


10 ミリ秒で 1 枚の画像、1 分で 6,000 枚の画像を生成します。コンセプトは何ですか?
下の写真では、AI のスーパーパワーを深く感じることができます。
 画像
画像
二次元の女性の画像によって生成されたプロンプトに新しい要素を追加し続けると、それぞれの要素がこのスタイルの絵の切り替わりも一瞬です。
 写真
写真
このような驚くべきリアルタイム画像生成速度は、カリフォルニア大学バークレー校の研究者によって提案された StreamDiffusion の結果です。つくば市などで成果をあげています。
この新しいソリューションは、100fps を超えるリアルタイムのインタラクティブな画像生成を可能にする拡散モデル プロセスです。
 #写真
#写真
論文アドレス: https://arxiv.org/abs/2312.12491
オープンソース化後、StreamDiffusion は GitHub ランキングを直接独占し、3.7,000 個のスターを獲得しました。
 画像
画像
StreamDiffusion は、シーケンスのノイズ除去ではなくバッチ処理戦略を革新的に使用しており、従来の方法よりも約 1.5 倍高速です。さらに、著者が提案した新しい残差分類子なしガイダンス (RCFG) アルゴリズムは、従来の分類子なしガイダンスよりも 2.05 倍高速になります。
最も注目すべき点は、新しい方法により、RTX 4090 上で 91.07fps の画像間の生成速度を達成できることです。
 画像
画像
#将来的には、StreamDiffusion はメタバース、ビデオ ゲーム グラフィックスのレンダリング、ライブビデオストリーミングこれらのアプリケーションの高スループット要件を満たすことができます。
特に、リアルタイム画像生成は、ゲーム開発やビデオ レンダリングに携わる人々に強力な編集機能と創造的な機能を提供します。
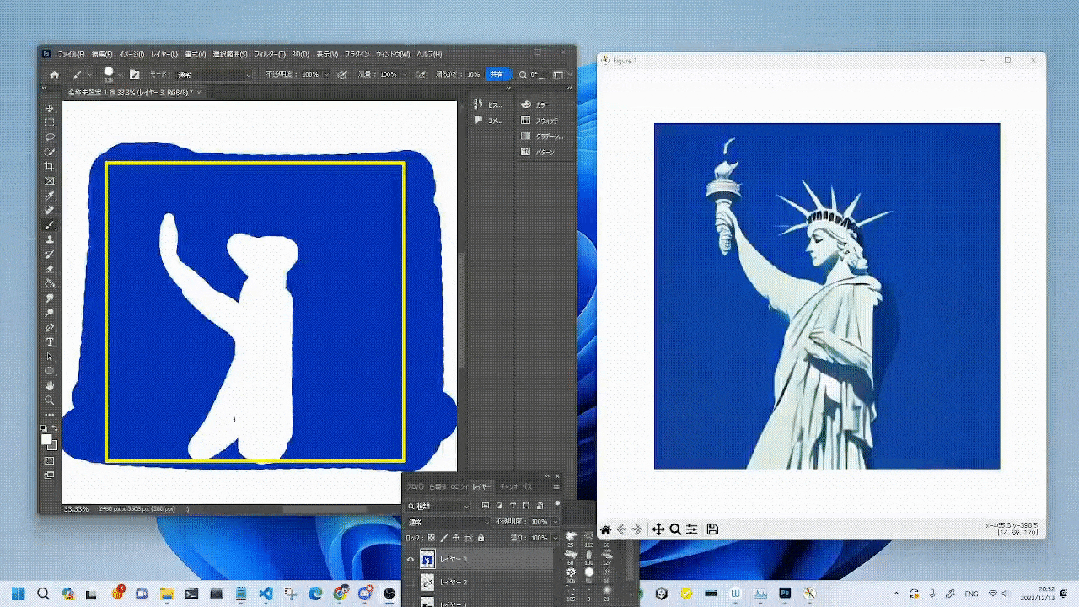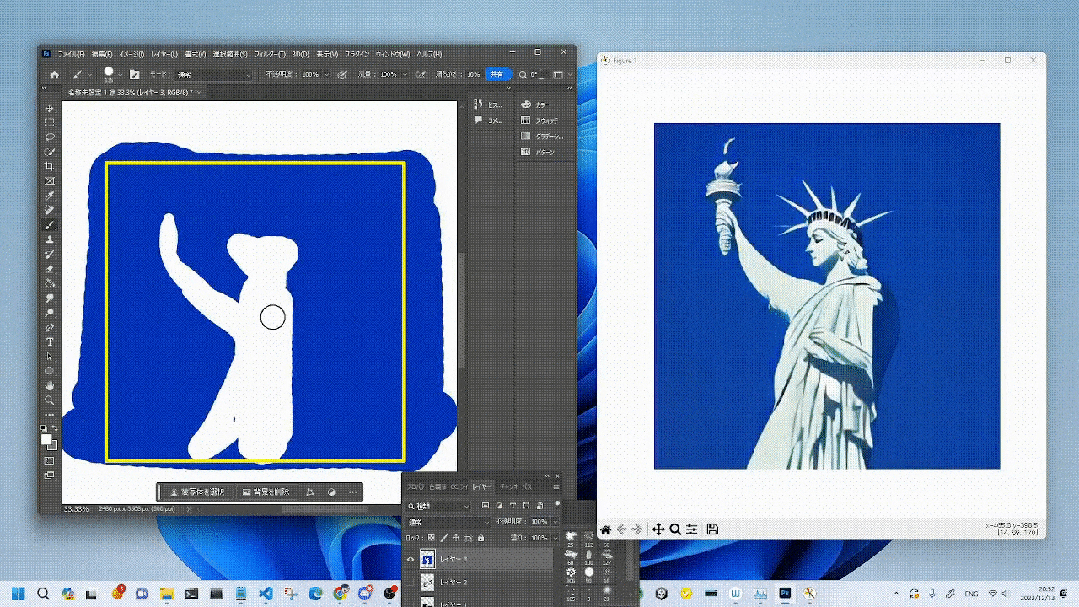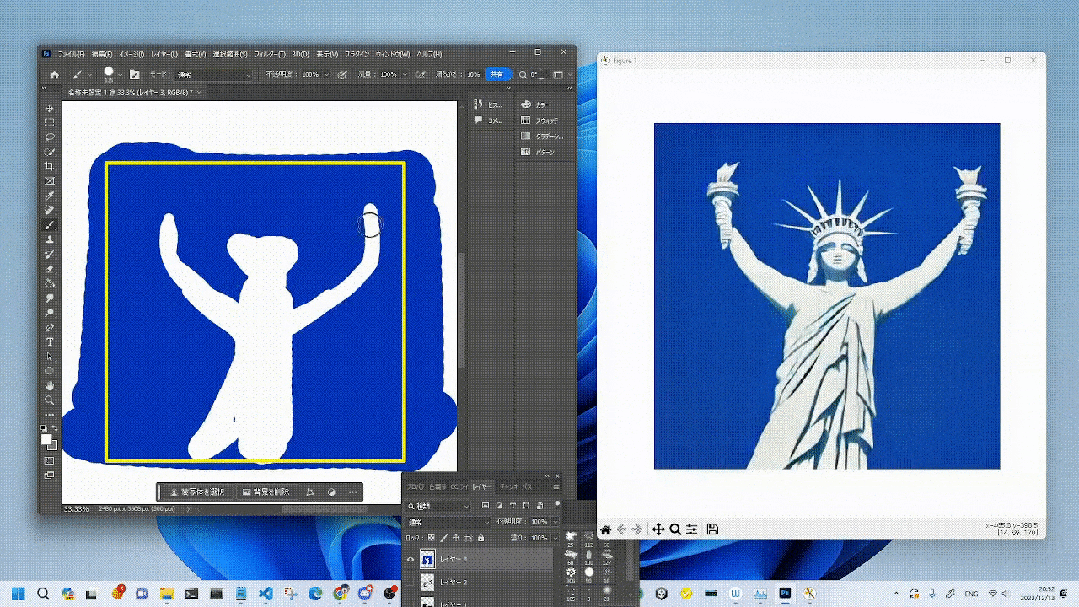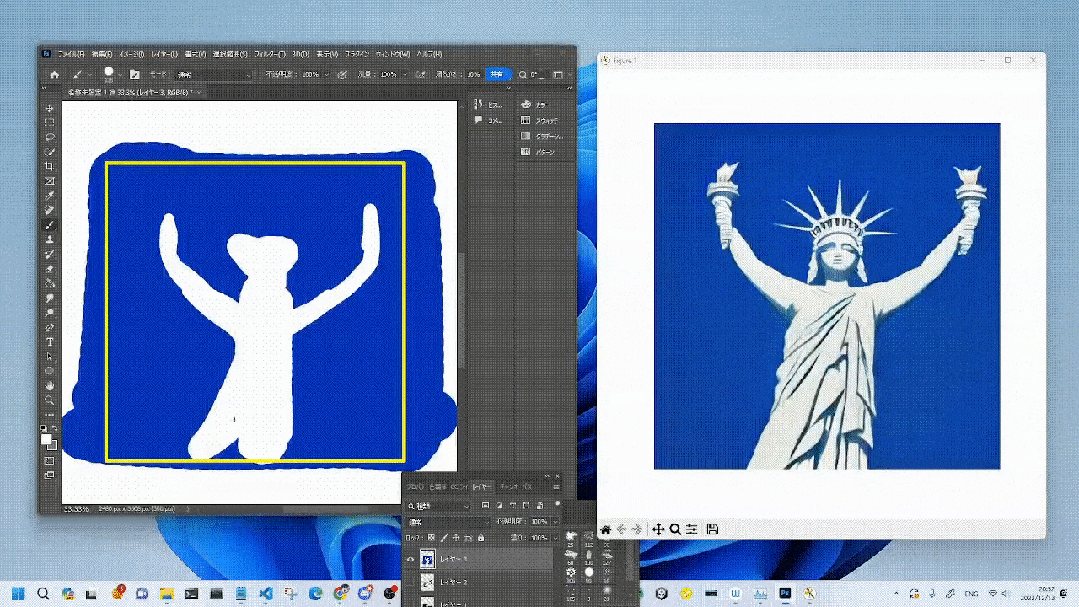 写真
