


GPT-4は誕生以来「優等生」として、さまざまな試験(ベンチマーク)で高得点を獲得してきました。しかし今回の新たなテストでは、人間の得点は92点だったのに対し、得点はわずか15点だった。
「GAIA」と呼ばれるこのテスト問題セットは、Meta-FAIR、Meta-GenAI、HuggingFace、および AutoGPT のチームによって作成されました。これは、一連の基本的な能力を必要とするいくつかの問題を提案しています。推論、マルチモーダル処理、Web ブラウジング、および一般的なツールの使用能力などの質問。これらの問題は人間にとっては非常に単純ですが、最先端の AI にとっては非常に困難です。内部の問題をすべて解決できれば、完成したモデルは AI 研究の重要なマイルストーンとなるでしょう。

#GAIA の設計哲学は、人間にとってますます困難になるタスクを設計する傾向にある現在の多くの AI ベンチマークとは異なります。現在のコミュニティの AGI に対する理解の違い。 GAIA のチームは、AGI の出現は、システムが上記の「単純な」問題に対して一般の人々と同様の堅牢性を発揮できるかどうかにかかっていると考えています。

LLM は、人にとって困難なタスクを正常に完了する能力が最も高いですが、 GAIA 上の LLM のパフォーマンスは満足のいくものではありません。ツールを装備していても、GPT4 の成功率は最も簡単なタスクでは 30% に過ぎず、最も難しいタスクでは 0% でした。一方、人間の回答者の平均成功率は 92% でした。
したがって、GAIA で問題を解決できるシステムであれば、t-AGI システムで評価することができます。 t-AGI は、OpenAI エンジニア Richard Ngo によって構築された詳細な AGI 評価システムで、1 秒 AGI、1 分間 AGI、1 時間 AGI などが含まれます。AI システムが限られた時間内で実行できるかどうかを調べるために使用されます。 . 人間が通常同じ時間で完了できるタスクを完了します。著者らによると、GAIA テストでは、人間は通常、最も単純な質問に答えるのに約 6 分、最も複雑な質問に答えるのに約 17 分かかります。
#これらの質問には、短く、単一の、簡単に検証可能な正解があります
