


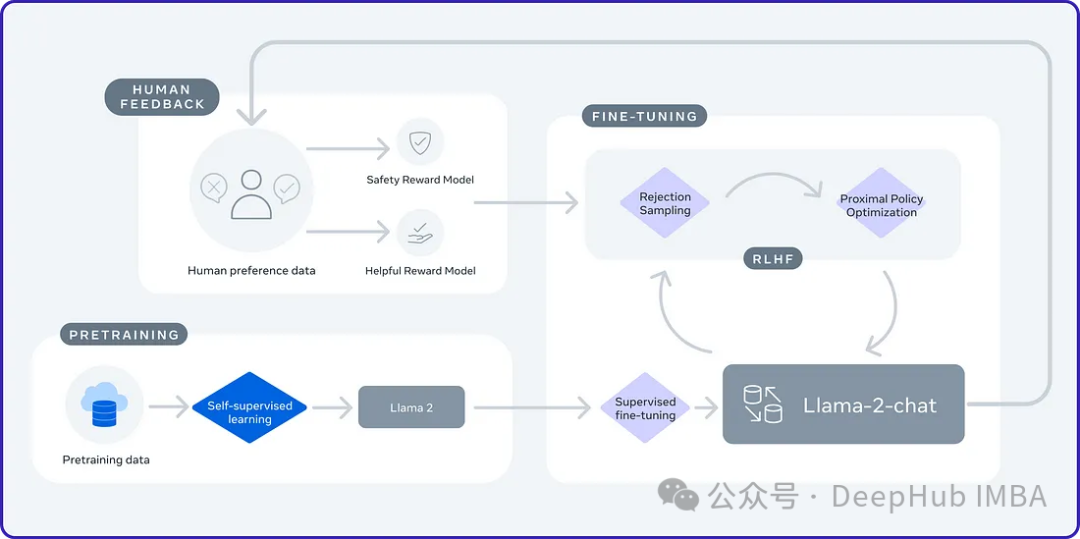
2024 年は、大規模言語モデル (LLM) が急速に開発される年です。 LLM のトレーニングでは、教師あり微調整 (SFT) や人間の好みに依存する人間のフィードバックによる強化学習 (RLHF) などのアライメント手法が重要な技術手段です。これらの方法は LLM の開発において重要な役割を果たしてきましたが、位置合わせ方法には手動で注釈を付けた大量のデータが必要です。この課題に直面して、微調整は活発な研究分野となっており、研究者は人間のデータを効果的に活用できる方法の開発に積極的に取り組んでいます。したがって、位置合わせ方法の開発は、LLM 技術のさらなる進歩を促進するでしょう。
カリフォルニア大学は最近研究を実施し、SPIN (Self Play fine tuNing) と呼ばれる新しいテクノロジーを導入しました。 SPIN は、AlphaGo Zero や AlphaZero などのゲームで成功した自動対局メカニズムを利用して、LLM (言語学習モデル) が自動対局に参加できるようにします。このテクノロジーにより、人間であっても、より高度なモデル (GPT-4 など) であっても、専門のアノテーターが必要なくなります。 SPIN のトレーニング プロセスには、新しい言語モデルのトレーニングと、一連の反復を通じて、言語モデルが独自に生成した応答と人間が生成した応答を区別することが含まれます。最終的な目標は、人間の応答と区別できない応答を生成する言語モデルを開発することです。本研究の目的は、言語モデルの自己学習能力をさらに向上させ、人間の表現や思考に近づけることです。本研究の成果は、自然言語処理の開発に新たなブレークスルーをもたらすことが期待されます。
セルフゲームは、自分のコピーと対戦することで、学習環境の挑戦と複雑さを増す学習テクニックです。このアプローチにより、エージェントはそれ自体のさまざまなバージョンと対話できるようになり、その機能が向上します。 AlphaGo Zero はセルフゲームの成功例です。

#セルフ ゲームは、マルチエージェント強化学習 (MARL) において効果的な方法であることが証明されています。ただし、これを大規模言語モデル (LLM) の拡張に適用するのは新しいアプローチです。セルフゲームを大規模な言語モデルに適用することで、より一貫性のある情報豊富なテキストを生成する能力をさらに向上させることができます。この手法により、言語モデルのさらなる開発と改善が促進されることが期待されます。
セルフプレイは、競争環境でも協力環境でも適用できます。競争では、アルゴリズムのコピーが目標を達成するために互いに競合し、協力では、コピーが共通の目標を達成するために協力します。教師あり学習、強化学習、その他のテクノロジーと組み合わせてパフォーマンスを向上させることができます。
SPIN は 2 人用のゲームのようなものです。このゲームの内容:
マスター モデル (新しい LLM) の役割は、言語モデル (LLM) によって生成された応答と人間によって作成された応答を区別することを学習することです。各反復で、マスター モデルは LLM を積極的にトレーニングして、応答を認識して区別する能力を向上させます。
敵対者モデル (旧 LLM) は、人間が生成するものと同様の応答を生成する役割を担っています。これは、セルフゲーム メカニズムを使用して、過去の知識に基づいて出力を生成する、前の反復の LLM を通じて生成されます。敵対者モデルの目標は、新しい LLM がそれが機械によって生成されたものであるかどうかを確信できないほど現実的な応答を作成することです。
このプロセスは GAN に非常に似ていますが、それでも異なります
SPIN のダイナミクスには、入力 (x ) と出力 (y ) のペアの構成。これらの例には人間によって注釈が付けられ、人間のような応答を認識するようにメイン モデルをトレーニングするための基礎として機能します。公開されている SFT データセットには、Dolly15K、Baize、Ultrachat などが含まれます。
