


OpenAI GPT-4V と Google Gemini は、非常に強力なマルチモーダル理解機能を実証し、マルチモーダル大規模モデル (MLLM) の迅速な開発を促進し、MLLM は現在業界で最も注目されている研究の方向性。
MLLM は、さまざまな視覚言語オープンタスクにおいて優れた指示追従能力を実現します。マルチモーダル学習に関するこれまでの研究では、異なるモダリティが連携して相互に促進できることが示されていますが、既存の MLLM 研究は主に、マルチモーダル タスクの能力の向上と、モーダル コラボレーションの利点とモーダル干渉の影響のバランスをとる方法に焦点を当てています。それは対処する必要があります。

論文を表示するには、次のリンクをクリックしてください: https://arxiv.org/pdf/2311.04257.pdf
次のコード アドレスを確認してください: https://github.com/X-PLUG/mPLUG-Owl/tree/main/mPLUG-Owl2
ModelScope エクスペリエンスアドレス: https://modelscope.cn/studios/damo/mPLUG-Owl2/summary
HuggingFace 体験アドレス リンク: https://huggingface.co/spaces/MAGAer13/mPLUG- Owl2
この問題に対応して、Alibaba のマルチモーダル大型モデル mPLUG-Owl がメジャー アップグレードされました。モーダルコラボレーションにより、プレーンテキストとマルチモーダリティのパフォーマンスを同時に向上させ、LLaVA1.5、MiniGPT4、Qwen-VLなどのモデルを上回り、さまざまなタスクで最高のパフォーマンスを実現します。具体的には、mPLUG-Owl2は、共有機能モジュールを利用して異なるモダリティ間の連携を促進し、各モダリティの特性を維持するためにモーダル適応モジュールを導入します。シンプルで効果的な設計により、mPLUG-Owl2 はプレーン テキストやマルチモーダル タスクなどの複数の分野で最高のパフォーマンスを実現します。モーダル コラボレーション現象の研究は、マルチモーダル大規模モデルの将来の開発にもインスピレーションを与えます
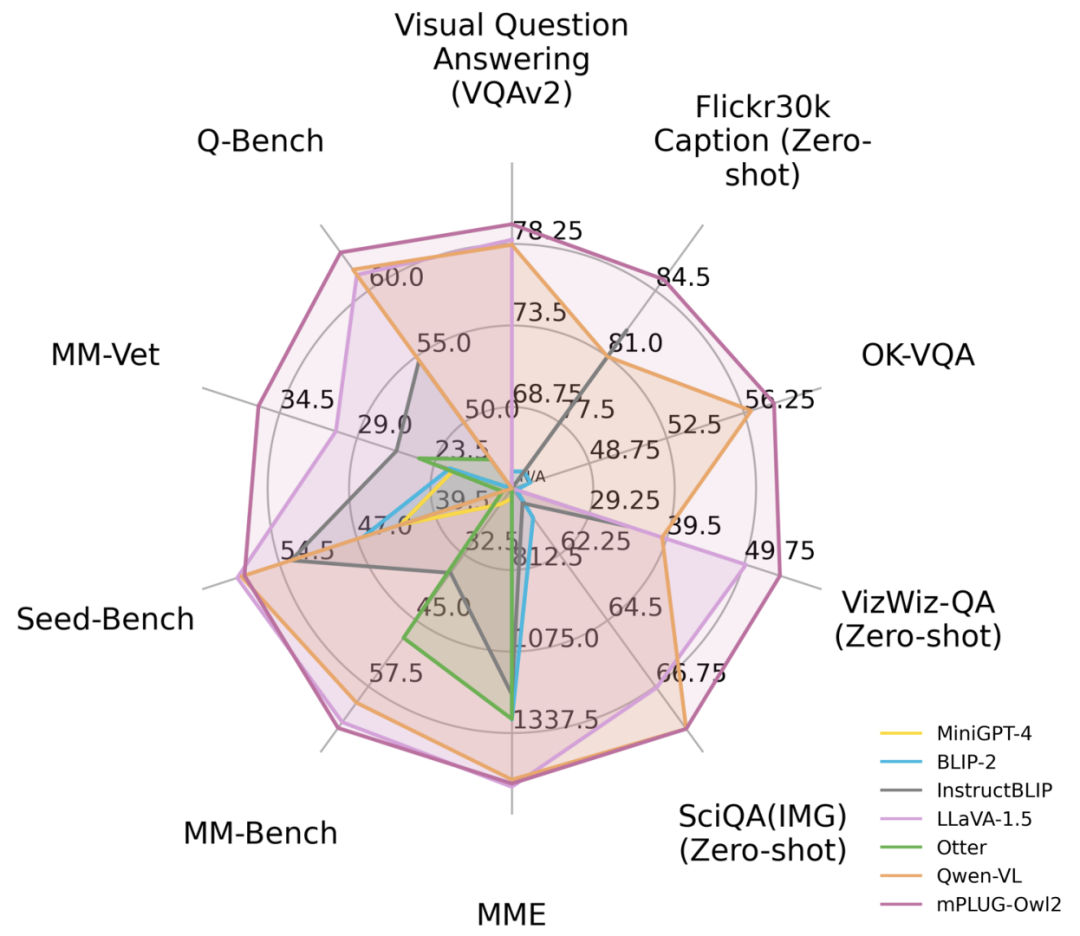
図 1 既存の MLLM モデルとのパフォーマンスの比較