写真
現在、さまざまな分野で普及モデルが使用されています。アプリケーションには、人間とコンピューターの対話の効率を確保するために、高スループットかつ低遅延の拡散パイプラインが必要です。
典型的な例は、拡散モデルを使用して VTuber 可能な仮想キャラクターを作成することです。ユーザー入力に流動的に応答します。
 写真
写真
高スループットとリアルタイムのインタラクション機能を向上させるために、現在の研究の方向性は主にコスト削減に焦点を当てています。反復のノイズ除去 たとえば、反復回数が 50 反復から数回、または 1 回にまで減ります。
一般的な戦略は、複数ステップの拡散モデルをいくつかのステップに洗練し、ODE を使用して拡散プロセスを再構築することです。効率を向上させるために、拡散モデルも定量化されています。
最新の論文では、研究者たちは直交方向から始めて、インタラクティブな画像生成の高スループット向けに設計されたリアルタイム拡散パイプラインである StreamDiffusion を紹介しました。
既存のモデル設計作業を StreamDiffusion と統合しながら、N ステップのノイズ除去拡散モデルを使用して高スループットを維持し、より柔軟なオプションをユーザーに提供できます
 写真
写真
リアルタイム画像生成|1列目、2列目:AIによるリアルタイム描画例、3列目:リアルタイムレンダリング3Dアバターの2Dイラストから。列 4 および 5: ライブ カメラ フィルター。 リアルタイム画像生成 | 1 列目と 2 列目は AI 支援によるリアルタイム描画の例を示し、3 列目は 3D アバターをリアルタイムでレンダリングして 2D イラストを生成するプロセスを示します。 4 番目と 5 番目の列は、リアルタイム カメラ フィルターの効果を示しています。
これはどのように実装されていますか?