言語モデル (LLM) と人間の応答を区別するようにメイン モデルをトレーニングするために、SPIN は目的関数を使用します。この関数は、実際のデータと敵対者モデルによって生成された応答との間の期待値のギャップを測定します。メイン モデルの目標は、この期待値のギャップを最大化することです。これには、実際のデータからの応答とペアになったキューに高い値を割り当て、敵対者モデルによって生成された応答のペアに低い値を割り当てることが含まれます。この目的関数は最小化問題として定式化されます。
マスター モデルの仕事は、実際のデータからのペアごとの割り当て値と相手モデルの応答からのペアごとの割り当て値の差を測定する損失関数を最小化することです。トレーニング プロセス全体を通じて、マスター モデルはこの損失関数を最小限に抑えるためにパラメーターを調整します。この反復プロセスは、マスター モデルが LLM 応答と人間の応答を効果的に区別できるようになるまで継続されます。
敵対者モデルの更新には、トレーニング中に実際のデータと言語モデルの応答を区別することを学習したマスター モデルの能力の向上が含まれます。マスター モデルが改善され、特定の関数クラスの理解が深まるにつれて、敵対者モデルなどのパラメーターも更新する必要があります。マスタープレイヤーが同じプロンプトに直面すると、学習した識別力を利用してその価値を評価します。
対戦相手モデル プレーヤーの目標は、言語モデルを強化して、その応答がマスター プレーヤーの実際のデータと区別できないようにすることです。これには、言語モデルのパラメータを調整するプロセスを設定する必要があります。目標は、安定性を維持しながら、言語モデルの応答に対するマスター モデルの評価を最大化することです。これには、改善が元の言語モデルから大きく逸脱しないようにするためのバランスをとる作業が含まれます。
少しわかりにくいように聞こえるので、簡単に要約します。
トレーニング中にモデルは 1 つだけですが、モデルは前のラウンドのモデル (旧 LLM) に分割されます。 /相手モデル) とメイン モデル (トレーニング中) では、トレーニング中のモデルの出力と前のラウンドのモデルの出力を比較として使用して、現在のモデルのトレーニングを最適化します。ただし、ここでは、トレーニング済みのモデルを相手モデルとして使用する必要があるため、SPIN アルゴリズムはトレーニング結果を微調整する場合にのみ適しています。
SPIN は、事前トレーニングされたモデルから合成データを生成します。この合成データは、新しいタスクでモデルを微調整するために使用されます。

上記は、元の論文の Spin アルゴリズムの疑似コードです。少し理解しにくいように思えます。仕組みをよりわかりやすく説明するために、Python で再現します。
元の論文では基本モデルとして Zephyr-7B-SFT-Full を使用しています。データセットには、OpenAI の Turbo API を使用して生成された約 140 万の会話で構成される、より大規模な Ultrachat200k コーパスのサブセットが使用されました。彼らは 50,000 個のキューをランダムにサンプリングし、基本モデルを使用して合成応答を生成しました。
# Import necessary libraries from datasets import load_dataset import pandas as pd # Load the Ultrachat 200k dataset ultrachat_dataset = load_dataset("HuggingFaceH4/ultrachat_200k") # Initialize an empty DataFrame combined_df = pd.DataFrame() # Loop through all the keys in the Ultrachat dataset for key in ultrachat_dataset.keys():# Convert each dataset key to a pandas DataFrame and concatenate it with the existing DataFramecombined_df = pd.concat([combined_df, pd.DataFrame(ultrachat_dataset[key])]) # Shuffle the combined DataFrame and reset the index combined_df = combined_df.sample(frac=1, random_state=123).reset_index(drop=True) # Select the first 50,000 rows from the shuffled DataFrame ultrachat_50k_sample = combined_df.head(50000)作成者のプロンプト テンプレート「
命令: {プロンプト}\n\n応答:」