メソッドの紹介 元の意味を変えないという目的を達成するには、内容を中国語に書き直す必要があります。
mPLUG-Owl2 モデルは主に 3 つの部分で構成されます。 ##Visual Encoder: ビジュアル エンコーダーとして、ViT-L/14 は、H x W の解像度を持つ入力画像を H/14 x W/14 のビジュアル トークンのシーケンスに変換し、Visual Abstractor に入力します。
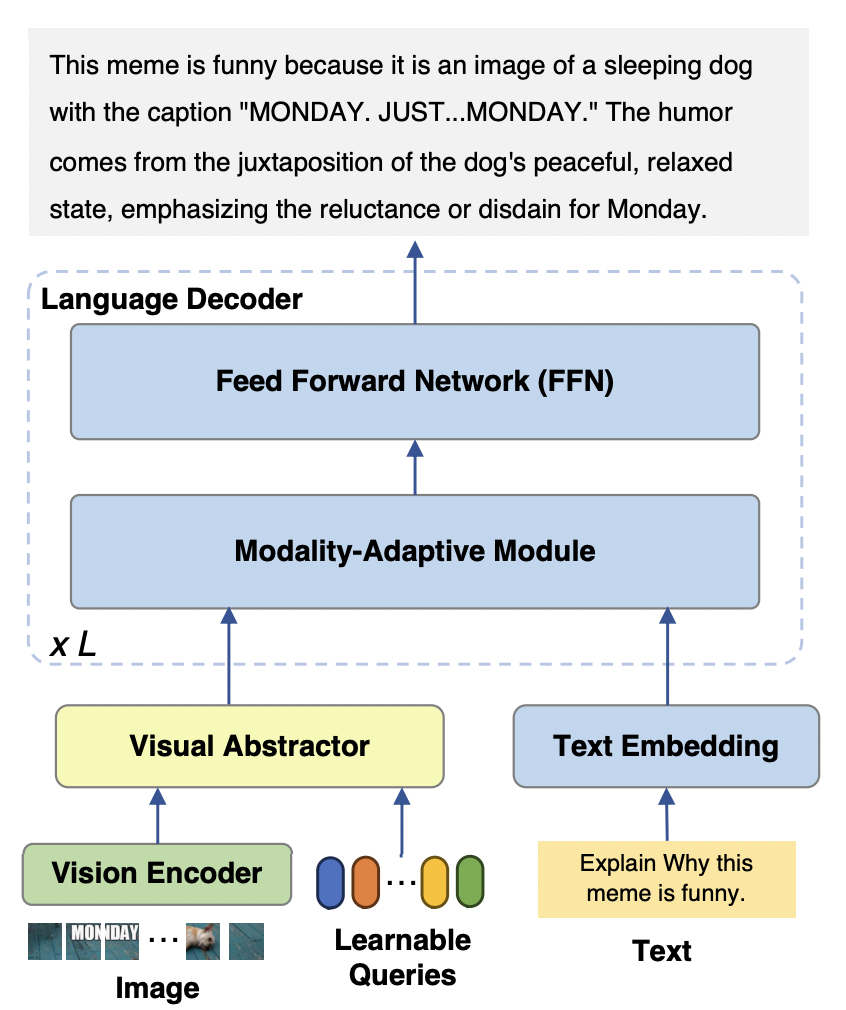
視覚的および言語モダリティの場合、既存の研究では通常、視覚的特徴をテキストの意味空間にマッピングしますが、このアプローチでは視覚情報とテキスト情報のそれぞれの特性が無視され、意味の粒度の不一致によりモデルのパフォーマンスに影響を与える可能性があります。この問題を解決するために、この論文では、視覚的特徴とテキスト的特徴を共有意味論的空間にマッピングすると同時に、視覚的言語表現を切り離して各モダリティの固有の特性を保持するモダリティ適応モジュール (MAM) を提案します。
#図 3 は、モーダル適応モジュールの概略図を示しています。
