


k 最近傍アルゴリズムは、分類と認識のためのインスタンス ベースまたはメモリ ベースの機械学習アルゴリズムです。その原理は、特定のクエリ ポイントの最近傍データを見つけて分類することです。このアルゴリズムは保存されたトレーニング データに大きく依存しているため、ノンパラメトリック学習方法とみなすことができます。
k 最近傍アルゴリズムは、分類または回帰問題の処理に適しています。分類問題の場合は離散値を使用しますが、回帰問題の場合は連続値を使用します。分類する前に距離を定義する必要がありますが、一般的な距離の尺度には多くの選択肢があります。
これは一般的に使用される距離の尺度であり、実数値ベクトルに適しています。この式は、クエリ ポイントと別のポイントの間の直線距離を測定します。
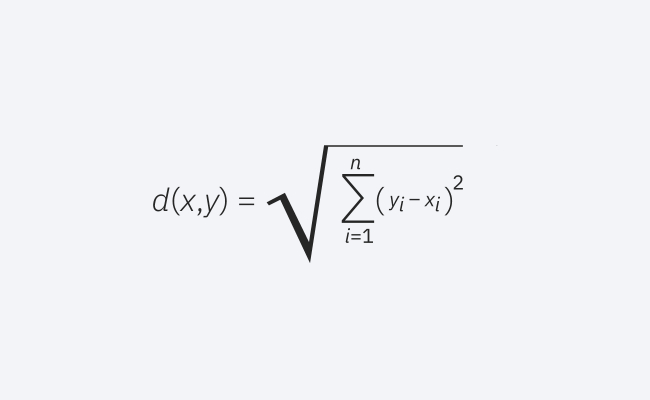
ユークリッド距離の公式
これも、2 点間の絶対値を測定する一般的な距離測定方法です。

マンハッタン距離の公式
この距離測定は、ユークリッド距離測定とマンハッタン距離測定の一般化された形式です。

ミンコフスキー距離の式
この手法は、ベクトルが一致しない点を特定するために、ブール値または文字列ベクトルとともによく使用されます。したがって、オーバーラップ対策とも呼ばれます。

ハミング距離の式
どのデータ ポイントが特定のクエリ ポイントに最も近いかを決定するには、次のようにします。クエリ ポイント間の距離と他のデータ ポイント間の距離を計算するために必要です。これらの距離測定は、クエリ ポイントをさまざまな領域に分割する決定境界を形成するのに役立ちます。
以上がK 最近傍アルゴリズムで一般的に使用される距離測定方法を適用するの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



