


AI 生成コンテンツは、現在の人工知能分野で最も注目されているトピックの 1 つであり、この分野の最先端テクノロジーを表しています。近年、Stable Diffusion、DALL-E3、ControlNetなどの新技術のリリースにより、AI画像の生成・編集分野は驚異的な視覚効果を実現し、学界と産業界の両方で幅広い注目と議論を集めています。これらの手法のほとんどは拡散モデルに基づいており、これが強力な制御可能な生成、フォトリアリスティックな生成、多様性を実現する能力の鍵となります。
ただし、単純な静止画像と比較して、ビデオにはより豊富な意味情報と動的な変化が含まれます。ビデオは物理オブジェクトの動的な進化を示すことができるため、ビデオの生成と編集の分野におけるニーズと課題はより複雑です。この分野では、注釈付きデータとコンピューティングリソースの制限により、ビデオ生成の研究は困難に直面していますが、Make-A-Video、Imagen Video、Gen-2 手法などのいくつかの代表的な研究作業はすでに開始されています。支配的な地位を超えて。
これらの研究成果は、ビデオ生成および編集技術の開発方向を導きます。調査データによると、2022 年以降、ビデオ タスクの普及モデルに関する研究作業が爆発的な増加を示しています。この傾向は、学界や産業界におけるビデオ普及モデルの人気を反映しているだけでなく、この分野の研究者がビデオ生成技術の画期的な進歩と革新を続けることが緊急に必要であることも浮き彫りにしています。
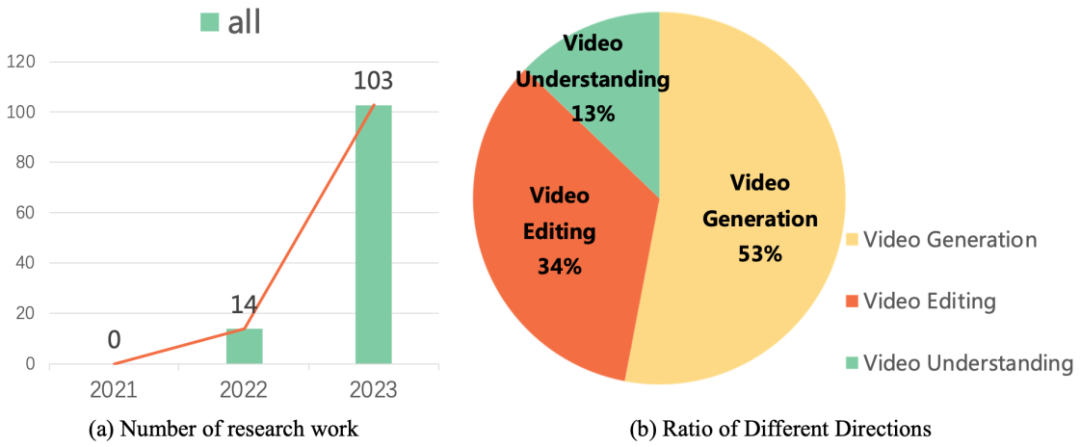
最近、復旦大学のビジョンと学習研究室は、マイクロソフトやファーウェイなどの学術機関と共同で、最初のリリース ビデオ タスクにおける拡散モデルの作業に関するこのレビューでは、ビデオ生成、ビデオ編集、およびビデオ理解における拡散モデルの学術的な最先端の結果が体系的にまとめられています。

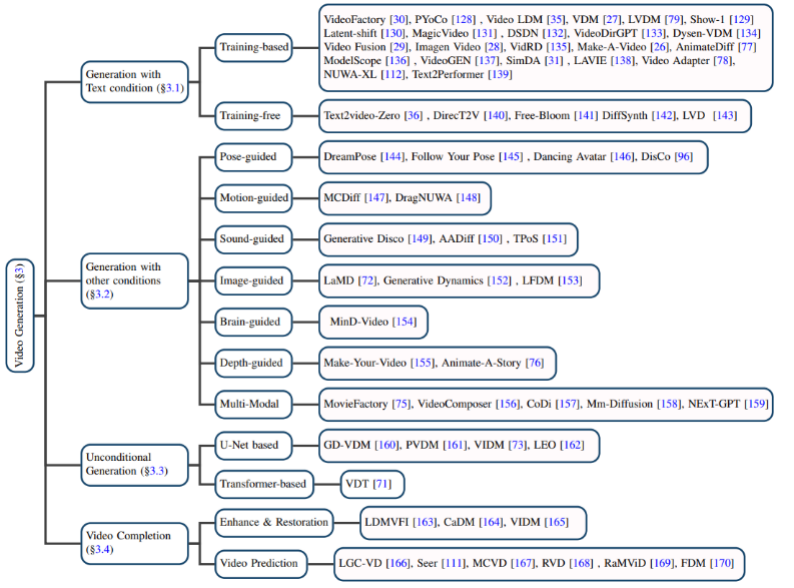
テキストベースのビデオ生成: 自然言語を入力として使用したビデオ生成が、ビデオ生成分野の重要なタスクの 1 つです。著者はまず、普及モデルが提案される前のこの分野の研究結果をレビューし、次にトレーニングベースとトレーニングフリーのテキストビデオ生成モデルをそれぞれ紹介します。

