


オープンソースの MoE モデルに、ついに初の国内プレーヤーが登場しました!
性能はdense Llama 2-7Bモデルに劣りませんが、計算量は40%しかありません。
このモデルは、特に数学とコーディング能力の点で、ラマを圧倒する 19 面の戦士と呼ぶことができます。
これは、Deep Search チームの最新のオープンソース 160 億パラメータ エキスパート モデル DeepSeek MoE です。
DeepSeek MoE は、優れたパフォーマンスに加えて、コンピューティング能力を節約することを主な焦点としています。
このパフォーマンス アクティベーション パラメータ図では、これが「選択」され、左上隅の大きな空白領域を占めています。
リリースからわずか 1 日後、X に関する DeepSeek チームのツイートは大量のリツイートと注目を集めました。
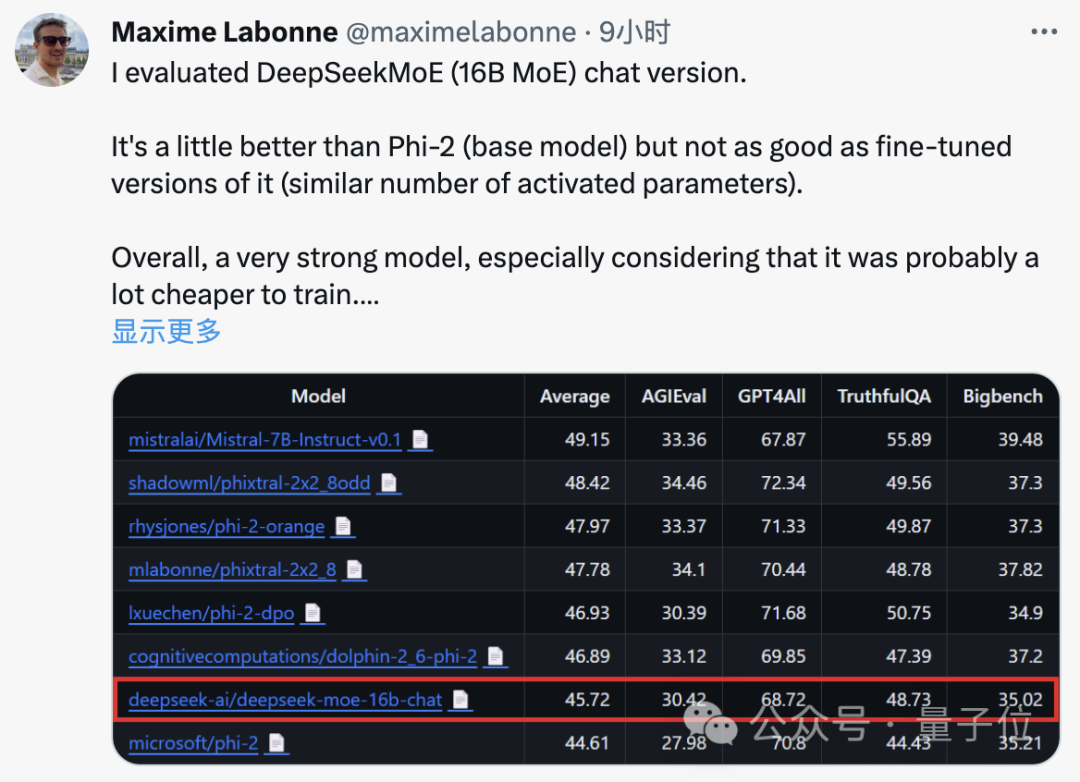
JP モルガンの機械学習エンジニア、マキシム・ラボンヌ氏もテスト後に、DeepSeek MoE のチャット版は Microsoft の「小規模モデル」Phi-2 よりも若干パフォーマンスが優れていると述べました。
同時に、DeepSeek MoE も GitHub で 300 個のスターを獲得し、Hugging Face テキスト生成モデル ランキングのホームページに掲載されました。
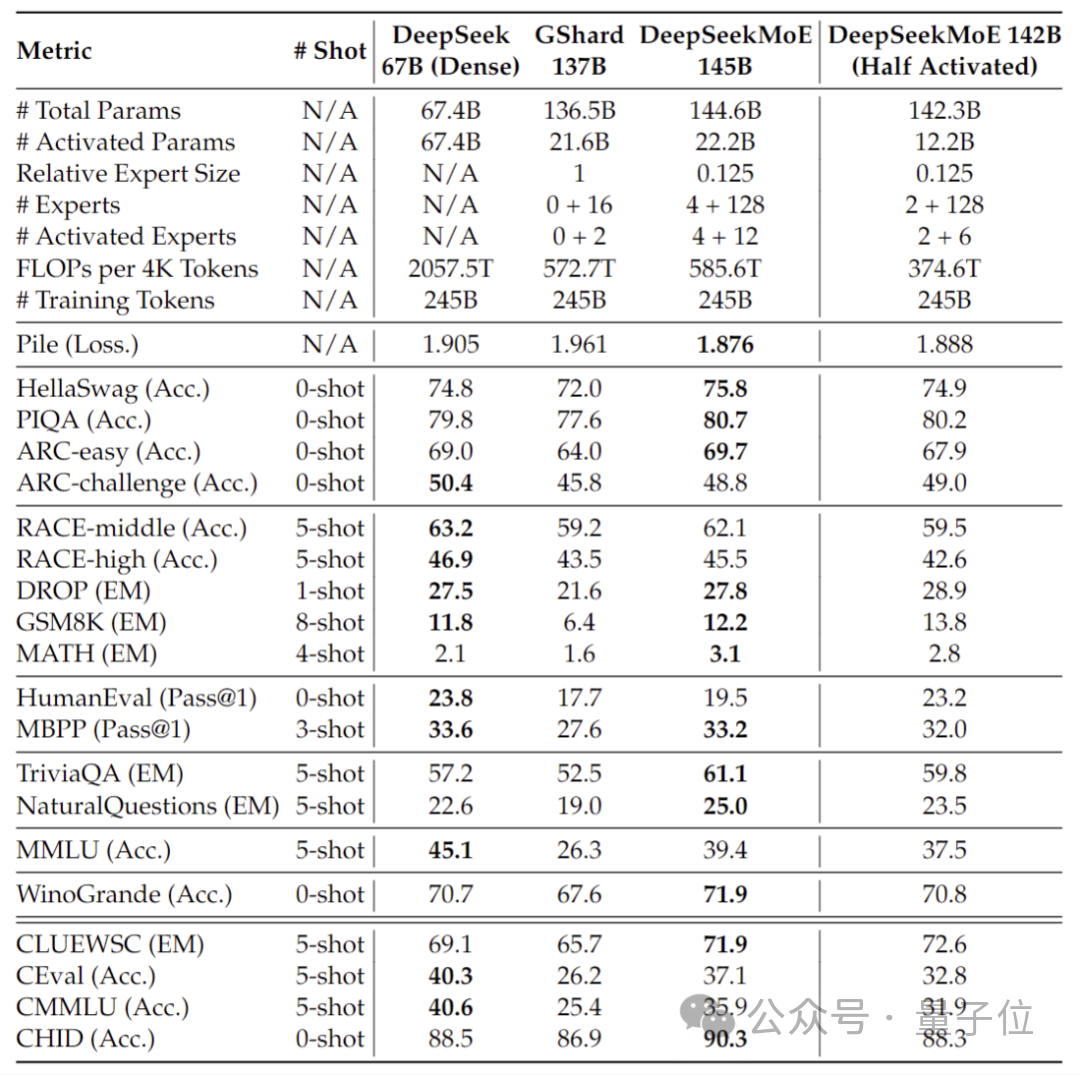
それでは、DeepSeek MoE の具体的なパフォーマンスはどのようなものでしょうか?
