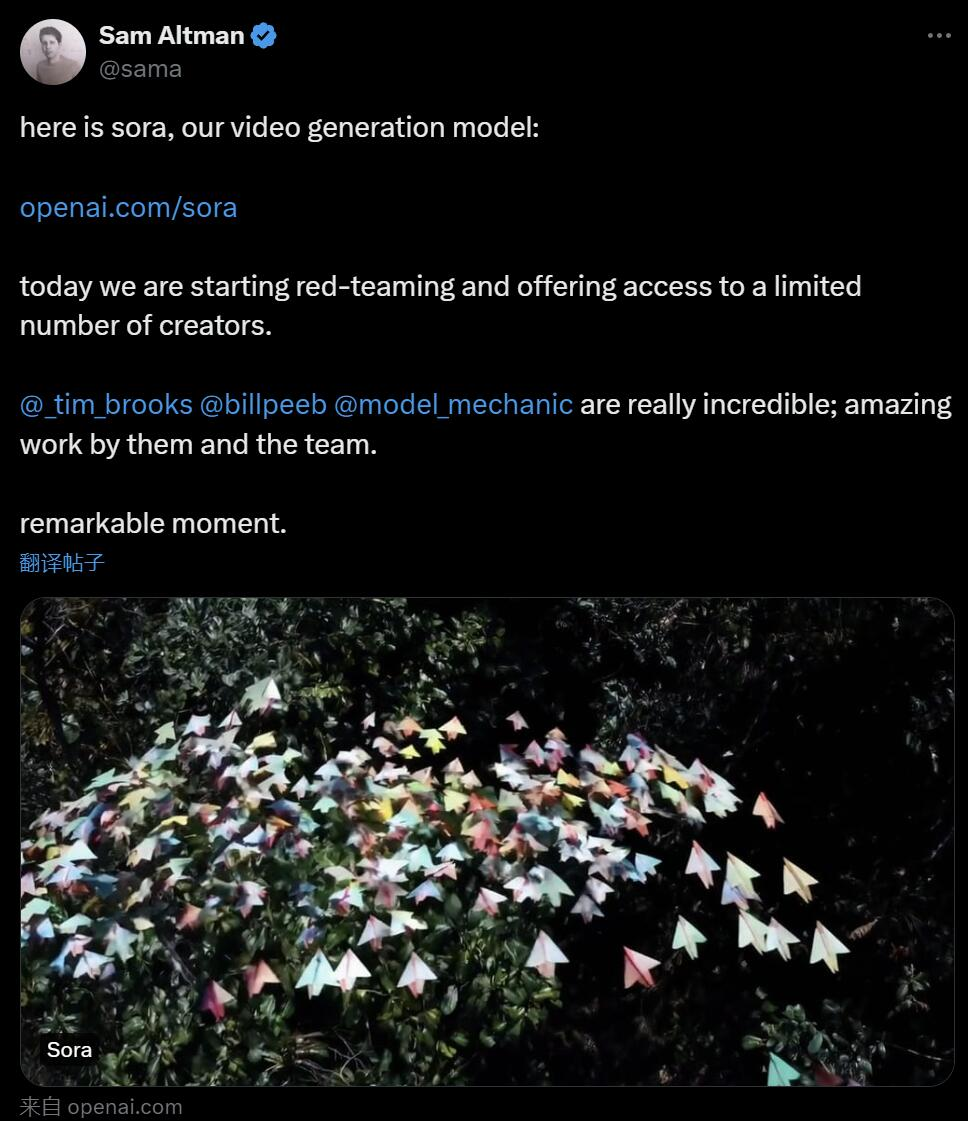
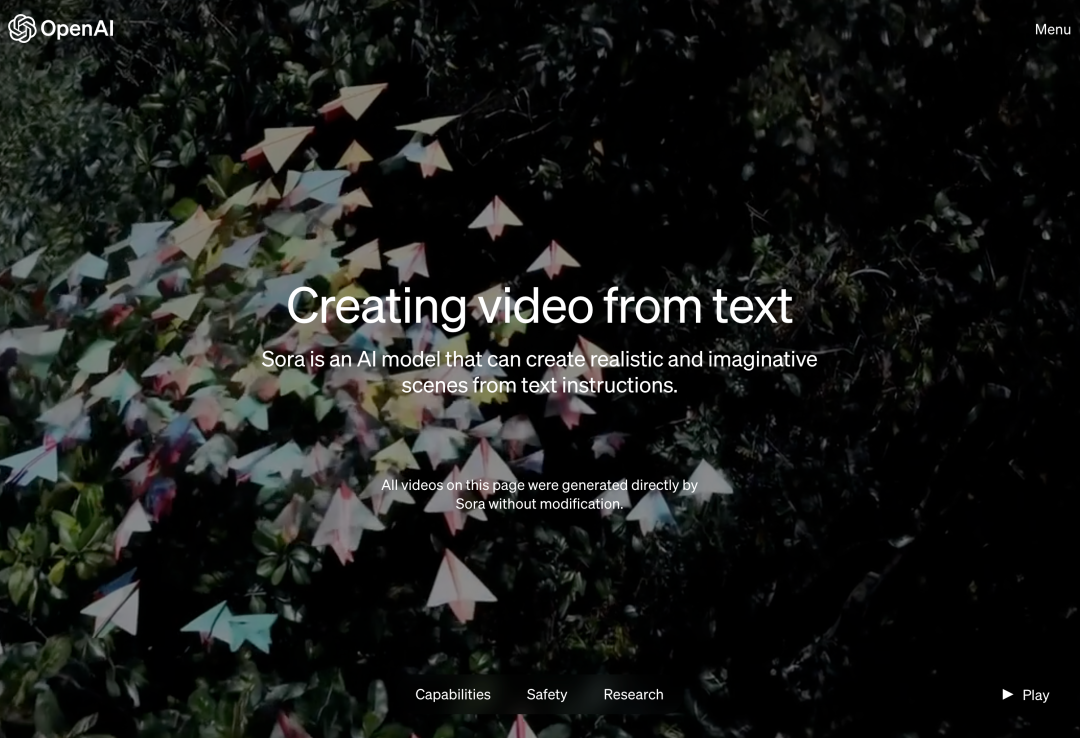
北京時間の今朝早く、OpenAI はテキストからビデオへの生成モデル Sora を正式にリリースしました。Runway、Pika、Google、Meta に続き、OpenAI はついにこの戦争に加わりました。ビデオ生成の分野。 サム アルトマンに関するニュースが発表された後、人々は OpenAI エンジニアによって実証された AI 生成のビデオ効果を初めて目にしました。 ? OpenAI は、短いまたは詳細な説明や静止画を指定すると、Sora は複数のキャラクター、さまざまなタイプのアクション、および背景の詳細を含む映画のような 1080p シーンを生成できると主張しています。 #ソラの何がそんなに特別なのでしょうか?言語を深く理解し、プロンプトを正確に解釈し、生き生きとした感情を表現する魅力的なキャラクターを生成することができます。同時に、Sora はプロンプト内のユーザーのリクエストを理解できるだけでなく、それが物理世界でどのように存在するかを理解することもできます。 公式ブログでは、OpenAI が Sora によって生成された多くのビデオ例を提供しており、少なくとも以前に登場したテキスト生成ビデオ技術に匹敵する印象的な効果を実証しています。 まず、Sora はさまざまなスタイル (フォトリアリスティック、アニメーション、白黒など) で最大 1 分間のビデオを生成できます。ビデオモデルはかなり長いです。 ビデオは適度な一貫性を維持しており、物体が物理的にありえない方向に移動するなど、いわゆる「AI の奇妙さ」に常に屈するわけではありません。 まず、Sora に辰年の中国のドラゴン ダンスのビデオを生成させます。 
たとえば、「プロンプト: カリフォルニア ゴールド ラッシュの歴史的な映像」と入力します。 
#プロンプトを入力: 中に禅の庭があるガラス球の拡大図。球体の中にはドワーフがいて、砂に模様を作り出しています。 