StreamDiffusion は、スループットを向上させるために設計された新しい拡散パイプラインです。
これは、いくつかの重要な部分で構成されています:
ストリーミング バッチ処理戦略、残差分類子なしガイダンス (RCFG)、入力および出力キュー、確率的類似性フィルター、事前計算プログラム、マイクロ オートエンコーダー用のランダム モデル アクセラレーション ツール。
拡散モデルでは、ノイズ除去ステップが順番に実行されるため、U-Net の処理時間が増加します。歩数に比例します。
ただし、高忠実度の画像を生成するには、ステップ数を増やす必要があります。
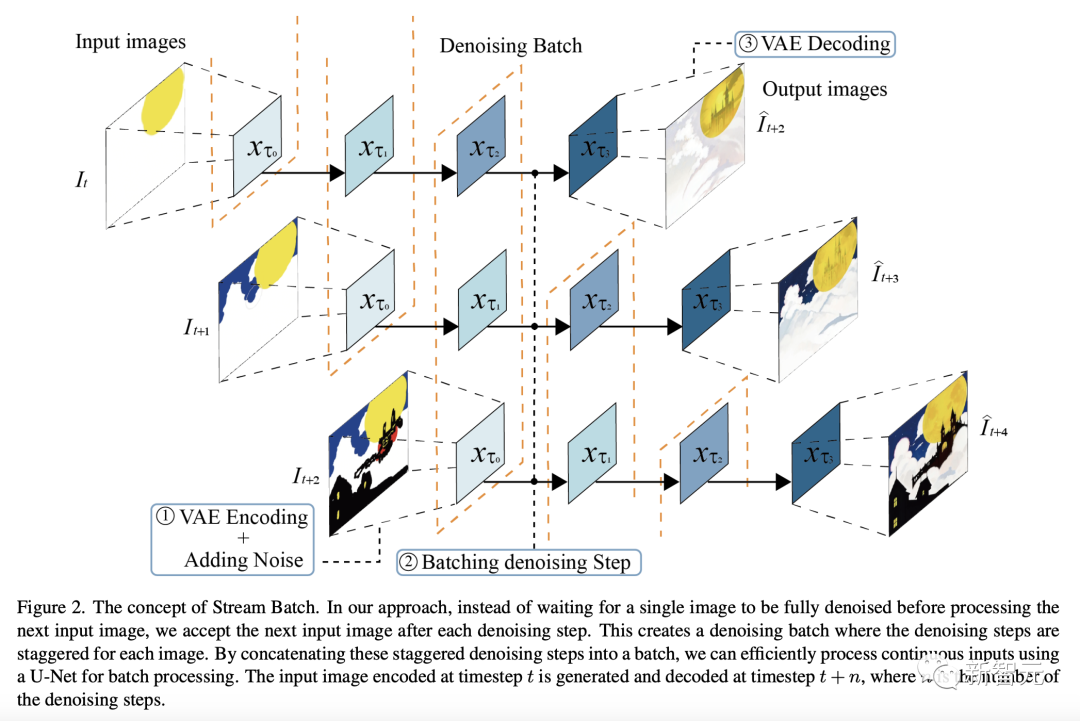
インタラクティブ拡散における待ち時間の長い生成の問題を解決するために、研究者はストリーム バッチと呼ばれる方法を提案しました。
下の図に示すように、最新の方法では、単一の画像が完全にノイズ除去されるのを待ってから次の入力画像を処理するのではなく、各ノイズ除去ステップの後に次の入力を受け入れます。画像。
これによりノイズ除去バッチが形成され、各画像のノイズ除去ステップが交互に行われます。
これらのインターリーブされたノイズ除去ステップをバッチに連結することにより、研究者は U-Net を使用して連続入力のバッチを効率的に処理できます。
タイム ステップ t でエンコードされた入力画像は、タイム ステップ t n で生成およびデコードされます。ここで、n はノイズ除去ステップの数です。
 図
図
一般的な分類子 -フリー ガイダンス (CFG) は、無条件または負の条件項と元の条件項の間でベクトル計算を実行する方法です。元の状態の効果を高めるアルゴリズム。
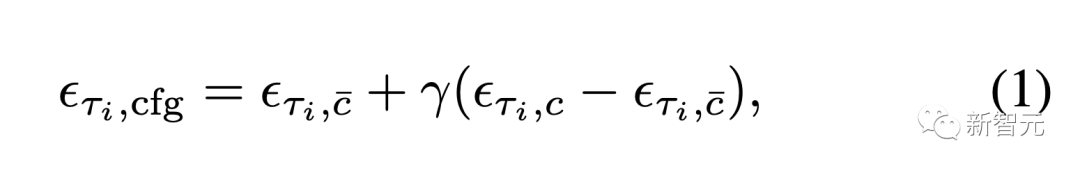 写真
写真
これにより、プロンプトの効果が高まるなどのメリットが得られます。
ただし、負の条件付き残留ノイズを計算するには、各入力潜在変数を負の条件付き埋め込みとペアにして、各推論時間に U-Net に渡す必要があります。
