


GPT-5 はいつ登場しますか?また、どのような機能がありますか?
アレン AI 研究所の新しいモデルがその答えを教えてくれます。
アレン人工知能研究所によって発表された Unified-IO 2 は、テキスト、画像、オーディオ、ビデオ、およびアクション シーケンスを処理および生成できる最初のモデルです。
この高度な AI モデルは、数十億のデータ ポイントを使用してトレーニングされており、モデルのサイズはわずか 70 億ですが、これまでで最も広範なマルチモーダル機能を示します。

論文アドレス: https://arxiv.org/pdf/2312.17172.pdf
それでは、Unified-IO 2 と GPT-5 の関係は何ですか?
2022 年 6 月、アレン人工知能研究所は、画像と言語を同時に処理できるマルチモーダル モデルの 1 つとなる、第 1 世代の Unified-IO を発表しました。
同じ頃、OpenAI は内部で GPT-4 をテストしており、2023 年 3 月に正式にリリースする予定です。
つまり、Unified-IO は、将来の大規模 AI モデルのプレビューとして見ることができます。
とはいえ、OpenAI は内部で GPT-5 をテストしている可能性があり、数か月以内にリリースされる予定です。
#今回 Unified-IO 2 によって示された機能は、新年に期待できるものでもあります。
## New #GPT-5 のような AI モデルは、より多くのモダリティを処理し、広範な学習を通じて多くのタスクをネイティブに実行でき、オブジェクトやロボットとの対話についての基本的な理解を得ることができます。
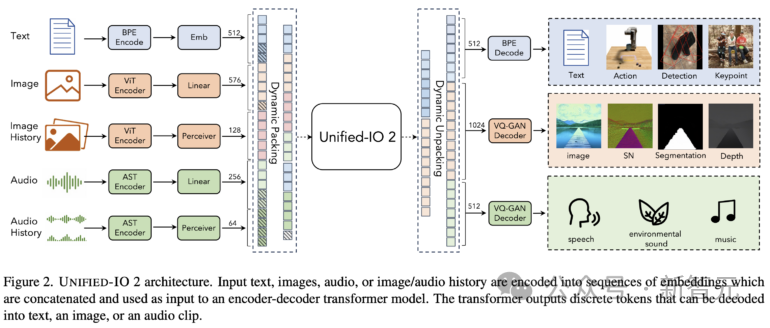
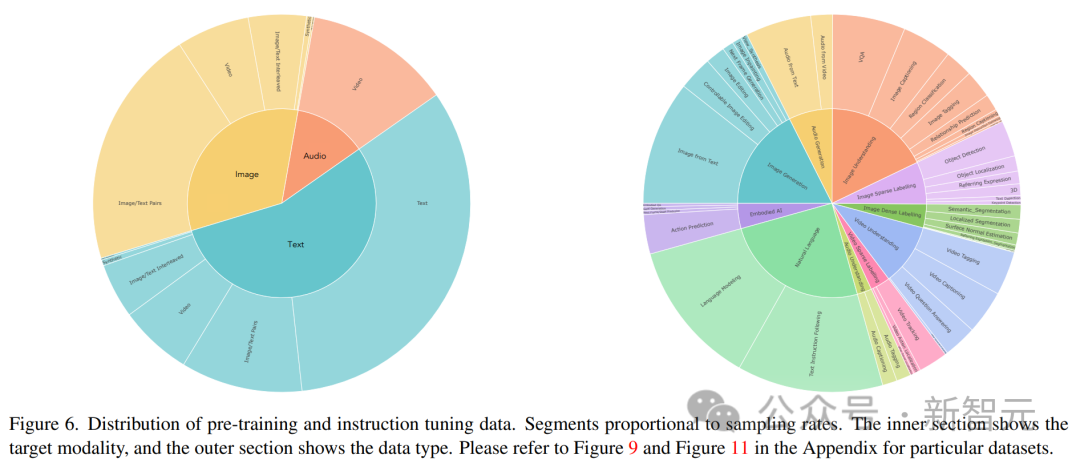
Unified-IO 2 のトレーニング データには、10 億の画像とテキストのペア、1 兆のテキスト トークン、1 億 8,000 万のビデオ クリップ、1 億 3,000 万の画像が含まれます。テキスト、300 万の 3D アセット、および 100 万のロボット エージェントのモーション シーケンス。
研究チームは、合計 120 を超えるデータセットを、220 の視覚、言語、聴覚、運動タスクをカバーする 600 TB のパッケージに結合しました。
Unified-IO 2 は、トレーニングを安定させ、マルチモーダル信号を効果的に利用するために、いくつかの変更を加えたエンコーダー/デコーダー アーキテクチャを採用しています。