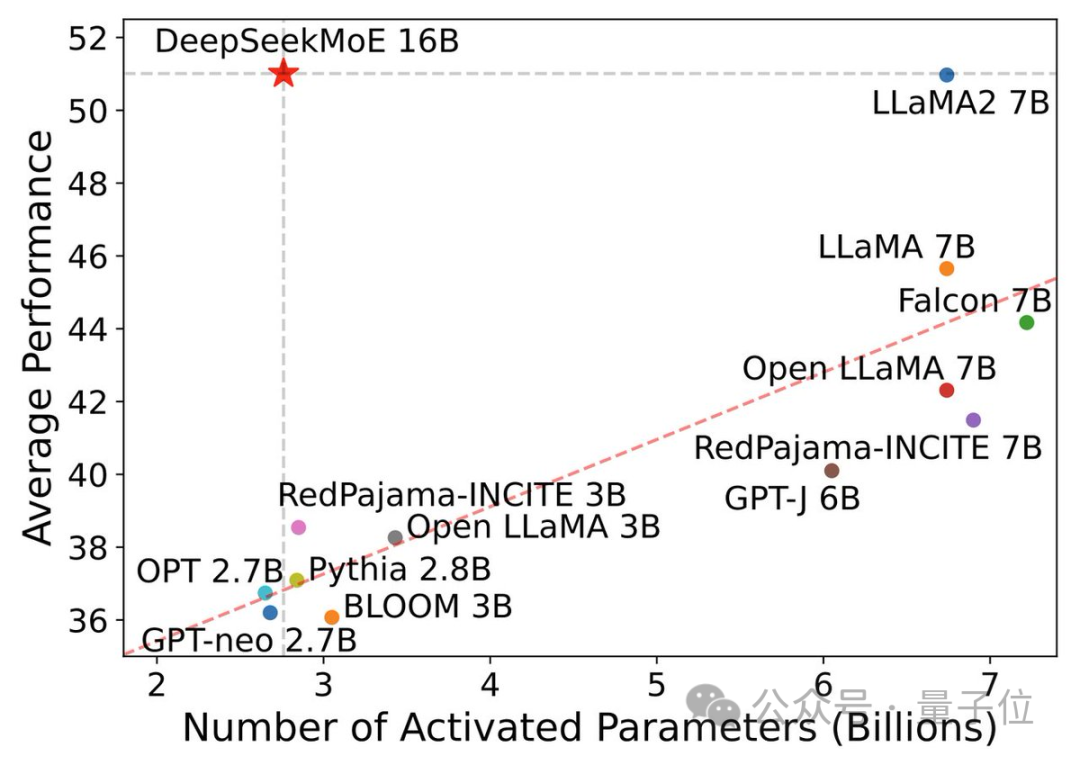
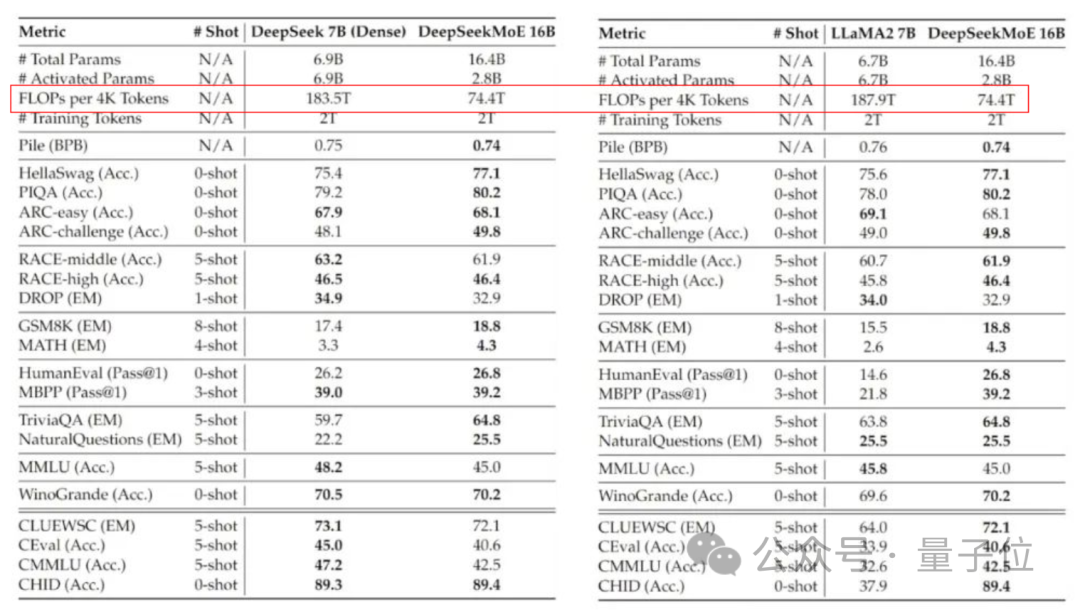
現在のバージョンの DeepSeek MoE には 160 億個のパラメータがあり、実際に有効化されるパラメータの数は約 28 億個です。
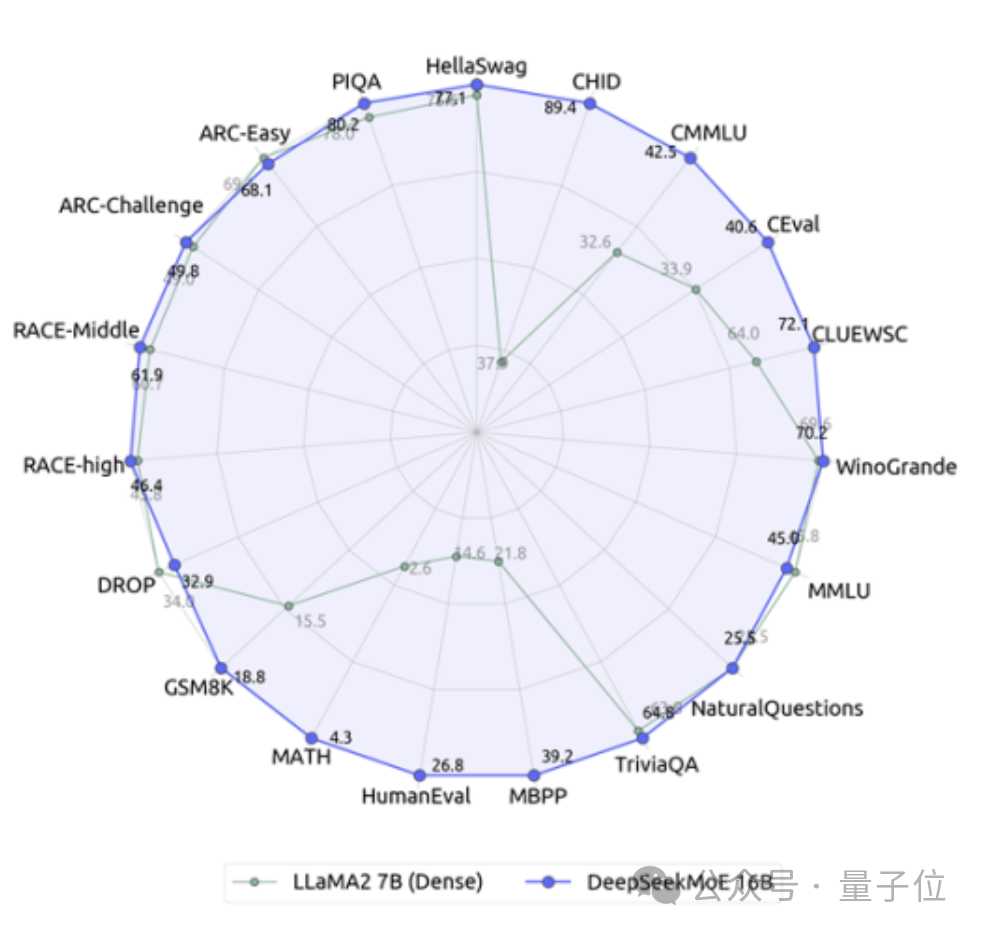
独自の 7B 高密度モデルと比較すると、19 データセットにおける 2 つのパフォーマンスには異なる長所と短所がありますが、全体的なパフォーマンスは比較的近いです。
同じく高密度モデルである Llama 2-7B と比較すると、DeepSeek MoE は数学やコードなどにおいて明らかな利点を示しています。