この問題を解決するために、著者は革新的な残差分類子を使用しないブートストラップ (RCFG) を導入しました。
この方法では、仮想残差ノイズが使用されます。負の条件を近似するため、プロセスの初期段階で負の条件ノイズを計算するだけで済みます。これにより、負の条件を埋め込む際の追加の U-Net 推論計算コストが大幅に削減されます
#入力キューと出力キュー
#入力イメージをパイプラインで管理可能なテンソル データ形式に変換し、デコードされたテンソルを出力に変換します。画像、両方 無視できない追加の処理時間が必要です。
これらの画像処理時間がニューラル ネットワーク推論プロセスに追加されるのを避けるために、画像の前処理と後処理を異なるスレッドに分離し、それによって並列処理を可能にします。
また、入力テンソルキューを利用することで、機器の故障や通信エラーによる入力画像の一時的な中断にも対応でき、スムーズなストリーミングが可能となります。 ###############写真######
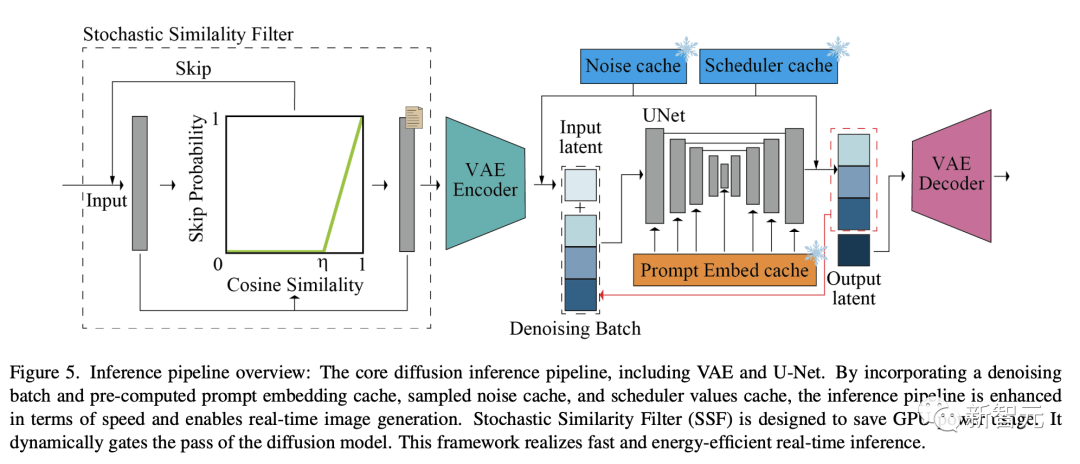
次の図は、VAE と U-Net を含む、コアの拡散推論パイプラインを示しています。
ノイズ除去バッチ処理と事前計算されたヒント埋め込みキャッシュ、サンプリングされたノイズ キャッシュ、およびスケジューラ値キャッシュを導入することにより、推論パイプラインの速度が向上し、リアルタイムの画像生成が可能になります。
確率的類似性フィルタリング (SSF) は、GPU の消費電力を節約するように設計されており、拡散モデルのパイプラインを動的に閉じることができるため、高速かつ効率的なリアルタイム推論を実現できます。
 図
図
U-Net アーキテクチャには両方の入力電位が必要です変数には条件付きの埋め込みも必要です。
通常、条件付き埋め込みは「ヒント埋め込み」から派生し、異なるフレーム間で変更されません。
これを最適化するために、研究者はヒントの埋め込みを事前計算し、キャッシュに保存します。インタラクティブ モードまたはストリーミング モードでは、この事前計算されたヒント埋め込みキャッシュが呼び出されます。