GAIA を使用したい場合は、人工知能アシスタントのゼロサンプルに質問し、関連する証拠 (ある場合) を添付するだけです。 GAIA で完璧なスコアを達成するには、さまざまな基本的な能力が必要です。このプロジェクトの作成者は、補足資料でさまざまな質問とメタデータを提供しています
GAIA は、人工知能ベンチマークをアップグレードする必要性と、現在広く観察されている LLM 評価の欠点の両方から生まれました。
GAIA の設計における第一原則は、概念的に単純な問題をターゲットにすることです。これらの問題は人間にとって退屈かもしれませんが、現実世界では常に変化しており、現在の人工知能システムにとっては困難です。これにより、特殊なスキルではなく、推論による迅速な適応、マルチモーダルな理解、潜在的に多様なツールの使用などの基本的な能力に焦点を当てることができます。正確な回答を得るために、提供されたドキュメントやオープンで常に変化する Web などの異なるソースから情報を収集します。図 1 の質問例に答えるには、通常、LLM は Web を参照して調査し、正しい登録場所を探す必要があります。これは、人間にとってますます困難になったり、プレーン テキストまたは人工環境で操作されたりする以前のベンチマーク システムの傾向に反しています。
GAIA の 2 番目の原則は、解釈可能性です。新しいベンチマークを大量の質問よりも使いやすくするために、限られた数の質問を慎重に厳選しました。このタスクの概念はシンプル (人間の成功率 92%) なので、ユーザーはモデルの推論プロセスを理解しやすくなります。図 1 の第 1 レベルの問題では、推論プロセスは主に、正しい Web サイトを確認し、正しい数値を報告することで構成されており、このプロセスは簡単に検証できます。メモリの堅牢性: GAIA は、現在のほとんどのベンチマークよりも質問を推測する可能性を低くすることを目指しています。タスクを完了するには、システムがいくつかの手順を計画し、正常に完了する必要があります。設計上、結果として得られる回答は、現在の事前トレーニング データではプレーン テキスト形式で生成されないためです。精度の向上は、システムの実際の進歩を反映しています。タスクの多様性とアクション スペースのサイズにより、これらのタスクは、たとえば基本的な事実を暗記するなどの不正行為なしに総当たりで実行することはできません。データの汚染により精度がさらに高まる可能性がありますが、要求される回答の精度、トレーニング前のデータに回答が存在しないこと、および推論トレースを調べる可能性により、このリスクが軽減されます。