しかし、両方の高密度モデルの計算量は 4k トークンあたり 180TFLOP を超えますが、DeepSeek MoE の計算量は 74.4TFLOP のみで、この 2 つのモデルの 40% にすぎません。
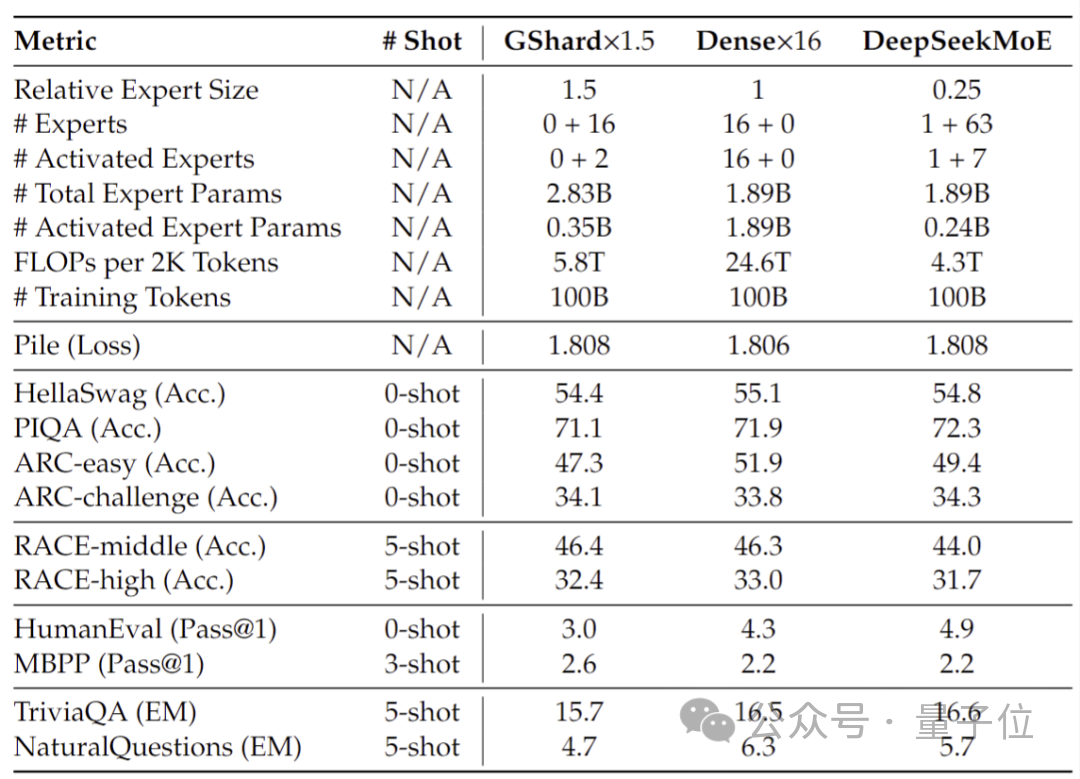
20 億のパラメーターで実施されたパフォーマンス テストでは、DeepSeek MoE が、より少ない計算で 1.5 倍のパラメーターを使用しても同じ MoE モデルのパフォーマンスを達成できることが示されています。 B は同等かそれ以上の結果を示しています。
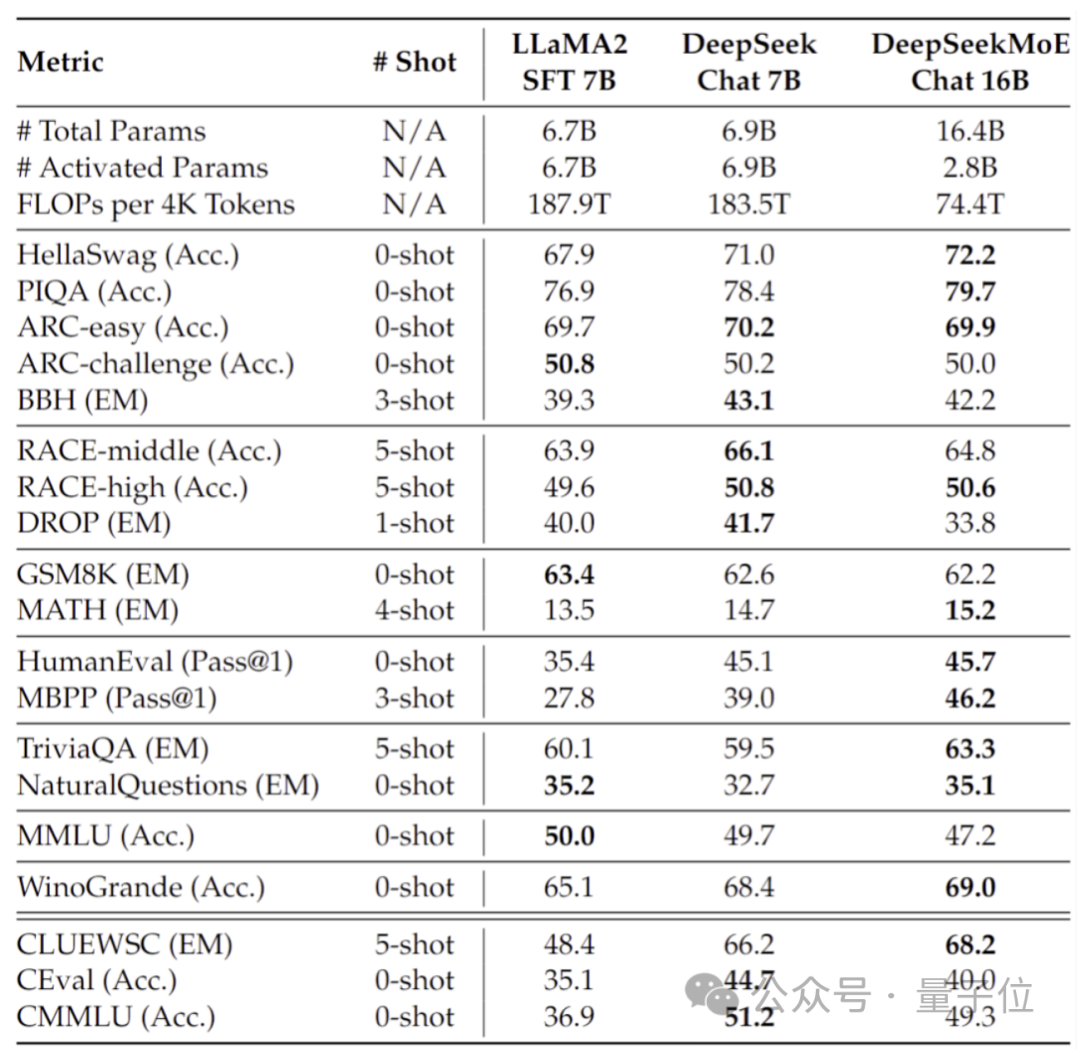