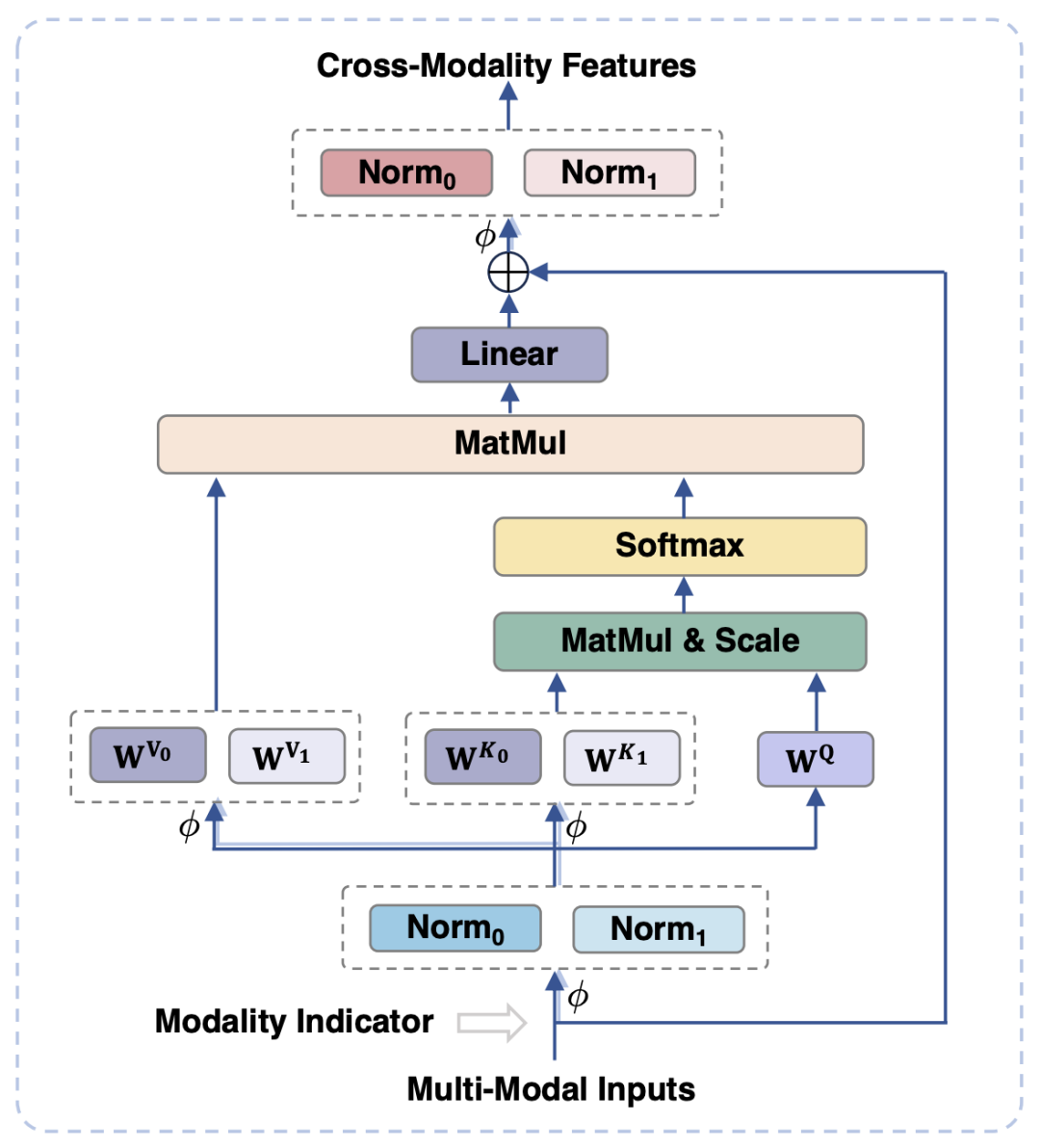
モジュールの入力ステージと出力ステージでは、LayerNorm 操作がそれぞれ視覚モダリティと言語モダリティに対して実行されます。 2 つのモードのそれぞれの特徴分布に適応します。
セルフアテンション操作では、ビジュアルモダリティと言語モダリティに別個のキー射影行列と値射影行列が使用されますが、キー射影と値射影を分離するために共有クエリ射影行列が使用されます。マトリックスは、意味論的な粒度が一致しない場合に 2 つのモダリティ間の干渉を回避できます。
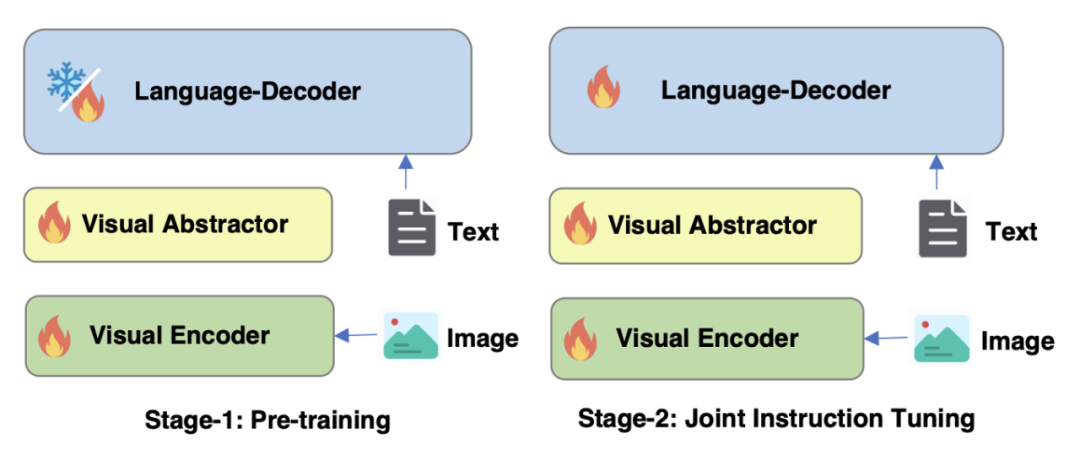
図 4 に示すように、mPLUG-Owl2 のトレーニングには、事前トレーニングと命令の微調整という 2 つの段階が含まれます。トレーニング前の段階では、主にビジュアル エンコーダーと言語モデルの調整を行います。この段階では、ビジュアル エンコーダーとビジュアル アブストラクターはトレーニング可能であり、言語モデルでは、モダリティによって追加されるビジュアル関連のモデルの重みのみが追加されます。アダプティブ モジュールが処理されます。