



インターネットの発展により、企業はますます多くのデータを取得できるようになりました。このデータは、企業が顧客プロファイルと呼ばれるユーザーをより深く理解するのに役立ち、ユーザー エクスペリエンスを向上させることができます。ただし、これらのデータにはラベルのないデータが大量に含まれる可能性があります。すべてのデータに手動でラベルを付ける場合、2 つの問題が発生します。まず、手動でのラベル付けは時間がかかり、非効率的です。データ量が増加すると、より多くの人員を雇用する必要があり、時間がかかり、コストも高くなります。第 2 に、ユーザーの規模が増加するにつれて、手動のラベル付けではデータの増加に追いつくことが困難になります
半教師あり学習とは、ラベル付きデータとラベルなしデータの両方を使用してモデルをトレーニングすることを指します。半教師あり学習では通常、ラベル付きデータに基づいて属性空間を構築し、ラベルなしデータから有効な情報を抽出して属性空間を埋める(または再構築)します。したがって、半教師あり学習の初期トレーニング セットは、通常、ラベル付きデータ セット D1 とラベルなしデータ セット D2 に分割され、前処理や特徴抽出などの基本的な手順を通じて半教師あり学習モデルがトレーニングされ、トレーニングされたモデルが完成します。ユーザーにサービスを提供するための実稼働環境に使用されます。
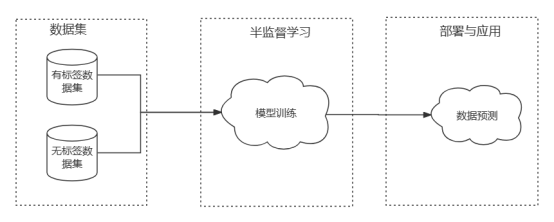
効果的なラベルデータ補完を実現するためにラベル付けされたデータを使用して、データ内の「有用な」情報を使用し、データのセグメント化やその他の側面についていくつかの仮定を立てます。半教師あり学習の基本的な前提は、p(x) には p(y|x) の情報が含まれているということです。つまり、ラベルなしデータには、ラベル予測に役立ち、ラベル付きデータとは異なる、または困難な情報が含まれている必要があります。ラベル付けされたデータから、データから抽出された情報を取得します。さらに、アルゴリズムに役立ついくつかの仮定があります。たとえば、類似性仮説 (滑らかさ仮説) は、データ サンプルによって構築された属性空間において、近いサンプルまたは類似したサンプルが同じラベルを持つことを意味し、低密度分離仮説は、異なるラベルが存在する場所に異なるラベルを区別できる決定境界があることを意味します。いくつかのデータサンプルです。
上記の仮定の主な目的は、ラベル付きデータとラベルなしデータが同じデータ分布に由来することを示すことです。
半教師あり学習アルゴリズムは多数あります。 Transductive learning と Inductive learning (帰納モデル) に大別され、 2 つの違いは、モデル評価に使用されるテスト データ セットの選択 にあります。ダイレクトプッシュ半教師あり学習とは、ラベルを予測する必要があるデータセットがトレーニングに使用されるラベルなしのデータセットであることを意味し、学習の目的は予測結果の精度をさらに向上させることです。帰納学習は、まったく未知のデータセットのラベルを予測します。
さらに、一般的な半教師あり学習アルゴリズムのステップは次のとおりです。最初のステップは、ラベル付きデータでモデルをトレーニングし、次に使用することです。このモデルは、ラベルのないデータに擬似ラベルを付け、擬似ラベルとラベル付きデータを新しいトレーニング セットに結合し、このトレーニング セットで新しいモデルをトレーニングし、最後にこのモデルを使用して予測データ セットにラベルを付けます。 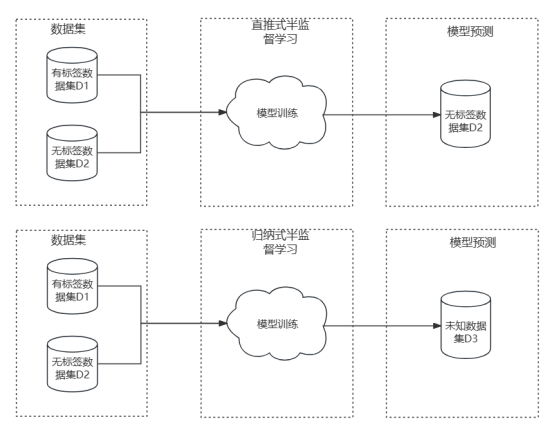
パート 04. 概要
半教師あり学習の開発の方向性は、アルゴリズムの堅牢性とデータ抽出の有効性を向上させることです。 現在、半教師あり学習の分野では、PU 学習 (正および負のサンプル学習) が人気のアルゴリズムです。このタイプのアルゴリズムは主に、陽性サンプルとラベルのないデータのみを含むデータセットに適用されます。その利点は、特定のシナリオでは、信頼できる陽性のサンプル データ セットを比較的簡単に取得でき、データ量が比較的大きいことです。たとえば、スパム検出では、大量の通常の電子メール データを簡単に取得できます。
以上がタイトルを書き直しました: 半教師あり学習の応用分野とその関連シナリオの探索の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



