


最近、新しい論文が出版されるスピードが速すぎて、読めない気がします。言語と視覚に関するマルチモーダルな大規模モデルの融合が業界のコンセンサスになっていることがわかります。UniiPad に関するこの記事は、マルチモーダル入力と世界に似たモデルの事前トレーニングされたベース モデルを備えた、より代表的なものです。複数の従来のビジョン アプリケーションに拡張するのが簡単です。また、大規模言語モデルの事前トレーニング方法を 3D シーンに適用する問題も解決され、知覚ベースの統合された大規模モデルの可能性が提供されます。
UniPAD は、MAE と 3D レンダリングに基づく自己教師あり学習手法で、優れたパフォーマンスでベース モデルをトレーニングし、深度推定、物体検出、セグメンテーション。この研究では、2D および 3D フレームワークに簡単に統合できる統合 3D 空間表現方法を設計しました。これにより、優れた柔軟性が示され、ベース モデルの位置付けとの一貫性が示されます。
マスク自動エンコード技術と 3D 微分可能レンダリング技術の関係は何ですか?簡単に言うと、マスクされた自動エンコーディングは Autoencoder の自己教師ありトレーニング機能を利用することであり、レンダリング テクノロジーは、生成された画像と元の画像の間の損失関数を計算し、教師ありトレーニングを実行することです。したがって、ロジックは依然として非常に明確です。
この記事では、基本モデルの事前トレーニング方法 を使用し、その後、ダウンストリームの検出方法とセグメンテーション方法を微調整します。この方法は、現在の大規模モデルが下流のタスクでどのように動作するかを理解するのにも役立ちます。
はタイミング情報と結合されていないようです。結局のところ、Pure Vision 50.2 の NuScenes NDS は、タイミング検出手法 (StreamPETR、Sparse4D など) と比較すると、現時点ではまだ弱いです。したがって、4D MAE 法も試してみる価値はありますが、実は GAIA-1 でも同様のアイデアが既に言及されています。
計算量やメモリ使用量はどうでしょうか?
UniPAD は 3D 空間情報を暗黙的にエンコードします。これは主にマスク自動エンコーディング (MAE、VoxelMAE など) からインスピレーションを得ています。この記事では A生成マスクはボクセル特徴の強化を完了するために使用され、シーン内の連続 3D 形状構造と 2D 平面上の複雑な外観特徴を再構築するために使用されます。
私たちの実験結果は、UniPAD の優位性を十分に証明しています。従来の LIDAR、カメラ、LIDAR とカメラの融合ベースラインと比較して、UniPAD の NDS はそれぞれ 9.1、7.7、6.9 向上しました。 nuScenes 検証セットでは、事前トレーニング パイプラインが 73.2 の NDS を達成し、3D セマンティック セグメンテーション タスクでは 79.4 の mIoU スコアを達成し、以前の方法と比較して最高の結果を達成したことは注目に値します
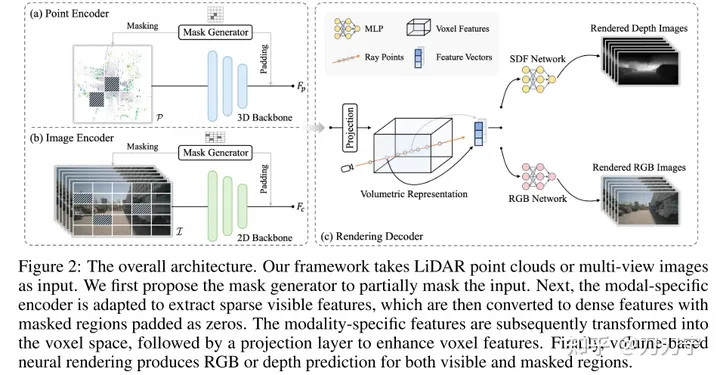
全体的なアーキテクチャ。フレームワークは LiDar とマルチショット画像を入力として受け取り、これらのマルチモーダル データはマスク ジェネレーターを通じてゼロで埋められます。マスクされた埋め込みはボクセル空間に変換され、レンダリング技術を使用してこの 3D 空間で RGB または深度予測が生成されます。このとき、マスクで隠されていない元の画像を教師あり学習用の生成データとして利用することができる。
Masked AutoEncoder のマスクは、Mask Generator によって生成されます。学習の難易度を上げることでモデルの表現能力や汎化能力が向上すると理解できます。マスク ジェネレーターは、特定の領域を選択的に遮ることによって点群データと画像データを区別するために導入されています。点群データにはブロックマスキング戦略が採用され、画像データにはスパースコンボリューション法が使用され、可視領域のみで計算が実行されます。入力データがマスクされると、後続のエンコード特徴は、対応するマスクされた領域で 0 に設定され、モデル処理では無視されます。また、ターゲットの予測に使用できる情報と、対応するグラウンドトゥルース情報を使用した後続の教師あり学習も提供されます