U-Net では、各フレームのキーと値の計算は、事前に計算されたヒントの埋め込みに基づいて実装されます
したがって, 研究者らは、これらのキーと値のペアを再利用できるように保存するように U-Net を修正しました。入力プロンプトが更新されるたびに、研究者は U-Net 内でこれらのキーと値のペアを再計算して更新します。
速度を最適化するために、静的なバッチ サイズと固定入力サイズ (高さ) を使用するようにシステムを構成しました。と幅)。
このアプローチにより、計算グラフとメモリ割り当てが特定の入力サイズに合わせて最適化され、処理が高速化されます。
ただし、これは、異なる形状 (つまり、異なる高さと幅) の画像を処理する必要がある場合は、異なるバッチ サイズ (ノイズ除去ステップのバッチ サイズを含む) を使用することを意味します。
#実験的評価研究者らは、バッチノイズ除去戦略を実装したところ、処理時間が大幅に改善されたことを発見しました。これにより、連続したノイズ除去ステップを使用する従来の U-Net ループと比較して、時間が半分に短縮されます。
ニューラル モジュール アクセラレーション ツール TensorRT を適用した場合でも、研究者らが提案したストリーミング バッチ処理は、さまざまなノイズ除去ステップで元の逐次拡散パイプラインの効率を大幅に向上させることができます。
写真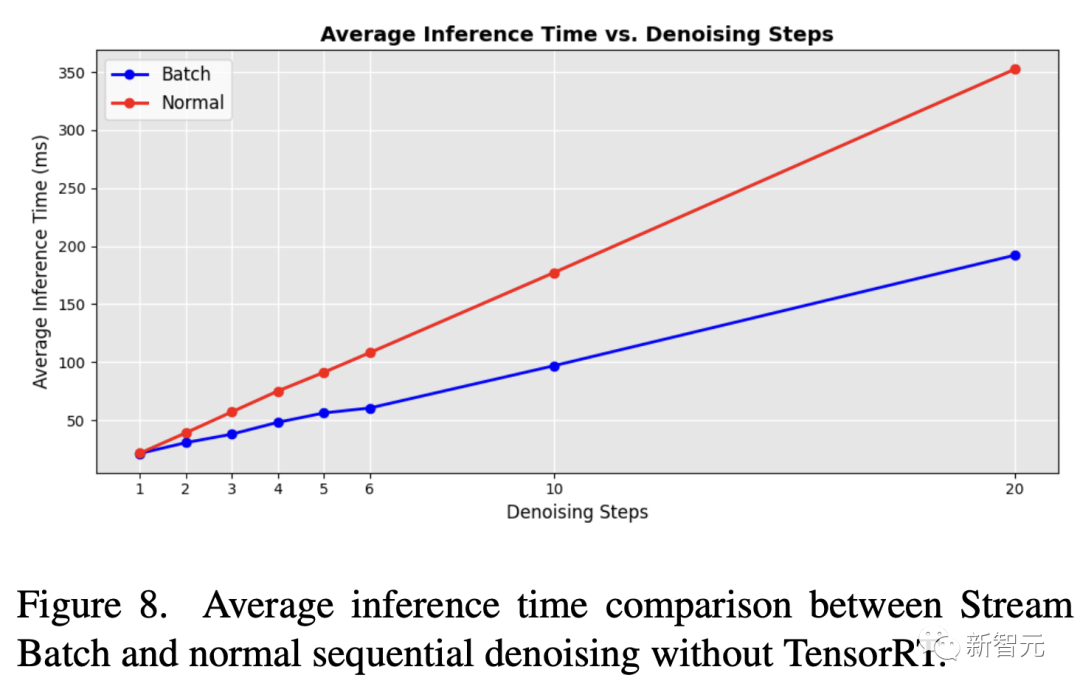
平均推論時間の比較を表 1 に示します。最新のパイプラインでは、速度が大幅に向上していることがわかります。
TensorRT を使用する場合、StreamDiffusion は 10 のノイズ除去ステップを実行すると 13 倍の高速化を達成できます。単一ステップのノイズ除去ステップのみを使用する場合、速度向上は 59.6 倍に達します。
# TensorRT を使用しない場合でも、単一ステップのノイズ除去を使用すると、StreamDiffusion は AutoPipeline より 29.7 倍高速になります。 10 ステップのノイズ除去を使用する場合。
写真
