これは普通の退屈な自動運転ビデオだと思いますか?

このコンテンツの元の意味を変更する必要はありません。中国語に書き直す必要があります。
1 つのフレームも「本物」ではありません。

さまざまな道路状況、さまざまな気象条件、 20 を超える 状況をシミュレートでき、その効果は本物とまったく同じです。

#ワールドモデルは、その強力な役割を再び示しています。今回、LeCun さんが

を見て興奮してリツイートしました 上記の効果は、最新バージョンの GAIA-1 によってもたらされます。
これは
90 億パラメータ の規模を持ち、4700 時間 の運転ビデオ トレーニングを使用して、ビデオ、テキスト、または操作を入力して自動運転を生成する効果を実現します。ビデオ。
最も直接的な利点は、将来のイベントをより正確に予測できることです。 20 以上のシナリオをシミュレーションできるため、自動運転の安全性がさらに向上し、コストが削減されます。

クリエイティブ チームは、これは自動運転ゲームのルールを変えるだろうと述べています。
GAIA-1 はどのように実装されますか?実は、Wayve チームが開発した GAIA-1 については、以前 Autonomous Driving Daily で詳しく紹介しました:自動運転のための生成世界モデル。ご興味がございましたら、公式アカウントにアクセスして関連コンテンツをご覧ください。
スケールが大きいほど、効果は高くなります
GAIA-1は、視覚、聴覚、聴覚などの複数の知覚方法を統合することで世界を理解し、生成できるマルチモーダル生成世界モデルです。言語、表現。このモデルは、深層学習アルゴリズムを使用して、大量のデータから世界の構造と法則を学習し推論します。 GAIA-1 の目標は、世界をよりよく理解し、世界と対話するために、人間の知覚と認知能力をシミュレートすることです。自動運転、ロボット工学、仮想現実など、さまざまな分野で幅広い用途があります。継続的なトレーニングと最適化を通じて、GAIA-1 は進化と改善を続け、よりインテリジェントで包括的な世界モデルになります。
ビデオ、テキスト、モーションを入力として使用し、リアルな運転シーンのビデオを生成します。自動運転車のシーン特性を細かく制御できます
テキスト プロンプトのみを使用してビデオを
生成できます 。

そのモデルの原理は、大規模な言語モデルの原理と似ています。つまり、次のトークンを予測します。
このモデルは、ベクトル量子化表現を使用して、次のことを行うことができます。ビデオ フレームを離散化すると、将来のシナリオの予測がシーケンス内の次のトークンの予測に変換されます。次に、拡散モデルを使用して、ワールド モデルの言語空間から高品質のビデオが生成されます。
具体的な手順は次のとおりです。
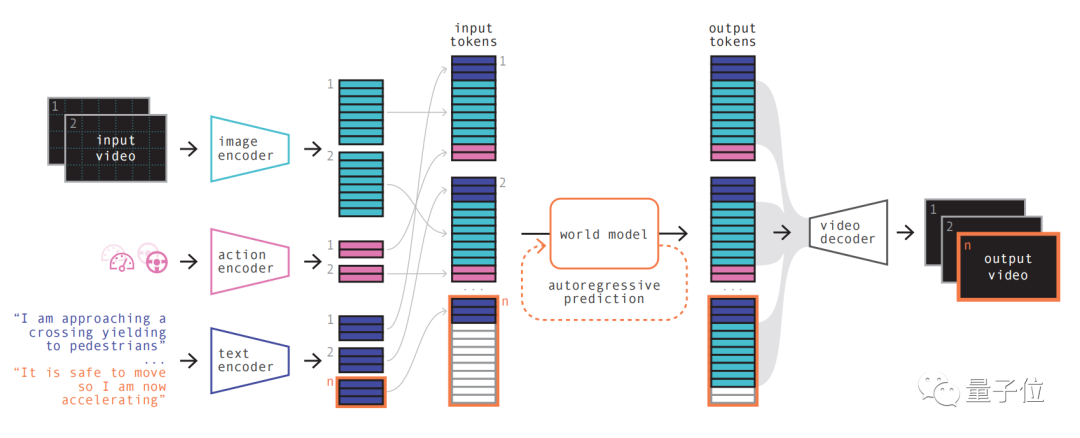
最初の手順は理解しやすく、さまざまな入力を再コード化して配置し、結合します。
特殊なエンコーダを使用してさまざまな入力をエンコードすることにより、さまざまな入力を共有表現に投影できます。テキスト エンコーダーとビデオ エンコーダーは入力を分離して埋め込みますが、操作表現は個別に共有表現に投影されます
これらのエンコードされた表現は時間的に一貫しています
並べ替え後の主要部分
ワールド モデル が表示されます。
自己回帰トランスフォーマーとして、シーケンス内の次の画像トークンのセットを予測する機能があります。以前の画像トークンだけでなく、テキストやアクションのコンテキスト情報も考慮します。
モデルによって生成されたコンテンツは、画像だけでなく、予測されたテキストやアクションとも一貫性を維持します
チームによると、GAIA-1 の世界モデルのサイズは
65 億パラメーター で、64 台の A100 で 15 日間トレーニングされました。
ビデオ デコーダとビデオ拡散モデルを使用することにより、これらのトークンは最終的にビデオに変換されます。
このステップは、ビデオの意味論的な品質、画像の精度、および時間的一貫性に関するものです。
GAIA-1 のビデオ デコーダは 26 億パラメータ の規模を持ち、32 台の A100 を使用して 15 日間トレーニングされました。
GAIA-1 は原理的に大規模言語モデルと類似しているだけでなく、モデル規模が拡大するにつれて生成品質が向上するという 特性を示していることは注目に値します。