モデルは、質問に答え、指示に従ってテキストを作成し、テキストの内容を分析できます。
マルチモーダル トレーニングのおかげで、画像上の特定のトラックで使用されている楽器にラベルを付けるなど、さまざまなモダリティも処理できます。

ほとんどのタスクにおいて、専用モデルと同等かそれ以上の性能を発揮します。
Unified-IO 2 は、画像タスクの GRIT ベンチマークでこれまでのところ最高スコアを達成しました (GRIT は、モデルが画像ノイズやその他の問題をどのように処理するかをテストするために使用されます)。
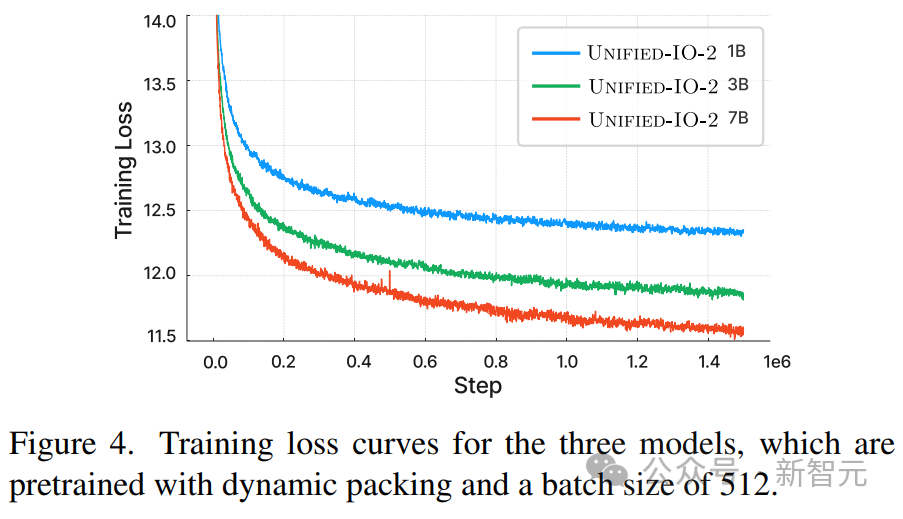
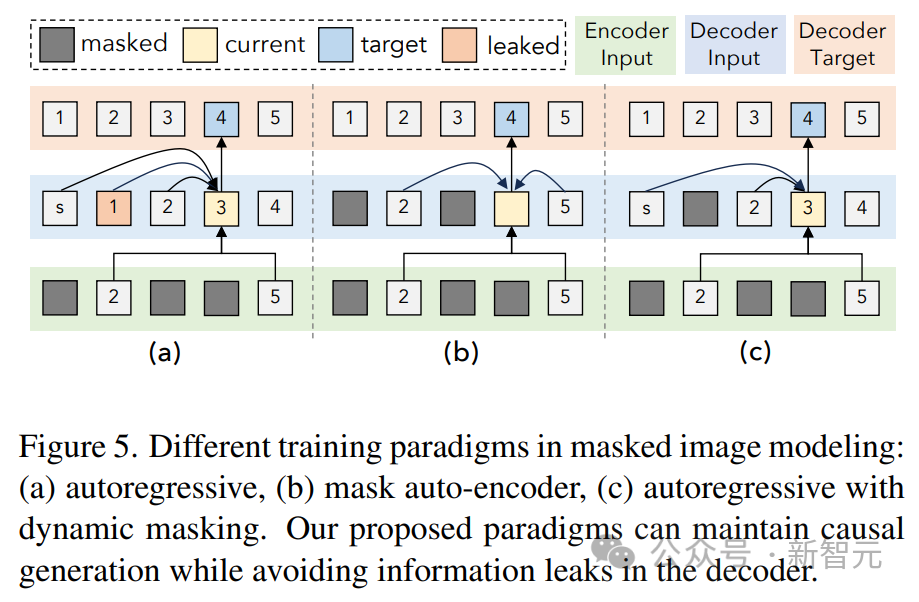
研究者らは現在、Unified-IO 2 をさらに拡張し、データ品質を向上させ、エンコーダ/デコーダ モデルを業界標準のデコーダ モデル アーキテクチャに変換することを計画しています。 Unified-IO 2 は、画像、テキスト、オーディオ、モーションのマルチモーダル モデルを理解して生成する初の自己回帰モデルです。 さまざまなモダリティを統合するために、研究者は入力と出力 (画像、テキスト、オーディオ、アクション、境界ボックスなど) を共有の意味論的空間にラベル付けし、単一のエンコーダーを使用します。デコーダコンバータモデルがそれを処理します。 モデルのトレーニングにさまざまなモダリティからの大量のデータが使用されたため、研究者は全体を改善するために一連の手法を採用しました。トレーニングのプロセス。 複数のモダリティにわたる信号の自己教師あり学習を効果的に促進するために、研究者らは、クロスモーダルなノイズ除去と生成を組み込んだ、デノイザー ターゲットの新しいマルチモーダル ハイブリッドを開発しました。 ダイナミック パッキングも開発され、非常に可変性の高いシーケンスを処理するためにトレーニング スループットを 4 倍に向上させました。 トレーニングにおける安定性とスケーラビリティの問題を克服するために、研究者らは、2D 回転埋め込み、QK 正規化、スケーリングされたコサイン アテンション メカニズムなど、パーセプトロン リサンプラーのアーキテクチャに変更を加えました。 ディレクティブを調整する場合は、既存のミッションを使用するか、新しいミッションを作成するかにかかわらず、各ミッションに明確なプロンプトがあることを確認してください。オープンエンドのタスクも含まれており、タスクと指導の多様性を高めるために、あまり一般的ではないパターンに対して合成タスクが作成されます。 