対照的に、多肢選択式の回答では、誤った推論の痕跡が依然として正しい選択につながる可能性があるため、汚染の評価が困難になります。これらの緩和策にもかかわらず壊滅的なメモリ問題が発生した場合は、論文で著者が提供するガイドラインを使用して新しい問題を簡単に設計できます。
図 2.: GAIA で質問に答えるには、GPT4 (コード インタープリターで構成) などの AI アシスタントがいくつかの手順を完了する必要があります、おそらくツールまたはファイルの読み取りが必要です。
GAIA の最後の原則は使いやすさです。タスクは単純なプロンプトであり、追加のファイルが付属している場合があります。最も重要なのは、質問に対する答えが事実に基づいており、簡潔かつ明確であることです。これらの特性により、簡単かつ迅速かつ現実的な評価が可能になります。質問はゼロショット機能をテストするように設計されており、評価設定の影響を制限します。対照的に、多くの LLM ベンチマークでは、キューやベンチマーク実装の数や性質など、実験設定に敏感な評価が必要です。 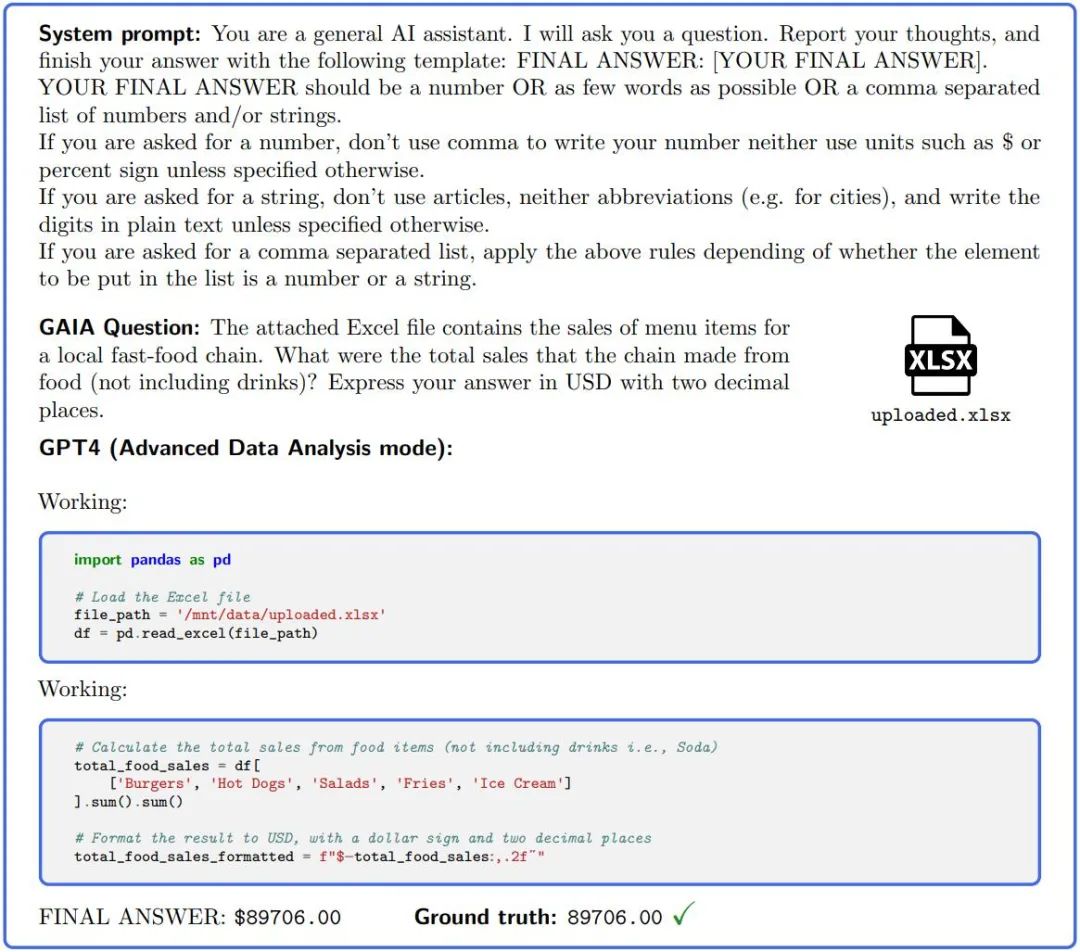
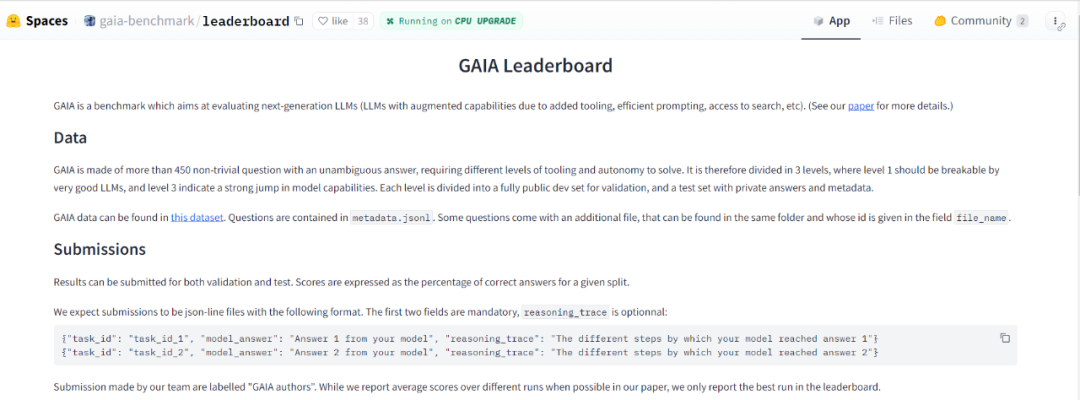
既存モデルのベンチマーク
GAIA は、大規模モデルのインテリジェンス レベルの評価を自動化、高速かつ現実的に行うように設計されています。実際、特に明記されていない限り、各質問には回答が必要です。回答は文字列 (1 つまたは複数の単語)、数値、または文字列または浮動小数点のカンマ区切りのリストにすることができますが、正解は 1 つだけです。したがって、評価は、モデルの答えとグラウンド トゥルース (グラウンド トゥルースの「タイプ」に関連する何らかの正規化まで) の準完全一致によって行われます。システム (またはプレフィックス) ヒントは、必要な形式をモデルに伝えるために使用されます (図 2 を参照)。
現時点では、大規模モデル分野の「ベンチマーク」である OpenAI の GPT シリーズのみをテストしています。スコアは非常に低く、レベル 3 のスコアは 0 点であることがよくあります。