さらに、Deep Seek チームは SFT に基づいて DeepSeek MoE のチャット バージョンも微調整し、そのパフォーマンスも独自の高密度バージョンや Llama 2 に近づきました。 -7B。
さらに、DeepSeek チームは、DeepSeek MoE モデルの 145B バージョンが開発中であることも明らかにしました。
段階的な予備テストでは、145B DeepSeek MoE が GShard 137B に大きくリードしており、28.5% の計算量で DeepSeek 67B モデルの高密度バージョンと同等のパフォーマンスを達成できることが示されています。
研究開発が完了したら、チームは 145B バージョンもオープンソース化する予定です。
これらのモデルのパフォーマンスの背後には、DeepSeek が独自に開発した新しい MoE アーキテクチャがあります。
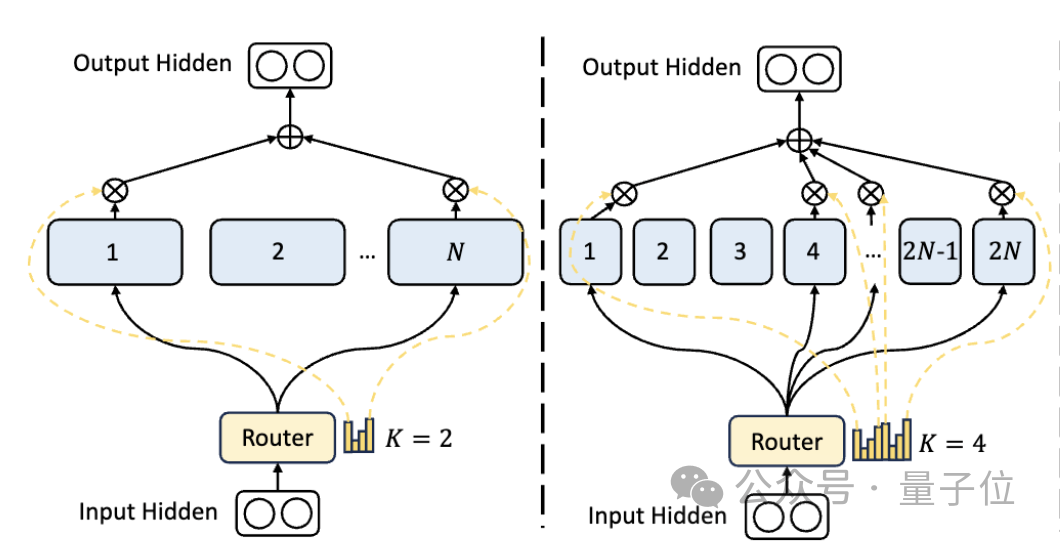
まず、従来の MoE アーキテクチャと比較して、DeepSeek にはよりきめ細かい専門部門があります。
パラメータの総数が固定されている場合、従来のモデルは N 人の専門家を分類できますが、DeepSeek は 2N 人の専門家を分類できます。
同時に、タスクを実行するたびに選択される専門家の数が従来のモデルの 2 倍になるため、使用されるパラメータの総数は変わりませんが、選択の自由度が高まります。
このセグメンテーション戦略により、アクティベーション専門家のより柔軟かつ適応的な組み合わせが可能になり、それによってさまざまなタスクにおけるモデルの精度と知識獲得の適切性が向上します。