マルチモーダル データを共有表現空間内の一連のトークンにエンコードします。次のものが含まれます。いくつかの側面: テキストの入出力は、LLaMA のバイト ペア エンコーディングを使用してトークン化され、次のようなスパース構造境界ボックス、キーポイント、カメラのポーズは離散化され、語彙に追加された 1000 個の特別なマーカーを使用してエンコードされます。 点は 2 つのマーカー (x、y) を使用してエンコードされ、ボックスは 4 つのマーカーのシーケンス (左上と右下) でエンコードされ、3D 直方体は 12 のマーカー (エンコード投影中心、仮想深度、対数正規化ボックス サイズ、および連続同心円回転)。 具体化されたタスクの場合、個別のロボットの動作はテキスト コマンド (「前進」など) として生成されます。特別なタグを使用して、ロボットの状態 (位置や回転など) をエンコードします。 画像は、事前トレーニングされた Visual Transformer (ViT) を使用してエンコードされます。 ViT の 2 番目と最後から 2 番目の層のパッチ フィーチャが連結されて、低レベルと高レベルの視覚情報がキャプチャされます。 画像を生成するときは、VQ-GAN を使用して画像を離散ラベルに変換します。ここでは、パッチ サイズ 8 × 8 の高密度の事前トレーニング済み VQ-GAN モデルが使用されます256 × 256 の画像を変換するには、エンコードは 1024 トークン、コードブック サイズは 16512 です。 各ピクセルのラベル (深度、表面法線、バイナリ セグメンテーション マスクを含む) は、RGB イメージとして表されます。 U-IO 2 は、最大 4.08 秒のオーディオをスペクトログラムにエンコードし、事前トレーニングされたオーディオ スペクトログラム変換を使用します。画像 ViT と同様に、AST の 2 番目と最後から 2 番目の層の特徴を連結し、線形層を適用することで、スペクトログラムをエンコードし、入力埋め込みを構築します。 オーディオを生成する場合、ViT-VQGAN を使用してオーディオを離散マーカーに変換します。モデルのパッチ サイズは 8 × 8 で、256 × 128 スペクトログラムは 512 トークンにエンコードされます. コードブックのサイズは 8196 です。 このモデルでは、最大 4 つの追加の画像と音声クリップを入力として提供できます。これらの要素も提供されますViT または AST を使用してエンコードされ、その後パーセプトロン リサンプラーを使用して特徴をさらに小さい数 (画像の場合は 32、音声の場合は 16) に圧縮します。 