チームは 6 月にリリースされた初期バージョンと最新の効果を比較しました。
後者は前者の 480 倍の大きさです。
動画のディテールや解像度などが大幅に向上していることが直感的にわかります。

実用的な応用という点では、GAIA-1 も影響を及ぼしており、そのクリエイティブ チームは、これが自動運転のルールを変えるだろうと述べています。

理由は 3 つの側面から来ています:
安全性- 包括的なトレーニング データ
- ロングテール シナリオ
-
まず第一に、安全性の観点から、世界モデルは未来をシミュレーションし、自動運転の安全性にとって重要な自身の決定を認識する能力を AI に与えることができます。
第二に、トレーニング データも自動運転にとって非常に重要です。生成されるデータはより安全で、より安価で、無限に拡張可能です。
生成 AI は、自動運転が直面する大きな課題であるロングテール シナリオを解決できます。霧の天候で道路を横断する歩行者に遭遇するなど、より多くのエッジケースに対応できます。これにより、自動運転のパフォーマンスがさらに向上します。
Wayve とは何ですか?
GAIA-1 は英国の自動運転スタートアップ
Wayve から提供されています。
Wayve は
Microsoft などの投資家とともに 2017 年に設立され、その評価額は Unicorn に達しています。
創設者は、現在の CEO である Alex Kendall と Amar Shah です (同社の公式 Web サイトのリーダーシップ ページには、もう彼らに関する情報はありません)。2 人ともケンブリッジ大学を卒業し、機械学習の博士号を取得しています

技術ロードマップでは、テスラと同様に、ウェイブはカメラを使用した純粋に視覚的なソリューションを提唱し、高精度地図を非常に早い段階で放棄し、「瞬間認識」路線をしっかりと守ります。
つい最近、チームがリリースした別の大型モデル
LINGO-1 もセンセーションを巻き起こしました。
この自動運転モデルは、運転中にリアルタイムで説明を生成できるため、モデルの解釈可能性がさらに向上します
今年 3 月には、ビル ゲイツ氏も Wayve の Self-Driving に試乗しました。車の運転。

文書アドレス: https://arxiv.org/abs/2309.17080
 書き換える必要がある内容は次のとおりです: 元のリンク: https://mp.weixin.qq.com/s/bwTDovx9-UArk5lx5pZPag
書き換える必要がある内容は次のとおりです: 元のリンク: https://mp.weixin.qq.com/s/bwTDovx9-UArk5lx5pZPag
以上が世界モデルが光る!これら 20 以上の自動運転シナリオ データの現実性は信じられないほどです...の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。



















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