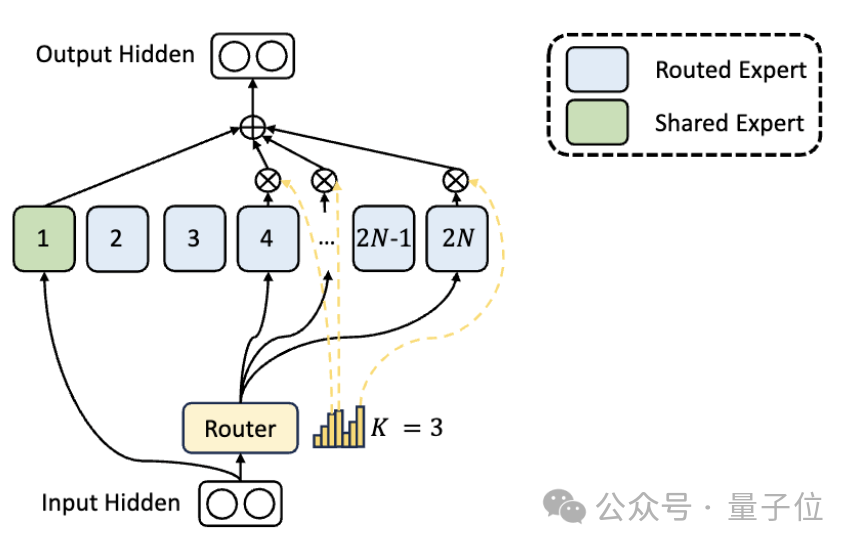
エキスパート部門の違いに加えて、DeepSeek では「共有エキスパート」設定も革新的に導入されています。
これらの共有エキスパートは、すべての入力のトークンをアクティブ化し、ルーティング モジュールの影響を受けません。目的は、さまざまなコンテキストで必要な共通の知識を取得して統合することです。
これらの共有知識を共有エキスパートに圧縮することで、他のエキスパート間のパラメーターの重複を減らすことができ、それによってモデルのパラメーター効率が向上します。
共有エキスパートを設定すると、他のエキスパートが独自の知識領域にさらに集中できるようになり、専門家の専門性の全体的なレベルが向上します。