これにより、シーケンスの長さが大幅に短縮され、モデルが履歴の要素をコンテキストとして使用しながら、画像またはオーディオ クリップを詳細に検査できるようになります。 研究者らは、他のモデルを統合する際に、U-IO 実装結果を使用した後の標準が重要であることに気づきました。ますます不安定なトレーニング中。 以下の (a) と (b) に示すように、画像生成 (緑色の曲線) のみをトレーニングすると、安定した損失と勾配ノルムが収束します。 画像とテキストのタスクの組み合わせ (オレンジ色の曲線) を導入すると、単一モダリティと比較して勾配ノルムがわずかに増加しますが、安定したままです。ただし、ビデオ モダリティ (青い曲線) を含めると、勾配ノルムが無制限にアップグレードされます。 図の (c) と (d) に示すように、XXL バージョンのモデルをすべてのモダリティでトレーニングすると、損失はは 350k ステップの後に爆発的に増加し、次のラベルの予測精度は 400k ステップで大幅に低下します。 この問題を解決するために、研究者はアーキテクチャにさまざまな変更を加えました。 各 Transformer 層で回転位置埋め込み (RoPE) を適用します。非テキスト モダリティの場合、RoPE は 2D 位置に拡張されます。画像および音声モダリティが含まれる場合、LayerNorm はドット積アテンション計算の前に Q および K に適用されます。 また、パーセプトロン リサンプラーを使用して、各画像フレームとオーディオ クリップを固定数のトークンに圧縮し、スケーリングされたコサイン アテンションを使用してパーセプトロンのより厳密な削減を適用します。これにより、トレーニングが大幅に安定します。 。 数値の不安定性を回避するために、float32 アテンション対数も有効になり、ViT と AST は事前トレーニング中にフリーズされ、命令調整の最後に微調整されます。 上の図は、入力モダリティと出力モダリティが異質であるにもかかわらず、モデルの事前トレーニング損失が安定していることを示しています。 この記事は UL2 パラダイムに従います。画像と音声のターゲットについては、2 つの同様のパラダイムがここで定義されています: [R]: ノイズ除去をマスクし、入力画像または音声パッチの特徴の x% をランダムにマスクし、モデルを再構築させます。 it; [S]: 他の入力モーダル条件下でターゲット モダリティを生成するようにモデルに要求します。 トレーニング中は、モーダル マーカー ([テキスト]、[画像]、または [音声]) およびパラダイム マーカー ([R]、[S]、または [X]) を次のように使用します。