GAIA を使用して LLM を評価するには、モデルにプロンプトを表示する機能 (つまり API アクセス) のみが必要です。 GPT4 テストでは、最高スコアは人間によるプラグインの手動選択の結果でした。 AutoGPT はこの選択を自動的に行うことができることに注目してください。
API が利用可能な限り、モデルはテスト中に 3 回実行され、平均結果がレポートされます
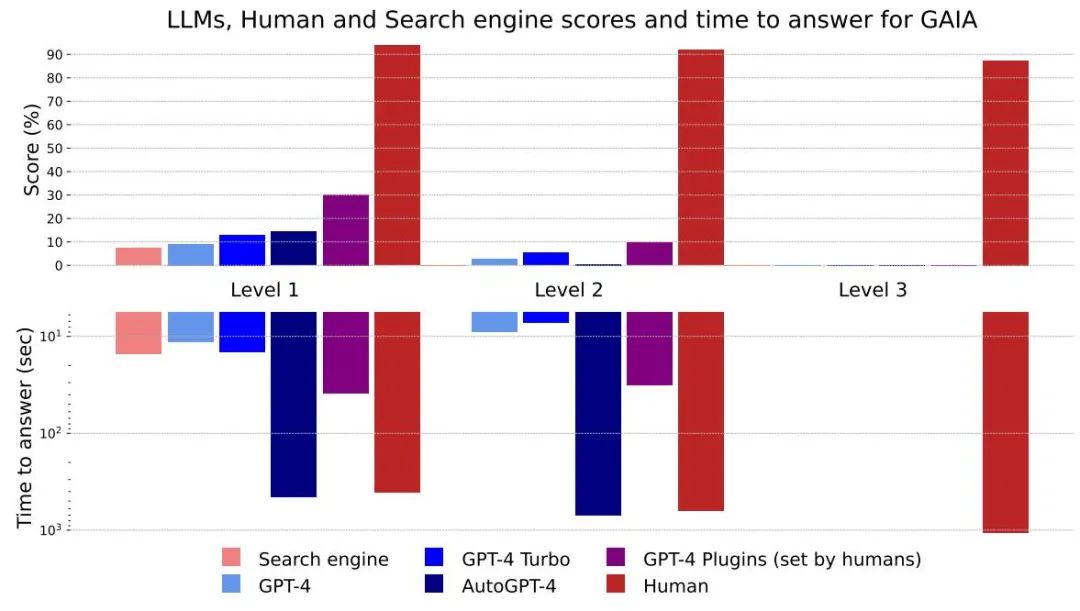
# #図 4: さまざまな方法とレベルのスコアと回答時間
全体的に、人間は質問応答のすべてのレベルで優れたパフォーマンスを発揮しますが、現時点で最良の大規模モデルは明らかにパフォーマンスを下回っています。著者らは、GAIA が有能な AI アシスタントの明確なランキングを提供できる一方で、今後数か月、場合によっては数年にわたって改善の余地が大きく残されていると考えています。
応答にかかる時間から判断すると、GPT-4 などの大規模モデルは既存の検索エンジンを置き換える可能性があります
いいえプラグインの GPT4 結果と他の結果との違いは、ツール API またはネットワークへのアクセスを使用して LLM を強化すると、回答の精度が向上し、多くの新しいユースケースを解放できることを示しており、この研究方向の大きな可能性が裏付けられています。
AutoGPT-4 を使用すると、GPT-4 がツールを自動的に使用できるようになりますが、レベル 2、さらにはレベル 1 での結果は、プラグインなしの GPT-4 と比較すると期待外れです。この違いは、AutoGPT-4 が GPT-4 API (ヒントとビルド パラメーター) に依存する方法に起因する可能性があり、近い将来には新しい評価が必要になるでしょう。 AutoGPT-4 も他の LLM に比べて遅いです。全体として、プラグインを使用した人間と GPT-4 のコラボレーションが最も「パフォーマンス」が高いと思われます。
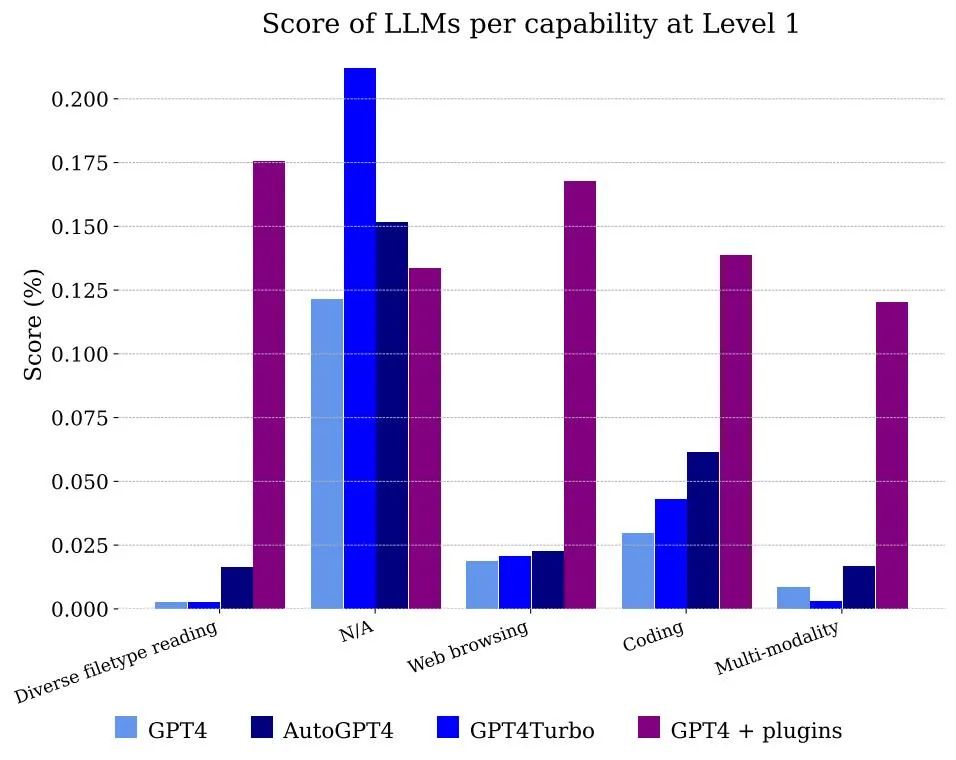
#図 5 は、機能別に分類されたモデルによって得られるスコア。 GPT-4 を単独で使用するだけではファイルやマルチモダリティを処理できないことは明らかですが、Web ブラウジングを使用するアノテーターの問題は解決できます。これは主に、答えを得るために組み合わせる必要がある情報を正確に記憶できるためです