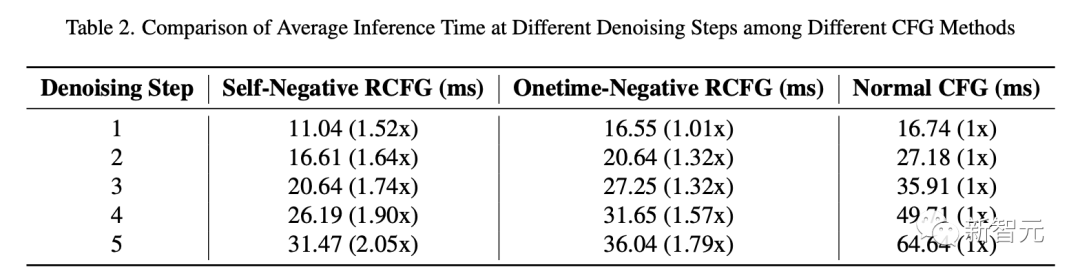
 表 2 は、RCFG と従来の CFG を使用した流れ拡散パイプラインの推論時間を比較しています。
表 2 は、RCFG と従来の CFG を使用した流れ拡散パイプラインの推論時間を比較しています。
シングルステップノイズ除去の場合、Onetime-Negative RCFG と従来の CFG の推論時間はほぼ同じです。
つまり、シングルステップノイズ除去中のワンタイム RCFG と従来の CFG の推論時間はほぼ同じです。ただし、ノイズ除去ステップの数が増加するにつれて、従来の CFG から RCFG への推論速度の向上がより明らかになります。
ノイズ除去の 5 番目のステップでは、セルフネガティブ RCFG は従来の CFG より 2.05 倍高速で、ワンタイムネガティブ RCFG は従来の CFG より 1.79 倍高速です。
 写真
写真
 写真
写真
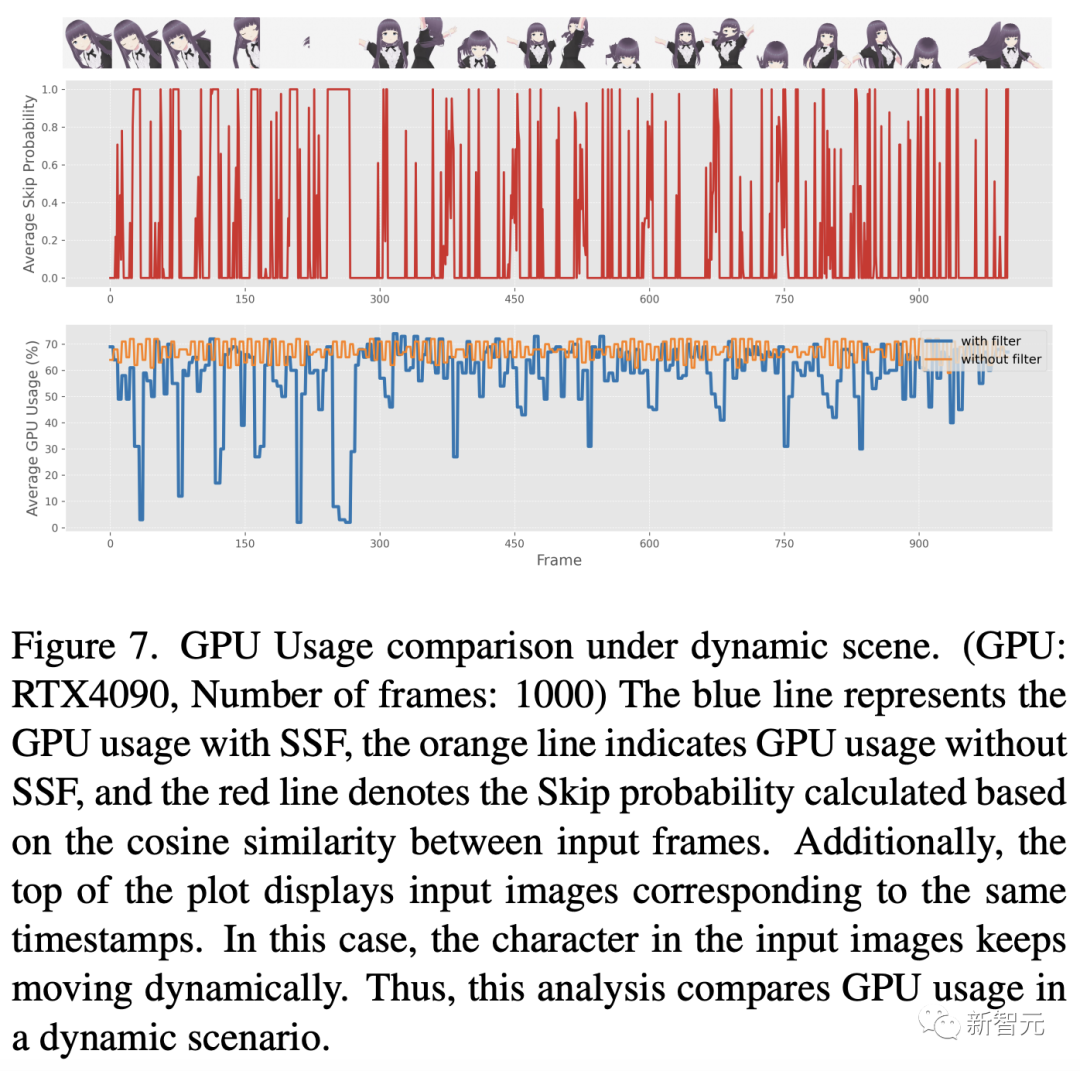
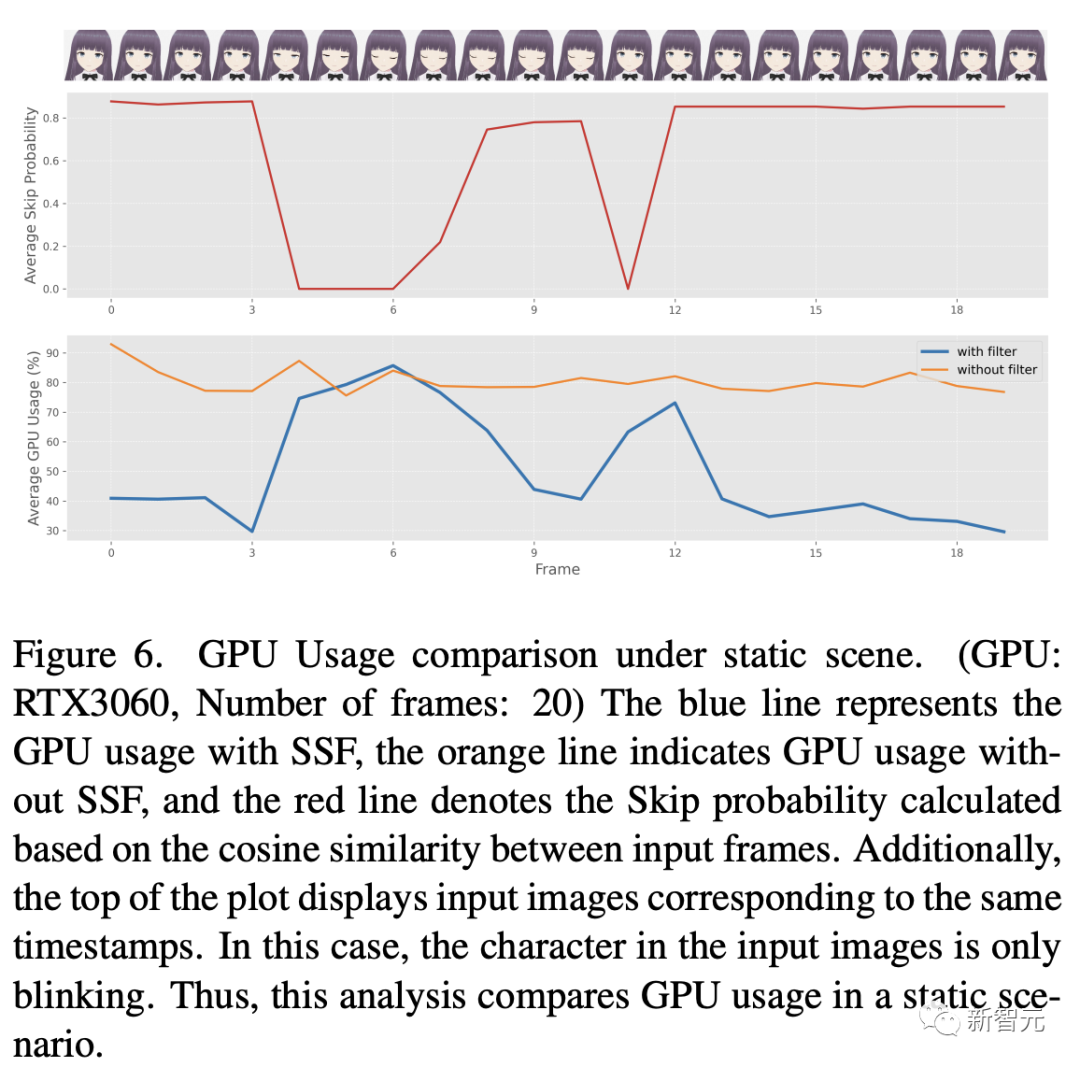
この後、研究者たちはエネルギー消費量を包括的に調査しました。評価されました。このプロセスの結果を図 6 と 7 に示します。
これらの図は、定期的な静的比較分析を含めるために入力ビデオに SSF を適用する (しきい値 eta を 0.98 に設定する) ことを示しています。特徴的なシーンにおける GPU 使用パターンの分析から、入力画像が主に静止画像で類似性が高い場合、SSF を使用すると GPU 使用量が大幅に削減できることがわかります。
写真
 アブレーション研究
アブレーション研究
写真
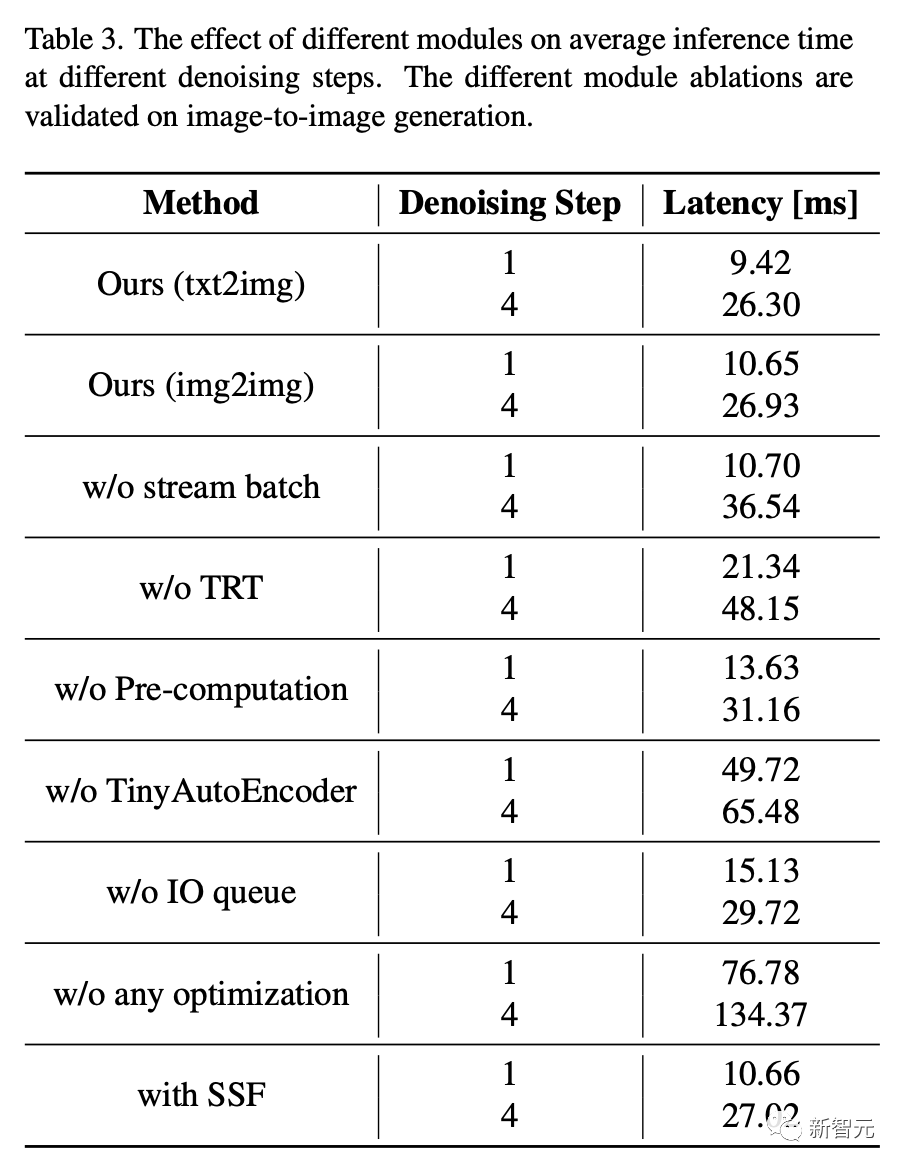 定性的な結果
定性的な結果
形式の CFG を使用せずに生成された画像には、特に色の変更などの側面で弱い位置合わせのヒントが表示されます。または、存在しない要素の追加が効率的に実装されていませんでした。