# for storing each template in a list templates_data = [] for index, row in ultrachat_50k_sample.iterrows():messages = row['messages'] # Check if there are at least two messages (user and assistant)if len(messages) >= 2:user_message = messages[0]['content']assistant_message = messages[1]['content'] # Create the templateinstruction_response_template = f"### Instruction: {user_message}\n\n### Response: {assistant_message}" # Append the template to the listtemplates_data.append({'Template': instruction_response_template}) # Create a new DataFrame with the generated templates (ground truth) ground_truth_df = pd.DataFrame(templates_data)その後、次のようなデータが得られました: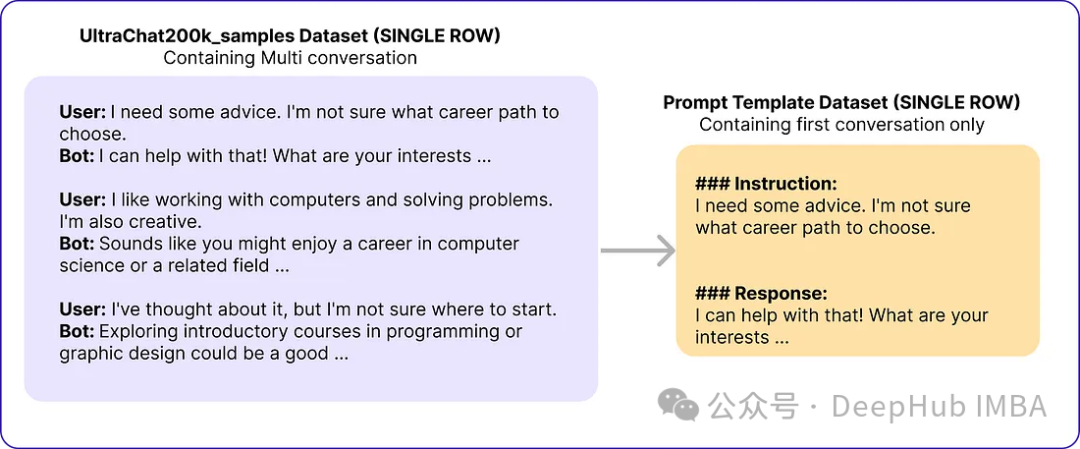
SPIN アルゴリズムは、言語モデル (LLM) のパラメーターを繰り返し更新して、グラウンド トゥルース応答と一致するようにします。このプロセスは、生成された応答とグランド トゥルースを区別することが困難になるまで継続され、高いレベルの類似性 (損失の低減) が達成されます。
# Importing the PyTorch library import torch # Importing the neural network module from PyTorch import torch.nn as nn # Importing the DeepSpeed library for distributed training import deepspeed # Importing the AutoTokenizer and AutoModelForCausalLM classes from the transformers library from transformers import AutoTokenizer, AutoModelForCausalLM # Loading the zephyr-7b-sft-full model from HuggingFace tokenizer = AutoTokenizer.from_pretrained("alignment-handbook/zephyr-7b-sft-full") model = AutoModelForCausalLM.from_pretrained("alignment-handbook/zephyr-7b-sft-full") # Initializing DeepSpeed Zero with specific configuration settings deepspeed_config = deepspeed.config.Config(train_batch_size=64, train_micro_batch_size_per_gpu=4) model, optimizer, _, _ = deepspeed.initialize(model=model, config=deepspeed_config, model_parameters=model.parameters()) # Defining the optimizer and