プロンプトを入力: マジックアワー中にマラケシュに立つ、まばたきする 24 歳の女性の極端なクローズアップ、70 mm で撮影されたフィルム、被写界深度、鮮やかな色色、映画。 
入力プロンプト: 東京郊外を通過する電車の窓に映る反射。 
プロモーションに入る: サイバーパンク環境におけるロボットのライフ ストーリー。 
この写真はあまりにもリアルであると同時にあまりにも奇妙ですしかし、OpenAI は現在のモデルにも弱点があることを認めています。複雑なシーンでの物理現象を正確にシミュレートすることが困難な場合があり、特定の因果関係を理解できない場合があります。また、モデルは、左と右などのキューの空間的詳細を混乱させる可能性があり、特定のカメラの軌跡をたどるなど、時間の経過に伴うイベントを正確に記述することが困難になる可能性があります。 たとえば、特に多くのエンティティが含まれるシーンでは、動物や人が生成プロセス中に自発的に出現することがわかりました。 次の例では、プロンプトはもともと「草に囲まれた人里離れた砂利道で、5 匹のハイイロオオカミの子犬が遊んだり追いかけたりしていました。子犬たちは走ったり跳ねたりしていました。」しかし、生成された「コピー アンド ペースト」画像は、いくつかの神秘的な幽霊の伝説を非常に思い出させます: 
次の例もあります。ろうそくの火を吹き消す前と後では、炎がまったく変化せず、奇妙なことが明らかになりました: 
Sora の背後にあるモデルの詳細についてはほとんどわかっていません。 OpenAI ブログによると、さらなる情報は今後の技術文書で公開される予定です。 いくつかの基本情報がブログで明らかにされました: Sora は、最初は静的なノイズのように見えるビデオを生成し、その後、複数のステップを通じてノイズを除去する拡散モデルです。一歩ずつ。 Midjourney および Stable Diffusion の画像およびビデオ ジェネレーターも拡散モデルに基づいています。ただし、OpenAI Sora によって生成されたビデオの品質ははるかに優れていることがわかります。