他の条件に基づくビデオ生成: 細分化された分野でのビデオ生成作業。著者は、ポーズ(ポーズガイド付き)、アクション(モーションガイド付き)、サウンド(サウンドガイド付き)、イメージ(画像ガイド付き)、深度マップ(深度ガイド付き)などの条件に基づいて分類しています。

 #無条件ビデオ生成:
#無条件ビデオ生成:
このタスクは、特定のフィールドでの入力条件なしのビデオ生成を指します。著者は、モデル アーキテクチャを主に U-Net ベースの生成モデルと Transformer ベースの生成モデルに分けます。 ビデオ完成:
主にビデオの強化と復元、ビデオ予測などのタスクが含まれます。 #データ セット:
#ビデオ生成タスクで使用されるデータ セットは、次の 2 つのカテゴリに分類できます。1.キャプション レベル: 各ビデオには対応するテキスト説明情報があり、最も代表的なものは WebVid10M データ セットです。 2.カテゴリ レベル: ビデオには分類ラベルのみがあり、テキストの説明情報はありません。UCF-101 は現在、ビデオ生成やビデオ予測などのタスクに最も一般的に使用されるデータ セットです。 評価指標と結果の比較: 動画による評価指標は、主に品質レベルの評価指標と定量レベルの評価指標に分けられます。品質レベルの評価指標は主に手動による主観的なスコアリングに基づいていますが、定量レベルの評価指標は次のように分類できます。レベル: ビデオは一連の画像フレームで構成されているため、画像レベルの評価方法は基本的に T2I モデルの評価指標を参照します。 2. ビデオレベルの評価指標: フレームごとの測定に偏った画像レベルの評価指標と比較して、ビデオレベルの評価指標は時間的コヒーレンスを測定できます。生成されたビデオなどの側面。 さらに、筆者は、ベンチマークデータセットにおける上記生成モデルの評価指標の水平比較も行った。
ビデオ編集 1. 忠実度: 編集されたビデオの対応するフレームは、元のビデオと内容が一致している必要があります。 2. 調整: 編集されたビデオを入力条件に合わせる必要があります。 3. 高品質: 編集されたビデオは一貫性があり、高品質である必要があります。 #テキスト ベースのビデオ編集: 既存のテキスト ビデオ データの規模が限られていることを考慮すると、テキスト ベースのビデオ編集タスクのほとんどは現在、 -トレーニングされた T2I モデルは、ビデオ フレームの一貫性や意味上の不一致などの問題を解決するために使用されます。著者は、こうしたタスクをさらにトレーニングベース、トレーニング不要、ワンショットチューニングの手法に細分化し、それぞれまとめています。
特定のニッチ分野でのビデオ編集: 一部の研究では、ビデオのカラーリングなど、特定の分野でのビデオ編集タスクの特別なカスタマイズの必要性に焦点を当てています。ポートレートビデオ編集など。
このレビューは、ビデオ タスクに関する AIGC 時代の普及モデルに関する最新の研究を包括的かつ細心の注意を払って要約しています。オブジェクトと技術的特徴に基づいて、100 を超える最先端の作品が分類および要約され、これらのモデルがいくつかの古典的なベンチマークで比較されます。さらに、普及モデルには、次のようなビデオ タスクの分野におけるいくつかの新しい研究の方向性と課題もあります: 2. 効率的なトレーニングと推論: ビデオ データは画像データに比べて膨大であり、トレーニングと推論の段階で必要な計算能力も飛躍的に増加しています。効率的なトレーニングと推論アルゴリズムにより、コストを大幅に削減できます。 3. 信頼できるベンチマークと評価指標: ビデオ分野における既存の評価指標は、生成されたビデオと元のビデオの間の分布の違いを測定することがよくありますが、分布を完全に測定することはできません。生成されたビデオの品質。一方、ユーザーテストは依然として重要な評価手法の一つですが、多大な労力と主観的な要素を要することから、より客観的かつ総合的な評価指標の確立が急務となっています。 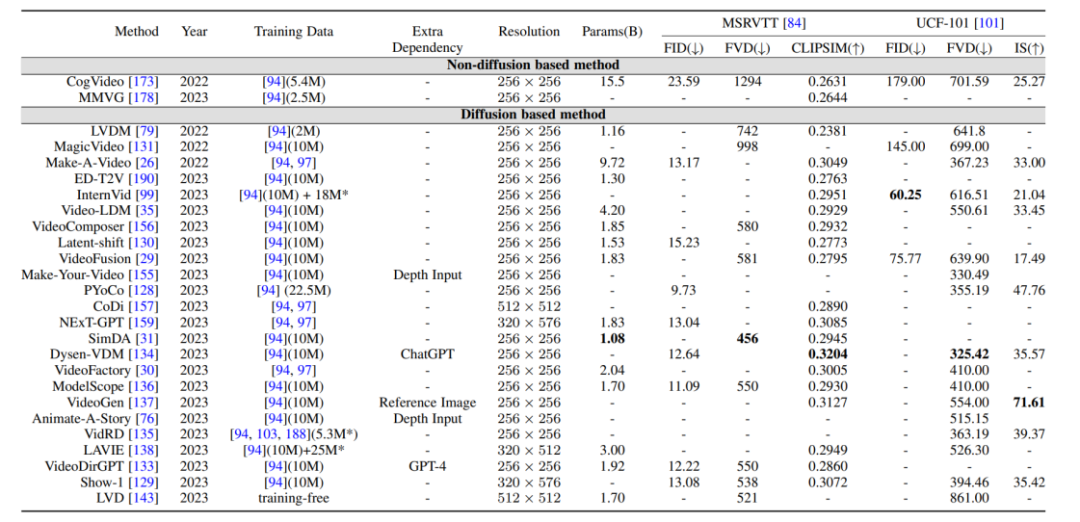
多くの研究を精査することで、著者はビデオの中核的な目標を発見しました。編集タスク それは次の実現にあります:
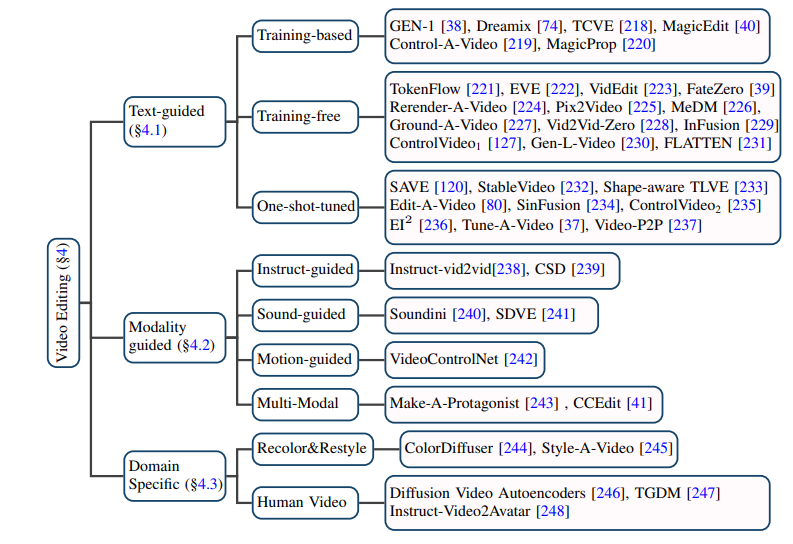