setting the learning rate using RMSprop optimizer = deepspeed.optim.RMSprop(optimizer, lr=5e-7) # Setting up a learning rate scheduler using LambdaLR from PyTorch scheduler = torch.optim.lr_scheduler.LambdaLR(optimizer, lambda epoch: 0.2 ** epoch) # Setting hyperparameters for training num_epochs = 3 max_seq_length = 2048 beta = 0.12. 合成データの生成 (SPIN アルゴリズムの内部ループ)
この内部ループは、実際のデータ (コード) と一致する必要がある応答を生成する役割を果たします。トレーニング バッチの
# zephyr-sft-dataframe (that contains output that will be improved while training) zephyr_sft_output = pd.DataFrame(columns=['prompt', 'generated_output']) # Looping through each row in the 'ultrachat_50k_sample' dataframe for index, row in ultrachat_50k_sample.iterrows():# Extracting the 'prompt' column value from the current rowprompt = row['prompt'] # Generating output for the current prompt using the Zephyr modelinput_ids = tokenizer(prompt, return_tensors="pt").input_idsoutput = model.generate(input_ids, max_length=200, num_beams=5, no_repeat_ngram_size=2, top_k=50, top_p=0.95) # Decoding the generated output to human-readable textgenerated_text = tokenizer.decode(output[0], skip_special_tokens=True) # Appending the current prompt and its generated output to the new dataframe 'zephyr_sft_output'zephyr_sft_output = zephyr_sft_output.append({'prompt': prompt, 'generated_output': generated_text}, ignore_index=True)これは、ヒントの真の値とモデル出力の例です。 
3. 更新ルール
最小化問題をコーディングする前に、llm によって生成される出力の条件付き確率分布を計算する方法を理解することが重要です。元の論文ではマルコフ プロセスを使用しており、条件付き確率分布 pθ (y∣x) は分解によって次のように表現できます。 
この分解は、指定された入力の出力を意味します。シーケンス シーケンスの確率は、指定された入力シーケンスの各出力トークンに前の出力トークンの確率を乗算することによって計算できます。たとえば、出力シーケンスは「本を読むのが好きです」、入力シーケンスは「楽しいです」です。入力シーケンスが与えられると、出力シーケンスの条件付き確率は次のように計算できます: 
マルコフ プロセスの条件付き確率は、真の値と Zephyr LLM 応答の確率分布を計算するために使用され、その後、損失関数の計算に使用されます。ただし、最初に条件付き確率関数をエンコードする必要があります。
