


テキストを使用して 3D グラフィックスを合成する AI モデルに新しい SOTA が登場しました!
最近、清華大学のLiu Yongjin教授の研究グループは、拡散モデルに基づいて3D画像を作成する新しい方法を提案しました。
異なる視点間の一貫性とプロンプトワードとのマッチングの両方が、以前に比べて大幅に改善されました。
 写真
写真
Vincent 3D は 3D AIGC の注目の研究コンテンツであり、学界や産業界から幅広い注目を集めています。
Liu Yongjin 教授の研究チームが提案した新しいモデルは TICD (Text-Image Conditioned Diffusion) と呼ばれ、T3Bench データセットでは SOTA レベルに達しています。
関連する論文がリリースされており、コードは間もなくオープンソースになる予定です。
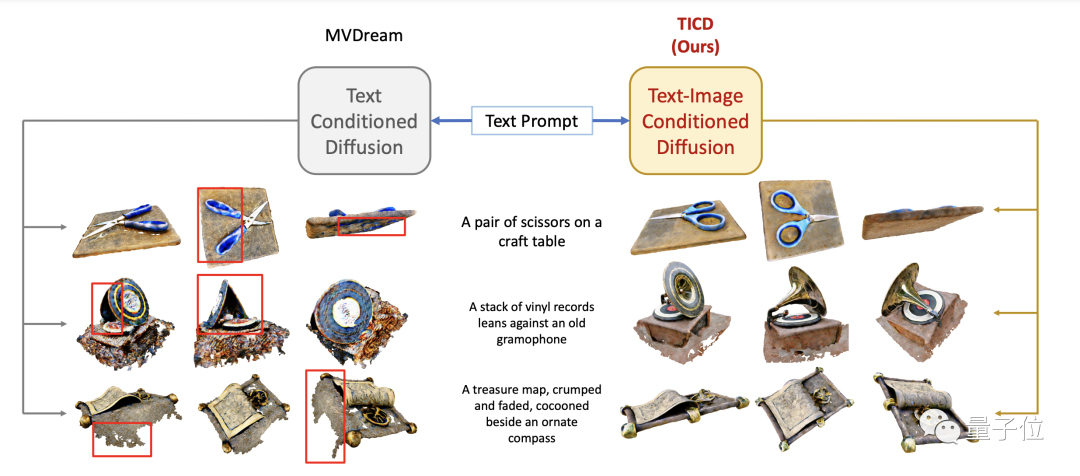
TICD法の効果を評価するために、研究チームはまず定性実験を実施し、以前のより良い方法をいくつか比較しました。
結果は、TICD 手法によって生成された 3D グラフィックスの品質が高く、グラフィックスがより鮮明で、プロンプトの単語との一致度が高いことを示しています。
 写真
写真
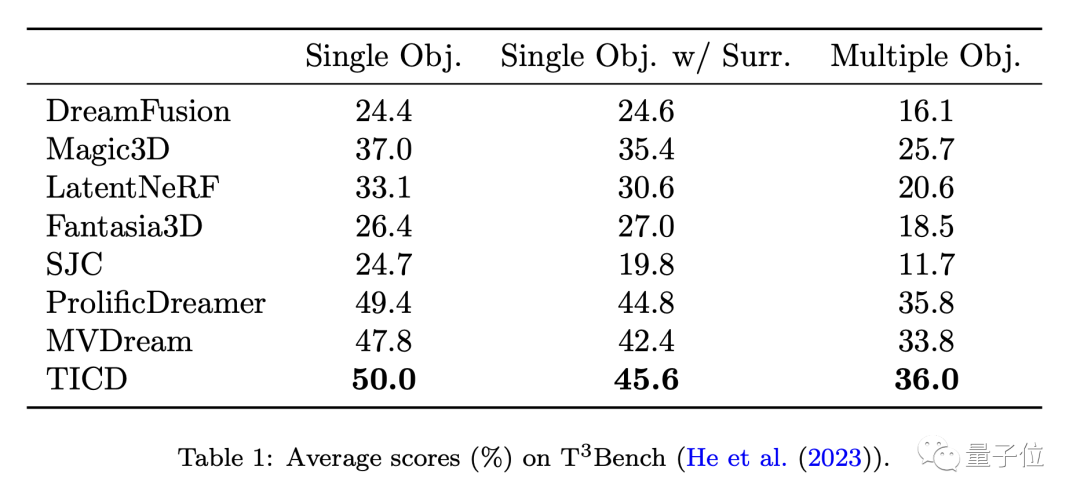
これらのモデルのパフォーマンスをさらに評価するために、チームは T3Bench データセットでこれらの方法を使用して TICD を定量的にテストしました。
結果は、単一オブジェクト、背景のある単一オブジェクト、および複数オブジェクトの 3 つのプロンプト セットで TICD が最良の結果を達成したことを示しており、生成品質とテキスト配置の両方において総合的な利点があることが証明されています。
 画像
画像
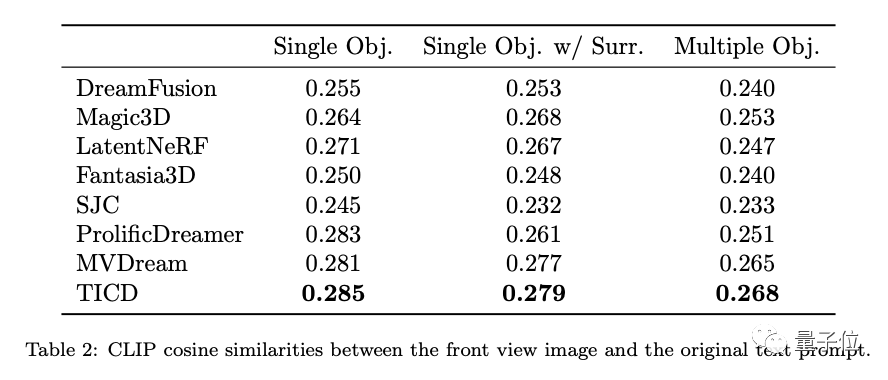
さらに、これらのモデルのテキスト配置をさらに評価するために、研究チームは 3D によってレンダリングされた画像の CLIP も実行しました。オブジェクトと元のプロンプト単語のコサイン類似性がテストされた結果、依然として TICD が最高のパフォーマンスを発揮することがわかりました。
それでは、TICD 手法はどのようにしてそのような効果を達成するのでしょうか?