タスクを示すテキストのプレフィックスを入力し、自動回帰に動的マスキングを使用します。 上図に示すように、画像と音声のマスキングノイズ除去の問題の 1 つは、デコーダ側での情報漏洩です。 ここでの解決策は、デコーダでトークンをマスクすることです (トークンを予測している場合を除く)。これにより、データ漏洩を排除しながら因果関係の予測を妨げません。 大量のマルチモーダル データをトレーニングすると、一連のコンバータ入力が発生します。出力の長さは大きく変化します。 ここでは、この問題を解決するためにパッキングが使用されています。複数のサンプルのタグがシーケンスにパックされ、コンバーターがサンプル間で交差するのを防ぐために注意が遮られます。 トレーニング中に、ヒューリスティック アルゴリズムを使用してモデルにストリーミングされたデータを再配置し、長いサンプルがパック可能な短いサンプルと一致するようにします。この記事のダイナミック パッケージ化により、トレーニングのスループットが 4 倍近く増加します。 マルチモーダル命令チューニングは、さまざまなモダリティで異なるスキルと能力をモデルに装備し、新しい命令にも適応することです。主要なプロセスに対する独自の指示。 研究者らは、広範囲の教師付きデータセットとタスクを組み合わせて、マルチモーダルな命令調整データセットを構築しました。 コマンドチューニングデータの分布を上図に示します。全体として、命令チューニングの組み合わせは、60% のヒント データ、30% の事前トレーニングから継承されたデータ (致命的な忘れを避けるため)、6% の既存のデータ ソースを使用して構築されたタスク拡張データ、および 4% の自由形式のテキスト (有効にするため) で構成されていました。チャットのような返信)。
Unified-IO 2
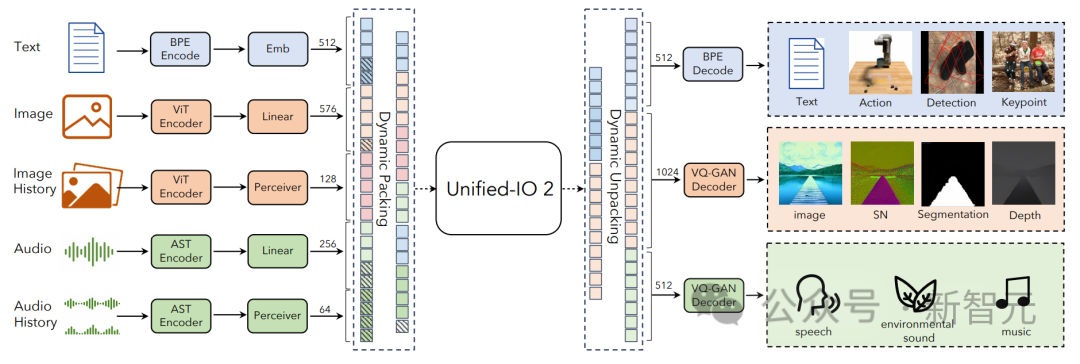
統合タスク表現
テキスト、スパース構造と操作
画像と密な構造
オーディオ
画像と音声の履歴
安定したトレーニングのためのモデル アーキテクチャとテクノロジー
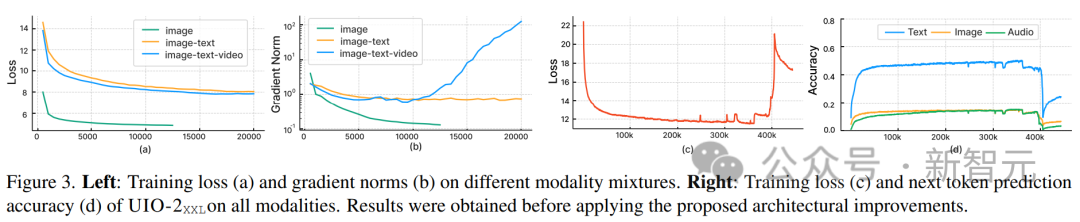
マルチモーダル トレーニングの目標
効率の最適化
命令チューニング
以上がGPT-5のプレビュー!アレン人工知能研究所が GPT-5 の新機能を予測する最強のマルチモーダル モデルをリリースの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



