



この記事では、AmodalSynthDrive を紹介します。AmodalSynthDrive は、自動 A ツールです。運転用の合成アモーダル知覚データセット。部分的なオクルージョンが存在する場合でもオブジェクトの全体を難なく推定できる人間とは異なり、最新のコンピューター ビジョン アルゴリズムでは、この点が依然として非常に困難であることがわかります。このアモーダルな認識を自動運転に活用することは、適切なデータセットが不足しているため、ほとんど研究されていません。これらのデータセットの生成は、主に高価なアノテーション コストと、遮蔽された領域を正確にラベル付けする際のアノテーターの主観によって引き起こされる干渉を軽減する必要性によって影響を受けます。これらの制限に対処するために、この論文では、合成マルチタスク アモーダル知覚データセットである AmodalSynthDrive を紹介します。このデータセットは、150 の運転シーケンスのマルチビュー カメラ画像、3D バウンディング ボックス、LIDAR データ、オドメトリを提供し、さまざまな交通、天候、照明条件下での 100 万を超えるオブジェクト アノテーションが含まれています。 AmodalSynthDrive は、空間理解を強化するためのアモーダル深度推定の導入など、さまざまなアモーダル シーン理解タスクをサポートします。この記事では、タスクごとにいくつかのベースラインを評価して課題を示し、パブリック ベンチマーク サーバーをセットアップします。
この記事の貢献は次のように要約されます:
1) この記事は、AmodalSynthDrive データを提案します。セットは、複数のデータ ソースを使用した都市部の運転シナリオ向けの包括的な合成アモーダル知覚データセットです。
この論文では、アモーダル セマンティクス セグメンテーション、アモーダル インスタンス セグメンテーションを含む、アモーダル知覚タスクのベンチマークを提案します。アモーダル パノラマ セグメンテーション
3) 新しいアモーダル深度推定タスクは、空間理解を促進するように設計されています。このペーパーでは、いくつかのベースラインを通じてこの新しいタスクの実現可能性を実証します。

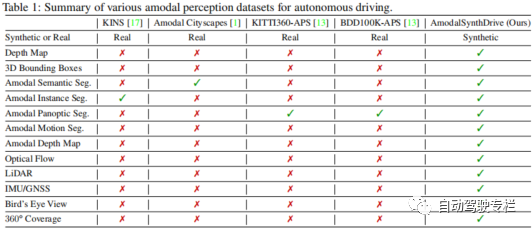


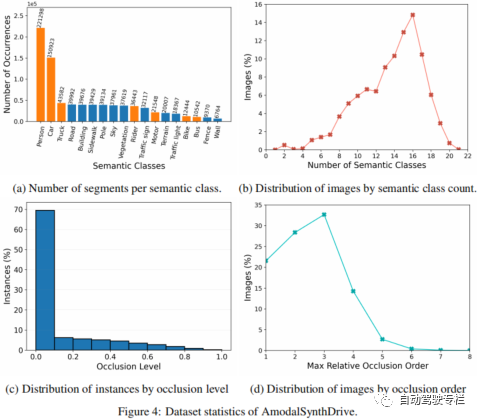
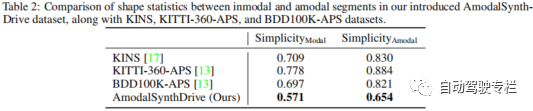
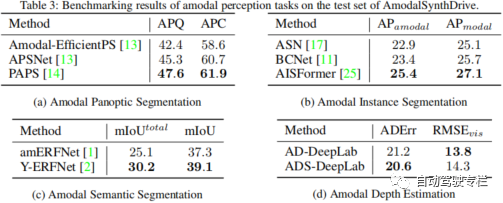
知覚は自動運転車にとって重要なタスクですが、現在の方法では、複雑な交通シーンを解釈するために必要なアモーダルな理解がまだ不足しています。したがって、この論文では、自動運転用のマルチモーダル合成知覚データセットである AmodalSynthDrive を提案します。合成画像と LIDAR 点群を使用して、基本的なアモーダル知覚タスク用のグラウンドトゥルースの注釈付きデータを含む包括的なデータセットを提供し、アモーダル深度推定と呼ばれる空間理解を強化する新しいタスクを導入します。この論文では、60,000 を超える個別の画像セットが提供されており、それぞれの画像セットには、モーダル インスタンス セグメンテーション、アモーダル セマンティック セグメンテーション、アモーダル パノラマ セグメンテーション、オプティカル フロー、2D および 3D 境界ボックス、アモーダル深度、および鳥瞰図が含まれています。 AmodalSynthDrive を通じて、この論文はさまざまなベースラインを提供し、この研究が動的な都市環境におけるアモーダル シーンの理解に関する新しい研究への道を開くと信じています。

##元のリンク: https ://mp.weixin.qq.com/s/7cXqFbMoljcs6dQOLU3SAQ
以上が合成アモーダル知覚データセット AmodalSynthDrive: 自動運転のための革新的なソリューションの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