対照的に、CFG または RCFG を使用すると、髪の色の変更、体のパターンの追加、メガネなどのオブジェクトの追加など、元の画像を変更する機能が強化されます。特に、RCFG を使用すると、標準の CFG と比較してキューのインパクトを高めることができます。
画像
 最後に、標準的なテキストから画像への生成結果の品質を図 11 に示します。
最後に、標準的なテキストから画像への生成結果の品質を図 11 に示します。
sd-turbo モデルを使用すると、図 11 に示すような高品質の画像を 1 ステップで生成できます。
GPU:RTX 4090、CPU:Core i9-13900K、OS:Ubuntu 22.04.3 LTSの環境で、研究者が提案したフロー拡散パイプラインとSD-turboモデルを使用した場合画像を生成する場合、100fpsを超える高品質の画像を生成することが可能です。
画像
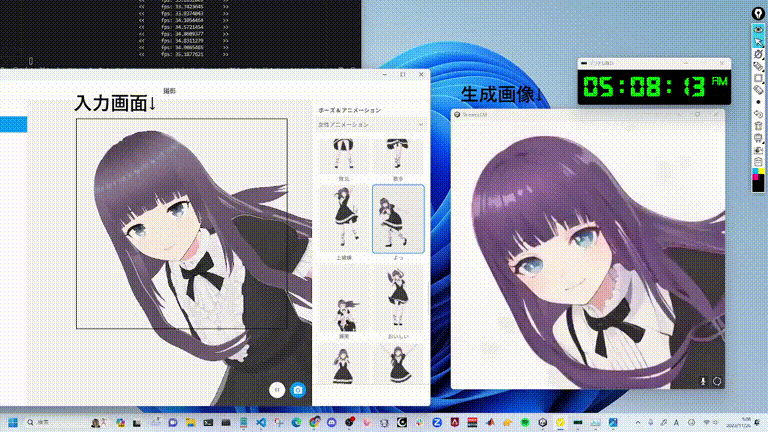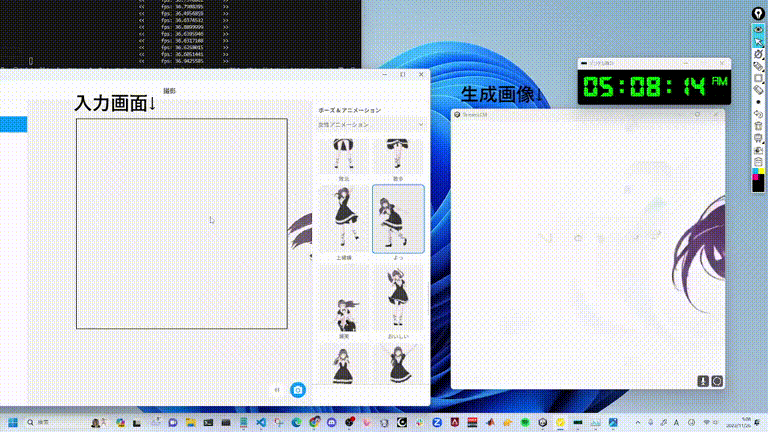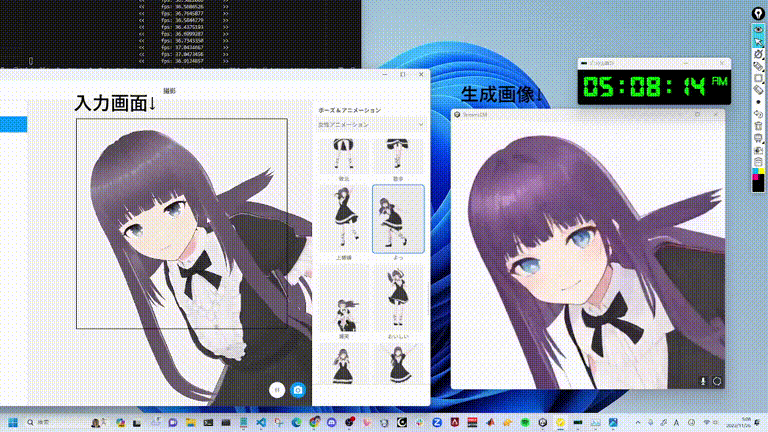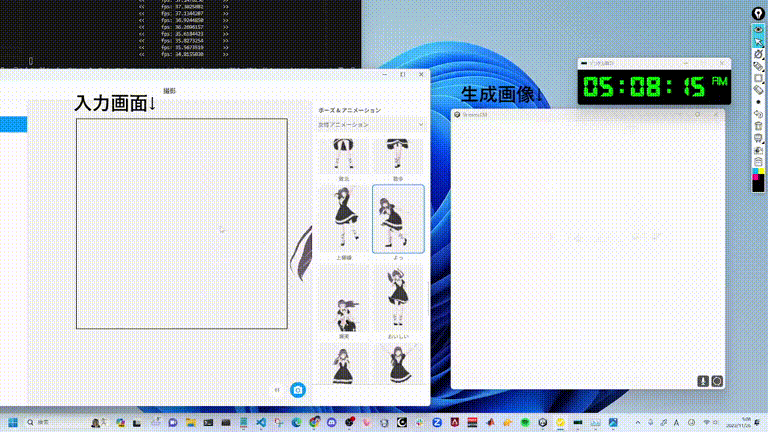
 ネチズンが始めて、二次元女性の大波がやって来た
ネチズンが始めて、二次元女性の大波がやって来た
写真
 プロジェクトアドレス: https://github.com/cumulo-autumn/StreamDiffusion
プロジェクトアドレス: https://github.com/cumulo-autumn/StreamDiffusion
多くのネットユーザーが自分の二次元嫁を生成し始めています。
写真
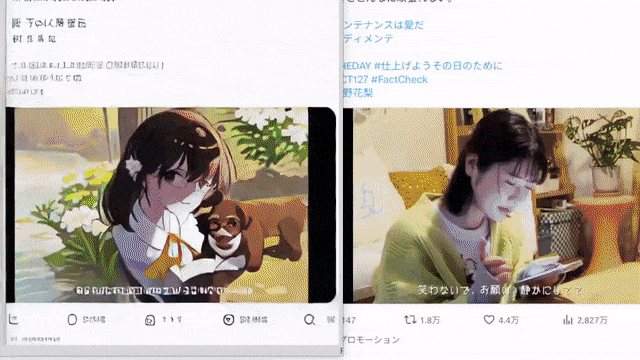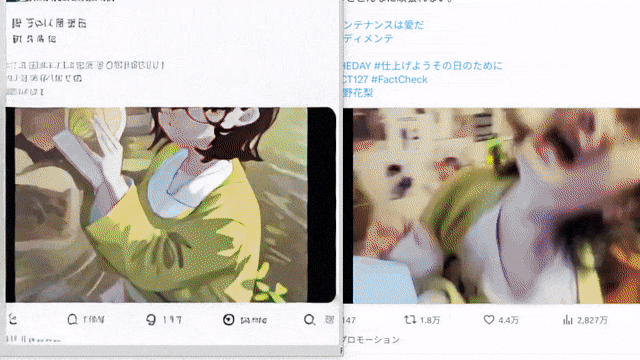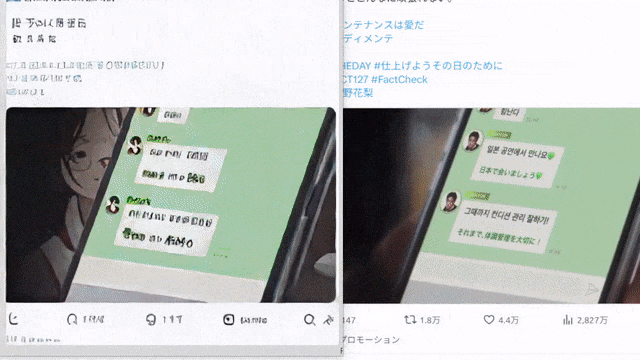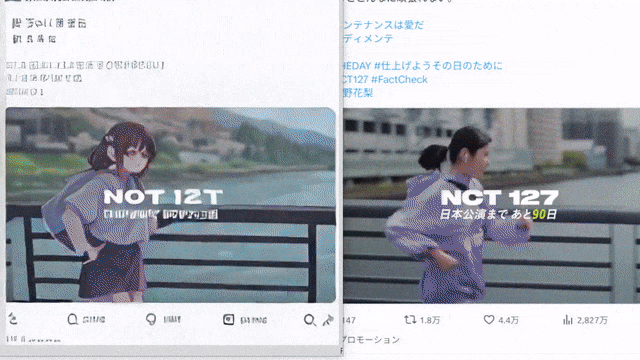