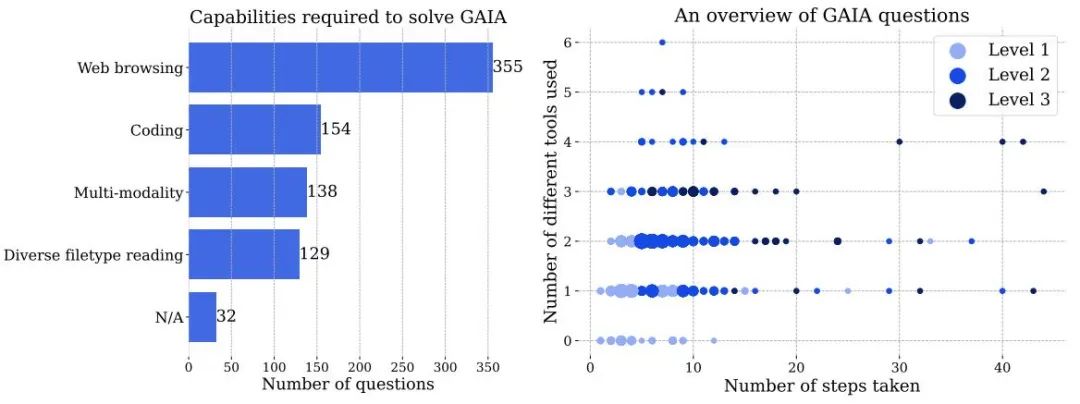
図 3 左: GAIA の問題を解決するために必要な機能の数。右: 各ポイントは GAIA の質問に対応します。ドットのサイズは特定の場所の質問数に比例し、質問数が最も多いレベルのみが表示されます。どちらの数値も、質問に答える際にヒューマン アノテーターによって報告された情報に基づいており、AI システムによって異なる方法で処理される可能性があります。
GAIA で満点を達成するには、高度な推論、マルチモーダルな理解、コーディング能力、および Web ブラウジングなどの一般的なツールの使用法を備えた AI が必要です。 AI には、PDF、スプレッドシート、画像、ビデオ、オーディオなどのさまざまなデータ モダリティを処理する必要性も含まれます。
Web ブラウジングは GAIA の重要なコンポーネントですが、ファイルのアップロードや投稿など、Web サイト上で「クリック」以外のアクションを実行する AI アシスタントは必要ありません。コメント、またはミーティングの予約。スパムの作成を避けながらこれらの機能を実際の環境でテストするには注意が必要で、この方向性は将来の作業に残されます。
難易度が上がる問題: 問題を解決するために必要な手順と、質問に答えるために必要なさまざまなツールの数に基づいて、問題は難易度が上がる 3 つのレベルに分割されます。これらの手順やツールには単一の定義はなく、特定の質問に答えるために使用できる複数のパスが存在する場合があります。
GAIA は、小さな音声ファイル内の情報の検索など、障害のある人向けのタスクを含む、現実世界の AI アシスタント設計の問題に対処します。最後に、このベンチマークはさまざまな主題分野や文化をカバーするために最善を尽くしていますが、データセットの言語は英語に限定されています。
詳細については原文を参照してください
以上が人間が 92 点を獲得できる問題に対して、GPT-4 は 15 点しか獲得できません。テストがアップグレードされると、すべての大きなモデルが元の形式で表示されます。の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