# その他の条件に基づくビデオ編集: 大規模なモデルの場合昨今、自然言語情報に基づいた最も直接的なビデオ編集に加え、指示、音声、アクション、マルチモダリティなどに基づいたビデオ編集がますます注目されており、著者もこれに対応する仕事を行っている。そして仕分け。 
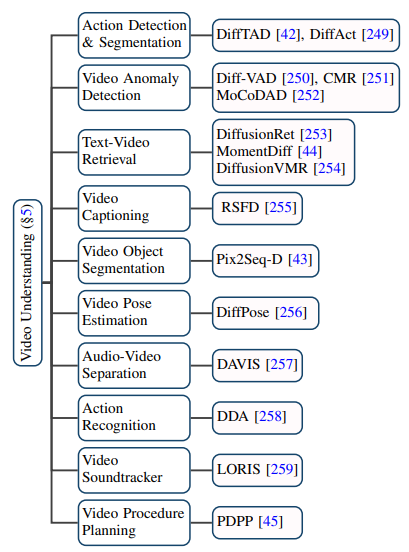
ビデオ分野における普及モデルの応用は、従来のビデオ生成をはるかに超えています。編集タスクだけでなく、ビデオ理解タスクにも大きな可能性を示します。著者は、最先端の論文を追跡することにより、ビデオ時間セグメンテーション、ビデオ異常検出、ビデオオブジェクトセグメンテーション、テキストビデオ検索、アクション認識などの 10 の既存のアプリケーションシナリオをまとめました。
1. 大規模なテキストビデオ データ セットの収集: 成功したT2I モデルの分離 T2V モデルは、何億もの高品質テキスト画像データ セットを開くことなく、サポートとして透かしのない高解像度のテキストビデオ データを大量に必要とします。
以上がAIGC時代のビデオ普及モデル、Fudanらチームが現場初レビューを公開の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