# Conditional Probability Function of input text def compute_conditional_probability(tokenizer, model, input_text):# Tokenize the input text and convert it to PyTorch tensorsinputs = tokenizer([input_text], return_tensors="pt") # Generate text using the model, specifying additional parametersoutputs = model.generate(**inputs, return_dict_in_generate=True, output_scores=True) # Assuming 'transition_scores' is the logits for the generated tokenstransition_scores = model.compute_transition_scores(outputs.sequences, outputs.scores, normalize_logits=True) # Get the length of the input sequenceinput_length = inputs.input_ids.shape[1] # Assuming 'transition_scores' is the logits for the generated tokenslogits = torch.tensor(transition_scores) # Apply softmax to obtain probabilitiesprobs = torch.nn.functional.softmax(logits, dim=-1) # Extract the generated tokens from the outputgenerated_tokens = outputs.sequences[:, input_length:] # Compute conditional probabilityconditional_probability = 1.0for prob in probs[0]:token_probability = prob.item()conditional_probability *= token_probability return conditional_probability
損失関数には、4 つの重要な条件付き確率変数が含まれています。これらの各変数は、基礎となる実際のデータまたは以前に作成された合成データに依存します。 
而lambda是一个正则化参数,用于控制偏差。在KL正则化项中使用它来惩罚对手模型的分布与目标数据分布之间的差异。论文中没有明确提到lambda的具体值,因为它可能会根据所使用的特定任务和数据集进行调优。
def LSPIN_loss(model, updated_model, tokenizer, input_text, lambda_val=0.01):# Initialize conditional probability using the original model and input textcp = compute_conditional_probability(tokenizer, model, input_text) # Update conditional probability using the updated model and input textcp_updated = compute_conditional_probability(tokenizer, updated_model, input_text) # Calculate conditional probabilities for ground truth datap_theta_ground_truth = cp(tokenizer, model, input_text)p_theta_t_ground_truth = cp(tokenizer, model, input_text) # Calculate conditional probabilities for synthetic datap_theta_synthetic = cp_updated(tokenizer, updated_model, input_text)p_theta_t_synthetic = cp_updated(tokenizer, updated_model, input_text) # Calculate likelihood ratioslr_ground_truth = p_theta_ground_truth / p_theta_t_ground_truthlr_synthetic = p_theta_synthetic / p_theta_t_synthetic # Compute the LSPIN lossloss = lambda_val * torch.log(lr_ground_truth) - lambda_val * torch.log(lr_synthetic) return loss
如果你有一个大的数据集,可以使用一个较小的lambda值,或者如果你有一个小的数据集,则可能需要使用一个较大的lambda值来防止过拟合。由于我们数据集大小为50k,所以可以使用0.01作为lambda的值。
这就是Pytorch训练的一个基本流程,就不详细解释了:
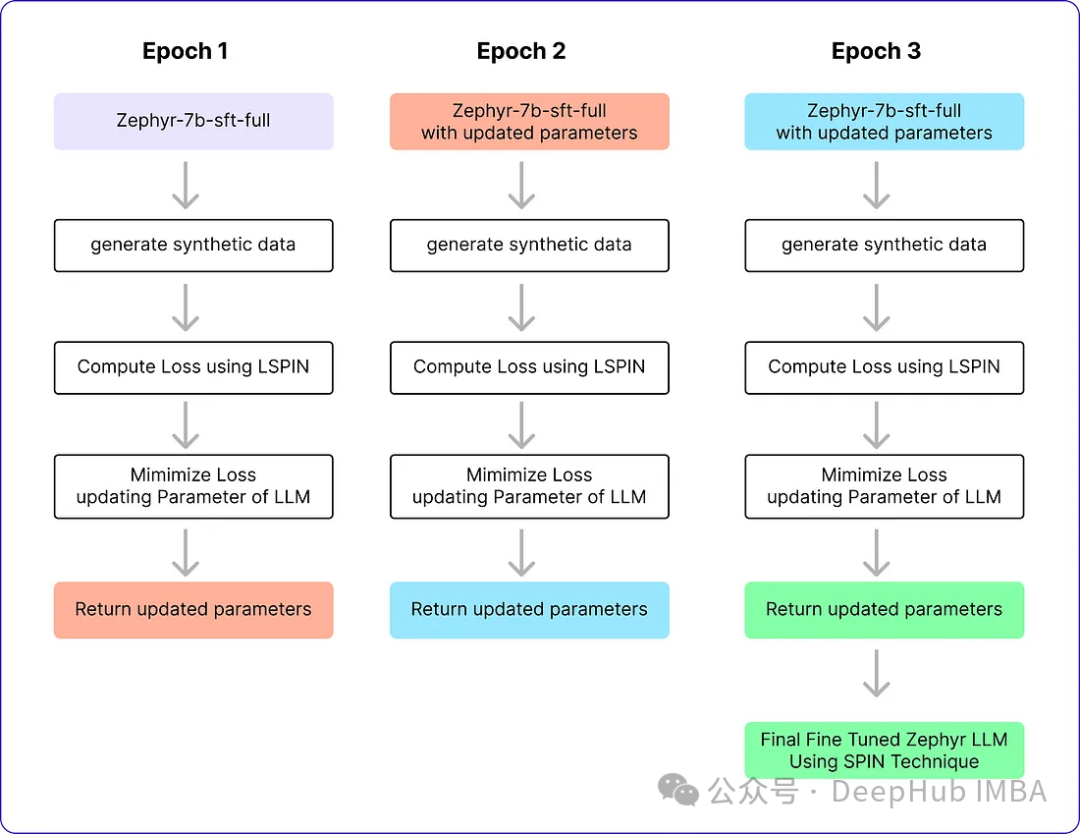
# Training loop for epoch in range(num_epochs): # Model with initial parametersinitial_model = AutoModelForCausalLM.from_pretrained("alignment-handbook/zephyr-7b-sft-full") # Update the learning ratescheduler.step() # Initialize total loss for the epochtotal_loss = 0.0 # Generating Synthetic Data (Inner loop)for index, row in ultrachat_50k_sample.iterrows(): # Rest of the code ... # Output == prompt response dataframezephyr_sft_output # Computing loss using LSPIN functionfor (index1, row1), (index2, row2) in zip(ultrachat_50k_sample.iterrows(), zephyr_sft_output.iterrows()):# Assuming 'prompt' and 'generated_output' are the relevant columns in zephyr_sft_outputprompt = row1['prompt']generated_output = row2['generated_output'] # Compute LSPIN lossupdated_model = model # It will be replacing with updated modelloss = LSPIN_loss(initial_model, updated_model, tokenizer, prompt) # Accumulate the losstotal_loss += loss.item() # Backward passloss.backward() # Update the parametersoptimizer.step() # Update the value of betaif epoch == 2:beta = 5.0我们运行3个epoch,它将进行训练并生成最终的Zephyr SFT LLM版本。官方实现还没有在GitHub上开源,这个版本将能够在某种程度上产生类似于人类反应的输出。我们看看他的运行流程
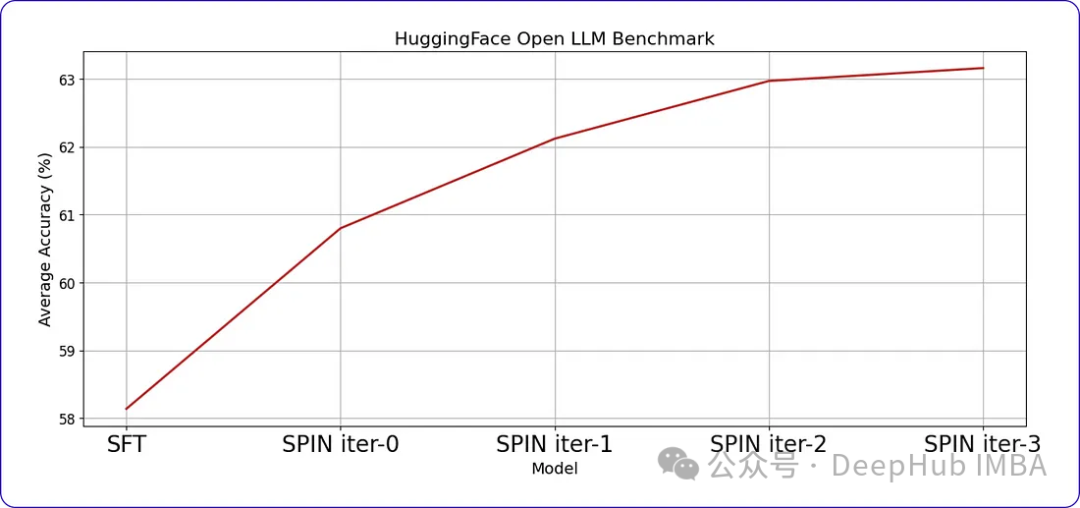
SPIN可以显著提高LLM在各种基准测试中的性能,甚至超过通过直接偏好优化(DPO)补充额外的GPT-4偏好数据训练的模型。
当我们继续训练时,随着时间的推移,进步会变得越来越小。这表明模型达到了一个阈值,进一步的迭代不会带来显著的收益。这是我们训练数据中样本提示符每次迭代后的响应。

以上がセルフゲーム微調整トレーニングのための SPIN テクノロジーを使用した LLM の最適化の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