現在主流の 3D テキスト生成方法は、ほとんどが事前トレーニング済み 2D 拡散モデルを使用し、スコア蒸留サンプリング (SDS) 神経放射場 (NeRF) を通じて最適化されています。 ) 新しい 3D モデルを生成します。
ただし、この事前トレーニングされた拡散モデルによって提供される監視は入力テキスト自体に限定されており、複数のビュー間の一貫性を制約せず、生成された幾何学的構造が不十分になるなどの問題が発生する可能性があります。
拡散モデルの事前にマルチビューの一貫性を導入するために、いくつかの最近の研究では、マルチビュー データを使用して 2D 拡散モデルを微調整していますが、依然としてきめ細かいビュー間の連続性が欠けています。
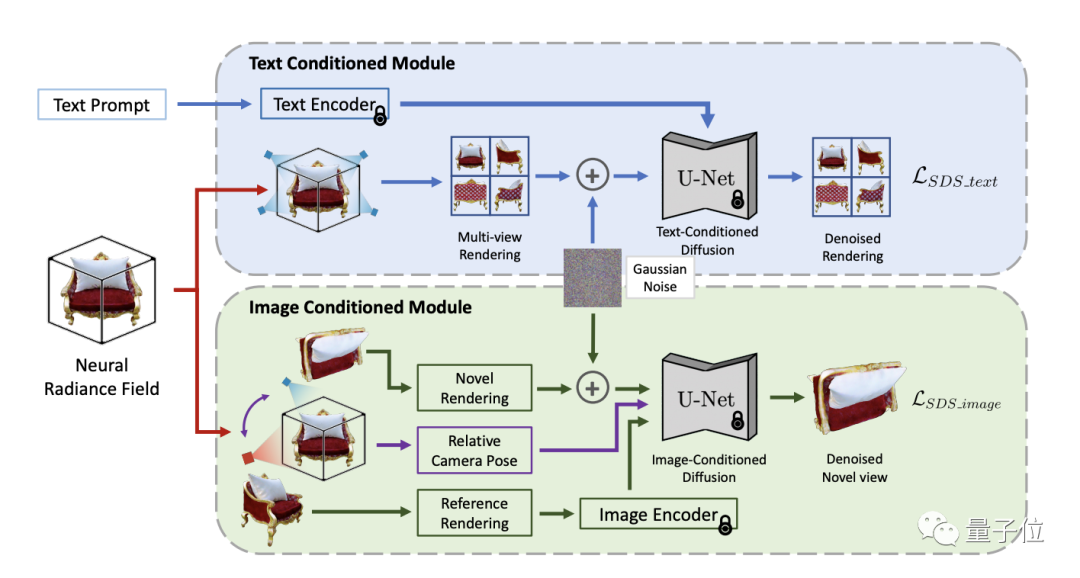
この課題を解決するために、TICD 手法では、テキスト条件付きおよび画像条件付きのマルチビュー画像を NeRF に最適化された監視信号に組み込んで、3D 情報とプロンプトワードおよび 3D オブジェクトのそれぞれを確実に整合させます。視野角間の一貫性により、生成される 3D モデルの品質が効果的に向上します。
 写真
写真
ワークフローの観点から見ると、TICD はまず直交する参照カメラの視点のいくつかのセットをサンプリングし、NeRF を使用して対応する参照ビューをレンダリングしてから、これらの参照ビューは、テキストベースの条件付き拡散モデルを使用して、コンテンツとテキストの全体的な一貫性を制限します。
これに基づいて、参照カメラ パースペクティブのセットをいくつか選択し、パースペクティブごとに追加の新しいパースペクティブからビューをレンダリングします。次に、2 つのビューと視点の間の姿勢関係が新しい条件として使用され、画像ベースの条件付き拡散モデルを使用して、異なる視点間の詳細の一貫性が制約されます。
2 つの拡散モデルの監視信号を組み合わせることで、TICD は NeRF ネットワークのパラメーターを更新し、最終的な NeRF モデルが取得され、高品質で幾何学的に鮮明でテキストの一貫性のある 3D コンテンツがレンダリングされるまで繰り返し最適化できます。
さらに、TICD手法は、既存の手法が特定のテキスト入力に直面した場合に発生する可能性のある、幾何情報の消失、不正確な幾何情報の過剰生成、色の混乱などの問題を効果的に排除できます。
紙のアドレス: //m.sbmmt.com/link/8553adf92deaf5279bcc6f9813c8fdcc
##
以上が清華文生氏は、拡散モデルと NeRF を組み合わせて、SOTA を実現する新しい 3D 手法を提案しました。の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



