人工知能フィードバック (AIF) は RLHF に代わるものですか?
大規模モデルの分野では、微調整はモデルのパフォーマンスを向上させるための重要なステップです。オープンソースの大規模モデルの数が徐々に増加するにつれて、多くの微調整方法がまとめられ、その中には良い結果をもたらしたものもあります。 最近、メタ大学とニューヨーク大学の研究者は、大規模モデルが独自の微調整データを生成できるようにする「自己報酬法」を使用しました。これは、新しいものをもたらしました。衝撃的です。 新しい方法では、著者は Llama 2 70B の微調整を 3 回繰り返し、生成されたモデルは、AlpacaEval の既存の重要な大規模モデルの数を上回りました。 2.0 ランキング。Claude 2、Gemini Pro、GPT-4 などのモデル。 したがって、この論文は arXiv に投稿されてからわずか数時間で人々の注目を集めました。 このメソッドはまだオープンソースではありませんが、論文で使用されているメソッドは明確に説明されており、再現するのは難しくないと考えられています。 
人間の好みデータを使用して大規模言語モデル (LLM) を調整すると、事前トレーニングされたモデルの命令追跡パフォーマンスが大幅に向上することがよく知られています。 GPT シリーズでは、OpenAI はヒューマン フィードバック強化学習 (RLHF) の標準手法を提案しました。これにより、大規模なモデルが人間の好みから報酬モデルを学習し、報酬モデルを凍結して、強化学習を使用して LLM をトレーニングすることができます。この方法は大きな成功を収めました。 最近登場した新しいアイデアは、報酬モデルのトレーニングを完全に回避し、直接好みの最適化 (DPO) など、人間の好みを直接使用して LLM をトレーニングするというものです。上記のどちらの場合でも、調整のボトルネックは人間の嗜好データのサイズと品質です。RLHF の場合、調整の品質は、それらのデータからトレーニングされた凍結報酬モデルの品質によってもボトルネックになります。 Meta の新しい研究では、著者らは、このボトルネックを回避するために、LLM 調整中に凍結されずに継続的に更新される自己改善報酬モデルをトレーニングすることを提案しています。 このアプローチの鍵は、(報酬モデルと言語モデルに分割するのではなく) トレーニング中に必要なすべての機能を備えたエージェントを開発し、指示を反映させることです。タスクをフォローする 事前トレーニングとマルチタスク トレーニングでは、複数のタスクを同時にトレーニングすることでタスクの移行が可能です。 したがって、著者は自己報酬言語モデルを導入します。このモデルのエージェントは両方ともモデルに従う指示として機能し、与えられたプロンプトに対する応答を生成し、また新しい言語を生成して評価することもできます。例に基づいたもの、独自のトレーニング セットに追加するための指示。 新しいアプローチでは、反復 DPO に似たフレームワークを使用して、これらのモデルをトレーニングします。図 1 に示すように、シード モデルから開始して、各反復で自己説明作成プロセスが行われます。このプロセスでは、モデルが新しく作成されたプロンプトに対する応答候補を生成し、同じモデルによって報酬が割り当てられます。後者は、LLM-as-a-Judge からのプロンプトによって達成され、指示に従うタスクとみなすこともできます。生成されたデータから設定データセットを構築し、DPO を通じてモデルの次の反復をトレーニングします。 
著者によって提案された方法は、まず次のことを前提としています。トレーニングされた言語モデルと人間が注釈を付けた少量のシード データを使用して、次の両方のスキルを備えたモデルを構築します。高品質で役立つ (そして無害な) 応答を生成します。 #2. 自己説明の作成: 例に従って新しい指示を生成して評価し、独自のトレーニング セットに追加する機能。 #これらのスキルは、モデルが自己調整を実行できるようにするために使用されます。つまり、人工知能フィードバック (AIF) を使用してモデル自体を反復的にトレーニングするために使用されるコンポーネントです。 自己指示の作成には、候補応答の生成と、モデル自体にその品質を判断させることが含まれます。つまり、モデル自体が独自の報酬モデルとして機能するため、応答の必要性が置き換えられます。外部モデル。これは、LLM-as-a-Judge メカニズム [Zheng et al., 2023b]、つまり、指示に従うタスクとして応答評価を定式化することによって実現されます。