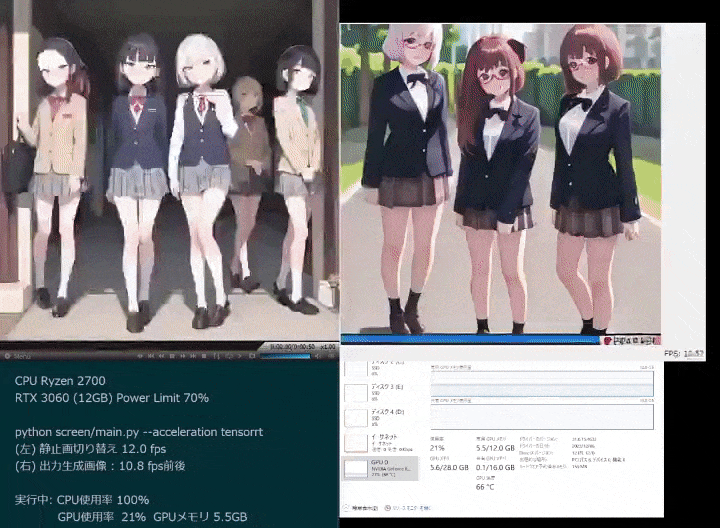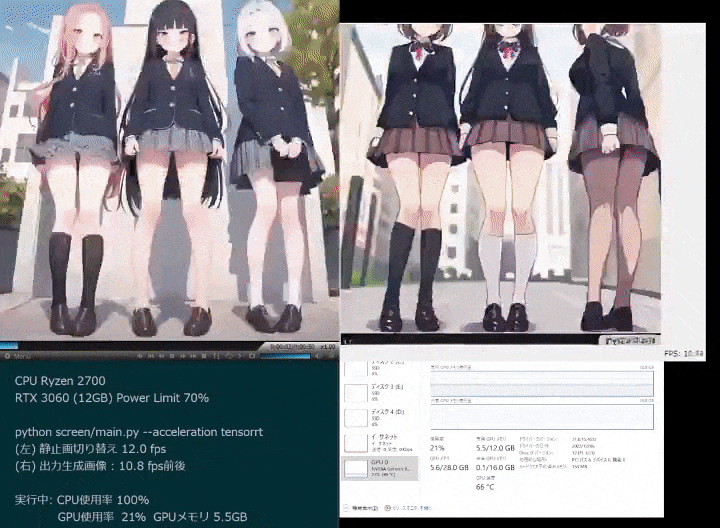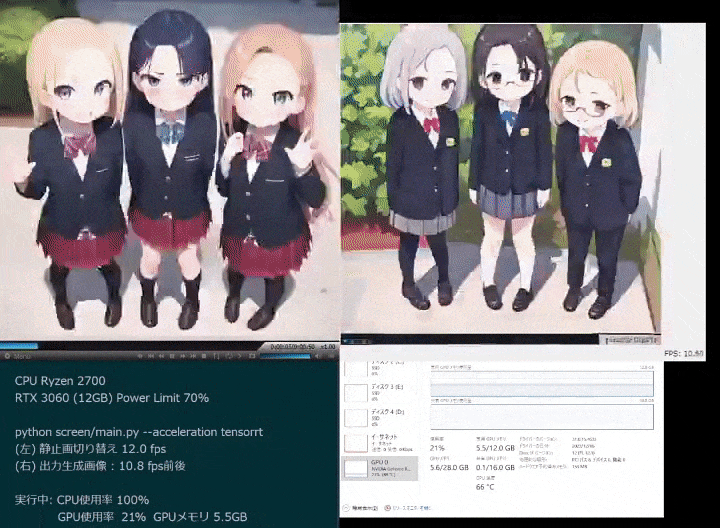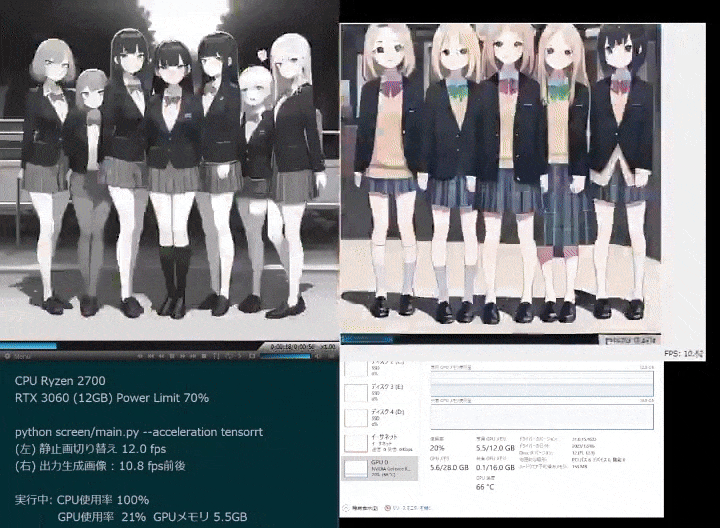
 リアルタイム アニメーションもあります。
リアルタイム アニメーションもあります。
写真
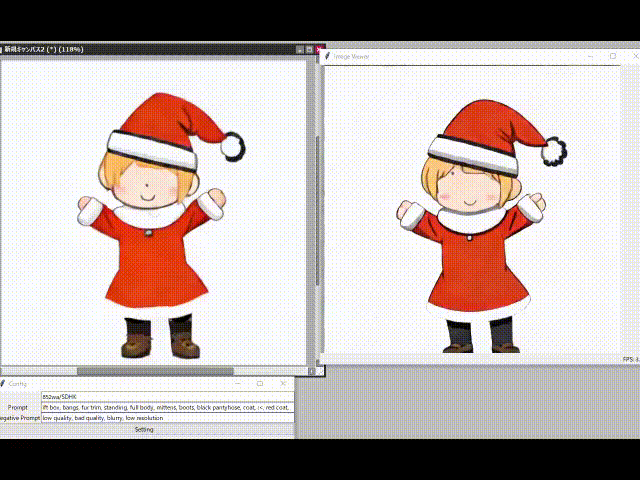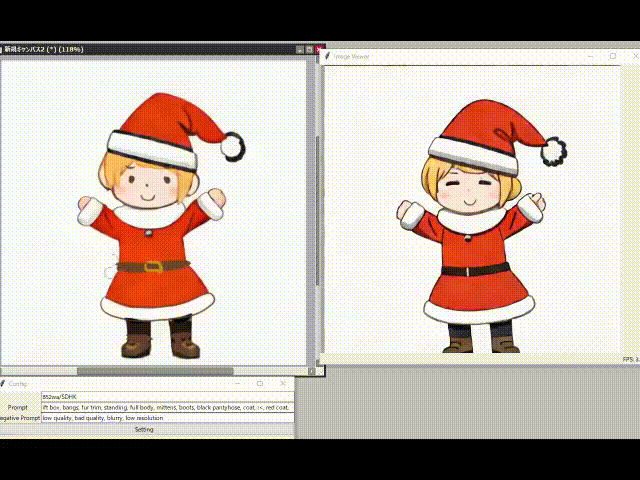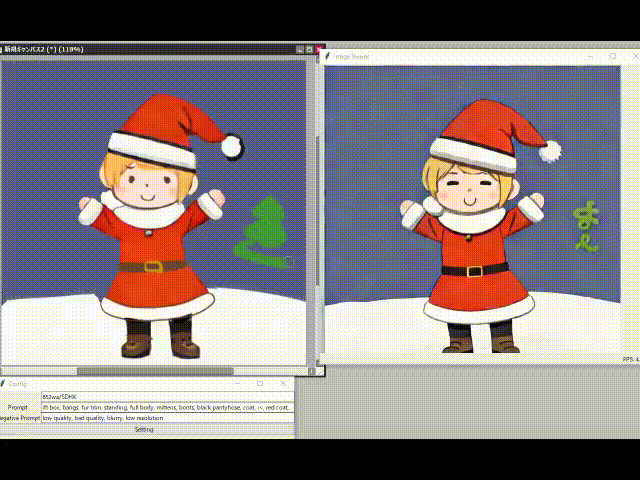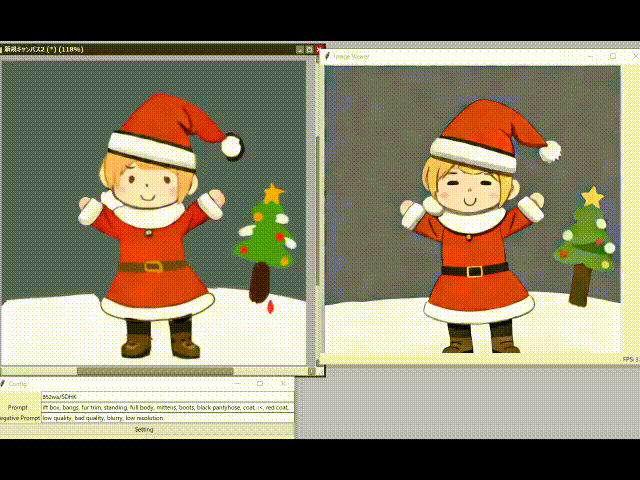
 10 倍速の手描き生成。
10 倍速の手描き生成。
 #写真
#写真
 写真
写真
##写真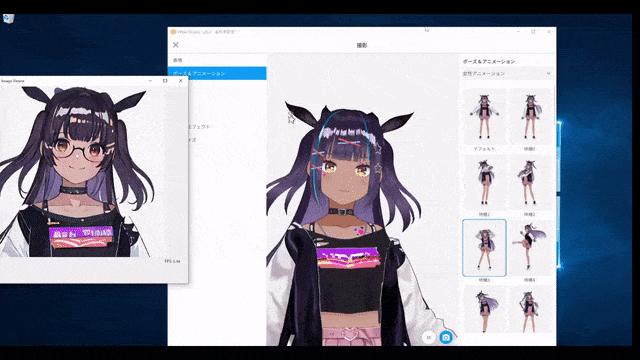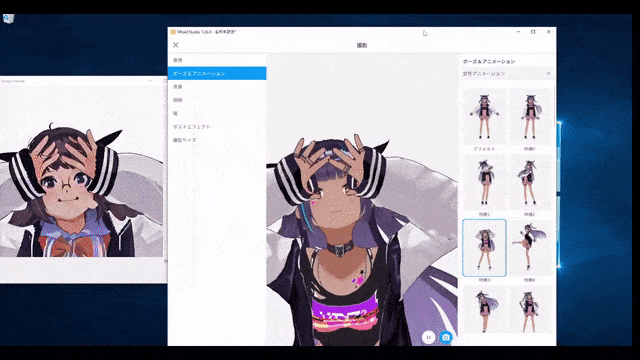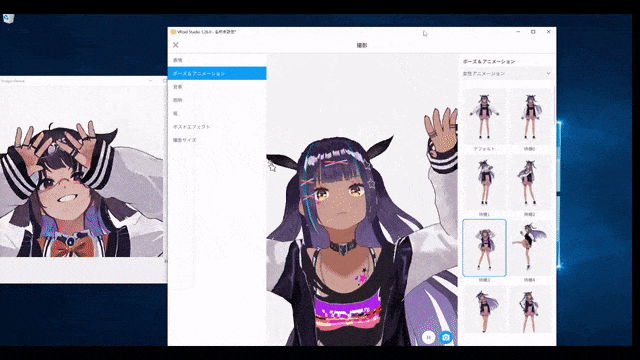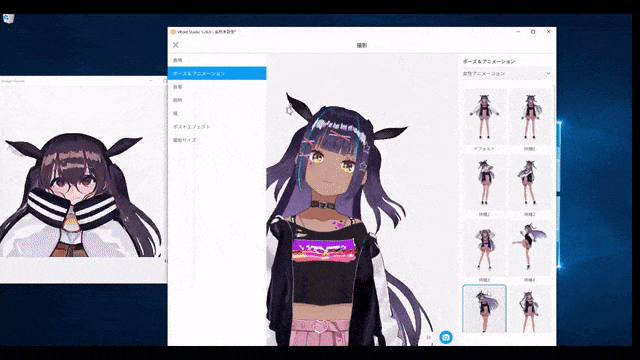 ## 子供靴に興味のある方はぜひ作ってみてはいかがでしょうか。
## 子供靴に興味のある方はぜひ作ってみてはいかがでしょうか。
//m.sbmmt.com/link/f9d8bf6b7414e900118caa579ea1b7be
//m.sbmmt.com/link/75a6e5993aefba4f6cb07254637a6133
以上が無料のパーソナライズされた学術論文推薦システム - ドイツの大学のトップビジュアルチームの「arXiv カスタマイズされたプラットフォーム」を開始の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