これらの競合他社の以前のモデルは AI が生成した画像のストップモーション アニメーションのように感じられたのに対し、Sora は実際のビデオを作成しているように感じられます。 #Sora はビデオ全体を一度に生成したり、生成されたビデオを拡張して長くしたりできます。 OpenAI は、モデルに一度に複数のフレームを予測させることで、被写体が一時的に視線から外れた場合でも確実に無傷のままであることを保証するという困難な問題を解決します。 GPT モデルと同様に、Sora もトランスフォーマー アーキテクチャを使用して優れたスケーリング パフォーマンスを実現します。 #OpenAI はビデオや画像をパッチと呼ばれる小さなデータ単位のコレクションとして表し、各パッチは GPT のトークンに似ています。データ表現を統一することで、OpenAI は、さまざまな継続時間、解像度、アスペクト比を含む、これまでよりも広範囲のビジュアル データに対して拡散トランスフォーマーをトレーニングできるようになります。 Sora は、DALL・E および GPT モデルに関する過去の研究に基づいています。 DALL・E 3 の要約技術を使用して、ビジュアル トレーニング データに対して説明性の高い字幕を生成します。その結果、モデルは、生成されたビデオ内のユーザーのテキスト キューをより忠実にたどることができます。 このモデルは、テキストの説明のみに基づいてビデオを生成できることに加えて、既存の静止画像に基づいてビデオを生成し、画像コンテンツを正確かつ細心の注意を払ってアニメーション化することができます。このモデルは、既存のビデオを抽出して拡張したり、欠落しているフレームを埋めたりすることもできます。 参考リンク:https://openai.com/sora以上が春節ギフトパッケージ! OpenAI が最初のビデオ生成モデルをリリース、ネチズンを感動させた 60 秒の高解像度の傑作の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。



















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