この自己作成された AIF 嗜好データはトレーニング セットとして使用されました。 したがって、微調整プロセスでは、同じモデルが「学習者」と「判断者」の両方の役割で使用されます。このモデルは、新たな裁判官の役割に基づいて、状況に応じた微調整を通じてパフォーマンスをさらに向上させることができます。 全体的な自己調整プロセスは、一連のモデルを構築することで進行する反復的なプロセスであり、それぞれが前回のものよりも改善されています。ここで重要なのは、モデルは生成能力を向上させることができ、自身の報酬モデルと同じ生成メカニズムを使用できるため、報酬モデル自体がこれらの反復を通じて改善できることを意味し、これは報酬モデルに固有の標準と一致するということです。 . アプローチには違いがあります。 研究者らは、この方法により、これらの学習モデルの可能性の上限が高まり、将来的には学習モデル自体が改善され、制限的なボトルネックが解消されると考えています。 #図 1 に、この方法の概要を示します。
#実験

実験では、研究者らは、基本的な事前トレーニング モデルとして Llama 2 70B を使用しました。彼らは、自己報酬 LLM アライメントにより、ベースライン シード モデルと比較して、命令追従パフォーマンスが向上しただけでなく、報酬モデリング機能も向上したことを発見しました。
これは、反復トレーニングにおいて、モデルは、特定の反復において、前の反復よりも高品質の嗜好データ セットを自身に提供できることを意味します。この効果は現実世界では飽和する傾向がありますが、結果として得られる報酬モデル (したがって LLM) が人間によって書かれた生のシード データのみからトレーニングされたモデルよりも優れているという興味深い可能性をもたらします。
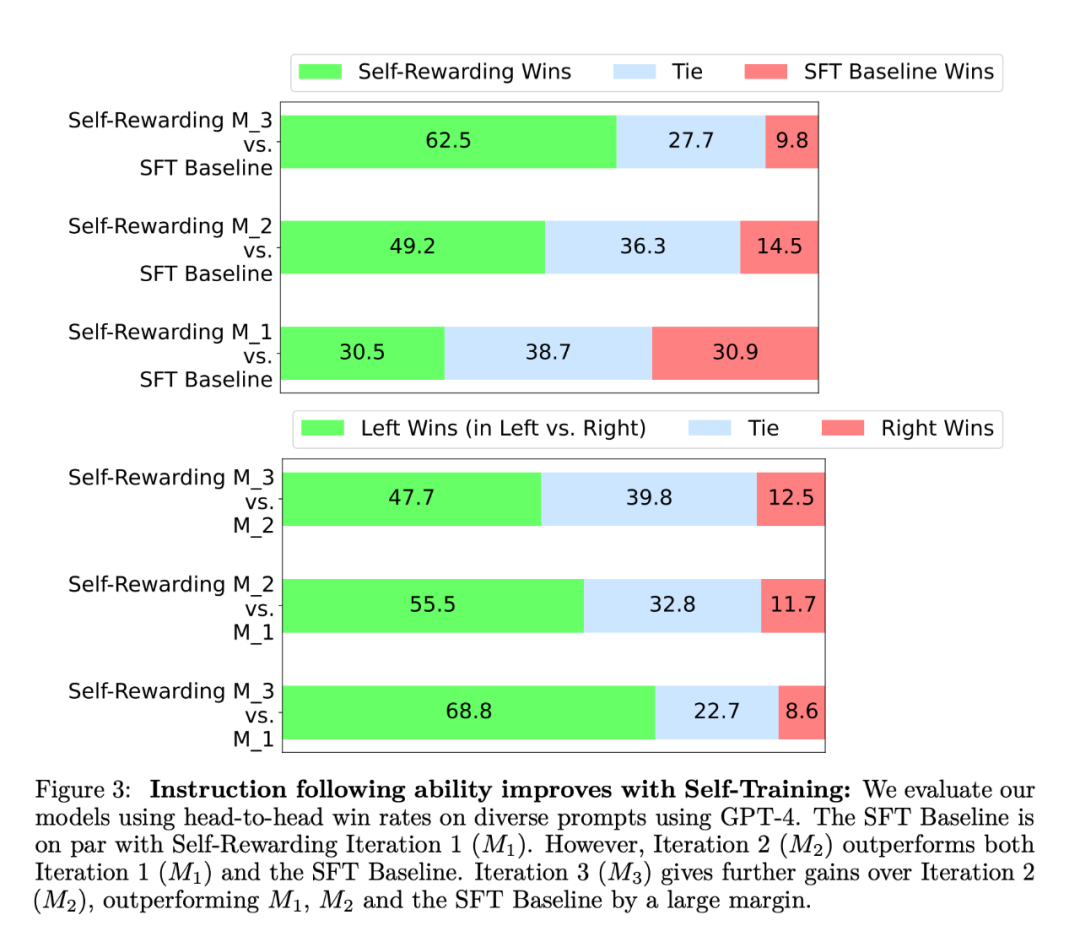
コマンド追従能力の観点から、実験結果を図 3 に示します。 研究者らは、AlpacaEval で自己報酬を評価しました。 2 ランキング リスト モデルの結果を表 1 に示します。彼らは、直接評価と同じ結論を観察しました。つまり、トレーニング反復の勝率は、反復 1 の 9.94%、反復 2 の 15.38%、反復 2 の 20.44% から GPT4-Turbo の勝率よりも高かったです。反復 3。一方、Iteration 3 モデルは、Claude 2、Gemini Pro、GPT4 0613 などの多くの既存モデルよりも優れています。
報酬モデリングの評価結果を表 2 に示します。結論は次のとおりです。
EFT は SFT ベースラインを改善しました。 IFT EFT を使用すると、IFT 単独と比較して 5 つの測定値すべてが向上しました。たとえば、人間とのペアごとの精度の一致は 65.1% から 78.7% に増加しました。 
自己トレーニングを通じて報酬モデリング能力を向上させます。一連の自己報酬トレーニングの後、次の反復で自己報酬を提供するモデルの能力が向上し、指示に従う能力も向上します。
-
LLMas-a-Judge ヒントの重要性。研究者らはさまざまなプロンプト形式を使用し、LLMas-a-Judge プロンプトは SFT ベースラインを使用した場合にペアごとの精度が高いことを発見しました。
著者は、自己報酬トレーニング方法により、モデルの命令追跡能力が向上するだけでなく、反復におけるモデルの報酬モデリング能力も向上すると考えています。 これは予備的な研究にすぎませんが、このようなモデルが将来の反復でより適切に報酬を割り当てることは、指示への遵守を改善し、高潔な行動を達成するための興味深い方向性であると思われます。サイクル。 この方法は、より複雑な判断方法に対する特定の可能性も開きます。たとえば、大規模なモデルでは、データベースを検索することで答えの正確さを検証でき、より正確で信頼性の高い出力が得られます。 参考コンテンツ: https://www.reddit.com/r/MachineLearning/comments/19atnu0/r_selfrewarding_ language_models_meta_2024/ 以上が自己報酬の下にある大規模モデル: Llama2 はメタ学習を通じて自身を最適化し、GPT-4 のパフォーマンスを上回るの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。




















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