命令の微調整ステージでは、モデルのすべてのパラメーターがテキストとマルチモーダル命令データ (図 5 に示す) に基づいて微調整され、モデルの命令追従能力が向上します。
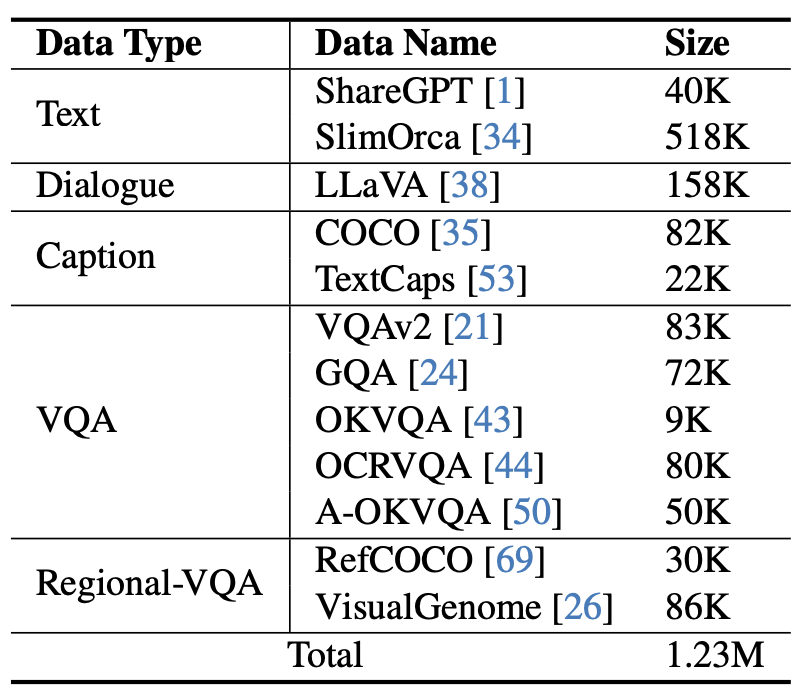
#図 5 mPLUG-Owl2 で使用される命令微調整データ
実験と結果
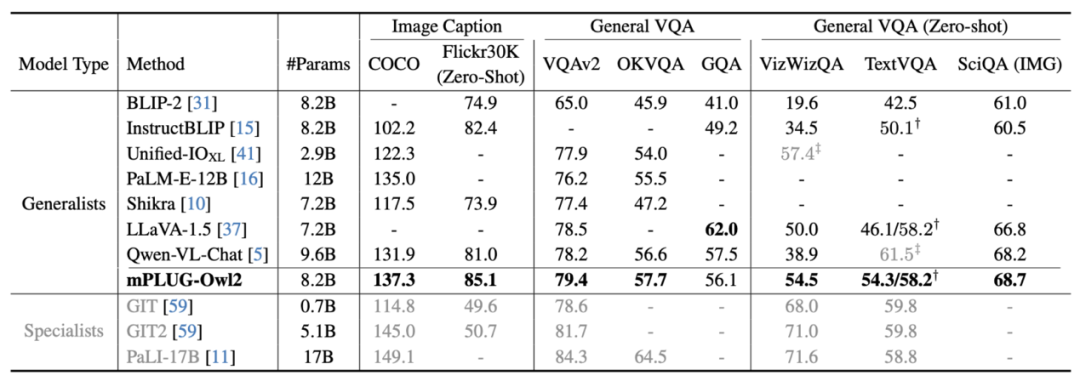
図 6 画像の説明と VQA タスクのパフォーマンス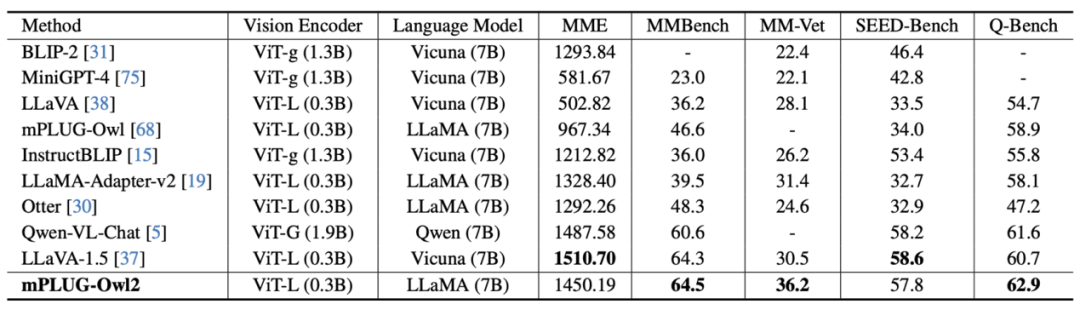
図 7 MLLM ベンチマークのパフォーマンス
図 6 と図 7 に示すように、従来の画像記述、VQA およびその他の視覚言語タスク、または MMBench、Q-ベンチなど マルチモーダル大規模モデルのベンチマーク データ セットにおいて、mPLUG-Owl2 は既存の研究よりも優れたパフォーマンスを達成しました。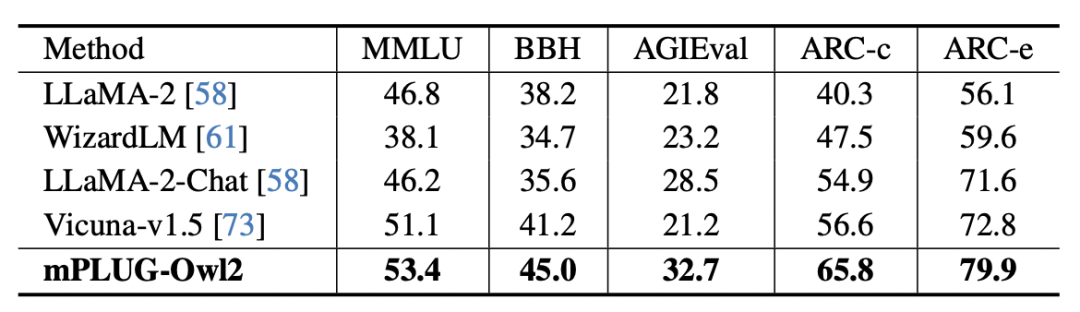
#図 8 プレーン テキストのベンチマーク パフォーマンス
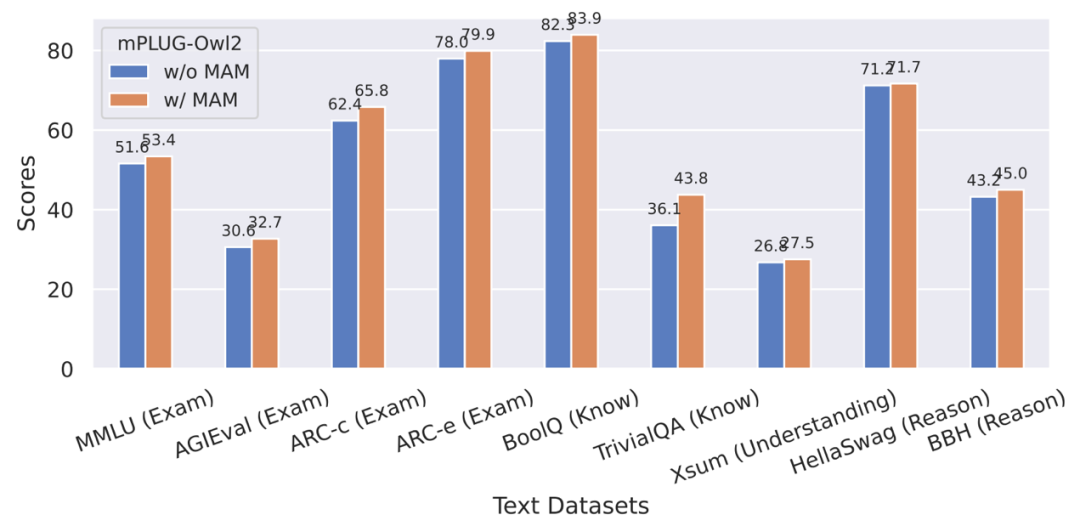
さらに、プレーン テキスト タスクに対するモーダル コラボレーションの影響を評価するために、著者は次のことも行いました。自然言語の理解と生成における mPLUG -Owl2 のパフォーマンスをテストしました。図 8 に示すように、mPLUG-Owl2 は、他の命令微調整 LLM と比較して優れたパフォーマンスを実現します。図 9 は、プレーン テキスト タスクのパフォーマンスを示しており、モーダル適応モジュールがモーダル コラボレーションを促進するため、モデルの検査能力と知識能力が大幅に向上していることがわかります。これは、マルチモーダル連携により、モデルが言語で説明するのが難しい概念を視覚情報を用いて理解できるようになり、画像内の豊富な情報によってモデルの推論能力が向上し、間接的にモデルの推論能力が強化されるためであると著者は分析している。テキスト。


以上がアリババの新しい mPLUG-Owl アップグレードは両方の長所を備えており、モーダル コラボレーションにより MLLM の新しい SOTA が可能になりますの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