事前トレーニング方法をさまざまなデータ モダリティに適用できるようにするには、統一表現を見つけることが重要です。 BEV や OCC などの過去の手法では、統一された識別形式が求められており、3D ポイントを画像平面に投影すると奥行き情報が失われ、それらを BEV 鳥瞰図にマージすると高さ関連の詳細が失われます。したがって、この記事では、両方のモダリティを、OCC に似た 3D ボクセル空間である 3D ボリューム空間に変換することを提案します。
微分可能レンダリング技術 これは、次のようになります。著者によれば、この論文の最大のハイライトは、NERF のようなサンプリング光線を使用して、多視点画像または点群を通過し、ニューラル ネットワーク構造を通じて各 3D 点の色または深度を予測し、最終的に 2D データを取得することです。光線の経路を通じて、マッピングの。これにより、画像内の幾何学的またはテクスチャの手掛かりをより適切に利用でき、モデルの学習能力と適用範囲が向上します。
シーンを SDF (暗黙的符号付き距離関数フィールド) として表します。入力がサンプリング ポイントの 3D 座標 P (光線に沿った対応する深さ D) と F (特徴の埋め込みは体積測定から抽出できます) である場合、トライリニア補間による表現)により、SDF を MLP とみなしてサンプリング点の SDF 値を予測することができます。ここで、F は点 P が位置するエンコード コードとして理解できます。次に出力が得られます: N (表面法線上のカラー フィールドの条件付け) と H (ジオメトリ特徴ベクトル) このとき、3D サンプリング ポイントの RGB は、P、D、F、N の MLP を通じて取得できます。 、H を入力値と深度値として使用し、レイを介して 3D サンプリング ポイントを 2D 空間に重ね合わせて、レンダリング結果を取得します。ここでのレイの使い方は基本的にナーフと同じです。
レンダリング方法ではメモリ消費を最適化する必要もありますが、これについてはここには記載されていません。ただし、この問題は実装上でより重要な問題です。
マスクとレンダリング メソッドの本質は、事前トレーニングされたモデルをトレーニングすることです。事前トレーニングされたモデルは、後続の分岐がなくても、予測されたマスクに基づいてトレーニングできます。事前トレーニング モデルの後続の作業では、さまざまなブランチを通じて RGB と深度の予測を生成し、ターゲット検出/セマンティック セグメンテーションなどのタスクを微調整して、プラグ アンド プレイ機能を実現します
損失関数は複雑ではありません。 ################## 実験結果: ############################ #他の最近の研究との比較:
 実際、GAIA-1 はタイミングに関してマスク AutoEncoder のアイデアをすでに使用していますが、監視データはさまざまな時点のデータのフレーム全体ですが、UniPAD はランダムに使用しています。 3D 空間でマスクの一部を抽出して予測を監視します。この2つを組み合わせる方法が見つかるのを本当に楽しみにしています。
実際、GAIA-1 はタイミングに関してマスク AutoEncoder のアイデアをすでに使用していますが、監視データはさまざまな時点のデータのフレーム全体ですが、UniPAD はランダムに使用しています。 3D 空間でマスクの一部を抽出して予測を監視します。この2つを組み合わせる方法が見つかるのを本当に楽しみにしています。
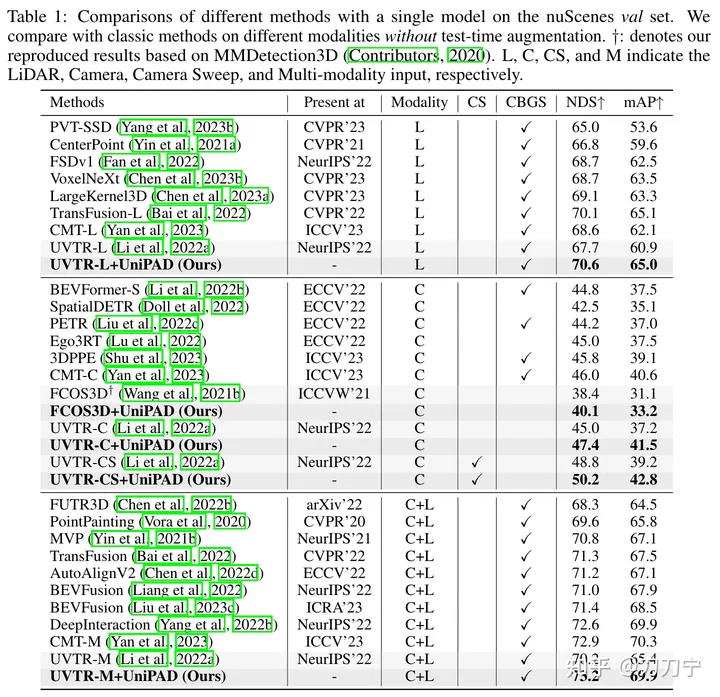
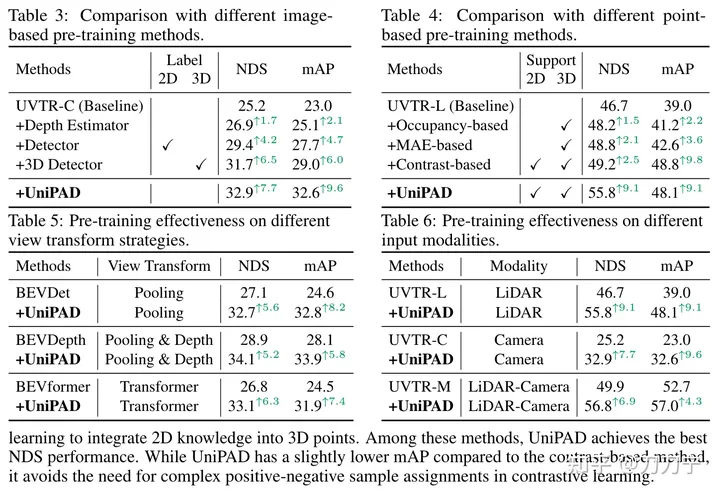 この手法は 3D 分野での可能性があるだけでなく、4D タイミング分野にも拡張でき、メモリと計算量の最適化という点で多くの新しい作業を生み出し、新しいアイデアを提供できます。将来の研究のための洞察と可能性。
この手法は 3D 分野での可能性があるだけでなく、4D タイミング分野にも拡張でき、メモリと計算量の最適化という点で多くの新しい作業を生み出し、新しいアイデアを提供できます。将来の研究のための洞察と可能性。
以上がUniPAD:ユニバーサル自動運転事前トレーニングモード!さまざまな知覚タスクをサポート可能の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