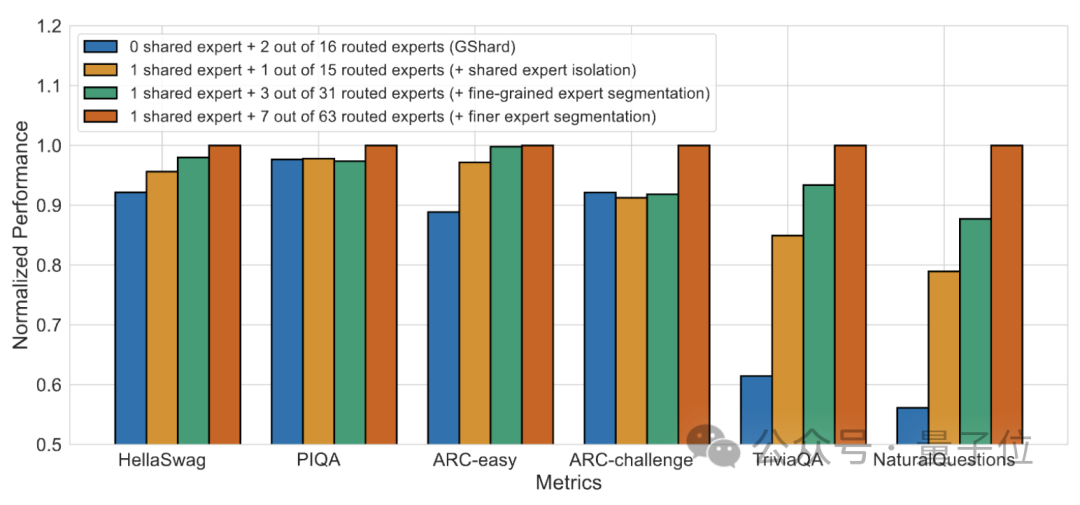
#アブレーション実験の結果は、両方のソリューションが DeepSeek MoE の「コスト削減と効率向上」において重要な役割を果たすことを示しています。
論文アドレス: https://arxiv.org/abs/2401.06066。
参考リンク: https://mp.weixin.qq.com/s/T9-EGxYuHcGQgXArLXGbgg。
以上が国内の大規模オープンソースMoEモデルを導入、Llama 2-7Bと同等の性能を持ちながら計算量を60%削減の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



